
浅析 python 一切皆对象

变量的迷惑
如果你有其它类 C 语言的使用经历(c,java,c++,Go等),那么一提到变量,我们会将变量想象成一个box,它代表了计算机中的一块内存,是一个可以存放值的容器:

如上图所示,声明初始化一个a=1,就相当于在内存中开辟了一块空间用于存放值1,使用变量名a就可以改变内存中的值a=2。 当把a赋给一个新的变量b的时候,会在内存中为b重新开辟一块空间,并把a的一个副本存入其中。也就是说变量与变量之间完全独立,抱有这种认识的人大多会对 python 中的变量产生很大的误解,不信我们试看下面的代码片段:
上面的代码段初始化了一个变量a并将其赋值为 9527,之后又把a赋给了变量b,打印他们的值都为 9527,到现在 python 中的变量表现和其它语言没什么不同(表面上看起来)。但我们接着打印了这两个变量的地址,你会惊奇的发现,他们竟然相同。使用is来判断,b就是a,也就是说此时在内存中只有一块空间来存放9527这个值。现在我们试着改变一下a的值:
我们赋予a一个新的值1024,然后打印了他们的值,python 的表现仍然跟我们“预期”的一样:a 的值改变了,b 的值没有。,但是在我们打印了他们的内存地址之后,一切看起来并没那么简单。
a和b的地址最初都是140232581997552,当a重新赋值之后,b的地址没有改变,而a的地址却变成了140232581997456。也就是说,python 的解释器重新开辟了一块内存给了a,这完全颠覆了我们印象中基于box和store对变量的理解。虽然目前看起来还算工作正常,但是我准备再对示例代码做一些改动:
这一次我们使用了list,一切看起来和刚才一样,a和b指向同一块内存,现在我们试着改变list中的元素
你认为上段代码的输出会是什么? b中元素的值也会改变么?
没错,这就是 python 让你惊讶的地方之一,这一次的表现不仅和你的预期不同,甚至和它上一次的表现也不相同。
第一次我们使用的是number,它在 python 中是一个不可变对象,python 中的变量其实是内存对象的一个标签,赋值仅仅是一个绑定的动作,画一个形象的图来表示:
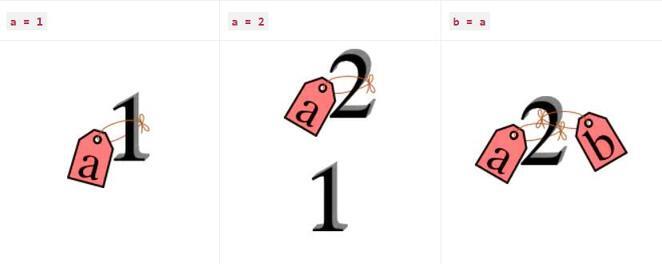
当我们使用list时表现又不同,这是因为list在 python 中是一个可变对象。在 python 中一切皆对象,这种特殊的数据模型是造成我们误解的根本原因,接下来我们重点讨论一下 python 中的对象。
一切皆对象
Objects are Python’s abstraction for data. All data in a Python program is represented by objects or by relations between objects. (In a sense, and in conformance to Von Neumann’s model of a “stored program computer”, code is also represented by objects.)Every object has an identity, a type and a value. An object’s identity never changes once it has been created; you may think of it as the object’s address in memory. The ‘is’ operator compares the identity of two objects; the id() function returns an integer representing its identity.
