
ebpf-linux 安全“双刃剑”
EBPF 技术简介
eBPF 全称 extended BPF,Linux Kernel 3.15 中引入的全新设计, 是对既有 BPF 架构进行了全面扩展,一方面,支持了更多领域的应用,另一方面,在接口的设计以及易用性上,也有了较大的改进。
eBPF 是一个基于寄存器的虚拟机,使用自定义的 64 位 RISC 指令集,能够在 Linux 内核内运行即时本地编译的 “BPF 程序”,并能访问内核功能和内存的一个子集。
发展历史
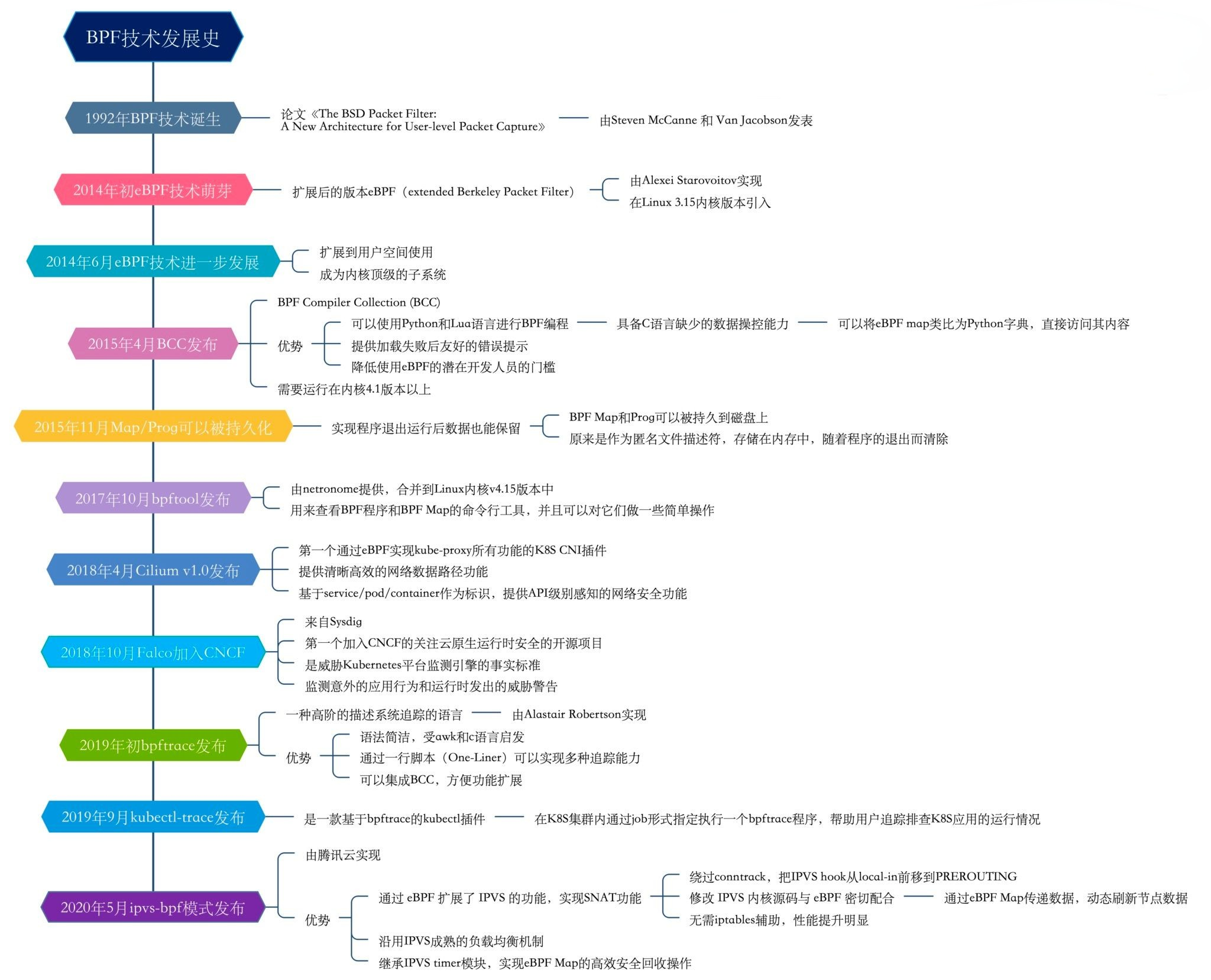
工作机制
ebpf 带来的安全威胁
eBPF 的 hook 点功能包括以下几部分:
1. 可以在 Storage、Network 等与内核交互之间;
