电商系统中的 ID 是如何生成的

分布式 ID, 我们可能都听过分布式系统,分布式,分布式 ID 可能比较少,因为业务,方向以及系统维护的方面出发,现在的互联网中的项目,多数都需要一个全局且唯一,有增量趋势的标识。目前用的可能是 MySQL 的自增主键,UUID,时间戳等,但是对于日益增长的消息系统,点评,支付等具体操作,都需要一个稳定,全局唯一,且有明显自增趋势的 ID 作为唯一标识。
一个分布式全局 ID 的硬性要求
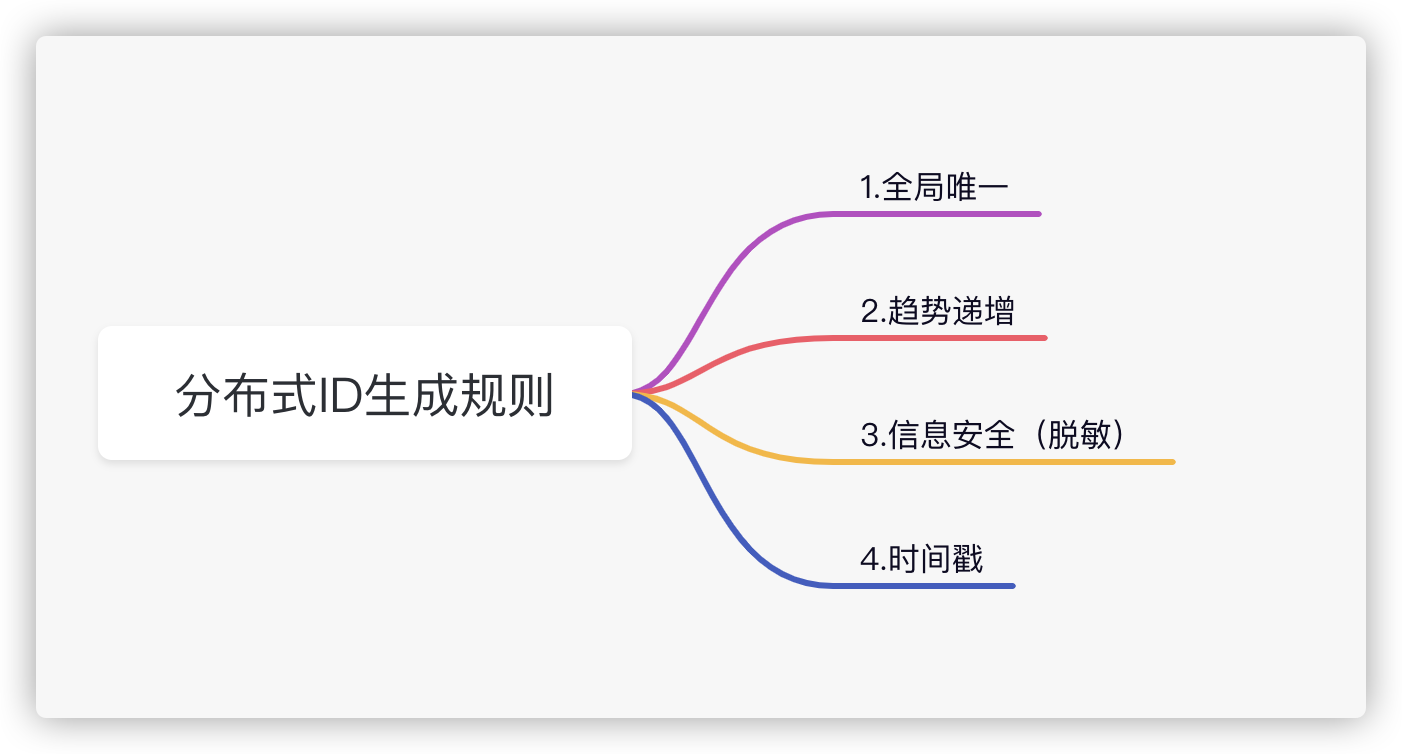
其中信息安全,可能有的小伙伴不太了解,你每次请求获取的 ID(查询操作),这个如果是递增,我们就能直观的判断出有信息,多少人,这是第多少个等,这属于敏感信息泄露的范畴, 安全还是很重要的;