以上是 python 官网文档中的描述,翻译一下:Python 中对象是所有数据的抽象。所有 Python 程序中的值都由对象或者对象之间的关系表示。Python 中每个对象有一个唯一标识 identity,一个对象的标识在对象被创建后不再改变。可以认为对象的 identity 是对象在内存中的地址,其值可以由内置函数 id()求得。is 操作符可以比较两个对象的 identity 是否相同,即两个对象是否是同一个。
对于 python 中的变量赋值操作,有两种类比说法。一个是 “boxes vs. label” ,另一个是“names and bindings” 。我们采用“names and bindings” 这种说法,在 python 里一切都是对象,如 interger、string、list、dict、set、function 等。当我们赋值给一个变量的时候,我们仅仅把变量当成一个名字(name):
<name> = <object>
我们实际上是将一个对象和一个名称绑定,需要注意的是一个对象可以被多个名称绑定,这是最司空见惯的情况,也是最容易引起歧义的地方:
这段代码就展示了一个对象被多个名称绑定的情况,number 9527和字符串bohu是一个数值对象和一个字符串对象,并分别被两个变量绑定。
现在我们使用list来代替number和string:
这个例子中,我们看到a和b指向了不同的内存空间,python 的表现之所以有所不同是因为string和number是immutable对象,而list是mutable的对象,关于 python 中对象的mutability见下表:
可见除了list,set,dict之外其余都是不可变的,一个immutable的对象被创建之后是不可以改变的。如果你试图通过与之绑定的变量去修改这个对象时,python 会创建一个新的实例对象并与原来的变量绑定,之前的对象则伺机被回收。相反,一个mutable的对象是可以被原地改变的,比如之前的例子:
除非重新赋值,否则a和b绑定的对象的内存地址是不会改变的。当你使用b = a时,你并没有成功的copy一个list,你只是把两个name绑定到了同一个list对象之上。因此,正确的理解 python 的对象模型会帮助你正确的调试你的程序。
要理解 python 中的变量,我们就不能把变量当成一个盛放值的盒子,我们要把 python 中的变量当做贴在盒子上的标签。我们可以在同一个盒子上贴多个标签,例如:
当我们执行a = "super hero powers"时,我们说:创建了等号右边的对象,并且把名称 a 绑定到这个对象上。当我们执行a = b时,我们说:把 a 绑定到 b 绑定的对象上。
由此可见,在 python 中:
变量的赋值,只是表示让变量指向了某个对象,并不表示拷贝对象给变量;而一个对象,可以被多个变量所指向。
可变对象(列表,字典,集合等等)的改变,会影响所有指向该对象的变量。
对于不可变对象(字符串、整型、元组等等),所有指向该对象的变量的值总是一样的,也不会改变。但是通过某些操作(+= 等等)更新不可变对象的值时,会返回一个新的对象。
变量可以被删除,但是对象无法被删除。
函数调用,传值还是传引用?
先来看官方的一段描述:
Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per se.
参数的传递是通过赋值进行传递(passed by assignment)。也就是说,参数传递时,只是让新变量与原变量指向相同的对象而已,并不存在值传递或是引用传递一说。
这里的参数传递,使变量 a 和 b 同时指向了 1 这个对象。但当我们执行到 b = 2 时,系统会重新创建一个值为 2 的新对象,并让 b 指向它;而 a 仍然指向 1 这个对象。所以,a 的值不变,仍然为 1。
那么对于上述例子的情况,是不是就没有办法改变 a 的值了呢?答案当然是否定的,我们只需稍作改变,让函数返回新变量,赋给 a。这样,a 就指向了一个新的值为 2 的对象,a 的值也因此变为 2。
当你想获取改变后的值的时候,最好的选择就是返回一个元组来包含多个结果:
当传入的参数是一个mutable的对象时,改变对象的值,就会影响所有指向它的变量,因此,我们可以利用这一点达到传引用的效果:
但我们要注意的是,改变变量和重新赋值的区别:
为什么 l1 仍然是[1, 2, 3],而不是[1, 2, 3, 4]呢?
