
什么是数据同步利器 DataX,如何使用?
什么是 Datax?
DataX 是阿里云 DataWorks数据集成 的开源版本,使用 Java 语言编写,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
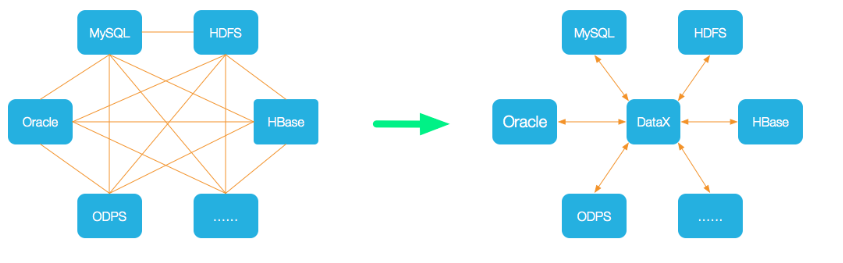
应用场景有那些?
数据仓库同步:DataX 可以帮助将数据从一个数据仓库(如关系型数据库、大数据存储系统等)同步到另一个数据仓库,实现数据的迁移、备份或复制。
数据库迁移:当我们需要将数据从一个数据库平台迁移到另一个数据库平台时,DataX 可以帮助完成数据的转移和转换工作
数据集成与同步:DataX 可以用作数据集成工具,用于将多个数据源的数据进行整合和同步。它支持多种数据源,包括关系型数据库、NoSQL 数据库、文件系统等,可以将这些数据源的数据整合到一个目标数据源中。
数据清洗与转换:DataX 提供了丰富的数据转换能力,可以对数据进行清洗、过滤、映射、格式转换等操作。这对于数据仓库、数据湖和数据集市等数据存储和分析平台非常有用,可以帮助提高数据质量和一致性。
数据备份与恢复:DataX 可以用于定期备份和恢复数据。通过配置定时任务,可以将数据从源端备份到目标端,并在需要时进行数据恢复。
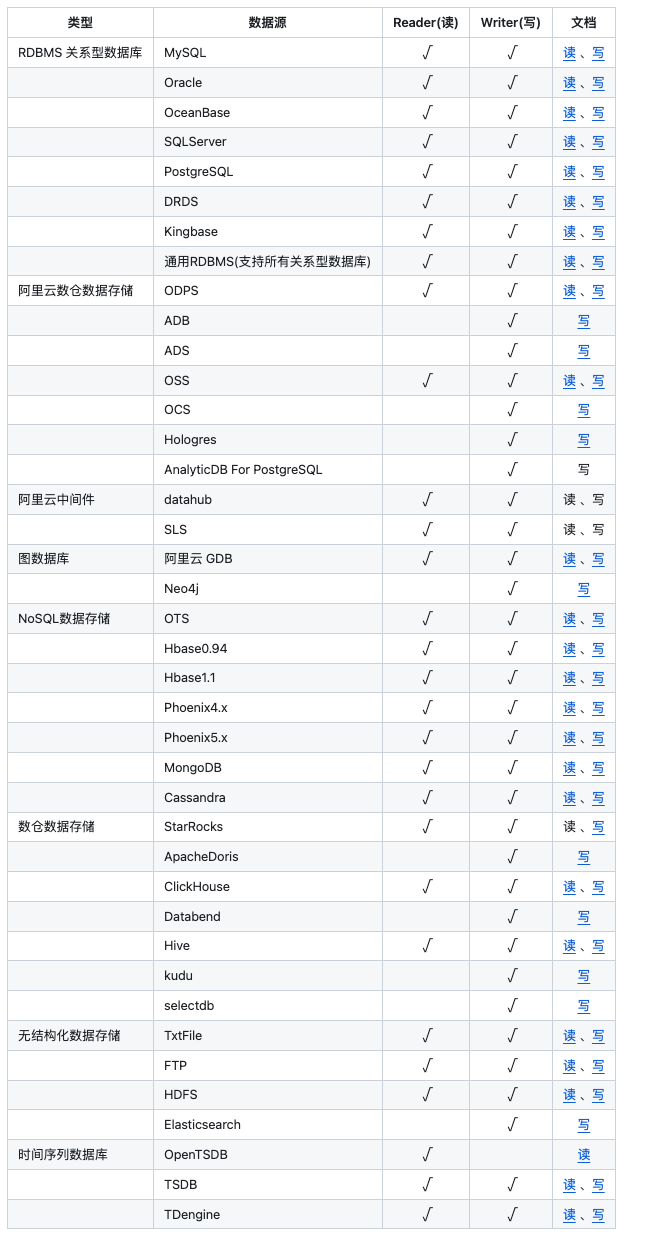
DataX 支持那些数据源?
架构设计

