一位 211 大学毕业生工作五年后,被腾讯 70 多道面试题问迷茫了(Java 高级开发岗)!
背景
211 毕业至今刚好五年,我曾做过两三个月的测试感觉不是很合适,后面选择从事后端开发,还挺香。现在已经进入秋招的提前批了,想着去大厂试试水,就去了腾讯,整个一面下来我整个人都傻了,表示怀疑人生...没想过一面就能问这么多,疯狂轰炸,连环 70 多问,不得停歇。感觉我这辈子都不会忘记这次面试经历了,给大家看看我的面试过程,我想,恐怕你也会表示同感。
我的面试过程(历经 70mins)
1、个人履历简述
2、项目简述
主要突出重难点,我 bb 了一堆业务逻辑结果人家都不感兴趣
3、SpringAOP 实现
JDK 动态代理:实现 Invocationhandler 接口,本质上是 new 一个继承了所有类上 Interface 的 Proxy 对象,然后通过 method.invoke 进行调用
CGLib 动态代理:在内存中动态生成子类对原对象进行代理,无法代理 final 类以及方法
共同限制:无法代理到当前 class 当中 this 引用的嵌套方法
4、AOP 用的哪种?
默认用的 JDK 动态代理
5、JDK 动态代理以及 CGLib 动态代理性能比较
JDK 走的反射,会多一些反射调用的开销(方法权限验证、调用开销等)
CGLib 需要创建新对象,在创建新对象上,即初始化时会多一些开销
6、Java 的线程池用过吗,具体参数讲一下
Java 的线程池是一个三级存储结构,线程先放入核心线程池,满了之后放到缓存队列当中,最后如果缓存队列也满了则扩容新线程,所以参数有:
核心线程数量
缓存队列类型
最大线程数量
线程活跃时间
线程工厂方法(写日志、重命名线程等)
7、线程池的 Execute 和 Submit 区别
Execute 执行 runnable,Submit 可以执行 Future,我们一般用 countDownLatch+Future 来获取所有的线程结果
8、继续问,还有别的区别吗?
不知道了,后续查了发现区别如下
Execute 会在运行期直接抛出异常,Submit 之后在调用 Future.get 的时候才会抛出异常
9、线程池如何保证当前线程获取池内的 worker 的时候不产生争用
volatile 的 state 标志这个 worker 有没有被使用
10、volatile 的特性
通过禁止指令重排序来保证内存可见性,实际使用内存屏障实现的
11、内存屏障分几种?
当时记不得了,回头查了一下如下:
LoadLoad 屏障:对于这样的语句 Load1; LoadLoad; Load2,在 Load2 及后续读取操作要读取的数据被访问前,保证 Load1 要读取的数据被读取完毕。
StoreStore 屏障:对于这样的语句 Store1; StoreStore; Store2,在 Store2 及后续写入操作执行前,保证 Store1 的写入操作对其它处理器可见。
LoadStore 屏障:对于这样的语句 Load1; LoadStore; Store2,在 Store2 及后续写入操作被刷出前,保证 Load1 要读取的数据被读取完毕。
StoreLoad 屏障:对于这样的语句 Store1; StoreLoad; Load2,在 Load2 及后续所有读取操作执行前,保证 Store1 的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
12、除了在 volatile 当中使用了内存屏障,JAVA 还有哪里使用了内存屏障
这个真不知道,知道的小伙伴请在评论区指点一二
13、你之前讲到了 CountDownLatch,你知道它的内部实现吗
知道,用的 AQS,在 state=0 的时候才允许所有等待的线程全部通过
14、简单讲一下 AQS
AQS 核心设计:
一个 volatile int state 的状态值,使用 volatile 保证线程可见性,使用 int 来提供可重入的多资源能力
双向队列,首节点为执行节点,可以根据执行节点的 Node 信息判断是 ShareLock 还是 ExclusiveLock,会关联一个执行线程,来提供可重入的判断
加锁的时候若是公平锁则尝试 CAS 载入队列,若是非公平锁则直接入队列
解锁的时候直接唤醒后继的第一个 wait 节点
15、加锁之后 AQS 是如何响应中断的?
太细节了真不会,之前复习源码没看这么深(结束之后补漏洞)
16、OK 问点别的,AQS 存在什么实现呢?
用过的 ReentranceLock、CountDownLatch
17、讲讲实现
ReentranceLock 通过判断线程是否相同进行冲入
CountDownLatch 在 state 为 0 的时候才让所有的 await 通过
18、听说过 ReadWriteLock 吗,你之前提到 AQS 当中只有一个 State 那你如何用一个 State 去支撑读写两种状态
一个 state 是 Int,可以分高位给 Read,低位给 Write,就当个 String 用了
19、Int 几个字节
我居然回答了 32 个,应该是 32 位,8 位一个 byte,共计四个 byte
20、你们用过缓存吗
没有,但是用 redis 做了分布式锁
21、你说说下分布式锁怎么做的?
分布式锁也是一个锁,需要满足几个特性,1 可重入 2 可以识别加锁的身份防止 ABA 问题 3 考虑是否需要续约
key 是所需要加上的锁的业务资源唯一编码,value 是当前线程的 uuid,uuid 存在 threadLocal 内 加锁的时候用的 jedis,先设一个过期时间,然后用 ex,若不存在 key 则添加新 key,若已经存在则直接失败
解锁用的阿里云企业版的 CAD(compareAndDelete),原子比较并解锁,本质是通过 lua 脚本进行的类似事务操作
22、除了 redis 还有什么可以做分布式锁?
Mysql、zookeeper 等
23、如果让你用 Mysql 做分布式锁你怎么做
新建一张表,主键为需要锁的锁 key,col1 为线程 uuid,col2 为 ttl 时间
加锁的时候在一个事务中选取当前 key 的 record,若存在则判断 ttl,若不存在则直接可以插入
