
【kafka 原理】kafka Log 存储解析以及索引机制
作者:石臻臻,CSDN 博客之星 Top5、Kafka Contributor、nacos Contributor、华为云 MVP,腾讯云 TVP,滴滴 Kafka 技术专家、 KnowStreaming PMC)。
KnowStreaming 是滴滴开源的Kafka运维管控平台, 有兴趣一起参与参与开发的同学,但是怕自己能力不够的同学,可以联系我,带你一起你参与开源! 。
本文设置到的配置项有
首先启动 kafka 集群,集群中有三台 Broker; 设置 3 个分区,3 个副本;
1 发送 topic 消息
启动之后kafka-client发送一个 topic 为消息szz-test-topic的消息
发送了之后可以去log.dirs路径下看看
这里的 3 个文件夹分别代表的是 3 个分区; 那是因为我们配置了这个 topic 的分区数num.partitions=3; 和备份数offsets.topic.replication.factor=3; 这 3 个文件夹中的 3 个分区有Leader有Fllower; 那么我们怎么知道谁是谁的 Leader 呢?
2 查看 topic 的分区和副本

可以看到查询出来显示分区 Partition-0在broker.id=0中,其余的是副本Replicas 2,1 分区 Partition-1在broker.id=1中,其余的是副本Replicas 0,2...
或者也可以通过 zk 来 查看leader在哪个 broker 上
3 分区文件都有啥
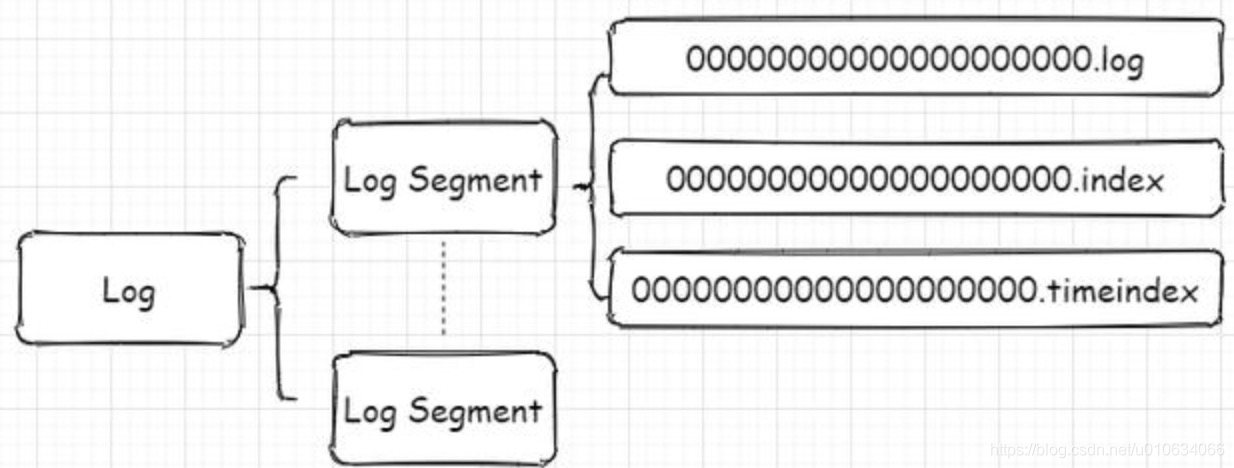
进入文件夹看到如下文件:

在这里插入图片描述
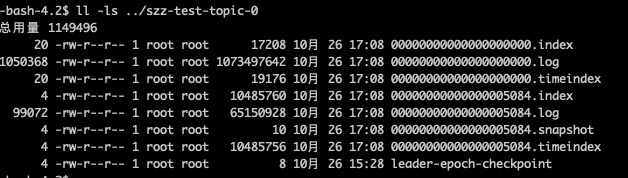
我们试试多发送一些消息,看它会不会生成新的 segment
在这里插入图片描述
从图中可以看到第一个 segment 文件00000000000000000000.log快要满log.segment.bytes的时候就开始创建了00000000000000005084.log了;并且.log和.index、.timeindex文件是一起出现的; 并且名称是以文件第一个 offset 命名的
.log 存储消息文件
.index 存储消息的索引
.timeIndex,时间索引文件,通过时间戳做索引
消息文件
上面的几个文件我们来使用 kafka 自带工具bin/kafka-run-class.sh 来读取一下都是些啥bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log

最后一行:
.index 消息索引
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index
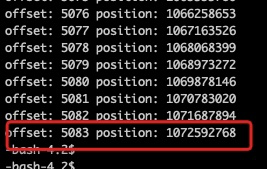
最后一行:
.timeindex 时间索引文件
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.timeindex

