一、技术原理
1.1 背景
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
举个例子,在微服务系统中,一个来自用户的请求,请求先达到前端 A(如前端界面),然后通过远程调用,达到系统的中间件 B、C(如负载均衡、网关等),最后达到后端服务 D、E,后端经过一系列的业务逻辑计算最后将数据返回给用户。对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
Google 开源的 Dapper 链路追踪组件,并在 2010 年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
中文翻译参考:http://bigbully.github.io/Dapper-translation/
目前,链路追踪组件有 Google 的 Dapper,Twitter 的 Zipkin,以及阿里的 Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
1.2 名词术语
微服务链路追踪系统实现时,需设置一些关键节点记录信息,链路追踪相关名词如下:
Span:基本工作单元,发送一个远程调度任务 就会产生一个 Span,Span 是一个 64 位 ID 唯一标识的,Trace 是用另一个 64 位 ID 唯一标识的,Span 还有其他数据信息,比如摘要、时间戳事件、Span 的 ID、以及进度 ID。
Trace:一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口,这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span,所有由这个请求产生的 Span 组成了这个 Trace。
Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
cs - Client Sent -客户端发送一个请求,这个注解描述了这个 Span 的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其 sr 减去 cs 时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果 ss 的时间戳减去 sr 时间戳,就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)-此时 Span 的结束,如果 cr 的时间戳减去 cs 时间戳便可以得到整个请求所消耗的时间。
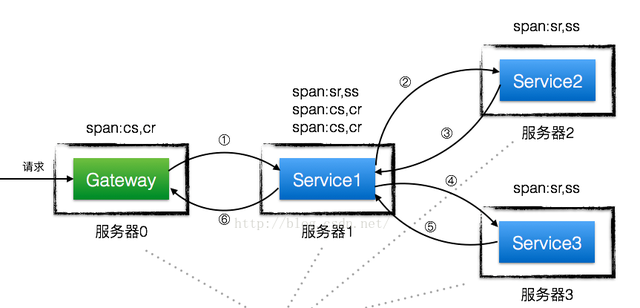
1.3 调用链分析
一个服务调用过程如下图所示:
二、技术实现
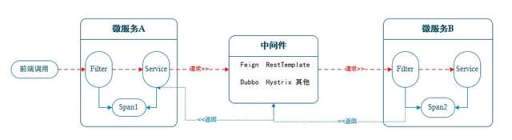
调用方每一次向系统服务发起请求时,会生成这一次调用产生的相关调用链日志,生成一个全局的 traceId,生成不同节点的 span 信息。其中当首个服务生成全局编码后,放入到 header 中,基于 http 传递给下级服务(其他模式类似)。下级服务可通过设置 Filter 过滤器(其他方案也可以),接收链路日志编码,并记录调用的日志信息。在将全局编码继续传递给下级服务。最终本次业务调用完成后,记录调用日志并清空本次调用链产生的全局编码。简易流程如下图所示:
2.1 单服务流程说明
调用方请求服务 A,进入服务 A 过滤器;
服务 A 过滤器判断请求的 header 中是否携带了 TraceId,ParentSpanId,有则使用携带的,没有就自动生成。
过滤器前置部分记录初始请求的一些信息,如请求地址,参数,请求时间等;
过滤器转发请求进入到 Service 方法;
过滤器后置部分再次记录 Service 方法执行完成后的一些信息,如返回内容,结束时间;
过滤器前后分别记录了信息,组合生成调用链路日志;
请求完成后,清空本次产生的 TraceId;
服务 A 调用链日志信息参考:
