
Redis 是什么?架构是怎么样的?
你是一个程序员,你维护了一个 商品服务,它背后直连 mysql 数据库。假设商品服务需要对外提供 每秒 1w 次查询,但背后的 mysql 却只能提供每秒 5k 次查询,那 mysql 根本顶不住!分分钟会被压垮。
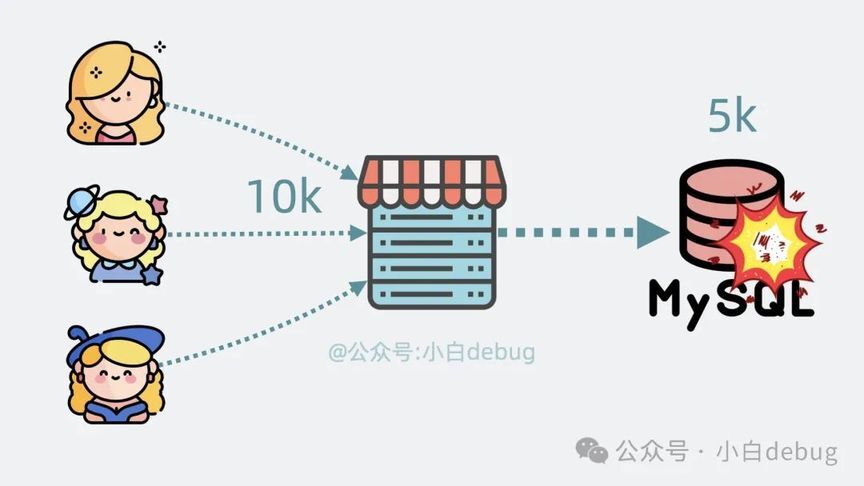
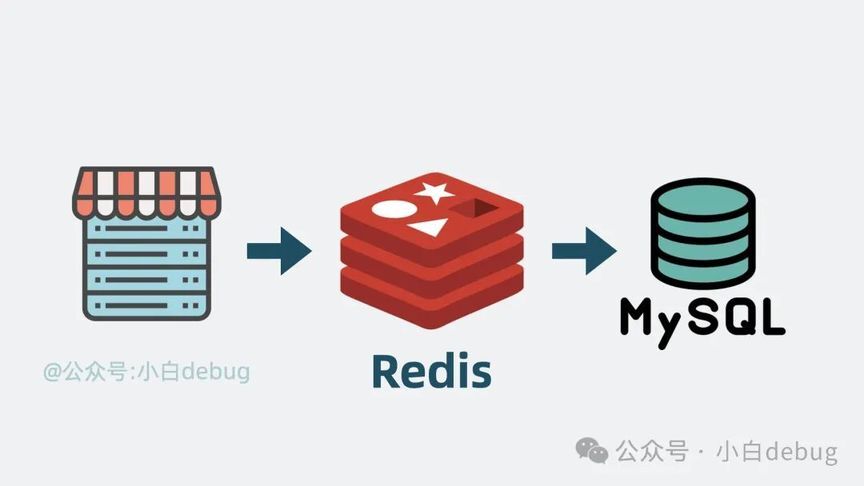
这类大流量查询场景非常常见,比如双十一秒杀和春节抢车票。那么问题就来了,有没有办法在 mysql 不被压垮的同时,让商品服务支持每秒 1w 次查询 ?当然有,没有什么是加一层中间层不能解决的,如果有,那就再加一层。这次我们要加的中间层是 Redis。
本地缓存
我们知道,查询内存的速度比查询磁盘要快, mysql 数据主要存放在磁盘里,如果能将 mysql 里的数据放内存里,查询完全不走磁盘,那必然能大大提升查询性能。
我们很容易想到,可以在商品服务的内存中,申请一个字典,在 python 里叫 dict,在 java 里叫 map。
key 是商品 ID,value 是商品数据。通过商品 ID, 就能查到商品数据。