最后一行:
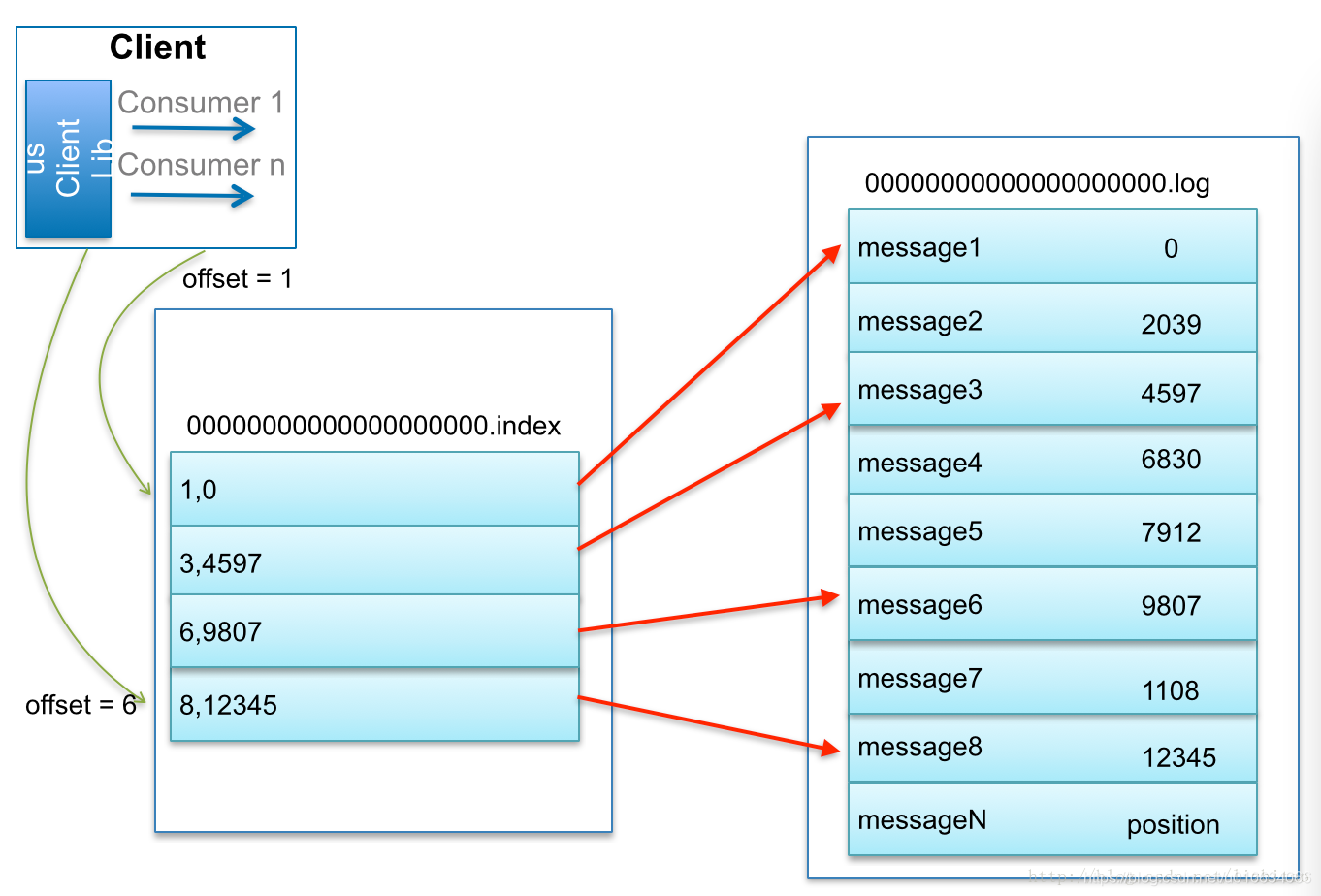
Kafka 如何查找指定 offset 的 Message 的
找了个博主的图 @lizhitao

比如:要查找绝对 offset 为 7 的 Message:
首先是用二分查找确定它是在哪个 LogSegment 中,自然是在第一个 Segment 中。
打开这个 Segment 的 index 文件,也是用二分查找找到 offset 小于或者等于指定 offset 的索引条目中最大的那个 offset。自然 offset 为 6 的那个索引是我们要找的,通过索引文件我们知道 offset 为 6 的 Message 在数据文件中的位置为 9807。
打开数据文件,从位置为 9807 的那个地方开始顺序扫描直到找到 offset 为 7 的那条 Message。
Kafka 中的索引文件,以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB)的消息时,偏移量索引文件 和 时间戳索引文件 分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。
稀疏索引通过 MappedByteBuffer 将索引文件映射到内存中,以加快索引的查询速度。
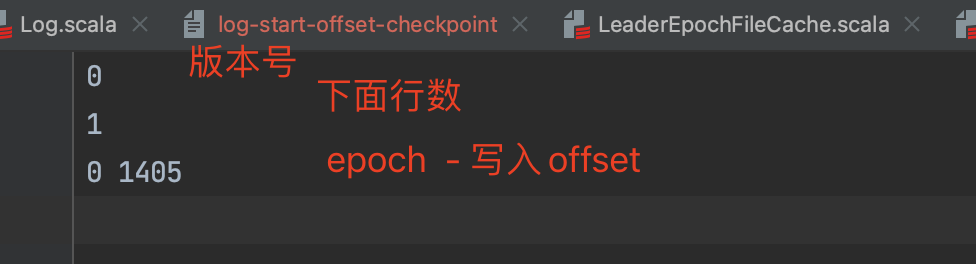
leader-epoch-checkpoint
leader-epoch-checkpoint 中保存了每一任 leader 开始写入消息时的 offset; 会定时更新 follower 被选为 leader 时会根据这个确定哪些消息可用
4 参考文档
Kafka-工作流程,文件存储机制,索引机制,如何通过offset找到对应的消息
版权声明: 本文为 InfoQ 作者【石臻臻的杂货铺】的原创文章。
原文链接:【http://xie.infoq.cn/article/04676e73359e882dfa96ec461】。未经作者许可,禁止转载。

关注公众号: 石臻臻的杂货铺 获取最新文章 2019-09-06 加入
进高质量滴滴技术交流群,只交流技术不闲聊 加 szzdzhp001 进群 20w字《Kafka运维与实战宝典》PDF下载请关注公众号:石臻臻的杂货铺









评论