// trace日志{"message":"trace log","context":{"trace_id":"e0d5c5ba-f497-4407-b8ca-f657a88452fc517513","request_uri":"/customize-trace-A/trace/jdk/async","request_method":"GET","refer_service_name":null,"service_name":"customize-trace-A","refer_service_host":"127.0.0.1","request_time":1608896030.689531,"response_time":1608896030.692276,"time_used":3.479,"service_addr":"192.168.45.42","service_port":8095,"request_id":"9adfcf3c-d606-418f-abc7-6600bff6adf0533098"},"datetime":"2020-12-25 19:33:50.690014"} // span节点{"trace_id":"e0d5c5ba-f497-4407-b8ca-f657a88452fc517513","request_id":"9adfcf3c-d606-418f-abc7-6600bff6adf0533098","span":{"span_id":"eb12eaf8-df3d-4dd2-923a-685360a4fd79588942","parent_id":null,"duration":3426,"annotations":[{"timestamp":1608896030686322,"action":"sr"},{"timestamp":1608896030689748,"action":"ss"}]} ,"datetime":"2020-12-25 19:34:50.690014"}
复制代码
2.2 多服务流程说明
多个服务与单个服务对比,是在不同的微服务里面分别记录对应的 Trace 信息,Span 信息。同一个调用请求,所有微服务记录的 TraceId 一致,父服务的 SpanId 为子服务的 ParentSpanId。
举例两个服务间的调用流程如下:
调用方发起调用,请求服务 A,进入服务 A 过滤器;
服务 A 过滤器判断请求的 header 中是否携带了 TraceId,ParentSpanId,有则使用携带的,没有就自动生成;
服务 A 过滤器前置部分记录初始请求的一些信息,如请求地址,参数,请求时间等;
服务 A 过滤器转发请求进入到 Service 方法;
服务 A 的 Service 方法内部执行部分逻辑后,开始通过中间件调用服务 B;
将服务 A 中已生成的 TraceId,ParentSpanId 信息,通过 header 设置参数(其他类似)的模式传递给服务 B;
进入服务 B 过滤器,服务 B 过滤器获取 header 中传递过来的 TraceId,ParentSpanId;
服务 B 过滤器前置部分记录初始请求的一些信息,如请求地址,参数,请求时间等
服务 B 过滤器转发请求进入到 Service 方法;
服务 B 过滤器后置部分再次记录 Service 方法执行完成后的一些信息,如返回内容,结束时间;
服务 B 过滤器前后分别记录了信息,组合生成调用链路日志;
服务 B 基于中间件返回调用的请求信息处理结果给服务 A;
服务 A 清空本次接收到的 TraceId 等编码信息。
服务 A 过滤器后置部分再次记录 Service 方法执行完成后的一些信息,如返回内容,结束时间;
服务 A 过滤器前后分别记录了信息,组合生成调用链路日志;
服务 A 清空本次请求产生的 TraceId。
2.3 中间件记录 Span 信息
中间件是否需要记录 Span 信息
上述举例并未记录服务的 Service 方法执行一段时间后,何时通过中间件发起调用其他服务的 Span 信息。现实业务中,服务调用经常存在这种情况,服务 A 中某一个方法,先调用了服务 B,获取到服务 B 的返回结果后,后续还又调用了服务 C,服务 D。此刻若不记录中间件的 Span 信息,在分析部分调用链超时情况时,会难以定位分析。只能获取到接受方的接收时间,不知道某一个服务调用时具体的发起时间(如服务 D 最终接收请求时的时间与最初进入服务 A 记录的请求时间相差一分钟,但这并不能说服务 A 调用服务 D 的接口就耗时一分钟)。
因此,中间件模块记录 Span 信息也至关重要。比如一个 http 请求的中间件,可重写他的 Client 实现类,记录开始发起请求和请求完成(类似于 Filter)这一段时间的 Span 信息。
2.4 TraceId 的管理
为什么每次服务调用完成后,需要清空 traceId?
多个请求同时发起时,如何保证调用链日志在不同线程中隔离,互不影响?