DataX 作为离线数据同步框架,采用 Framework + plugin 架构构建。将数据源读取和写入抽象成为 Reader/Writer 插件,纳入到整个同步框架中。
Reader:Reader 为数据采集模块,负责采集数据源的数据,将数据发送给 Framework。
Writer: Writer 为数据写入模块,负责不断向 Framework 取数据,并将数据写入到目的端。
Framework:Framework 用于连接 reader 和 writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 开源版本支持单机多线程模式完成同步作业运行,如下图
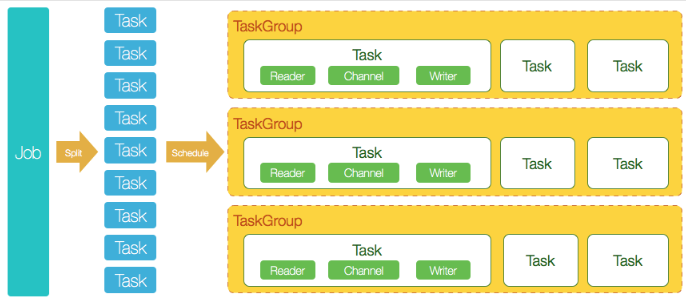
DataX 完成单个数据同步的作业,称之为 Job,DataX 接受到一个 Job 之后,将启动一个进程来完成整个作业同步过程。DataX Job 模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子 Task)、TaskGroup 管理等功能。
DataXJob 启动后,会根据不同的源端切分策略,将 Job 切分成多个小的 Task(子任务),以便于并发执行。Task 便是 DataX 作业的最小单元,每一个 Task 都会负责一部分数据的同步工作。
切分多个 Task 之后,DataX Job 会调用 Scheduler 模块,根据配置的并发数据量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组)。每一个 TaskGroup 负责以一定的并发运行完毕分配好的所有 Task,默认单个任务组的并发数量为 5。
每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader—>Channel—>Writer 的线程来完成任务同步工作。
DataX 作业运行起来之后, Job 监控并等待多个 TaskGroup 模块任务完成,等待所有 TaskGroup 任务完成后 Job 成功退出。否则,异常退出,进程退出值非 0
DataX 调度流程
举例来说,用户提交了一个 DataX 作业,并且配置了 20 个并发,目的是将一个 100 张表的 mysql 数据同步到 odps 里面。 DataX 的调度决策是:
Job 根据分表切分成了 100 个 Task。
根据 20 个并发,DataX 计算需要分配 4 个 TaskGroup。
4 个 TaskGroup 平分切分好的 100 个 Task,每一个 TaskGroup 负责 5 个并发共计运行 25 个 Task。
如何使用 Datax?
点击datax 下载,下载后解压至本地某个目录,如下图

