
Python 自动复制 Excel 数据:将各行分别重复指定次数
本文介绍基于 Python 语言,读取 Excel 表格文件数据,并将其中符合我们特定要求的那一行加以复制指定的次数,而不符合要求的那一行则不复制;并将所得结果保存为新的 Excel 表格文件的方法。
这里需要说明,在我们之前的文章多次复制Excel符合要求的数据行:Python批量实现中,也介绍过实现类似需求的另一种 Python 代码,大家如果有需要可以查看上述文章;而上述文章中的代码,由于用到了DataFrame.append()这一个在最新版本pandas库中取消的方法,因此有的时候可能会出现报错的情况;且本文中的需求较之上述文章有进一步的提升,因此大家主要参考本文即可。
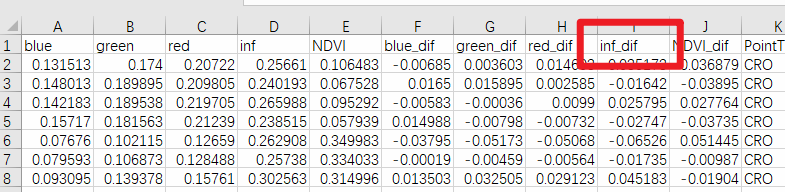
首先,我们来明确一下本文的具体需求。现有一个 Excel 表格文件,在本文中我们就以.csv格式的文件为例;其中,如下图所示,这一文件中有一列(也就是inf_dif这一列)数据比较关键,我们希望对这一列数据加以处理——对于每一行,如果这一行的这一列数据的值在指定的范围内,那么就将这一行复制指定的次数(复制的意思相当于就是,新生成一个和当前行一摸一样数据的新行);而对于符合我们要求的行,其具体要复制的次数也不是固定的,也要根据这一行的这一列数据的值来判断——比如如果这个数据在某一个值域内,那么这一行就复制10次;而如果在另一个值域内,这一行就复制50次等。
知道了需求,我们就可以开始代码的书写。其中,本文用到的具体代码如下所示。
其中,上述代码的具体含义如下。
首先,我们需要导入所需的库,包括numpy、pandas和matplotlib.pyplot等,用于后续的数据处理和绘图操作。接下来,即可开始读取原始数据,我们使用pd.read_csv()函数读取文件,并将其存储在一个 DataFrame 对象df中;这里的原始文件路径由original_file_path变量指定。
随后,我们开始设置重复次数。在这里,我们根据特定的条件,为每个值设定重复的次数。根据inf_dif列的值,将相应的重复次数存储在num列表中。根据不同的条件,使用条件表达式(if-else 语句)分别设定了不同的重复次数。
接下来,我们使用loc函数和np.repeat()函数,将数据按照重复次数复制,并将结果存储在duplicated_df中。
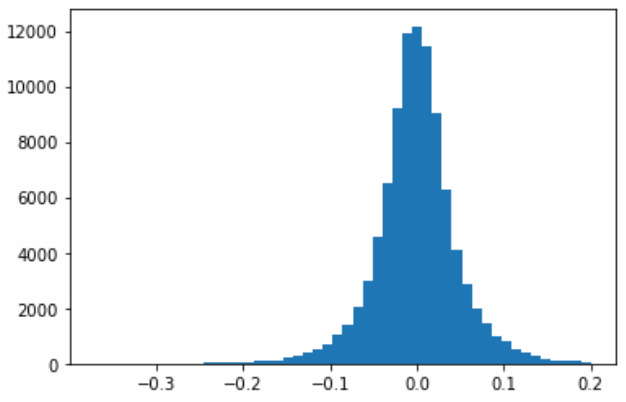
最后,为了对比我们数据重复的效果,可以绘制直方图。在这里,我们使用matplotlib.pyplot库中的hist()函数绘制了两个直方图;其中,第一个直方图是原始数据集df中inf_dif列的直方图,第二个直方图是复制后的数据集duplicated_df中inf_dif列的直方图。通过指定bins参数,将数据分成50个区间。
完成上述操作后,我们即可保存数据。将复制后的数据集duplicated_df保存为.csv格式文件,路径由result_file_path变量指定。
执行上述代码,我们将获得如下所示的两个直方图;其中,第一个直方图是原始数据集df中inf_dif列的直方图,也就是还未进行数据复制的直方图。
其次,第二个直方图是复制后的数据集duplicated_df中inf_dif列的直方图。
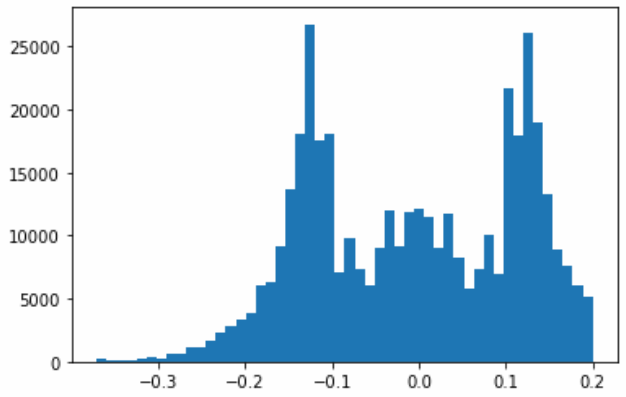
可以看到,经过前述代码的处理,我们原始的数据分布情况已经有了很明显的改变。
至此,大功告成。
文章转载自:疯狂学习GIS

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论