规则我们确定之后,我们就要求生成这个 ID 系统的要求,之前是对于生成单个一个 ID 的要求,
对 ID 系统生成的可用性要求
因为是存在于分布式系统的,那也就是我们比较熟悉的,
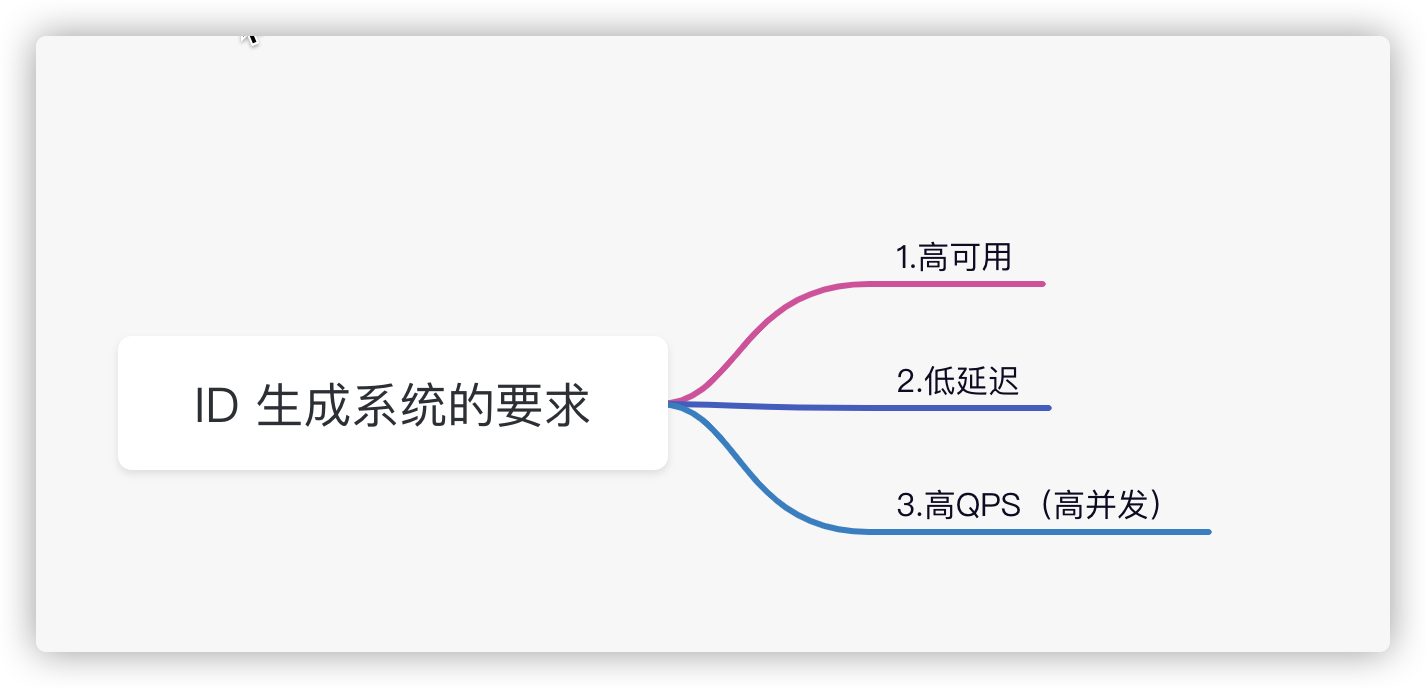
高可用:发起一个获取分布式 ID 的请求时,必须保证服务器在 99.999%的时候给我创建成功
低延迟: 获取分布式 ID,服务器响应快速,不能有高延迟,会有误差
高并发: 一秒钟可以获取 10 万左右的 ID,而且要成功,服务器要扛得住
情景再现:
面试中,对于面试者做过的项目,面试官一般会采用聊集群,QPS 等情况验证,项目的真实性, 其中分布式 ID 就属于具体实现了,一般会问:
你们项目是,分布式微服务,集群化部署,电商的这个系统中对于订单,支付等全局 ID 是如何生成的?
