
酷克数据发布 HD-SQL-LLaMA 模型,开启数据分析“人人可及”新时代
随着行业数字化进入深水区,企业的关注点正在不断从“数字”价值转向“数智”价值。然而,传统数据分析的操作门槛与时间成本成为了掣肘数据价值释放的阻力。常规的数据分析流程复杂冗长,需要数据库管理员设计数据模型,数据工程师进行 ETL 处理,再由数据分析师编写 SQL 查询进行分析,耗时耗力,同时欠缺足够的业务灵活度。
面对这一挑战,业界也在不断探索解决方案,无论是库函数的封装、API 的应用、还是各类图形化界面的出现,都是对流程中各个环节的不断简化。然而,大语言模型的广泛应用提供了一种端到端服务的可能性,凭借崭新的交互体验,为企业对内与对外的业务场景带来了大量的新机遇。数据库管理着高价值的结构化数据,成为了探索数据分析智能化的绝佳起点。
HD-SQL-LLaMA:更准确的 Text2SQL 垂类模型
众所周知,当面临具体特定场景时,通用模型的准确率、精确率和召回率有限,直接使用效果不佳。为了提升模型效果,降低幻觉产生的潜在风险,对基座模型进行微调生成垂类模型成为了一个必选项目。近日,业界领先的云数仓厂商酷克数据发布了专门用于从问题描述生成 SQL 的大语言模型 HD-SQL-LLaMA。该模型依托酷克数据自研云数仓产品 HashData 和下一代数据科学与 AI 开发工具 HashML,基于知名的开源语言模型 LLaMA2,使用大量高质量的中英文 Text2SQL 训练数据进行微调而来。在推理过程中,通过在 Prompt 中引入与查询相关数据库表的 Schema 信息,进一步提升了从文本描述生成 SQL 的精准度。
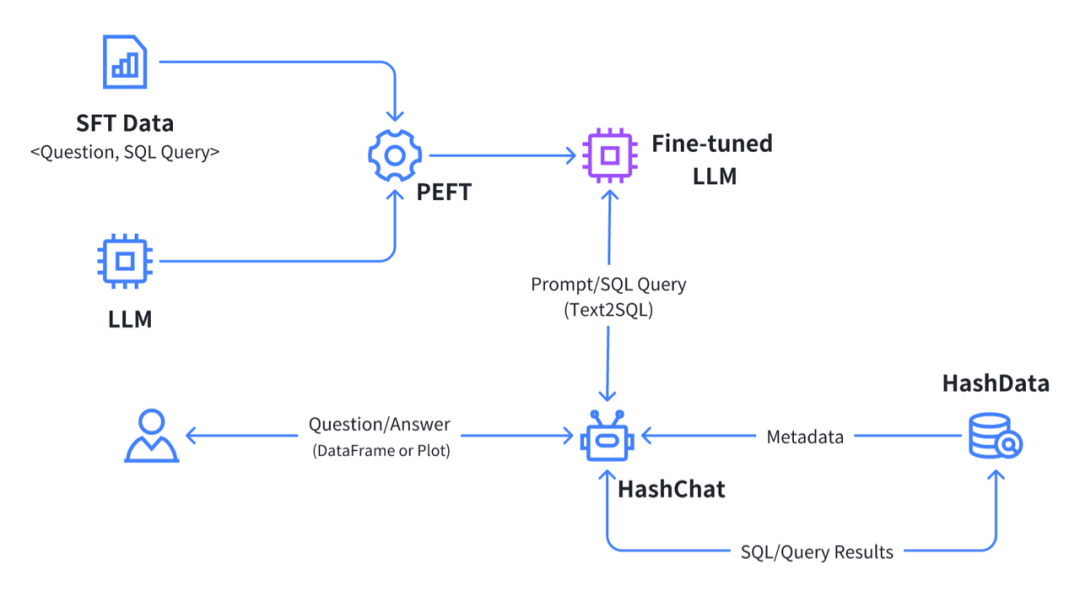
图 1: Text2SQL 模型微调及交互式数据查询分析应用
为保证微调数据的多样性,团队选取了 WikiSQL, Spider, sql-create-context, Bird 等在内的多个开源数据集,数据涵盖众多行业领域。除此之外,团队还收集整理了大量自有数据,通过数据清洗、正确性验证、数据采样等处理过程得到最终的微调训练数据。