用例说明
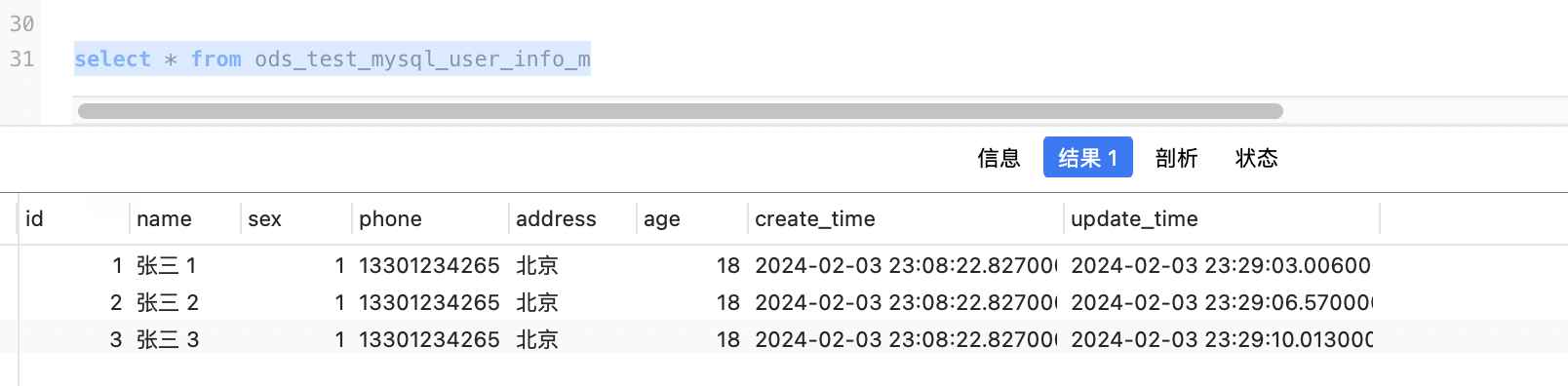
这里为了方便演示,我们同步 MySQL 的 user_info 表至 MySQL 的 ods_test_mysql_user_info_m,同步条件为更新时间字段,如下
在实际工作中你可以选择不同类型的数据源测试
在 user_info 表中插入数据如下

创建作业的配置文件(json 格式)
在 datax 的 script 目录,创建ods_test_mysql_user_info_m.json文件,配置如下,mysqlreader 表示读取端,mysqlwriter 表示写入端
创建执行脚本
为了更贴合实际,写一个调度脚本sync.sh支持动态参数来执行任务
假设我们要执以上ods_test_mysql_user_info_m.json脚本,并且同步十分钟之前的数据,如下
测试
执行./sync.sh ods_test_mysql_user_info_m.json 10进行同步

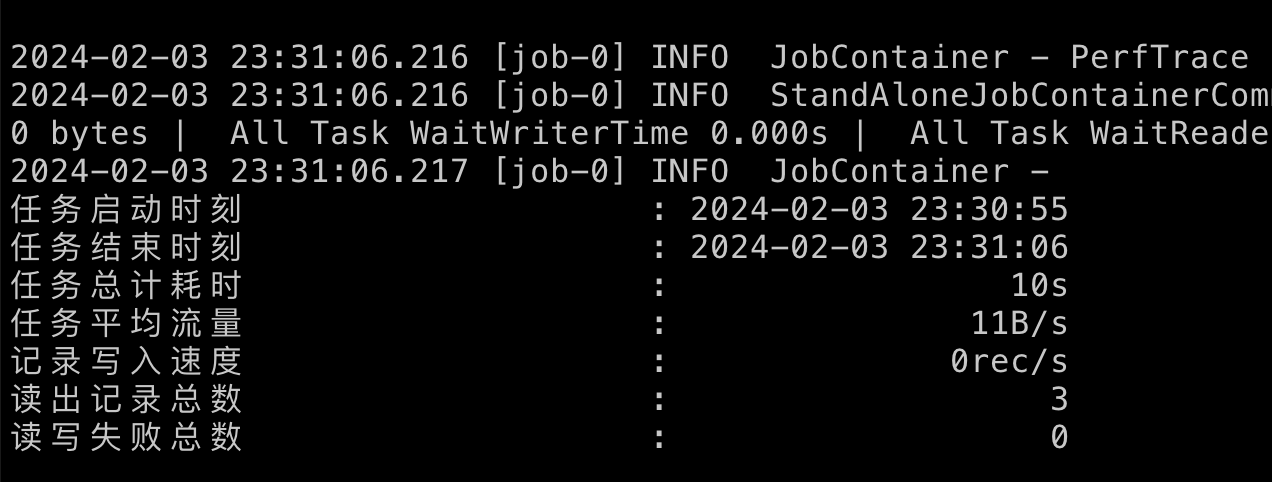
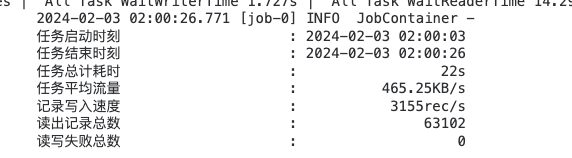
以上结果可能有些人有疑问,就三条数据执行时间为 10s,其实这个 10s 主要是初始化时间,耗时过长,同步的数据量多了优势就体现出来了,以下为实际生产同步数据结果,可以看到同步63102条耗时 22s
推荐用法
以上我们只是通过一个简单的示例来演示了 dataX 如何使用,如果只是一次性同步,没问题,但是如果是周期性进行同步,有以下几种方式推荐
crontab 调度
这种方式是最简单的,可以使用操作系统中的 crontab 定时调度,通过crontab -e编辑 corn 任务,添加对应脚本即可
海豚调度器
在种方式在大数据领域用的比较多,典型场景就是 mysql 同步到数仓,海豚调度器内置了 datax 并且提供了图形化配置界面,配置起来非常方便