每一个请求过来时,产生一个独立的子线程,在这个子线程内部设置对应的 traceId,可基于 ThreadLocal 存储调用链相关信息,达到子线程信息隔离的目的。
了解调用链信息基本原理后,自定义编码实现一套基于 traceId 的调用链追踪技术方案,需解决如下问题:
全局 traceId 的生成和清空;
traceId 调用链路传递与追踪;
traceId 基于 Filter 接收;
Span 生成与管理;
调用链路日志存储;
三、技术细节分析
3.1 生成调用链相关编码
traceId:全局调用链日志 id 编码,在多个服务调用的一条调用链日志中,为同一个日志编码
spanId:spanId 节点的唯一编码
requestId:本次请求生成的唯一 id 编码,在多个服务调用的一条调用链日志中,为不同的日志编码
每一次发起业务调用完成后,需清空本次产生的编码。同时,不同线程的调用链日志应互不影响。故调用链信息可基于 MDC 技术实现,查看 MDC 的实现原理,本质还是基于 ThreadLocal 实现。本例直接基于 ThreadLocal 实现,部分伪代码如下:
public class LoggerUtil{/*** 生成traceId ,requestId,spanId 类似,设置不同的方法名即可*/static String traceId() {return UUID.randomUUID().toString() + new Random().nextInt(1000000);}} public final class ThreadHolderUtil {/*** 任意类型数据集合*/private static final ThreadLocal<Map<Object, Object>> VALUE_MAP = ThreadLocal.withInitial(HashMap::new);/*** 设置key值** @param key key* @param value 值*/public static void setValue(Object key, Object value) {Optional.ofNullable(VALUE_MAP.get()).ifPresent(valueMap -> valueMap.put(key, value));} /*** 清除指定Key** @param key 指定key*/public static void clearValue(Object key) {Optional.ofNullable(VALUE_MAP.get()).ifPresent(valueMap -> valueMap.remove(key));} /*** 清除整个map*/public static void clearValueMap() {VALUE_MAP.remove();}}
复制代码
获取 traceId:String traceId = LoggerUtil.traceId();
单次调用过程中存储 traceId:ThreadHolderUtil.setValue(TRACD_ID, traceId );
整个调用完成后,清空整个变量:ThreadHolderUtil.clearValueMap();
3.2 调用链编码传递
调用链编码传递主要是一个请求涉及到多个微服务时,一般是从网关(或首个请求的微服务)生成调用链编码后,该编码在不同微服务中的流转过程。本文主要介绍 Feign 和线程池中 traceId 的链路传递
参考文档:基于 TraceId 链路追踪
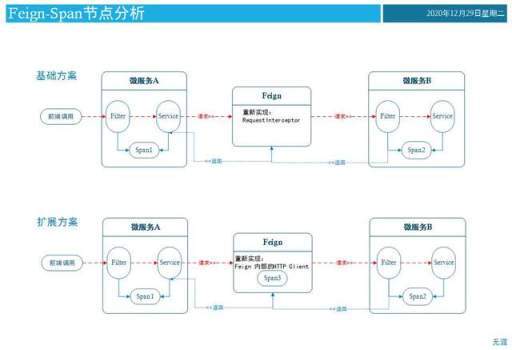
Feign 传递编码-重写 RequestInterceptor
网上介绍方案大多是通过重写实现 RequestInterceptor 接口实现的。参考代码如下:
/*** 调用服务追踪信息feign拦截器**/public class FeignTraceInterceptor implements RequestInterceptor {private static final Logger LOGGER = LoggerUtil.getTraceLogger(); @Overridepublic void apply(RequestTemplate template) {String projectName = LoggerUtil.PROJECT_NAME;if (!StringUtils.isEmpty(projectName)) {template.header(REFER_SERVICE_NAME, projectName);}if (!StringUtils.isEmpty(HOST_IP)) {template.header(REFER_REQUEST_HOST, HOST_IP);}String traceId = TraceUtil.getTraceId();if (StringUtils.isEmpty(traceId)) {traceId = LoggerUtil.traceId();}template.header(GATEWAY_TRACE, traceId);String spanId = TraceContext.parentSpanId();template.header(PARENT_ID_HEADER, spanId);}} @ConditionalOnClass(Feign.class)public static class FeignTraceAutoConfiguration {@Beanpublic FeignTraceInterceptor feignTraceInterceptor() {return new FeignTraceInterceptor();}}
复制代码
该方案是把调用链编码通过 header 传递给下级服务了,但并没有记录 Feign 处的 Span 信息。参考模型如下图所示:
Feign 传递编码-重新实现内部调用的 Http Client
扩展方案是需要记录每一次调用 Feign 时,记录 Feign 处的 Span 信息。Feign 最终可通过在 http 发起请求时,调整内部的 Http Client 扩展实现,达到记录 Span 信息的目的。(整体方案偏复杂,要考虑负载均衡时,池化请求等模式时,都可以记录信息)
Feign 添加自定义注解
目的是为了记录 Feign 在执行方法前后的调用链信息,可采用加入注解,在 Feign 类上面标记,记录方法执行前后时的情况。调用链信息还是通过重写 RequestInterceptor 实现传递给下级服务。
