池
上图是装水的池子——水池。
流行池化技术,那么到底什么是池化技术呢?
池化技术简单点来说,就是提前保存大量的资源,以备不时之需。在机器资源有限的情况下,使用池化技术可以大大的提高资源的利用率,提升性能等。
在编程领域,比较典型的池化技术有:线程池、连接池、内存池、对象池等。
案例
我们系统里经常会涉及到一些异步处理,比如说给用户发个站内信、某项业务搞完了给用户发个短信、发个推送等这种异步业务处理。(并不是每个系统都会使用消息队列之类的第三方框架),所以,针对上面的举例场景,如果没有线程池的说法,将会:
发站内信启动一个线程,发完结束线程。发个短信启动一个线程,发完结束线程。发个推送启动一个线程,发完结束线程….
有没有发现,我们会不断的启动线程、销毁线程。
还拿上边的例子说,如果我们使用线程池的方式的话,可以实现指定线程的数量,这样的话就算再多的数据需要入库,只需要排队等待线程池的线程即可,也就不用一直不断的创建线程销毁线程,就不会出现线程池过多而消耗系统资源的情况,当然这只是意见简单的场景。
说到这里,有人要说了线程不是携带资源的最小单位,操作系统的书籍中还给我们说了线程之间的切换消耗很小吗?
虽然如此,线程是一种轻量级的工具(或者称之为:轻量级进程),但其创建和关闭依然需要花费时间,如果为了一个很简单的任务就去创建一个线程,很有可能出现创建和销毁线程所占用的时间大于该线程真实工作所消耗的时间,反而得不偿失。
定义
为了避免系统频繁的创建和销毁线程,我们可以将创建的线程进行复用。数据库中的数据库连接池也是此意。
在线程池中总有那么几个活跃的线程,也有一定的最大值限制,一个业务使用完线程之后,不是立即销毁而是将其放入到线程池中,从而实现线程的复用。
简而言之:创建线程变成了从线程池获取空闲的线程,关闭线程变成了向池子中归还线程。
线程池的优点
Java 中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池,Spring、Dubbo、Mybatis等等框架中都有大量的使用线程池。
那线程池到底有哪些好处呢?
在开发过程中,合理地使用线程池能够带来几个好处:
降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行;
方便线程并发数的管控。因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM(Out Of Memory),并且会造成CPU过度切换(CPU切换线程是有时间成本的,需要保持当前执行线程的现场,并恢复要执行线程的现场)。
提供更强大的功能,延时定时线程池。
线程池的原理
线程的复用
线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了之前通过 Thread 创建线程时的一个线程必须对应一个任务的限制。
在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行。
其核心原理在于线程池对 Thread 进行了封装,并不是每次执行任务都会调用 Thread.start() 来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停的检查是否有任务需要被执行,如果有则直接执行。
也就是调用任务中的 run 方法,将 run 方法当成一个普通的方法执行,通过这种方式将只使用固定的线程就将所有任务的 run 方法串联起来。
JDK 自带线程池
JDK 提供了 java.util.concurrent.Executor接口,
可以让我们有效的管理和控制我们的线程,其实质也就是一个线程池。
public interface Executor {
