
“高并发”对于 Python 爬虫有多重要?反封控的底层逻辑在这!

很多人做 Python 爬虫时,往往会忽视动态代理的基础变量——并发。
为什么?
打个比方,同样是爬 10 万条数据,串行跑可能得花 8 小时以上;但如果并发数拉到 500,即使网络条件不变,时间可能只要十几分钟。
更关键的是,当请求分布更自然、耗时更短,触发平台反爬的概率也显著降低。

那么,动态代理 IP 的并发能力,究竟有多重要?我们来拆开讲。
高并发对爬虫来说为什么那么重要?
底层逻辑:爬虫最耗时的是网络 IO,而高并发正是把「网络等待」并行化,从时间线“压缩”到同一时刻。
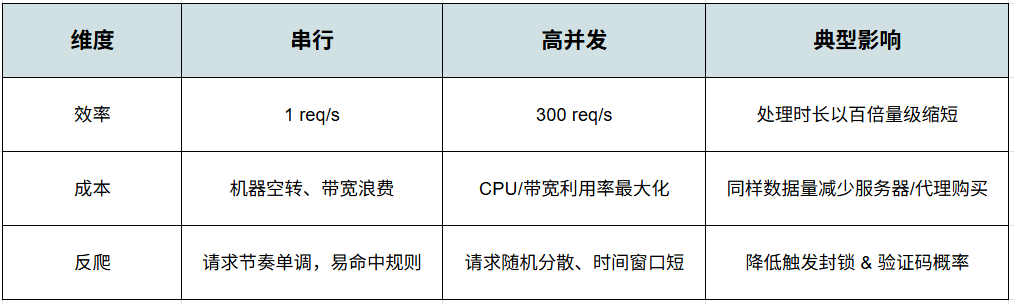
Python 实现高并发的三种主流路线
如果你用的是单一出口、低并发代理,一旦达到速率上限,就会触发平台封禁。而如果代理 IP 本身就支持高并发,就能有效撑住请求洪峰。
示例:
动态代理 IP 为什么要支持“高并发”?
高并发方案里,IP 本身往往是最先崩掉的地方。
但是部分“动态住宅 IP”可能会有限制并发的情况,就会上限速、限连接数:
这时就会出现:
并发线程太多,IP 端口承载不了,请求被强制断开;
触发代理商自建的限流策略,返回 403 或阻断连接。
所以代理 IP 的“并发承压”能力跟不上,效果也会大打折扣。
kookeey 提供的动态住宅 IP 服务,支持定制并发数,实现高并发,根据项目需求配置每个 IP 的连接上限。
kookeey7 月加赠福利,充值即可加赠 22%,限时 7 月,先到先得!
活动地址:
代理 IP 顶不住高并发,其实本质和程序里的线程调度原理很像——为什么?
类似的问题,也存在于主流编程语言的线程调度机制中。
我们从 Java 的线程调度模型里,也能看到 —— 不是开多少线程,而是背后调度和连接池能不能撑得住。
技术扩展-JDK 与 CGLIB
在 JDK 中,线程池的设计核心是“线程调度和连接复用”;而在 CGLIB 中,代理对象构建严重依赖类加载与缓存机制,高并发下性能差距明显。
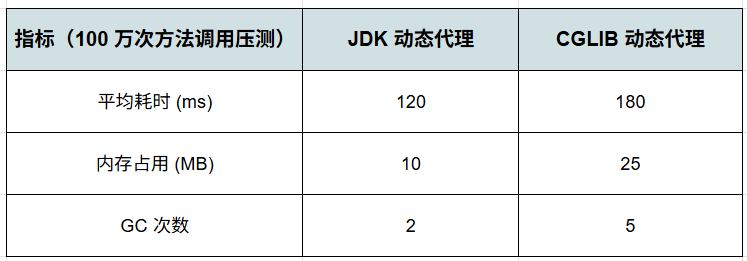
对比得出:JDK 平均耗时更低,内存占用更少,GC 次数也更少,说明它的高并发适应性更好。
与爬虫代理类比:如果你的代理出口响应慢、连接握手复杂(类似重字节码增强),并发再高也会被内耗吞掉;
真正适配 Python 并发爬虫的代理服务,必须在连接数支持、冷却机制、响应时延、提取速率和 API 结构这五个层面都稳得住,才能跑得快也扛得住。
🧩kookeey 提供动态住宅代理服务,支持子账户出口隔离和独显端口,是真正为高并发爬虫设计的代理方案。
以上就是今天的全部内容,各位还遇到什么问题欢迎在评论区留言~
版权声明: 本文为 InfoQ 作者【kookeey代理严选】的原创文章。
原文链接:【http://xie.infoq.cn/article/17bb6bee66ae1b99674f17eb6】。文章转载请联系作者。

欢迎咨询 2019-01-16 加入
业务级全球代理IP严选,提供正对客户业务场景,更纯净、更稳定的代理IP。












评论