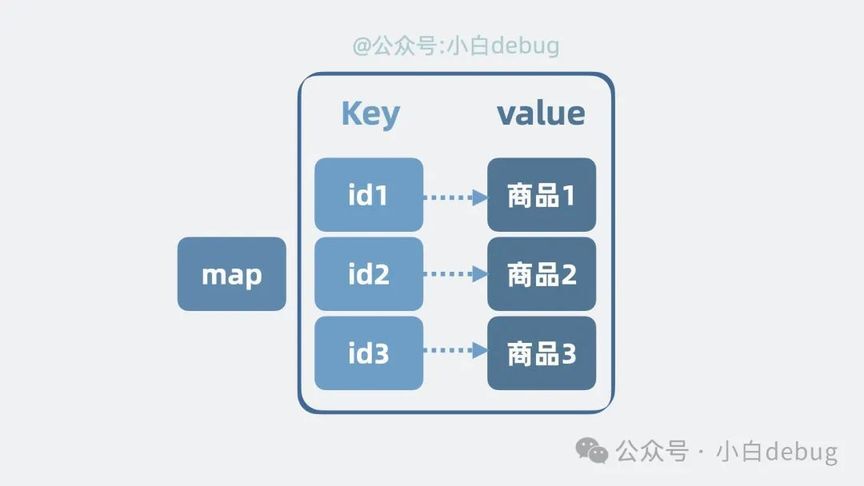
发生查询时,优先去查内存字典,没结果再跑到 mysql 数据库里查询,再将结果顺手放内存字典里,下次就又能从内存里查出来啦。
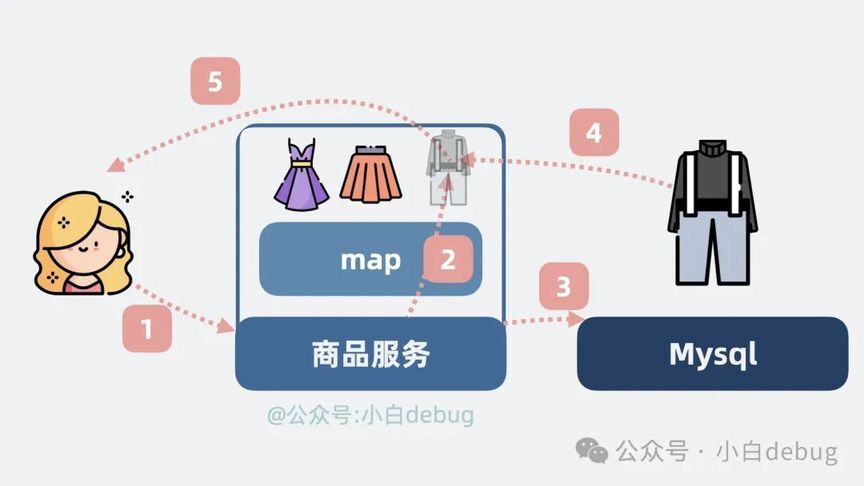
像这样,放在服务内部的缓存,就是所谓的本地缓存。有了本地缓存的加持,真正打到 mysql 的查询量就跟你喜欢的女生回你的消息字数一样少,将查询请求干到 1w qps 是很轻松的事情。

远程缓存
但问题又来了,为了保证系统高可用,商品服务经常不止一个实例,如果每个实例都重复缓存一份本地内存,那就有些浪费内存条了。所以更好的解决方案是将这部分字典内存抽出来,单独做成一个服务。它就是所谓的远程缓存服务。
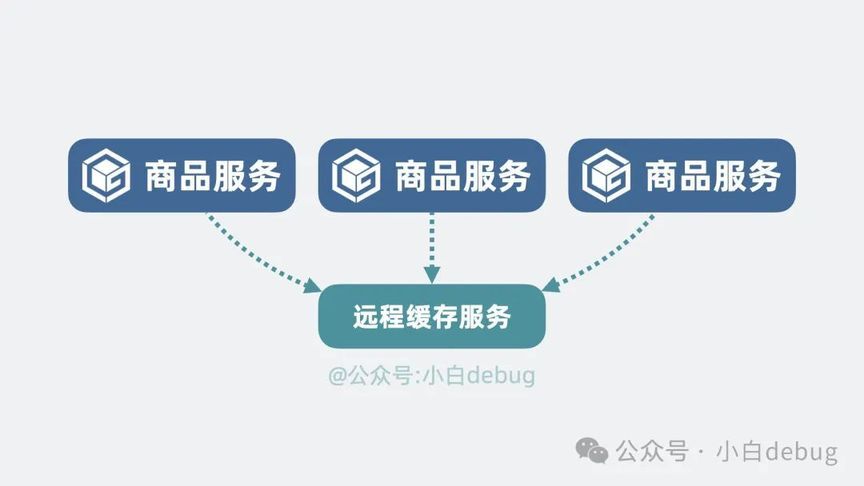
但这就引入另外一个问题,多个商品服务通过网络去读写同一份远程缓存,会存在并发问题。怎么办呢?很简单!对外不管有多少有个网络连接,收到读写命令后,都统一塞到一个线程上,在一个线程上对字典进行读写,什么并发问题和线程切换开销,完全不存在!