void execute(Runnable command);
}
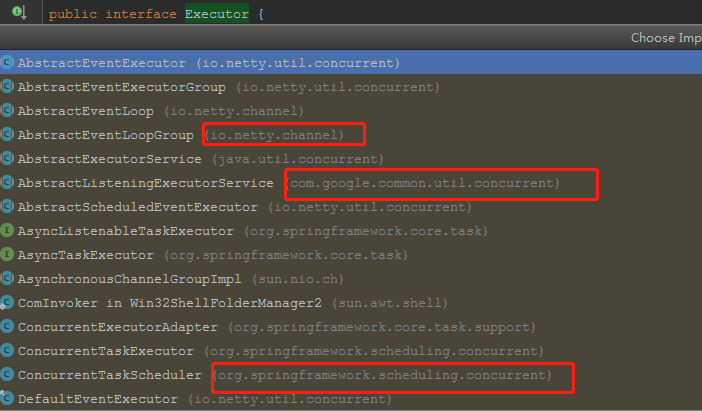
看看Executor实现类就知道,线程池使用的地方是相当多,netty、Spring、Google等。
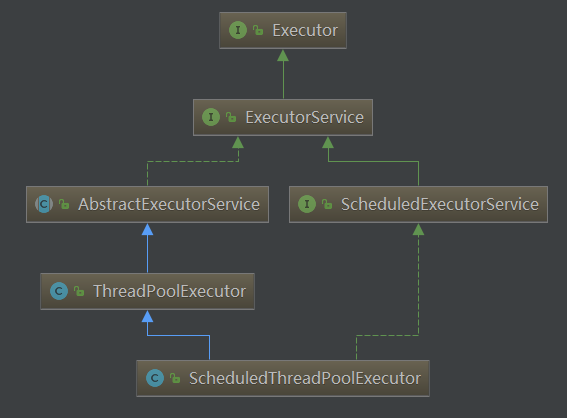
但是我们这篇讲的是Executor 的子接口ExecutorService
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
相关类继承关系如下:
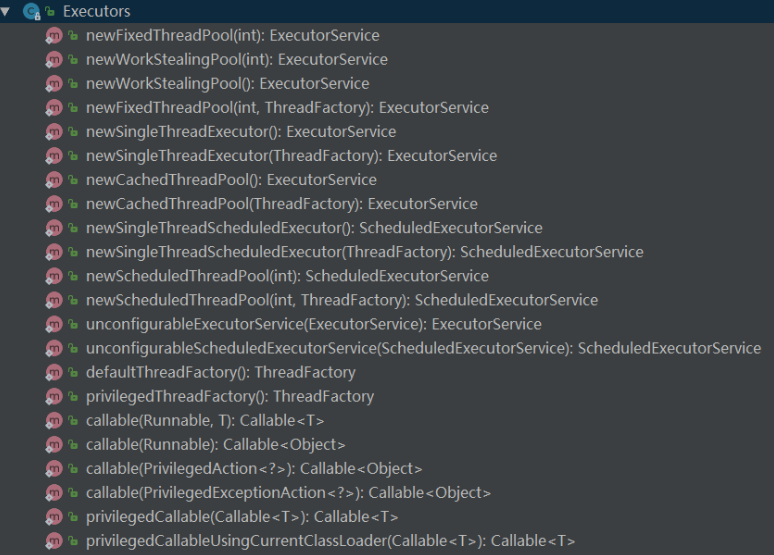
如果使用 Executor 框架的话,JDK提供了一个类似于工厂类的Executors 类,Executors 相比前面前面的Executor多了个s,这个得注意,Executors 其方法如下:
其中常用几类线程池如下:
//该方法返回一个固定线程数量的线程池;
public static ExecutorService newFixedThreadPool()
//该方法返回一个只有一个现成的线程池
public static ExecutorService newSingleThreadExecutor()
//返回一个可以根据实际情况调整线程数量的线程池
public static ExecutorService newCachedThreadPool()
//该方法和 newSingleThreadExecutor 的区别是给定了时间执行某任务的功能,可以进行定时执行等
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
//在newSingleThreadScheduledExecutor的基础上可以指定线程数量
public static ScheduledExecutorService newScheduledThreadPool()
构造方法
在 Executors 类中,上面几个创建线程池的方法源码部分如下:
//即核心线程数=nThreads,最大线程数=nThreads
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
//核心线程数=1,最大线程数=1
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
//核心线程数0,最大线程数=整形数的最大数
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
//
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
//ScheduledThreadPoolExecutor就是ThreadPoolExecutor子类
public ScheduledThreadPoolExecutor(int corePoolSize) {
//这里的super就是ThreadPoolExecutor的构造方法
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
//所以以上几种创建线程池最终还是调用这个构造方法
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler);
}
可以看出,类似的其他方法一样,在 Executors 内部创建线程池的时候,实际创建的都是一个 ThreadPoolExecutor 对象,只是对 ThreadPoolExecutor 构造方法,进行了默认值的设定。
线程池的参数含义如下:
corePoolSize 核心线程池大小;