采用 Feign 调用其他服务,记录 Fegin 的 Span 信息,可通过方案:(Feign 传递编码重写 RequestInterceptor, Feign 请求添加注解,组合实现。)
编写一个注解,并记录调用方法前后的时间信息,参考伪代码:
@Aspect@Componentpublic class FeignSpanAspect {@Pointcut("@annotation(com.trace.base.tool.annotation.FeignSpan)")public void pointcut() {}@Around("pointcut()")public void around(ProceedingJoinPoint joinPoint) {try {// 先生成spanIdString spanId = TraceContext.parentSpanId();ThreadHolderUtil.setValue("feign-spanId", spanId);// csAnnotation cs = TraceContext.cs();List<Annotation> annotations = new ArrayList<>(2);annotations.add(cs);// 避免执行超时,所以先设置span cs信息Span span = new Span.Builder().parentId(ThreadHolderUtil.getValue(PARENT_SPAN_ID_KEY, String.class)).spanId(spanId).annotations(annotations).build();List<Span> subSpanList = ThreadHolderUtil.getValue(SUB_SPAN_LIST_KEY, List.class);if (subSpanList != null) {subSpanList.add(span);}joinPoint.proceed();// crAnnotation cr = TraceContext.cr();// 增加crannotations.add(cr);span.setDuration(cr.getTimestamp() - cs.getTimestamp());} catch (Throwable throwable) {throwable.printStackTrace();}}}
复制代码
线程池传递编码
主线程中记录的调用链信息通过线程池执行时,子线程会获取不到主线程的调用链信息(子线程获取 traceId 为 null)。因此,需要在子线程执行时,主线程向子线程传递调用链相关编码信息。
3.3 微服务过滤器接收调用链编码
上游服务向下游服务发起调用请求时,下游服务接收到请求时,加入一个基础过滤器(设置过滤器 order 值小于其他业务的 order 值,保证优先执行),获取上游服务请求信息中的调用链信息,获取出来后,记录请求 Trace 日志信息,并通过 ThreadLocal 模式,记录调用链信息。参考实现部分伪代码如下:
@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {HttpServletRequest servletRequest = (HttpServletRequest) request;String uri = servletRequest.getRequestURI();// 服务健康检查日志不统计,根目录和HEAD请求忽略final String slash = "/";if (Arrays.stream(ignorePath).anyMatch(uri::startsWith) || slash.equals(uri) || HttpMethod.HEAD.name().equalsIgnoreCase(servletRequest.getMethod())) {chain.doFilter(request, response);} else {try {int port = request.getLocalPort();TraceLog traceLog = new TraceLog();traceLog.setRequestTime(getNowUs());//服务名称traceLog.setServiceName(LoggerUtil.PROJECT_NAME);// 开始时间戳(微秒)long start = LocalDateTimeUtil.getCurrentMicroSecond();// traceIdString traceId = servletRequest.getHeader(GATEWAY_TRACE);// 没有就新生成一个if (StringUtils.isEmpty(traceId)) {traceId = LoggerUtil.traceId();}// 尝试获取上游传递的parent_idString parentId = servletRequest.getHeader(TraceContext.PARENT_ID_HEADER);// 首先设置span id,作为后续子span的父span idString spanId = TraceContext.parentSpanId();ThreadHolderUtil.setValue(PARENT_SPAN_ID_KEY, spanId);// 需要提前初始化子span列表,否则父子线程无法持有一个数据引用ThreadHolderUtil.setValue(SUB_SPAN_LIST_KEY, new ArrayList<>()); // srAnnotation sr = TraceContext.sr();String requestId = LoggerUtil.requestId();// 设置trace,用于ResponseBody能够获取Trace trace = new Trace(traceId, requestId);ThreadHolderUtil.setValue(TRACE_KEY, trace); traceLog.setTraceId(traceId);// 远程调用服务名称traceLog.setReferServiceName(servletRequest.getHeader(REFER_SERVICE_NAME));traceLog.setRequestUri(servletRequest.getRequestURI());String method = servletRequest.getMethod();traceLog.setRequestMethod(method);traceLog.setServicePort(port);// 