2. 也可以在内核中的功能模块交互之间;
3. 又可以在内核态与用户态交互之间;
4. 更可以在用户态进程空间。
eBPF 的功能覆盖 XDP、TC、Probe、Socket 等,每个功能点都能实现内核态的篡改行为,从而使得用户态完全致盲,哪怕是基于内核模块的 HIDS,一样无法感知到这些行为。
网络层恶意利用 ebpf
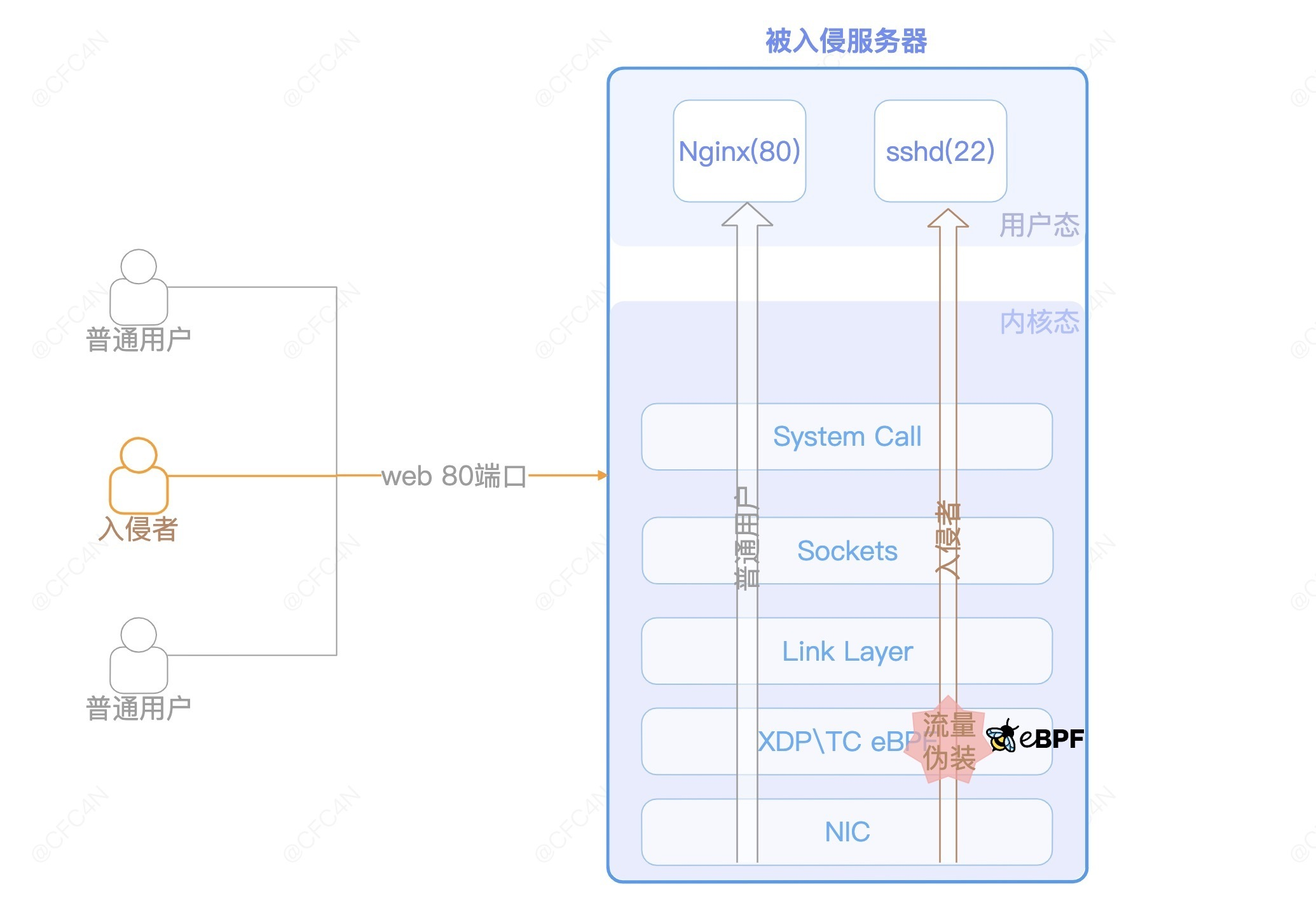
以一个 SSH、WEB 服务的服务器为例,在 IDC 常见网络访问策略中,开放公网 web 80 端口允许任意来源的 IP 访问。而 SSH 服务只允许特定 IP,或者只开放内网端口访问。
假设这台服务器已经被黑客入侵,黑客需要留下一个后门,且需要一个隐藏、可靠的网络链路作为后门通道,那么在 eBPF 技术上,会如何实现呢?