雪花算法 snowFlake;
现在系统常用的 ID 生成方式:
数据库自增,UUID ,时间戳;Redis 集群
(1) 数据库自增(mysql 自增)
其中数据库自增,对于单体系统,后台系统用的比较多,因为并发小,使用人数也少,适合于小系统,QPS 一般几十到一百左右的,
缺点:对于数据敏感的场景不宜使用, 且支撑不了分布式场景,自增之后还是会还原为原来的数值
(2) UUID
UUID 用的是比较普遍的一个 ID, 因为全局唯一,但是它存在很多的问题
UUID 的缺点:
无序,且无法预测生成顺序,无法有效的呈现递增趋势
存储,字段很长,耗费数据库资源,对于特点环境存在一些问题,
优点:只剩下全局唯一了
(3)时间戳
一般可以使用时间戳加具体的业务 ID 来规定,但是用的也比较少
(4)基于 Redis 集群生成策略
因为 Redis 特性是基于单线程,所以用它生成 ID 操作是原子性的,集群化可以实现,
通过设备集群的增长步长,起始值,就可以
比如 Redis 集群有五台机器, 可以初始化为每台 Redis 的值 1,2,3,4,5;步长是 5;
各个 Redis 生成的 Id 为:
A:1,6,11,16,21,...B:2,7,12,17.22,...C:3,8,13,18,23,...D:4,9,14,19,24,...E:5,10,15,20,25,...
虽然可以实现,但是配置 Redis 集群后, 要实现数据丢失怎么办,key 的失效时间等等,不是不能做,是杀鸡焉用牛刀,对的;
然后就到了我们今天的主题:
(5)Twitter 开源的 snowflake;
Snowflake(雪花) 是一项服务,用于为 Twitter 内的对象(推文,直接消息,用户,集合,列表等)生成唯一的 ID。这些 IDs 是唯一的 64 位无符号整数,它们基于时间,而不是顺序的。完整的 ID 由时间戳,工作机器编号和序列号组成。当在 API 中使用 JSON 数据格式时,请务必始终使用 id_str 字段而不是 id,这一点很重要。这是由于处理 JSON 的 Javascript 和其他语言计算大整数的方式造成的。如果你遇到 id 和 id_str 似乎不匹配的情况,这是因为你的环境已经解析了 id 整数,并在处理的过程中仔细分析了这个数字。
Twitter 的分布式雪花算法 SnowFlake,经测试 snowflake 每秒能够产生 26 万个自增可排序的 ID1、twitter 的 SnowFlake 生成 ID 能够按照时间有序生成 2、SnowFlake 算法生成 id 的结果是一个 64bit 大小的整数,为一个 Long 型(转换成字符串后长度最多 19).3、分布式系统内不会产生 ID 碰撞(由 datacenter 和 workerld 作区分)并且效率较高。
分布式系统中,有一些需要使用全局唯一 ID 的场景,生成 ID 的基本要求