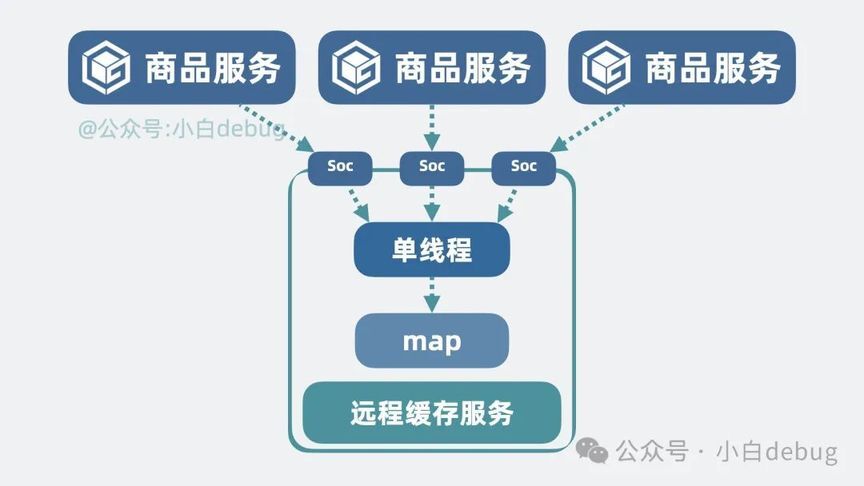
这个远程缓存服务足以满足大部分场景,但它属实过于简陋,我们来看下怎么优化它。
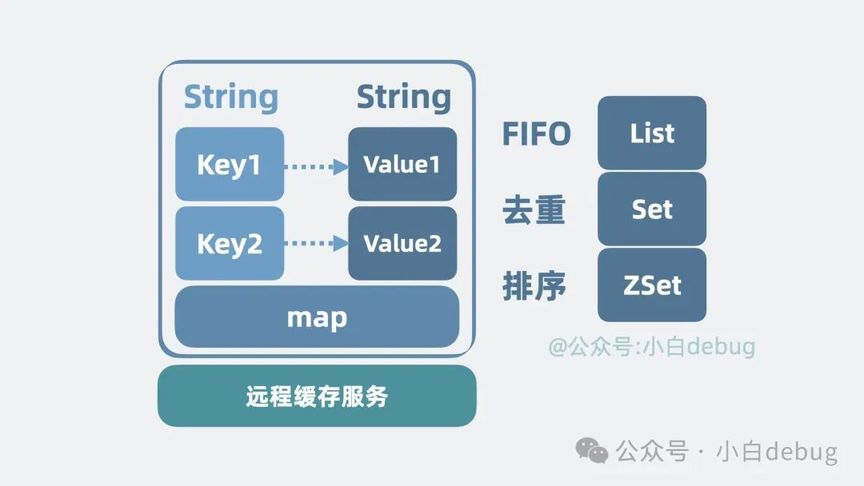
多种数据类型支持
现在缓存服务里,只有一个字典类型。key 和 value 都是字符串。但我们平时写代码的时候,还会用到很多其他内存里的数据结构,是不是也可以在缓存服务里提供类似的数据结构?于是我们对字段的 value 进行扩展,除了 字符串, 还支持先进先出的队列 List 和用于去重的 Set 类型,再加入可以做排行榜的 ZSet,现在缓存服务就更强了。
内存过期策略
缓存服务支持的数据结构变多了之后,塞到内存里的数据就越来越多了,内存又小又贵,迟早扛不住。怎么办呢?我们可以给缓存里的数据加个过期时间,一旦数据过期,就从内存里删掉,可以很大程度缓解掉内存增长速度。但问题又又来了,我怎么知道哪些数据该设置多长过期时间呢?完全没办法,只能交给调用方去做判断,让用户通过 expire 命令的形式来指定哪些数据多久过期。
缓存淘汰
但你不能指望每个调用方都是老实人,如果都不设置过期时间,那内存还是得炸。有解法吗?有!在内存接近上限的时候,根据一些策略删除掉一些内存。比如可以将最近最少使用的内存删掉,也就是所谓的 LRU,这样不仅解决了内存过大的问题,还让 redis 里的数据全是热点数据。真是一箭双雕。

持久化
现在内存过大的问题是解决了。但还有个问题,mysql 之所以过得那么舒服,那是因为前面有个缓存服务挡住了大部分流量。一旦缓存服务重启,那内存就全丢了,这时候流量会全都打到 mysql 身上,疼得它嗷嗷叫。

所以我们还需要给 redis 加入最大程度的持久化保证。确保服务重启后不至于什么数据都没有。于是可以在缓存服务里加个异步线程,定期将全量内存数据定期持久化到磁盘文件里,而这种将内存数据生成快照保存到文件的方式,就是所谓的 RDB,Redis Database Backup。