XDP/TC 层修改 TCP 包
为了让后门隐藏的更好,最好是不开进程,不监听端口(当前部分我们只讨论网络层隐藏)。而 eBPF 技术在 XDP、TC、socket 等内核层的功能,能够实现流量信息修改,这些功能常被应用在 L3、L4 的网络负载均衡上。比如 cilium 的网络策略都是基于 eBPF XDP 实现。eBPF hook 了 XDP 点后,更改了 TCP 包的目标 IP,系统内核再将该数据包转发出去。
按照 XDP 与 TC 在 Linux 内核中,处理 ingress 与 egress 的位置,可以更准确地确定 hook 点。
系统层恶意利用 ebpf
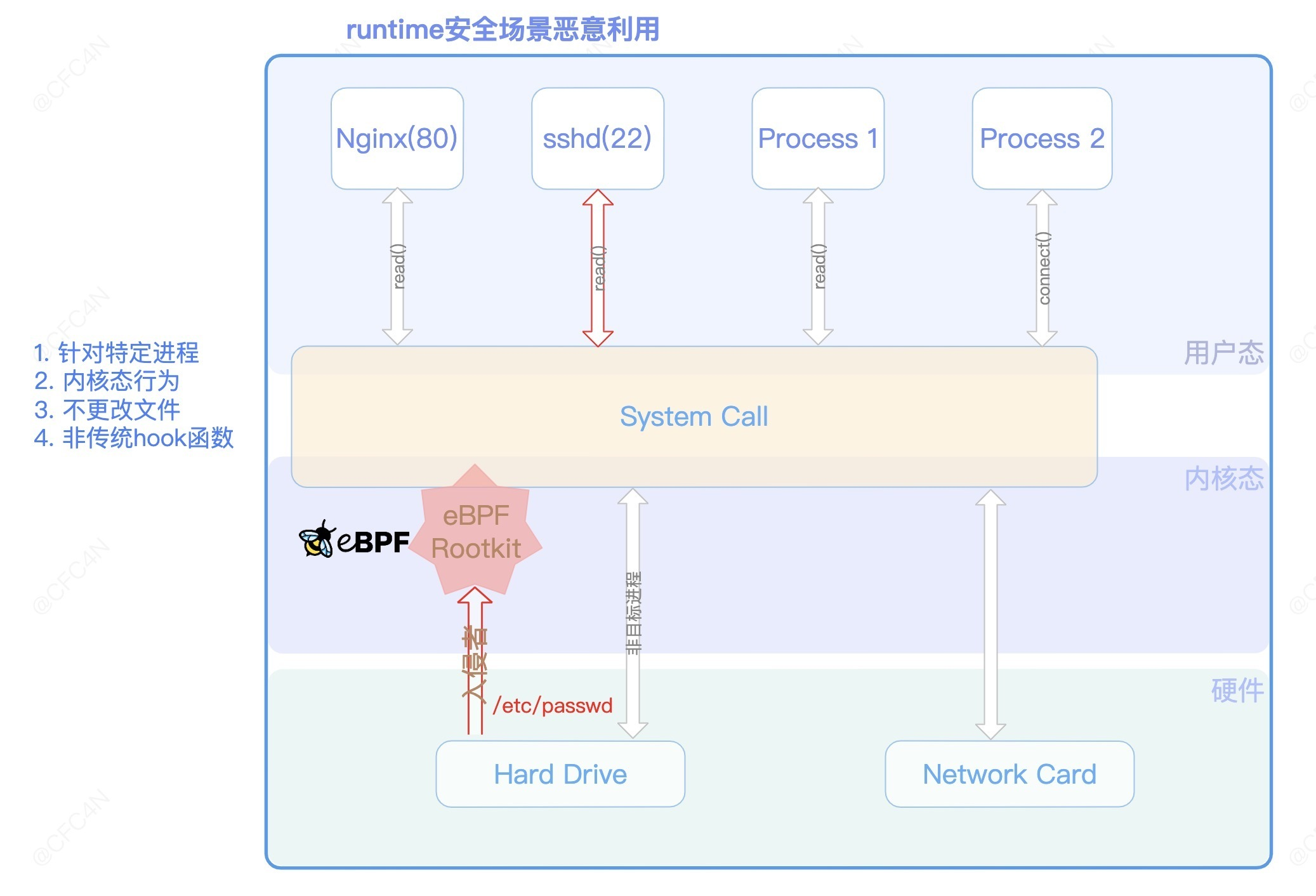
实现流程
回顾 eBPF 的 hook 点,作用在 syscall 的 kprobe、tracepoint 事件类型,倘若用在后门 rootkit 场景,是十分可怕的。比如,修改内核态返回给用户态的数据,拦截阻断用户态行为等为所欲为。而更可怕的是,常见的 HIDS 都是基于内核态或者用户态做行为监控,这恰恰就绕开了大部分 HIDS 的监控,且不产生任何日志.
tracepoint 事件类型 hook
在 SSHD 应用中,当用户登录时,会读取/etc/passwd 等文件。用户态 sshd 程序,调用 open、read 等系统调用,让内核去硬件磁盘上检索数据,再返回数据给 sshd 进程。
用户态生成 payload
用户态实现`/etc/passwd`、`/etc/shadown`等文件 payload 的生成,并通过 eBPF 的`RewriteConstants`机制,完成对 elf .rodata 的字段值替换。