解锁的时候直接把 record 删除即可
起一个定时任务来遍历表,清楚过期键防止无限膨胀
24、zookeeper 了解吗
一点点,摄入不深
25、那我们继续聊聊 Redis 吧,Redis 有什么数据结构?
List,Hash,Set,Zset,List
26、Zset 怎么实现的?
跳表+map 实现
27、什么是跳表?
常规链表只有一个 next 节点,跳表持有多个指向其他链表的指针,可以跨越式的进行查找,时间复杂度是 logn
28、如果我要找一个 score 为 A 的节点应该如何去找?
首先在 map 中找到对应的 node 排名,然后根据排名在 skiplist 中进行查找
29、zrange 是如何实现的?
这个没想到不应该,查了一下如下: ZRANGE key start stop [WITHSCORES],zrange 就是返回有序集 key 中,指定区间内的成员,而跳表中的元素最下面的一层是有序的(上面的几层就是跳表的索引),按照分数排序,我们只要找出 start 代表的元素,然后向前或者向后遍历 M 次拉出所有数据即可,而找出 start 代表的元素,其实就是在跳表中找一个元素的时间复杂度。跳表中每个节点每一层都会保存到下一个节点的跨度,在寻找过程中可以根据跨度和来求当前的排名,所以查找过程是 O(log(N) 过程,加上遍历 M 个元素,就是 O(log(N)+M),所以 redis 的 zrange 不会像 mysql 的 offset 有比较严重的性能问题。
30、Redis 持久化
RDB:快照存储,可以选择是否阻塞,使用场景在数据库上下线、主备复制等情况中
AOF:类似于 binlog,每个里面都是一个写事件,是优先读取的策略,支持多策略写入(强同步、按时间刷盘、交由操作系统决定刷盘等),AOF 为了防止文件膨胀也支持重写
31、AOF 重写的时候会不会 block 主线程?
不会,没有这个必要,起一个子线程重写完毕之后把手头的 buffer 在刷进去就行了
32、在载入的时候是怎么做的
本地起一个 client 直接读取 AOF 重放其中的命令
33、Redis 有哪些多机部署方案?
经典的主备同步,通过 RDB 初始化备库然后进行命令传播 Sentinel,实际上是一种容灾机制 cluster,集群部署,使用多机占用 slot 的方式进行集群服务提供
34、在主备环境下,如果一个备库中途断链了,重新上线的时候怎么执行同步?
主备各自维护一个写入的 Offset,对比差异之后在 buffer 中读出丢失的命令并进行同步
35、如果备库的 offset 过于落后已经不在 buffer 当中了呢?
直接 RDB 重新同步 使用 AOF 来查找对应 offset 的语句(这个是我猜的)
36、cluster 如何做的故障转移?
不知道,估计也是检测到客观下线然后 paxos 选主
37、Mysql 了解吗,里面有哪些锁?
类型分类:共享锁(S),独占锁(X),意向锁(与表锁互斥)
粒度分类:行锁、表锁
38、行锁怎么实现的?
不知道,这个时候已经有点崩溃了,怎么这么多不知道 nnd
39、讲一下事务隔离级别吧
RU、RC、RR、Serializable
40、你们用的是哪个隔离级别
mysql 默认的是 RR,我们改成 RC 了
41、在默认隔离级别下会产生幻读问题吗?
会,这是幻读是 RR 的经典问题之一
42、描述一下幻读
在 T1 里 Select * From table where id = 1;若不存在该记录则 insert id = 1 的记录进去,但是在 select 完毕之后 T2 事务插入了 id=1 的 record,此时后续 insert 执行失败,本质上来讲是当前的快照都不支持后续 dml 语句的执行
43、MVCC 机制了解吗?
了解,由 undolog 支撑的数据隔离机制,主要是为了提供更高的并发度
44、讲一下原理
每一行 record 都存在两个隐藏行,一个是当前的事务 id,一个是指向 undolog 的指针 mvcc 机制运行
在 rr 和 rc 两个隔离级别下 在每次生成 ReadView 的时候,会将当前的活跃事务 ID 维护在列表当中,如果访问的 Record 的 ID 比最小活跃事务的 ID 还要小说明之前已经提交了,可以直接读取,如果与最大事务 ID 还要大就证明该事务在这个快照时没提交,需要根据 undolog 去找对应的历史版本,如果在最大和最小之间,那么若其为活跃事务则找历史版本,若不是则直接读取
在 RC 级别下,每次 Select 都生成新的 ReadView,所以能看到不同事物间的提交
在 RR 级别下,只在第一次 Select 的时候生成 ReadView,所以会产生幻读,因为快照读和真实读的结果不一致
45、慢 sql 怎么处理?
捞慢 sql 日志先分析写的索引是不是有问题或者 offset 太大了,然后看 expain
46、你关注 explain 的那些 col?
key:真实用到的索引
possible_key:可能用的索引
rows:扫描行数,越大越拉垮
filter:过滤数据比例,这个 col 可以验证索引有效性
extra:包含是否使用索引、sort 是否时 filesort 等
47、https 了解吗?
client 发一个随机数给 server
server 发证书+随机数回来
client 拆证书找第三方验证证书有效性,取出公钥
client 拿公钥加密第三个随机数发 server
server 私钥解密
48、线上机器 cpu100%你怎么处理?
容器化时代,一定要 top 看下是不是 st 过高,存在超卖的可能性
如果不是的话 top 看下哪个进程有问题,然后看这个进程哪个线程吃了 cpu
jstack 直接把线程 dump 出来然后找对应有问题的线程再分析
也有可能是内存泄漏导致的频繁 GC 问题,可以拉 GClog 然后在 jmap 把 heap dump 出来看下
49、你们线上 JVM 一般调整什么参数?
XMX&XMS 固定防止内存抖动
堆空间调整:年轻代 Age 调整、年轻代 eden:s0:s1 比例调整
收集器调整:大促前把 CMS 的预清理次数调低一些,CMS 的清理阈值调高一些
50、反问
什么团队?
做什么业务的?
自我反思