maximumPoolSize 线程池最大容量大小;
keepAliveTime 线程池空闲时,线程存活的时间;
TimeUnit 时间单位;
ThreadFactory 线程工厂;
BlockingQueue任务队列;
RejectedExecutionHandler 线程拒绝策略;
这也是一道非常高频率的面试题,面试官一般会问你熟悉线程池吗?你说熟悉,那就说一下jdk自带的能创建多少中线程池,这里你说个常见的上面几种就基本ok了,但是你要是全部都知道的话那是更好,但是可能你把其他说出来了,你的面试官会懵逼的。所以面试官会继续问说一下创建线程池有哪些参数,然后再针对上面的参数可以顺带着把线程池的原理也给面试官讲一下。
主要四个参数
核心线程数
最大线程数
任务队列
拒绝策略
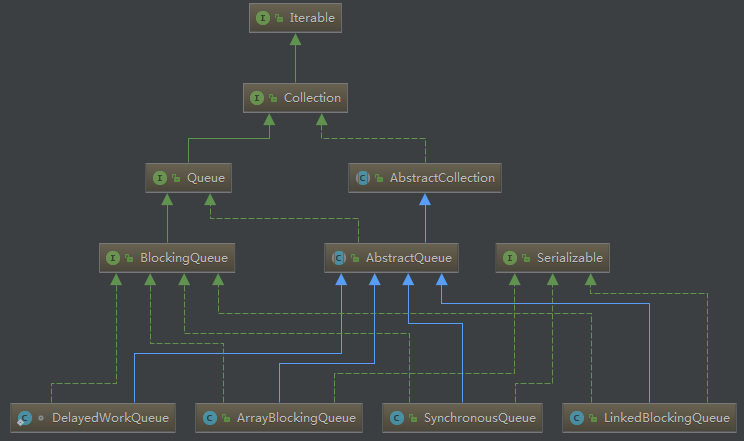
任务队列
用到了三种阻塞同步队列,LinkedBlockingQueue、SynchronousQueue、DelayedWorkQueue。都是BlockingQueue的实现类,AbstractQueue的子类。
LinkedBlockingQueue
是一个由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE整形数的最大值,
所以我们在使用LinkedBlockingQueue时建议手动传值,为其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。
newFixedThreadPool、newSingleThreadExecutor中都是使用这个队列作为任务队列的。
SynchronousQueue
是一个没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
使用SynchronousQueue阻塞队列一般要求maximumPoolSizes为无界(Integer.MAX_VALUE),避免线程拒绝执行操作。
newCachedThreadPool中使用的就是SynchronousQueue作为任务队列。
DelayedWorkQueue
DelayedWorkQueue是基于堆结构的等待队列。该队列是定制的优先级队列,只能用来存储RunnableScheduledFutures任务。
堆是实现优先级队列的最佳选择,而该队列正好是基于堆数据结构的实现,ScheduledThreadPoolExecutor的任务队列就是使用了DelayedWorkQueue。
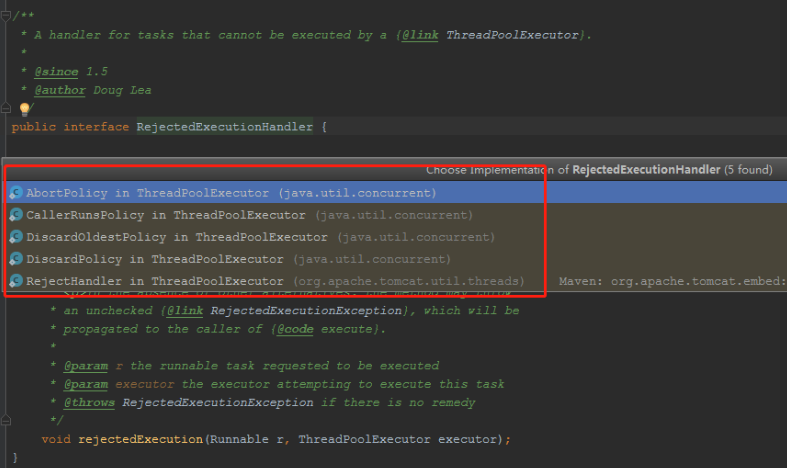
线程池的拒绝策略
AbortPolicy:丢弃任务并抛出
RejectedExecutionException:异常
DiscardPolicy:丢弃任务,但是不抛出异常
DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务
CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务
默认拒绝策略AbortPolicy
/**
* The default rejected execution handler
*/
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
实例
实例一:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Description:
*
* @author : tianweichang
* @date : 2020/10/24
* 公众号:java后端技术全栈
*/