内核态通过 ebpf 调用完成了随机用户名密码的 root 账号添加。在鉴权认证上,也可以配合`eBPF 网络层恶意利用`的 demo,利用 eBPF map 交互,实现相应鉴权。 但 rootkit 本身并没有更改硬盘上文件,不产生风险行为。并且,只针对特定进程的做覆盖,隐蔽性更好。
安全防御应对
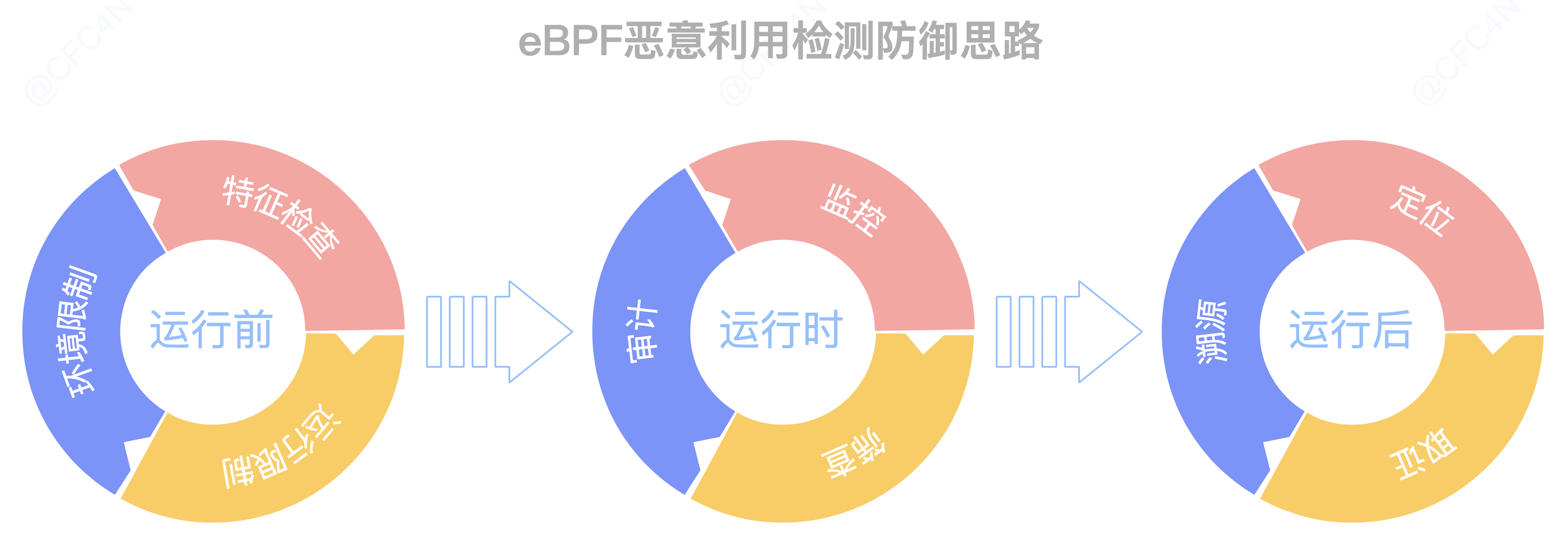
运行前
在恶意程序运行前,减少攻击面,这个思路是不变的。
环境限制
不管是宿主机还是容器,都进行权限收敛,能不赋予 SYS_ADMIN、CAP_BPF 等权限,就禁止掉。若一定要开放这个权限,那么只能放到运行时的检测环节了。
seccomp 限制
在容器启动时,修改默认 seccomp.json,禁止 bpf 系统调用,防止容器逃逸,注意此方法对于 Privileged 特权容器无效。
内核编译参数限制
修改函数返回值做运行时防护时,需要用到 bpf_override_return,该函数需要内核开启 CONFIG_BPF_KPROBE_OVERRIDE 编译参数,因此非特殊情况不要开启该编译参数。
非特权用户指令
大部分 eBPF 程序类型都需要 root 权限的用户才能调用执行。但有几个例外,比如 BPF_PROG_TYPE_SOCKET_FILTER 和 BPF_PROG_TYPE_CGROUP_SKB 这两个类型,就不需要 root。但需要读取系统配置开关。
运行时
监控
Linux 系统中,所有的程序运行,都必须进行系统调用,eBPF 程序也不例外。需要调用 syscall 为 321 的 SYS_BPF 指令。并且,所有的 eBPF 程序执行、map 创建都必须进行这个 syscall 调用。那么,在这个必经之路进行拦截监控,是最好的方案。
根据程序白名单筛选
在一些 BPF 应用的业务服务器上,本身业务行为会产生大量调用,会给安全预警带来较大审计压力。对于已知的进程,我们可以根据进程特征过滤。