图 2:微调样例数据
为了对模型效果进行客观评估,团队参考了 CSpider 的 SQL 难度评级方法,构造了一个具备多样性的评估数据集,评估样本涵盖从简单(easy)、中等(medium)、困难(hard)到极难(extra)4 个等级。该评价方法主要根据 SQL 语句中出现关键字(如 WHERE、GROUP BY、ORDER BY、 HAVING、UNION、INTERSECT 等)的类别和数量对 SQL 语句的难度进行分级。
图 3:SQL 难度分级样例数据
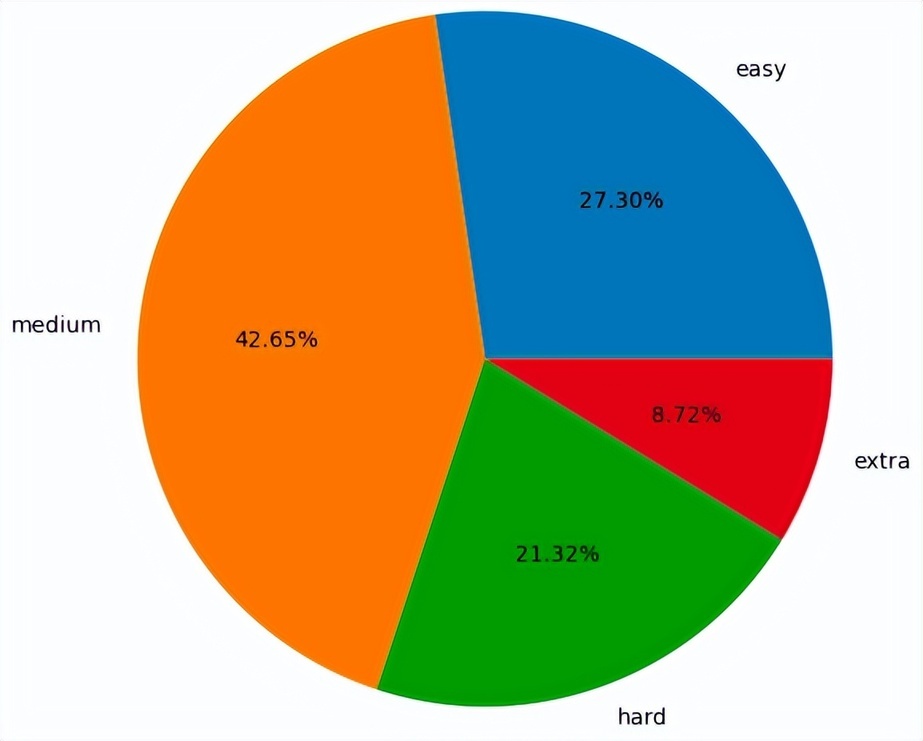
图 4:评估数据集难度分级占比
为了验证生成 SQL 的正确性,团队针对每个评估样本构造了一个由若干数据表构成的数据库,每张数据表都包含若干条数据记录。对于每个评估样本,分别执行 Ground-Truth SQL 和生成的 SQL,通过检验生成 SQL 的可执行度和比对查询结果的一致性,判断生成 SQL 的正确性,最终统计整个评估集的准确率。评估结果显示,HD-SQL-LLaMA2 在不同难度的评估样本集上均表现良好,13B 模型准确率接近 82%,34B 模型准确率超过 88%,展现了该模型强大的零样本泛化能力和商业化应用潜力。
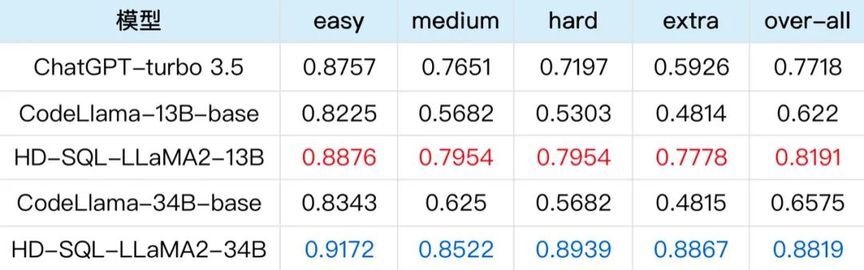
表 1:Text2SQL 难度分级评估结果
与需要大规模计算资源的千亿级参数模型不同,HD-SQL-LLaMA2 模型更轻量化,可以部署在单个消费级 GPU 上进行实时高效推理。这不仅降低了企业使用成本,也使其可以部署于私有环境中,有效保护了企业敏感数据的安全性,满足合规要求。同时,基于 HashML 提供的 AI 开发能力,HD-SQL-LLaMA2 还支持根据企业数据特点进行快速的本地微调和升级,提供了一个灵活的定制化解决方案。
