
ThreadPoolExecutor 线程池内部处理浅析
我们知道如果程序中并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束时,会因为频繁创建线程而大大降低系统的效率,因此出现了线程池的使用方式,它可以提前创建好线程来执行任务。本文主要通过 java 的 ThreadPoolExecutor 来查看线程池的内部处理过程。
1 ThreadPoolExecutor
java.uitl.concurrent.ThreadPoolExecutor 类是线程池中最核心的一个类,下面我们来看一下 ThreadPoolExecutor 类的部分实现源码。
1.1 构造方法
ThreadPoolExecutor 类提供了如下 4 个构造方法
通过观察上述每个构造器的源码实现,我们可以发现前面三个构造器都是调用的第四个构造器进行的初始化工作。
下面解释一下构造器中各个参数的含义:
corePoolSize:核心池的线程个数上线,在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务。默认情况下,在创建了线程池后,线程池中的线程数为 0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到 corePoolSize 后,就会把到达的任务放到缓存队列当中。
maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程。
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于 corePoolSize 时,keepAliveTime 才会起作用,直到线程池中的线程数不大于 corePoolSize,即当线程池中的线程数大于 corePoolSize 时,如果一个线程空闲的时间达到 keepAliveTime,则会终止,直到线程池中的线程数不超过 corePoolSize。但是如果调用了 allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于 corePoolSize 时,keepAliveTime 参数也会起作用,直到线程池中的线程数为 0。
unit:参数 keepAliveTime 的时间单位。
workQueue:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响;
threadFactory:线程工厂,主要用来创建线程;
handler:表示当拒绝处理任务时的策略。有以下四种取值:ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出 RejectedExecutionException 异常。 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务。
1.2 核心方法
在 ThreadPoolExecutor 类中,最核心的任务提交方法是 execute()方法,虽然通过 submit 也可以提交任务,但是实际上 submit 方法里面最终调用的还是 execute()方法。
主要方法 addWorker。
1.3 任务执行 run 方法
在上述 addWorker 中,当调用线程的 start 方法启动线程后,会执行其中的 run 方法。
2 整体处理过程
通过上述源码分析,我们可以得出线程池处理任务的过程如下:
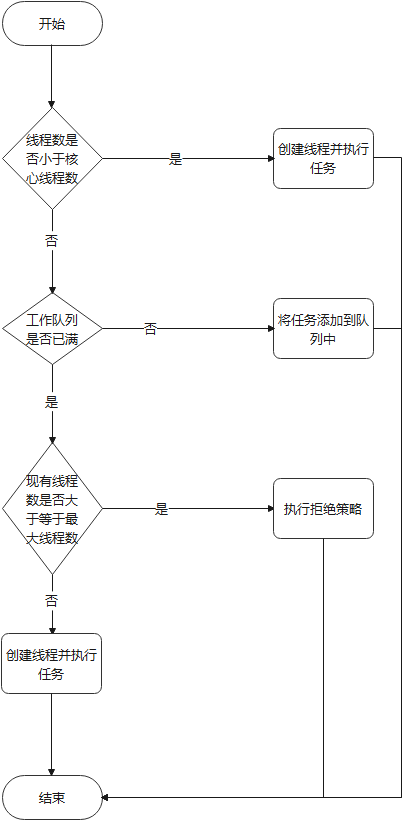
3 总结
本文从源码层面主要分析了线程池的创建、运行过程,通过上述的分析,可以看出当线程池中的线程数量超过核心线程数后,会先将任务放入等待队列,队列放满后当最大线程数大于核心线程数时,才会创建新的线程执行。
文章转载自:京东云开发者

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论