
DeepSeek-R1 本地部署如何选择适合你的版本? 看这里
DeepSeek-R1 本地部署:选择最适合你的版本,轻松搞定!

关于本地部署 DeepSeek-R1 前期知识
如果你正在考虑将 DeepSeek-R1 部署到本地服务器上,了解每种类型的硬件需求是非常重要的。DeepSeek-R1 是一个非常强大的语言模型,它有多个不同的版本,每个版本在计算资源和硬件要求上都有不同的需求。本文将帮助你理解每个版本的参数、所需硬件以及如何根据自己的需求选择合适的类型。

选择最合适你的版本
PS:本文是本地化部署 DeepSeek 系列教程第二篇。本系列共计 4 篇文章,最终,我们讲实操在 Windows 操作系统和 Mac 操作系统实现本地部署 DeepSeek-R1 大模型。
DeepSeek-R1 的不同类型及含义
DeepSeek-R1 有多个不同的类型,每个类型的名称后面跟着一个数字(比如 1.5B、7B、14B 等),这些数字代表模型的参数量。参数量直接决定了模型的计算能力和存储需求,数字越大,模型越强,但也需要更多的硬件资源。
什么是“B”?
在这些数字中,B 代表“billion”(十亿),所以:
1.5B 意味着该模型有 15 亿个参数
7B 表示 70 亿个参数
8B 表示 80 亿个参数
14B 表示 140 亿个参数
32B 表示 320 亿个参数
70B 表示 700 亿个参数
671B 表示 6710 亿个参数
这些模型的参数量越大,处理的数据和生成的内容就越复杂,但它们也需要更多的计算资源来运行。
每种类型的硬件需求
每个模型的计算和存储需求都有所不同,下面我们列出了 DeepSeek-R1 的各个型号,并给出了所需的硬件配置。根据不同的使用需求,选择合适的模型可以帮助你节省成本,同时提升部署效率。
DeepSeek-R1 类型信息表格
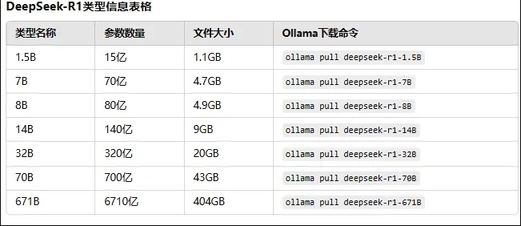
R1 不同版本模型大小
各类型模型的硬件需求总结
根据你选择的型号,硬件需求会有所不同。以下是每个模型的大致硬件要求:
1.5B(1.1GB):
CPU:普通的四核或六核处理器即可。
显卡:中等性能显卡,如 NVIDIA GTX 1650 或 RTX 2060。
内存:16GB RAM。
磁盘空间:至少 50GB 空闲空间。
7B(4.7GB):
CPU:6 核或 8 核处理器。
显卡:NVIDIA RTX 3060 或更强显卡。
内存:32GB RAM。
磁盘空间:至少 100GB 空闲空间。
8B(4.9GB):
CPU:6 核或 8 核处理器。
显卡:NVIDIA RTX 3060 或更强显卡。
内存:32GB RAM。
磁盘空间:至少 100GB 空闲空间。
14B(9GB):
CPU:8 核以上处理器,如 Intel i9 或 AMD Ryzen 9。
显卡:NVIDIA RTX 3080 或更强。
内存:64GB RAM。
磁盘空间:至少 200GB 空闲空间。
32B(20GB):
CPU:8 核以上处理器。
显卡:NVIDIA RTX 3090、A100 或 V100 显卡。
内存:128GB RAM。
磁盘空间:至少 500GB 空闲空间。
70B(43GB):
CPU:12 核以上处理器,推荐使用高端 Intel 或 AMD 处理器。
显卡:NVIDIA A100、V100 显卡,甚至需要多个显卡配置。