ChatData:更便捷的对话式数据查询与分析应用
为了帮助客户快速便捷地将这一模型应用于实际业务,酷克数据还研发了 ChatData:基于自然语言的交互式数据分析智能应用。
ChatData 通过自然语言对话的方式,自动将用户提出的问题转化为 SQL 查询,使数据库访问和数据分析成为一件尤其简单的事情。用户无需掌握 SQL 语法,只需用中文或英文提出自己的查询需求,ChatData 将自动转换为 SQL 语句,在后端数据库中检索并返回结果,同时还支持基于自然语言交互的方式对查询结果可视化。这为广大的业务团队提供了简单直观地查询数据的新途径。
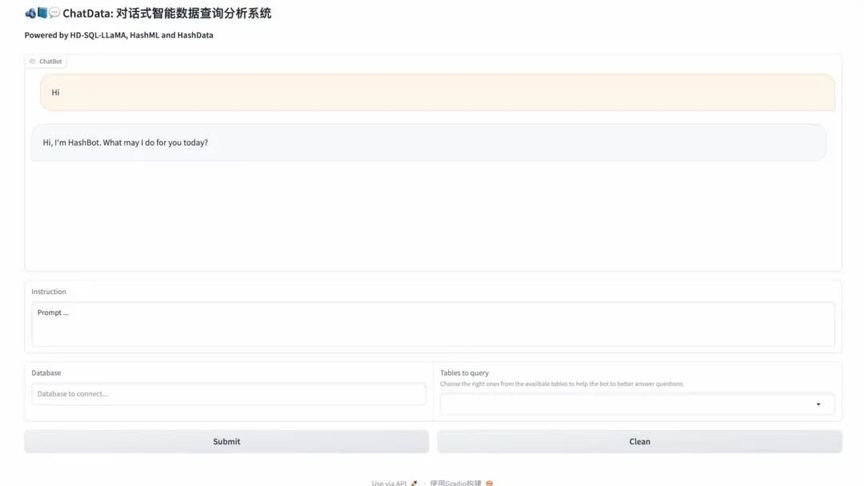
图 5:中英文对话式数据查询与可视化
结语
HD-SQL-LLaMA2 基于大语言模型强大的语言理解和生成能力实现了更精准的 Text2SQL,降低了数据分析的工作量,极大地提高了企业大数据团队的工作效率,使得用户能够将宝贵时间投入到更多的商业价值创造中。
ChatData 的出现,进一步简化了整个数据分析操作,降低了数据分析的技术门槛。用户只需使用自然语言描述问题,就可以获取所需的信息与结论。这将使得企业内更多的业务团队能够参与到数据驱动的业务决策中,提高整个组织的协同效率和决策准确性,同时大幅缓解数据工程团队的工作负载。在技术创新力量推动下,数据分析正在步入“人人可及”的新时代。
在这个数据赋能商业的时代,酷克数据将继续致力于自主创新的技术和产品,服务助力企业的数智化转型。我们坚信科技进步必将造福人类,让世界变得更加智能与美好。
版权声明: 本文为 InfoQ 作者【HashData】的原创文章。
原文链接:【http://xie.infoq.cn/article/089b96eb028febdf233c6d48d】。文章转载请联系作者。

还未添加个人签名 2021-03-10 加入
云原生企业级数据仓库









评论