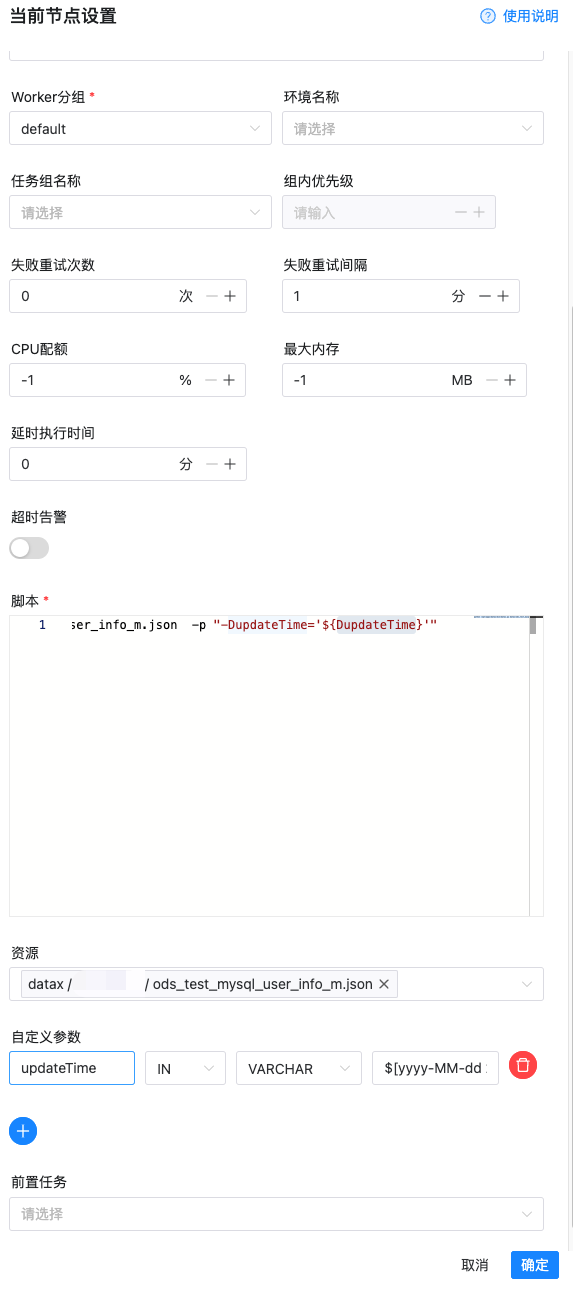
同时每次执行都有记录,并且都有对应的日志

定时任务框架(elasticjob/xxl-job)
在我们实际使用的业务系统定时调度框架都支持调度 shell 脚本,通过传入对应参数也可执行
文章转载自:架构成长指南

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论