要注意,这里 l2 = l2 + [4],表示创建了一个“末尾加入元素 4“的新列表,并让 l2 指向这个新的对象。这个过程与 l1 无关,因此 l1 的值不变。当然,同样的,如果要改变 l1 的值,我们就得让上述函数返回一个新列表,再赋予 l1 即可:
浅拷贝与深拷贝
当我们说深拷贝和浅拷贝时,一般都是针对于集合类型来讲的,如 python 中的list、tuple、set、dict等。其它语言中的struct类型也会涉及到深浅拷贝之说,通常是指这些集合类型或者结构体中有其它集合的引用。
浅拷贝(shallow copy)
浅拷贝会创建新对象,是指重新分配一块内存,创建一个新的对象,里面的元素是原对象中子对象的引用。注意,其内容非原对象本身的引用,而是原对象内第一层对象的引用。浅拷贝有三种形式:
类型构造器
这里,l2 就是 l1 的浅拷贝,s2 是 s1 的浅拷贝。当然,对于可变的序列,我们还可以通过切片操作符':'完成浅拷贝。
切片操作
copy 模块中的 copy 函数
因为浅拷贝只是创建一个新对象,集合中的元素内容仍然是原对象中子对象的引用,我们用以上三种方式中的任意一种来观察一下(因为他们都是浅拷贝,结果都是相同的):
这里l1和l2是两个不同的对象,而l1[2]和l2[2]是两个变量名称,通过id()可以看到他们两个绑定到了相同的对象之上:
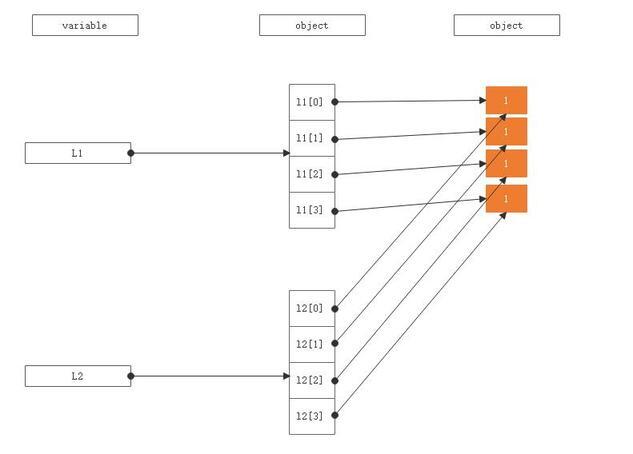
这是没有可变对象的情况下的拷贝,当有可变对象时,也就是说当对象元素中有list、set、dict等集合对象时,浅拷贝只是做一个引用绑定,并不会创建新的可变对象:
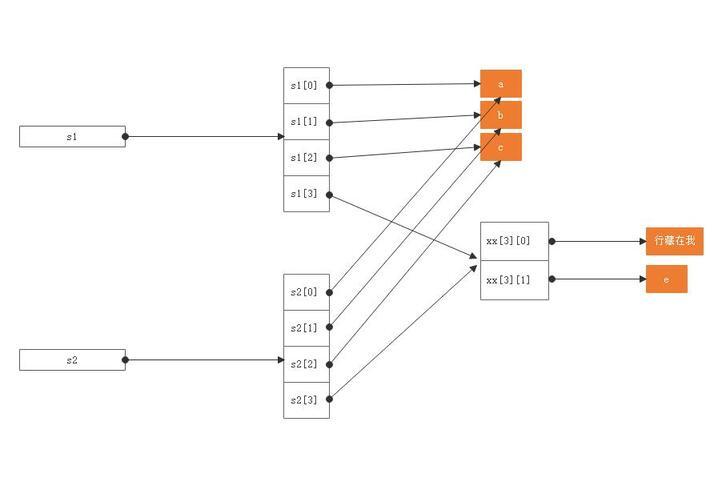
上面的代码片段增加了深拷贝的例子,关于深拷贝我们一会儿再说,这里只看s1和s2,其中s1是包含列表的列表,经过浅拷贝之后我们发现:s1[3]和s2[3]指向同样的对象。可以说明浅拷贝只是对子列表做了变量绑定,并没有创建新的对象。那么你在修改s1的同时,必然会影响到s2:
用一张图来描述一下此时的内存图景:
深拷贝(deep copy)
深拷贝只有一种形式,copy 模块中的 deepcopy() 函数。深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空间开销要高。
通过上面的浅拷贝示例可知,浅拷贝不会为可变的子对象构建新的对象,这样就会带来修改了新数据之后旧数据也会被修改的副作用。有时候为了避免这种副作用,我们会使用深拷贝。
还是上一节浅拷贝的例子,我们重点来看s3,s3是用深拷贝构建出来的,观察可变子对象的 id 可以发现它是一个新的对象,拥有全新的内存地址,但是其中的不可变对象仍然共享了原来的对象。
