
Git 的存储原理
概括的讲,Git 就是一个基于快照的内容寻址文件系统。 往下慢慢看。
Git vs SVN
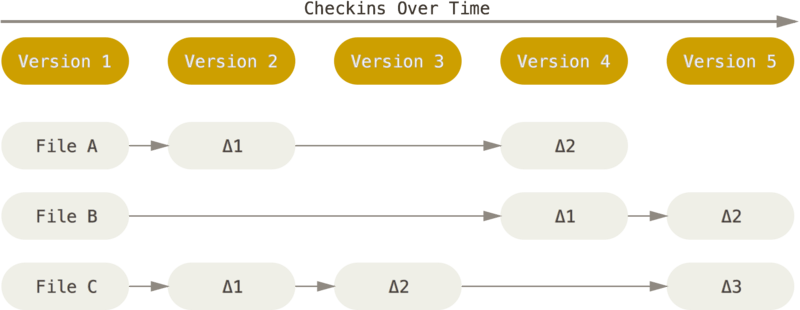
Git 出现前,主流版本控制系统(SVN...)一般为基于增量(delta-based)的系统,如下图:
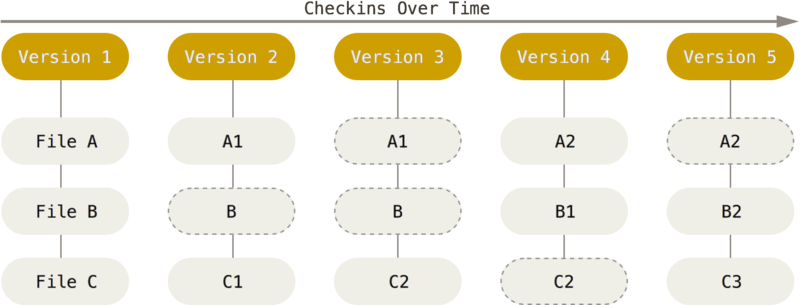
Git 则是基于快照(snapshot),即针对每一个被修改的文件生成一个快照,没被修改的则不再重新生成快照,如下图:
直觉上讲,似乎基于增量的方式要更好些?
毕竟针对被修改的文件,Git 生成的是完全的快照,而其他系统只是生成增量文件。没错,但是当需要回滚版本或者比对多个版本间的差异时,Git 只需要取出对应版本的快照文件进行对比即可,而基于增量的系统则需要从头开始一步步应用增量文件来回溯,Git 的速度优势就很明显了。
Git 存储模型
.git 目录结构
当用git init 或者 git clone 获取一个 git 仓库时,可以发现目录下有一个隐藏目录。git,它的基本结构类似如下:
这个目录下包含了 Git 所有信息,且都是用文件的形式存储,所以说 Git 是一个文件系统。
Git 基本数据对象
blob(二进制大对象):也就是前面说的基于快照存储的文件
tree:目录,代表了 blob 对象的集合
commit:提交,包含了 blob、tree 的集合
tag:标签对象(指 annotation 标签),还有一种轻量标签不记录创建标签人等额外信息,不需要再单独创建标签对象
上述 4 种数据对象均存储在。git/object/目录下,git 会对每一种数据对象计算哈希值来确定具体的存储路径,下面来举个例子。
git hash-object 命令可以用于计算文件的哈希值
-w 表示把将对象写入到 git 数据库中
--stdin 表示从标准输入读取内容
git cat-file 命令可以根据传入哈希值取出 git 存储的对象
-p 自动判断内容的类型
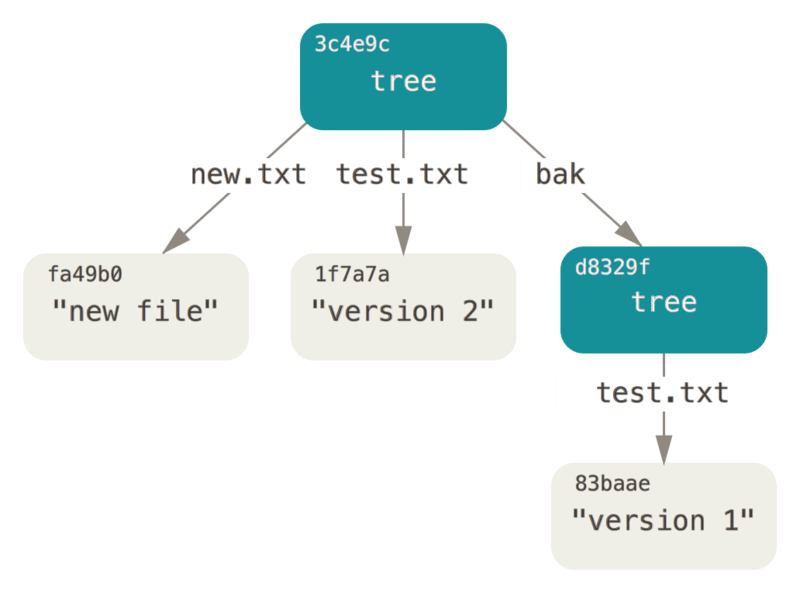
一次提交的数据结构可以用下图来概括:
Git 包文件
可能有的小伙伴通过上述方式在自己项目中尝试时,发现在。git/objects/下找不到对应文件,这是什么原因呢?
可能真的不是操作出了问题,而是 Git 进行了压缩操作。
Git 最初存储对象时使用的时"松散(loose)"对象格式,即保存在。git/objects/下。
但是,Git 会时不时(或者当你手动执行git gc命令后)地将这些对象打包成一个称为“包文件(packfile)”的二进制文件(存储在。git/objects/pack),以节省空间和提高效率。
Git 引用
引用类似于指针,除了 HEAD 存储在。git/HEAD 以外,其他指针存储在。git/refs 目录下
分支
HEAD:一种特殊的指针,用于指向目前所在的 commit,。git/HEAD 文件里存储的就是引用的 commit 的哈希值
标签(轻量标签)
可以看出,所谓的引用只是一个记录了 commit 哈希值的文件,非常的轻量,这也是为什么分支/标签的创建、删除速度能这么快的原因。
文章转载自:小江的学习日记

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论