内存:128GB RAM。
磁盘空间:至少 1TB 空闲空间。
671B(404GB):
CPU:高性能、多核 CPU,建议多台服务器配置。
显卡:NVIDIA A100 或多个 V100 显卡,甚至需要集群支持。
内存:至少 512GB RAM。
磁盘空间:至少 2TB 空闲空间。
各模型硬件需求如下表:
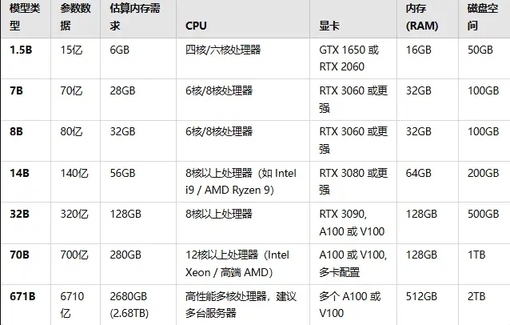
各模型对比
说明:
CPU:随着模型参数量的增加,CPU 的核心数要求也逐渐增加。高端多核处理器有助于减少计算瓶颈,尤其在大模型推理时。
显卡:随着模型规模的增大,对显卡的要求也越来越高。GPU 的显存和计算能力成为关键。如果单卡显存不够,可能需要多个显卡联合工作。
内存:内存不仅仅用于存储模型参数,还需要为计算过程中的中间结果、缓存等分配足够空间。大模型尤其对内存的需求大,超过 32GB 的模型在内存方面会有较大压力。
磁盘空间:磁盘空间是根据模型的大小和推理过程中的临时数据存储需求计算的。尤其对于大型模型,在存储和加载数据时需要更多的空间。
注意:
这些硬件需求是针对 推理 场景进行估算的,如果是 训练,硬件需求会更高,特别是在 GPU 和内存方面。
实际硬件需求还取决于模型优化方法、量化技术、分布式计算和云服务等因素,可能会有所不同。
每个参数需要多少字节?
一般来说,DeepSeek-R1 模型中的每个参数占用 4 个字节(32 位)。这个值相对固定,常用于大多数深度学习模型。通过这个假设,我们可以计算出每个版本大致需要多少内存。
计算方法:
每个参数需要 4 字节
假设某个模型有 70 亿个参数(即 70B 模型)
所以,内存需求 = 70 亿个参数 × 4 字节/参数 = 28GB
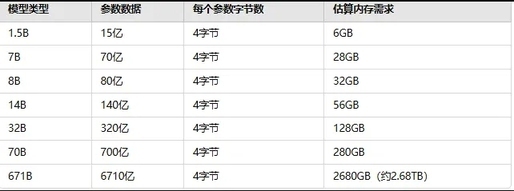
不同模型需要内存大小
疑问:7B 或者 8B 是阉割版本吗?
在 DeepSeek-r1 中,1.5B、7B、8B 模型分别指的是模型的参数数量:1.5B 代表 15 亿个参数,7B 代表 70 亿个参数,8B 代表 80 亿个参数。这些参数数量直接影响模型的计算能力和所需的存储空间。
1.5B 模型是较小的版本,计算能力较弱,但占用的内存和存储空间较小,适合对硬件要求不高的场景。
7B 和 8B 是更强大的版本,参数更多,计算能力更强,因此模型的推理能力和生成质量也更高。
7B 不是阉割版,它只是相对于 8B 而言,参数数量稍少,因此它的计算能力和生成效果可能略差,但并不意味着它比 8B“功能不全”或者“缩水”,只是在计算能力上有所差距。
如果你对推理速度和资源占用有较高的要求,选择 1.5B 会更合适。如果你希望模型生成质量更高,可能更倾向于 7B 或 8B。不过,性能差距主要体现在任务的复杂性和精度上。
下面是每个版本的计算能力和生成质量的详细比较:
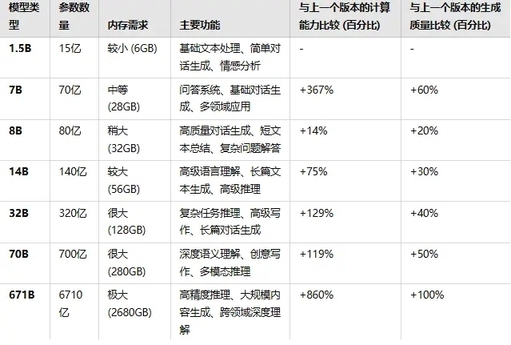
各个版本之间计算能力及生产能力对比
详细比较:
1.5B (15 亿参数)
主要功能:适合基础的文本处理、情感分析、简单对话生成等。
与上一个版本的计算能力比较:没有前一个版本可比,作为最小模型,计算能力最弱。
与上一个版本的生成质量比较:同理,生成质量最低,文本较为简单和粗糙。
7B (70 亿参数)
主要功能:能够处理多领域应用,如问答系统、对话生成、基本文本总结。