原始response对象chain.doFilter(request, response);// 结束时间戳(微秒)long end = LocalDateTimeUtil.getCurrentMicroSecond();// ssAnnotation ss = TraceContext.ss();// durationlong duration = ss.getTimestamp() - sr.getTimestamp();// span日志SpanLog spanLog = new SpanLog();// 父spanSpan span = new Span.Builder().parentId(parentId).spanId(spanId).duration(duration).annotations(Arrays.asList(sr, ss)).build();spanLog.setTraceId(traceId);spanLog.setRequestId(requestId);spanLog.setSpan(span);List<Span> subSpanList = ThreadHolderUtil.getValue(SUB_SPAN_LIST_KEY, List.class);spanLog.setSubSpans(subSpanList);// todo 存储span信息// todo 存储trace信息} finally {// 最后清除VALUE_MAP// 执行完成后,清空产生的日志信息ThreadHolderUtil.clearValueMap();}}}
复制代码
3.4 Span 生成与管理
通过技术原理分析,生成 Span 的场景为每一个微服务请求开始至请求完成时,记录一个 Span 节点信息。若服务执行过程中,通过中间件调用了其他微服务时,每一次中间件调用时,再记录一个 Span 节点信息(调用多少次,记录多少个)。
3.5 调用链日志存储
发起一次调用后,会生成 Trace 请求信息,Span 节点信息,针对这些日志信息,可以通过写入到 Log4g2 日志中。或者写入到其他数据库等系统中做日志信息存储,便于后续分析问题。
举例一个场景:
发起请求,先调用服务 A,服务 A 通过 Feign 调用一次服务 B,整体记录日志参考如下:
服务 A 对应 traceLog
生成全局 traceId: 2bf002c7-c140-4304-9c42-98ec0e359e1a314225。
服务 A 调用起止时间:1612344583.027557~ 1612344589.716305。
{"message":"trace log","context":{"trace_id":"2bf002c7-c140-4304-9c42-98ec0e359e1a314225","request_uri":"/customize-trace-A/trace/feign/name","request_method":"GET","refer_service_name":null,"service_name":"customize-trace-A","refer_service_host":"127.0.0.1","request_time":1612344583.027557,"response_time":1612344589.716305,"time_used":4774.917,"service_addr":"192.168.45.42","service_port":8095,"request_id":"01d91c6f-1745-414c-a556-06d2e2630995119672"},"level":200,"level_name":"INFO","channel":"REQUEST","datetime":"2021-02-03 17:29:50.405499"}
复制代码
服务 A 对应 spanLog
服务 A 本身具备一个 span 节点信息。且服务 A 的 spanId,为 sub_spans 的 parentSpanId。因为服务 A 通过 Feign 调用了一次服务 B,记录中间件的 Span 信息一次。(调用多少次,记录多少个孩子 span 节点。)
孩子节点的 span 信息,内部的开始请求时间,结束请求时间,小于上级节点的起止时间。
全局 traceId: 2bf002c7-c140-4304-9c42-98ec0e359e1a314225。
sub_spans 节点下面,所有相关的子节点,他的 parentId 为上级 span 节点的 spanId,值为 e495b1e3-72e3-4dfc-92ad-8526c1c05e68901528。
{"message":"span log","context":{"trace_id":"2bf002c7-c140-4304-9c42-98ec0e359e1a314225","request_id":"01d91c6f-1745-414c-a556-06d2e2630995119672","span":{"span_id":"e495b1e3-72e3-4dfc-92ad-8526c1c05e68901528","parent_id":null,"duration":4772900,"annotations":[{"timestamp":1612344583030172,"action":"sr"},{"timestamp":1612344587803072,"action":"ss"}]},"request_uri":null,"request_method":null,"sub_spans":[{"span_id":"6a112df7-762d-4467-aab5-8d4ea8d30e34265554","parent_id":"e495b1e3-72e3-4dfc-92ad-8526c1c05e68901528","duration":4064421,"annotations":[{"timestamp":1612344583090733,"action":"cs"},{"timestamp":1612344587155154,"action":"cr"}]}]},"level":200,"level_name":"INFO","channel":"SPAN","datetime":"2021-02-03 17:29:49.705213"}
复制代码
服务 B 对应 traceLog
服务 B 接收上级的传入的 TraceId,全局编码:2bf002c7-c140-4304-9c42-98ec0e359e1a314225。
服务 B 调用起止时间:1612344586.914167~ 1612344587.162829.