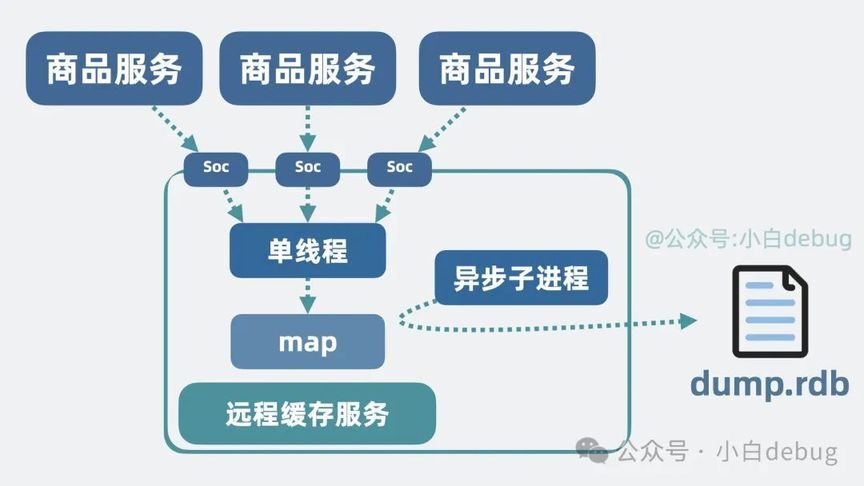
它可以每隔几分钟记录下缓存服务 的全量数据,类似于游戏的"存档"。这样就算进程挂了,重启的时候,通过加载快照文件,就能复原大部分数据。之所以说是大部分,是因为"存档"之后写入的数据可能会丢。那还有其他方式可以保留更多数据吗?有!全量数据备份当然耗时,那我们化整为零,在每次写入数据时,顺手将数据记录到文件缓存中,并每秒将文件缓存刷入磁盘,这种持久化机制叫 AOF,Append Only File,服务启动时跟着文件重新执行一遍就能将大部分数据还原,最大程度保证了数据持久化。
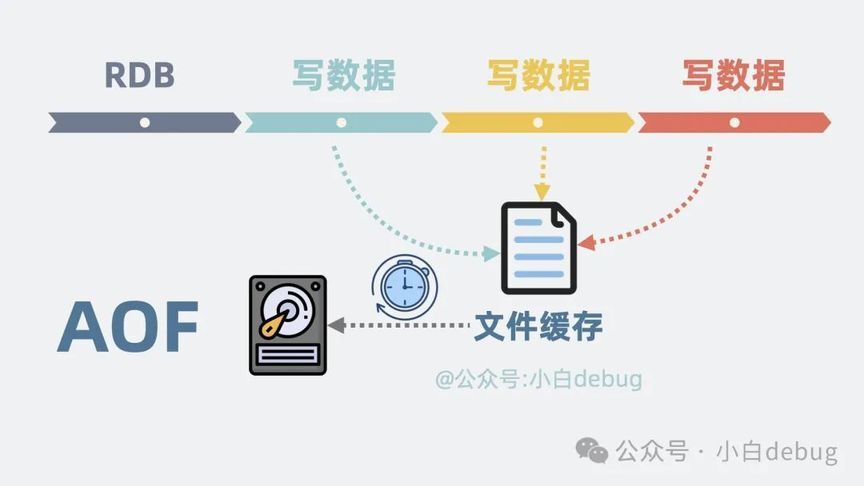
那问题就来了,AOF 文件会不会很大?没事,定期重写压缩就行,比如 a 被依次赋值 a=1,a=2,最终保留 a=2 就够了。
简化网络协议
刚刚提到远程缓存服务对外提供读写能力,那是对外提供的 HTTP 接口吗?当然不是!我们知道, HTTP 是基于 TCP 做的通信,实现了很多笨重的特性。既然当初是为了性能,特地上的缓存服务,那就索性彻底点,抛弃 HTTP,直接基于 TCP 做传输就好!传输协议也设计得简单点,比如只要通过 TCP 传入 SET key value,就能完成写入。传入"GET key" 就能获得对应的 value。非常简洁。那传输协议的解析需要我们自己写代码去实现吗?完全不需要,redis 官方提供了一个命令行工具,redis-cli,通过它,我们可以输入一些命令,读写 Redis 服务器里的各种内存数据。
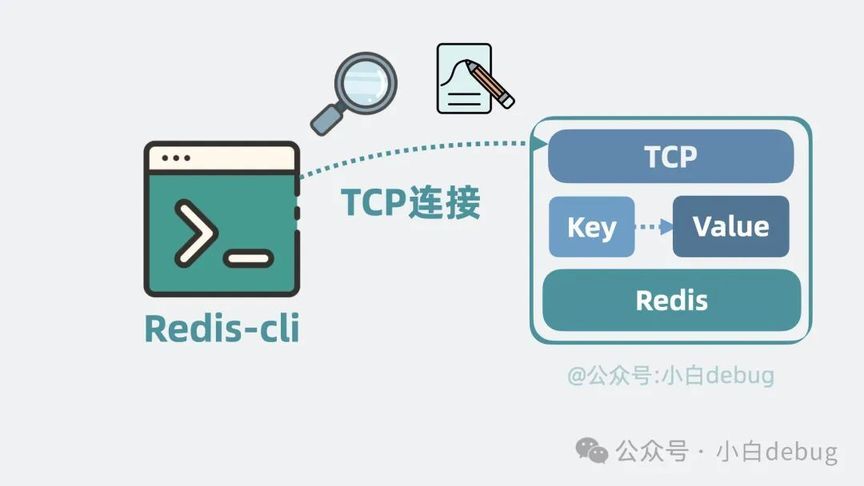
不想用命令行也没关系,各路大神已经用各种语言将 redis-cli 支持的命令实现了一遍,完全不需要自己手写。