虽说这次是抱着试水的心态去的,但是这一连 50 问着实是有点傻眼了,而且也发现了自己的很多漏洞,如下:
我的简历过长,难以被面试官抓住重点
项目使用技术栈没有体现出来
涉及相关项目重难点表述不是很清楚,分布式锁、多租户的分库分表以及中间件隔离方案、性能问题排查等
各类技术栈停其实都还留在使用层,没有深入去挖掘
语速太快了,70 分钟的面试大大小小回答了 50 个问题,我感觉放慢点够我回答两轮了
最后总结个人所得(供大家参考学习)
这次一面结束之后我反思很久,发现自己真的是有很多不足和漏洞,所以最近一直在规划自己的学习路线去不足,不论你是复习备战面试还是自己学习,我相信我所说的多少还是有点用处的。
1.1 首先,第一个应该去梳理整个体系的知识大纲
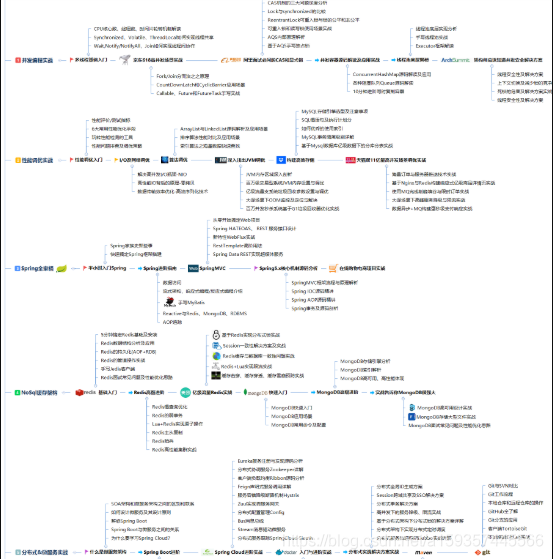
整个体系的知识大纲
我将整个体系分为 5 个专题:并发编程、性能调优、Spring 全家桶、缓存数据库、分布式 &微服务
1.2 其次,根据上面的分类,按照大纲来学习(最后看面试专题)
对于每一个专题,去搜集相应的面试学习笔记,比如下面我所收集的(若是对我收集的这份知识体系大纲以及下方每个专题对应的面试+学习笔记感兴趣,小编可以免费分享给你一起学习;
免费获取文章资料方式:一键三连+评论,然后添加我的 VX(tkzl6666)即可免费领取。