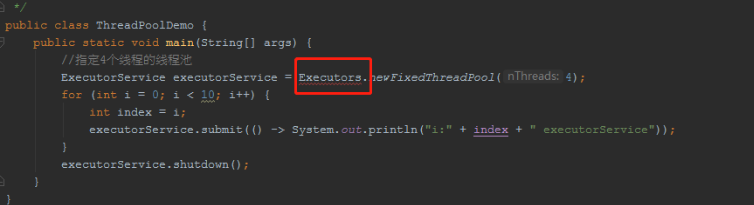
public class ThreadPoolDemo {
public static void main(String[] args) {
//指定4个线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int i = 0; i < 10; i++) {
int index = i;
executorService.submit(() -> System.out.println("i:" + index + " executorService"));
}
executorService.shutdown();
}
}
submit(Runnable task) 方法提交一个线程。
一般我们在IDEA要是装了“阿里巴巴编码规范插件”,当你使用上面这种方式创建线程池,然后就会提示你。
提示内容如下:
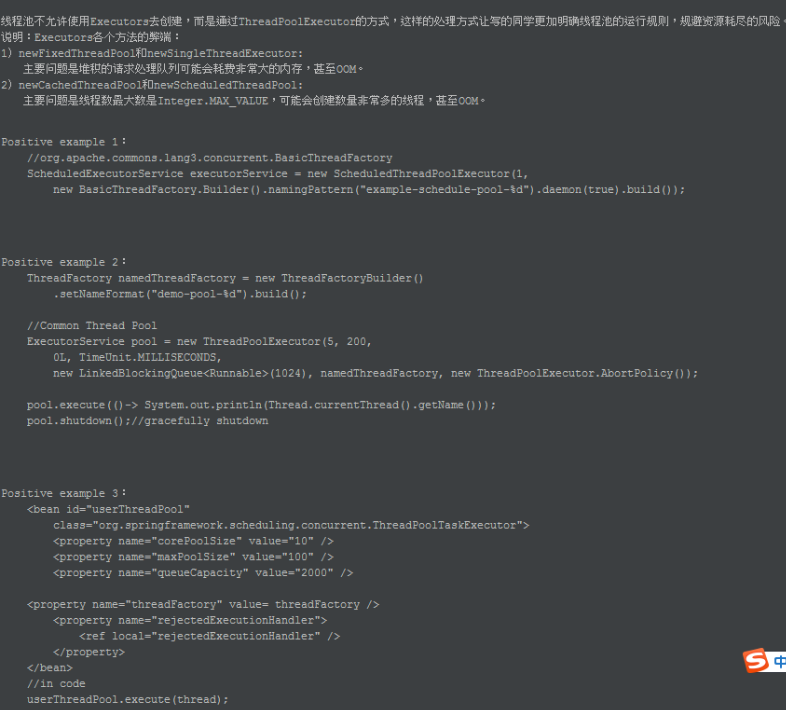
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式, 这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
另外这个插件还给咱们写了两个demo案例。
关于阿里巴巴编码规范插件地址:https://github.com/alibaba/p3c
实例二:
遵循阿里巴巴编码规范的提示,示例如下:
public class ThreadPoolDemo {
public static void main(String[] args) {
//创建核心线程数=2,最大线程数=2的线程池
ExecutorService executorService = new ThreadPoolExecutor(2, 2, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 10; i++) {
int index = i;
executorService.submit(() -> System.out.println("i:" + index + " executorService"));
}
executorService.shutdown();
}
}
或者这样:
public class ThreadPoolDemo {
public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 2, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 10; i++) {
int index = i;
pool.submit(() -> System.out.println("i:" + index + " executorService"));
}
pool.shutdown();
}
}
execute() VS submit()方法
execute() 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
submit() 方法用于提交需要返回值的任务。
线程池会返回一个 future 类型的对象,通过这个 future 对象可以判断任务是否执行成功,并且可以通过 future 的 get() 方法来获取返回值,get() 方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
部分参考:
1.https://blog.csdn.net/qq_43012792/
2.徐刘根的《java多线程编程核心技术》















评论