Redis 是什么?
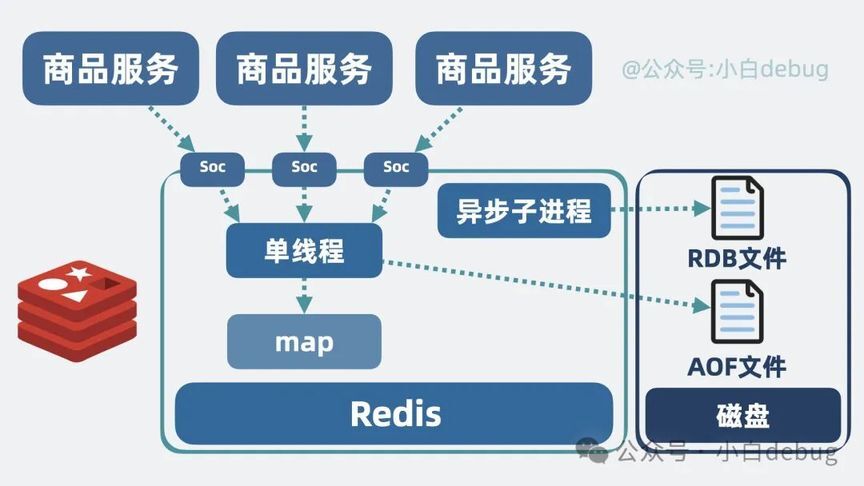
好了,到这里,当初那个简陋的远程缓存服务,就成了一个高性能,支持多种数据类型和各种缓存淘汰策略,并提供一定持久化能力的超强缓存服务,没错,它就是我们常说的 Redis,全称 Remote Dictionary Server,这名字就很精辟了,说白了 redis 就是个远程的字典服务。
redis 作为架构中最常用的提速神器,是万金油一般的存在,将它放在 mysql 面前挡一道查询只是最基础的用法。通过扩展插件,还能实现各种高阶玩法。比如 RedisJSON 支持复杂的 JSON 查询和更新,说白了就是内存版本的 MongoDB。RediSearch 支持全文搜索,说白了就是内存丐版的 es。RedisGraph 支持图数据库功能,类似 Neo4j,RedisTimeSeries 处理时间序列数据,也就是内存版 InfluxDB。大有一种要在内存里将所有中间件都实现一遍的味道。
现在大家通了吗?
总结
• redis 本质上就是个远程字典服务,所有读写命令等核心逻辑,都在一个线程上完成。什么并发问题和线程切换开销,完全不存在!
• redis 支持多种数据类型、内存过期策略和多种缓存失效策略,通过 TCP 对外提供了一套非常简单的传输协议。
• redis 加入了最大程度的持久化保证。将数据持久化为 rdb 和 AOF,确保服务重启后不至于什么数据都没有。
• redis 支持多种扩展,玩法非常多,比如 RediSearch 和 RedisJSON。
最后遗留一个问题,redis 到目前为止就是个单机服务,高性能是有了,但高可用和可扩展性是一点没看到。这就需要聊聊 主从 、哨兵和集群模式了,如果大家感兴趣,下期我们聊聊这个话题。

还未添加个人签名 2022-04-10 加入
还未添加个人简介












评论