1.在分布式的环境下必须全局且唯一。
对比 2.一般都需要单调递增,因为一般唯一 ID 都会存到数据库,而 InnoDB 的特性就是将内容存储在主键索引树上的叶子节点,而且是从左往右,递增的,所以考虑到数据库性能,一般生成的 id 也最好是单调递增。为了防止 ID 冲突可以使用 36 位的 UUID,但是 UUID 有一些缺点,首先他相对比较长,另外 UUID-般是无序的


snowflake 是中可以用 69 年是否成立?
雪花算法可以高度唯一和可用性时间长:作比较, 41 位的 1 二进制数字,对于十进制来说,是多少呢;十进制的数字是:2199023255551https://tool.lu/hexconvert/ 进制转换的工具箱
我做了个 demo 来证明:
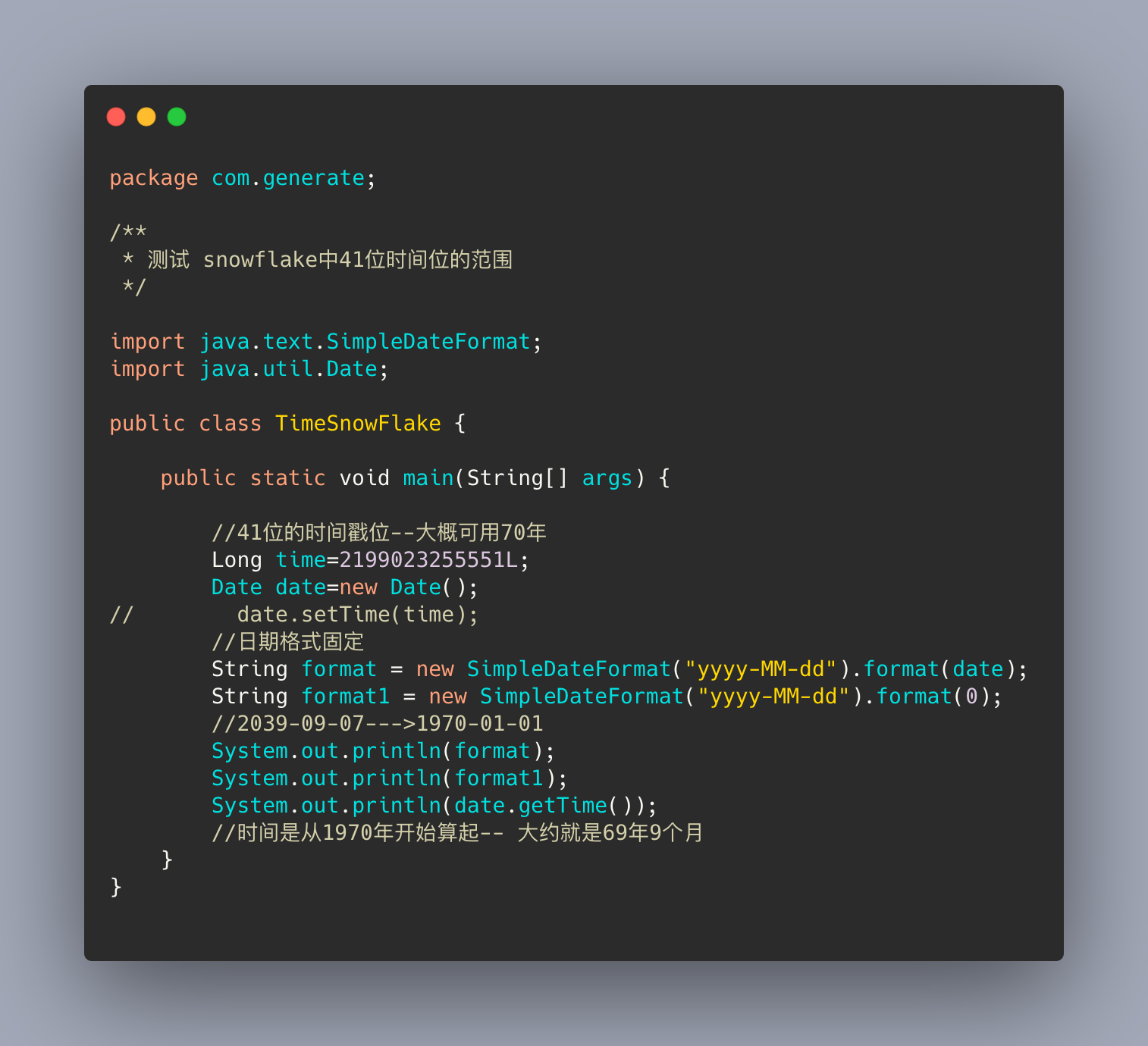
其中主要设置的是 10 位的工作进程位;-
一般分为数据中心和机器位
生成 snowFlake 的 ID
我们以 springboot 的项目来构建这个 snowFlake 的 ID 生成,
依赖:
这里我们表示的是 Java 代码库中,hutool 的类库,调用已经封装好的 IdUtil 就好
这里是简单的一个版本,与真实项目中有差异,差异主要是体现在参数配置中,
虽然雪花算法可以生成,唯一且自增的 ID ,但是它也存在问题,是关于时间戳的;
总结:
优点:
1.不依赖与第三方系统(MySQL,Redis 等),稳定性,生成 ID 的性能非常高
2.毫秒数在高位,自增序列在低位,整个 ID 都是有趋势递增的;
缺点:
依赖于机器时钟,也就是对表时间,如果机器回拨,会导致重复 ID 生成;
这种情况一般会发生在分布式环境中,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况
但是对于中小公司,此缺点可以忽略, 一般会要求趋势递增,并不会严格要求递增;
snowFlake 的优化
对于时钟回拨的情况,国内的大厂也修复了这个雪花算法的问题,比如
百度开源的 Uid Generator
Leaf--美团点评分布式生成 ID
两者都是在雪花算法的基础上,优化和改进;
适用于
对于普通公司,200 人上下的,体制主要对于研发人员,都可以使用 snowFlake, 配置具体 ID 生成,规定其中位数的默认值,
尤其是对于时钟回拨的,(时间一直在走),重点在配置,选择,处理异常,就可以完成
寄语
今日的分享就到这里了,学海无涯难行洲,唯有坚持方可成;我是卢卡,我们下期见
版权声明: 本文为 InfoQ 作者【卢卡多多】的原创文章。
原文链接:【http://xie.infoq.cn/article/fc843a99098162fe74522c14c】。文章转载请联系作者。

还未添加个人签名 2020.04.12 加入
还未添加个人简介









评论 (2 条评论)