与上一个版本的计算能力比较:相比 1.5B,计算能力提升了 367%,推理能力增强,能处理更多复杂任务。
与上一个版本的生成质量比较:相比 1.5B,生成质量提升 60%,文本更自然,理解上下文能力增强。
8B (80 亿参数)
主要功能:适用于高质量对话生成、短文本总结、复杂问题解答等。
与上一个版本的计算能力比较:相比 7B,计算能力提升 14%,推理能力有所增强,但增幅较小。
与上一个版本的生成质量比较:相比 7B,生成质量提升 20%,生成的文本更加自然、准确,适应更复杂的语境。
14B (140 亿参数)
主要功能:高级语言理解、长篇文本生成、高级推理等任务。
与上一个版本的计算能力比较:相比 8B,计算能力提升 75%,能够处理更复杂的语境和任务。
与上一个版本的生成质量比较:相比 8B,生成质量提升 30%,长篇生成更连贯、自然,文本质量大幅提升。
32B (320 亿参数)
主要功能:适合复杂推理任务、高级写作、长篇对话生成等。
与上一个版本的计算能力比较:相比 14B,计算能力提升 129%,可以处理更多复杂任务。
与上一个版本的生成质量比较:相比 14B,生成质量提升 40%,文本质量接近人工水平,适合高级写作和深度理解。
70B (700 亿参数)
主要功能:深度语义理解、创意写作、多模态推理等高端应用。
与上一个版本的计算能力比较:相比 32B,计算能力提升 119%,能够处理更加复杂的推理和生成任务。
与上一个版本的生成质量比较:相比 32B,生成质量提升 50%,文本质量更加精细,几乎无明显错误,适用于创意和高精度任务。
671B (6710 亿参数)
主要功能:超高精度推理、大规模内容生成、跨领域深度理解等任务。
与上一个版本的计算能力比较:相比 70B,计算能力提升 860%,能够处理极为复杂的推理任务和大规模内容生成。
与上一个版本的生成质量比较:相比 70B,生成质量提升 100%,文本生成几乎完美,几乎没有语境偏差,适用于最复杂的任务。
总结:
计算能力:从 1.5B 到 671B,每个版本相对于前一个版本的计算能力都有显著提升,尤其是从 70B 到 671B,计算能力的大幅度提升说明了超大模型在推理复杂性上的巨大优势。
生成质量:生成质量从 1.5B 到 671B 逐步提升,每个新版本生成的文本更加自然、流畅,能够处理更复杂的上下文和细节。尤其是 70B 和 671B 版本的文本生成已经达到了极高水平,几乎可以媲美人工写作。
如何选择合适的型号?
选择哪种类型的 DeepSeek-R1 模型取决于你的应用场景以及硬件配置。如果你只是进行简单的文本处理、学习或小型项目,1.5B 和 7B 可能就足够了。如果你的需求是生成高质量的文本,或者做大规模的数据处理,14B 和更高的型号可能更适合。对于科研或者企业级应用,32B、70B 甚至 671B 的型号能提供超高的性能和处理能力。
总结
不同型号的 DeepSeek-R1:每个型号的参数数量和存储需求不同,越大的型号需要的硬件配置越高,处理能力也越强。
硬件配置:选择合适的型号时,需要考虑自己的硬件配置。例如,1.5B 模型对硬件要求较低,而 70B 和 671B 则需要非常强大的计算资源。
估算内存需求:一般来说,每个参数占用 4 字节,通过参数数量和字节数可以粗略估算每个模型的内存需求。
文章转载自:kaizi1992

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论