我们通过s1[3][0] = "行藏在我"改变了子列表中的内容之后,深拷贝构造出来的s3并未受到影响,因为s1[3][0]改变的是s1[3]指向的对象本身,而s3[3]指向的是另一个不同的对象,此时的内存图景为:
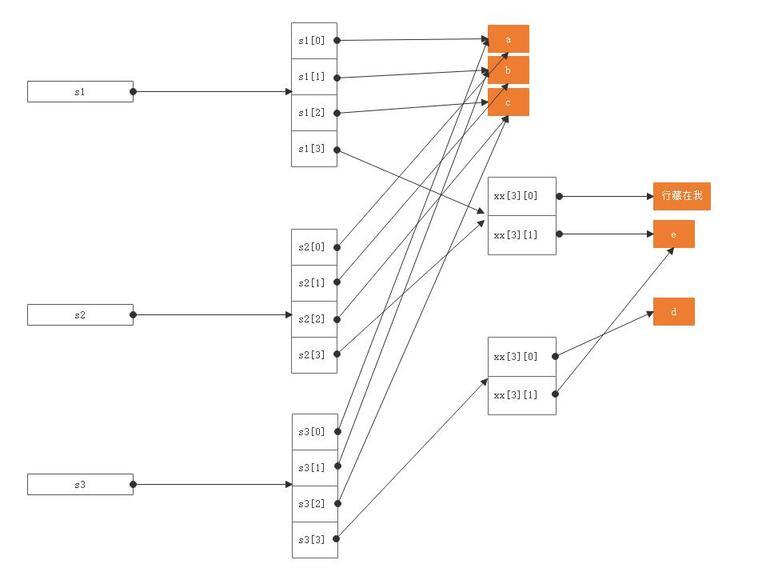
关于元组 copy 时的注意事项:
元组只包含非容器类型时(如数字、字符串、和其他'原子'类型的对象),无论是浅拷贝还是深拷贝返回的都是原元组对象的引用。
元组包含可变对象时(如
list、set、dict等),浅拷贝依然返回引用,深拷贝则会创建一个新的对象和子对象。
再论元组
元组是
immutable的,却有潜在的被更改的可能性
元组本身是不可变的,但是它包含的值却有可能被更改,特别是当元组hold住一个mutable的对象时,例如list。
有了之前把变量名称当做一个对象的标签的论述,我们这里举起例子来就容易多了:
我们创建了 2 个 tuple 对象,dum和t_doom是第一个对象的标签,dee是第二个对象的标签。
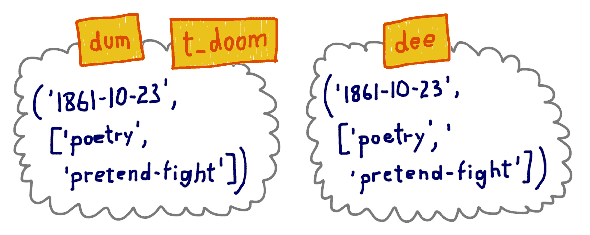
现在我们为t_doom增加技能:
dum和t_doom都获得了rap技能,原因是他们绑定的是同一个对象, t_doom[1] 和 skills也绑定到了同一个list对象上面:
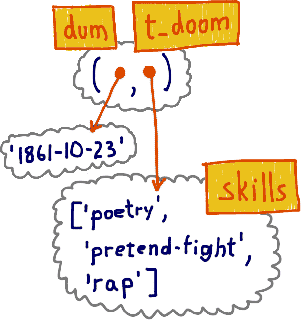
那么我们为什么说此时元组仍是不可变的呢?其实不可变值得是元组的物理内容,元组里包含的是什么?是对于各种对象的引用,dum[1]引用的list对象的值改变了,但被引用的对象本身的id并没有变。所以,元组中的可变对象可能会有改动,但是可变对象本身却总保持不变。
参考文章:
Everything Is an Object in Python — Learn to Use Functions as Objects
Python: Everything is an Object, and Some Objects are Mutable
版权声明: 本文为 InfoQ 作者【计算机漫游】的原创文章。
原文链接:【http://xie.infoq.cn/article/0343a60cd5d0c7e0dd081703f】。文章转载请联系作者。

感而后应,迫而后动,不得已而后起 2018-11-20 加入
非著名程序员,任职过测试,前端,devops,DBA、Go 后端开发等等 个人网站: https://liupzmin.com 联系方式: liupzmin@gmail.com









评论