1. 并发编程(手写笔记:并发编程+并发编程_原理+并发编程_应用+并发编程_模式)
并发编程
并发编程
并发编程_原理
并发编程_原理
并发编程_应用
并发编程_应用
并发编程_模式
并发编程_模式
性能调优(Java 性能调优实战:Java 编程性能调优+多线程性能调优+JVM 性能监测及调优+设计模式调优+数据库性能调优+实战演练)
性能调优
Spring 全家桶(关注这一部分,我将 Spring、MVC、Cloud、Boot 归整在一块了)
手绘的各思维脑图(帮助梳理知识点,比较多就不一一截图了)

Spring 全家桶手绘的各思维脑图
进阶学习的笔记
Spring 全家桶进阶学习的笔记
缓存数据库(主要是 MySQL+Redis+MongDB)

MySQL+Redis+MongDB
分布式 &微服务(整理的笔记如下)

分布式 &微服务
1.3 最后来看面试专题
我从基础-中级-高级开始一步一步逐步深入,这些面试问题一样都有分类整理,私信我【学习】给你分享喔(附答案解析)。
比如基础部分:
基础部分
中级部分:
中级部分
高级部分(消息队列+Redis 缓存+分库分表+读写分离+分布式系统+高可用+微服务架构)
高级部分
以上就是我全部的一个学习路线的规划了,从整体的一个知识体系出发,梳理全部的知识,有漏洞就去查阅我相关的手写笔记加以巩固,最后上面试刷题,争取查漏补缺,下次面试不再出现这么多的不知道和知识空白。
话说到这里,不论是知识体系大纲,还是相关的并发编程、性能调优、Spring 全家桶、缓存数据库、分布式 &微服务等等的笔记,如何你也想学习或者复习一下,那便可直接来找小编分享就行。
免费获取文章资料方式:一键三连+评论,然后添加我的 VX(tkzl6666)即可免费领取。

微信:tkzl6666 添加获取你想要的Java资料 2019.01.29 加入
添加VX(tkzl6666 ) 获取大厂面试真题,面试复习资料,Java进阶资料,Java实战项目。









评论 (1 条评论)