获取当前进程 pid、comm 等属性,根据用户态写入 eBPF map 的配置,决定是否上报、是否拦截。
根据 SYSCALL 类型筛选
在 BPF syscall 里,子命令的功能包含 map、prog 等多种类型的操作,bpf() subcommand reference 里有详细的读写 API。在实际的业务场景里,“写”的安全风险比“读”大。所以,我们可以过滤掉“读”操作,只上报、审计“写”操作。
运行后
如果恶意程序比检查工具运行的早,那么对于结果存在伪造的可能。
安全工程师需要根据不同场景作不同的溯源策略:
命令 bpftool prog show,可以看到当前系统正在运行的 BPF 程序、关联的 BPF map ID,以及对应的进程信息等。
命令 bpftool map show,通过查看 map 信息,可以与程序信息作辅助矫正。并且,可以导出 map 内数据用来识别恶意进程行为。
bpflist-bpfcc -vv 命令可以看到当前服务器运行的“部分”BPF 程序列表。
bpftool net show dev ens33 -p 命令可以用于查看网络相关的 eBPF hook 点。
结语
EBPF 目前作为一门相对热门的技术,在越来越多技术人员了解到其方便性和高效率的同时,也会带来相当一大部分的“滥用”和“恶意利用”。正越来越成为安全领域不可回避的一个安全隐患甚至安全风险。
安全技术人员,既需要理解 ebpf 的实现机制,熟悉常用 ebpf 工具,又要能够了解并发现系统中被有心或者无意引入的这些 ebpf 的“泛滥”使用,加以封堵和规范,才能真正的用好 ebpf,这把 linux 内核的安全“双刃剑”。

还未添加个人签名 2022-08-11 加入
还未添加个人简介









评论