服务 A 通过 Feign 发起的时间为: 1612344583090733,服务 B 接收到的请求时间 1612344586914167,表明中间件到服务 B 中还是存在细微的时间差。
{"message":"trace log","context":{"trace_id":"2bf002c7-c140-4304-9c42-98ec0e359e1a314225","request_uri":"/customize-trace-B/trace/name","request_method":"GET","refer_service_name":"customize-trace-A","service_name":"customize-trace-B","refer_service_host":"127.0.0.1","request_time":1612344586.914167,"response_time":1612344587.162829,"time_used":218.196,"service_addr":"192.168.45.42","service_port":8096,"request_id":"c3141791-b5c4-49e3-ad4a-08c40782f687651638"},"level":200,"level_name":"INFO","channel":"REQUEST","datetime":"2021-02-03 17:29:47.161630"}
复制代码
服务 B 对应 spanLog
服务 B 接收上级的传入的 TraceId,全局编码:2bf002c7-c140-4304-9c42-98ec0e359e1a314225.
服务 B 没有再次调用其他的服务了,故不存在下级 sub_spans 节点。
服务 B 节点信息中的 parent_id,为服务 A 中的孩子节点 spanId,值为:6a112df7-762d-4467-aab5-8d4ea8d30e34265554。
{"message":"span log","context":{"trace_id":"2bf002c7-c140-4304-9c42-98ec0e359e1a314225","request_id":"c3141791-b5c4-49e3-ad4a-08c40782f687651638","span":{"span_id":"d4a7f2d5-d49d-4f88-95ee-4f73c18ff9d5967084","parent_id":"6a112df7-762d-4467-aab5-8d4ea8d30e34265554","duration":207818,"annotations":[{"timestamp":1612344586929937,"action":"sr"},{"timestamp":1612344587137755,"action":"ss"}]},"request_uri":null,"request_method":null,"sub_spans":[ ]},"level":200,"level_name":"INFO","channel":"SPAN","datetime":"2021-02-03 17:29:47.139560"}
复制代码
四、自实现方案优缺点
自定义一个调用链插件,便于根据项目需求,充分地定制化开发。
结合公司项目的需求,调整调用链方案,在调用链模块成熟后,可作为中间件模块,应用于公司的其他项目;
实现一个调用链插件,有利于了解整个调用链技术体系的技术关键点,技术细节。后续就算切换为其他的成熟的调用链产品,当使用中出现问题时,也能从原理层面分析问题。
自定义调用链插件在日志管理方面更灵活,便于后期业务日志分析,日志存储切换方案等可以做出快速调整。
随着 Spring 体系的升级,中间件的升级,自定义的调用链插件受到影响时,也需要升级。存在一定的维护成本。
在更加多元化的日志分析中,如权重管理,比例拦截日志等方面,自定义的插件都需要开发才能支持。
自定义插件的性能,技术实现方案与开发者掌握的技术密切相关。同开源的优秀调用链工具对比,肯定还是存在差异,需要开发者更新和替换。
五、案例源码
参考完整实现代码:https://github.com/wuya11/TraceDemo
运行截图参考:
原文链接:https://www.cnblogs.com/wlandwl/p/trace.html
如果觉得本文对你有帮助,可以关注一下我公众号,回复关键字【面试】即可得到一份 Java 核心知识点整理与一份面试大礼包!另有更多技术干货文章以及相关资料共享,大家一起学习进步!












评论 (1 条评论)