
五个独特且有趣的 ChatGPT 指令

今天分享 5 个很实用的指令,这几个指令很多时候对我们输出内容的连贯性、文章风格、创意性等方面有着决定性的作用。
第一个:Max tokens(最大令牌)
Max tokens 决定了生成文本的最大长度。通过设置一个限制,可以控制 AI 说的内容,确保它不给出过长的答案。
示例:max_tokens = 50 - 如果你想要一个简短的回答,像是快速回答或推文。
这样对输出的内容做了字数的限制,只有 50 个字,你可以根据自己的需求进行字数的调整

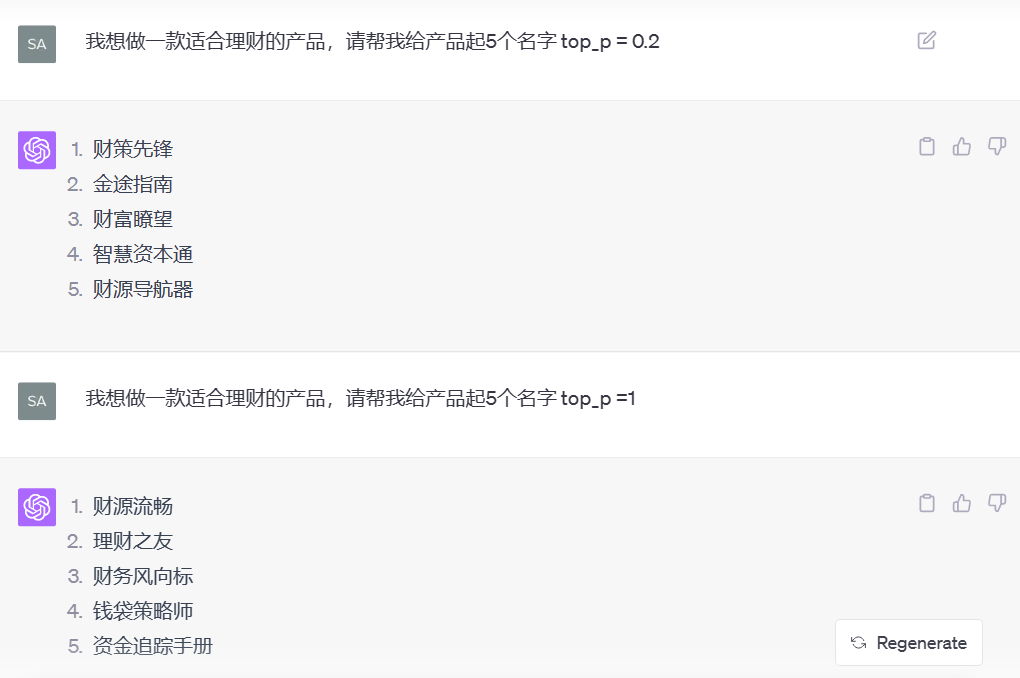
第二个:Top_p(控制采样)
此参数在 0 和 1 之间,控制核心采样,一种引入随机性的方法。
接近 1.0 的值使输出更加多样和随机, 接近 0 的值使其更加确定性。
示例:top_p = 0.8 - 如果你想在为新产品生成多个名称时得到多样的选项。
第三个:Presence_penalty (阻止调整)
这个参数范围在-2.0 至 2.0 之间,用来防止模型引入新的话题。值越高,会话将更加集中但可能较为乏味。
示例:presence_penalty = 0.6 - 如果你希望模型坚持讨论特定话题,如详细探讨某个具体项目。


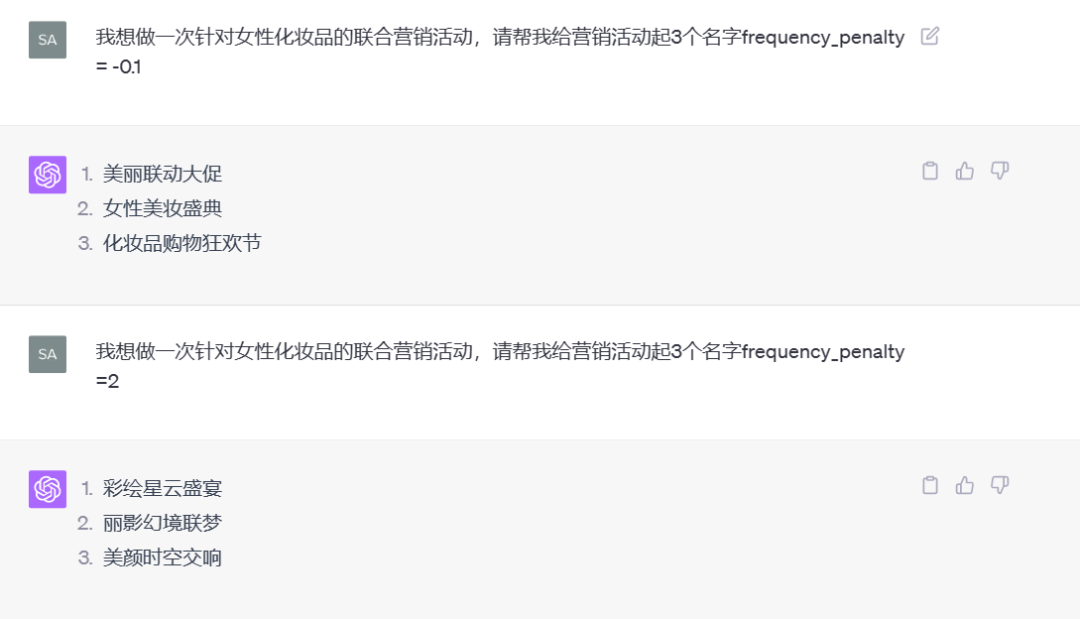
第四个:Frequency_penalty (短语效应)
此参数的范围在-2.0 至 2.0 之间,它用来防止模型使用常见的短语或回应。值越高,输出内容将更具创意,但可能减少连贯性。
示例:frequency_penalty = 1.0 - 如果你想生成一个口号或标语,并希望它是独特的,而不是常见的短语。
第五个:Temperature(文风的温度)
使用较低温度生成的文本将更加集中和保守,而使用较高温度生成的文本则会更具创意和变化。温度的范围是从 0 到 1。
温度 = 0:模型会产生最确定的输出,但可能显得重复或模板化。
0 < 温度 < 0.5:输出将倾向于较为稳定和保守,提供高度相关且一致的回应。
温度 = 0.5:产生的文本会有一个适中的平衡,既不过于随机也不过于保守。
0.5 < 温度 < 1:输出会更具创意和变化,但可能牺牲一些连贯性。
温度 = 1:模型会产生最大程度的创意和随机性,可能产生出奇不意的答案,但风险也更高。

实战中可以多个组合使用,比如:
Temperature:0.7 至 1,以获得最大的创意和多样性。
Frequency_penalty:1 至 2,用于产生各种独特的短语和想法。
Max tokens:根据你所需的故事长度或场景进行设置。
版权声明: 本文为 InfoQ 作者【这我可不懂】的原创文章。
原文链接:【http://xie.infoq.cn/article/0cda30c93babe6ff5dc0a7c01】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

低代码技术追随者,为全民开发而努力 2023-02-15 加入
大家好,我是老王,专注于分享低代码图文知识,感兴趣的伙伴就请关注我吧!









评论