week6 技术选型(二) 作业和学习总结
作业一(至少完成一项):
请简述 CAP 原理。
CAP原理
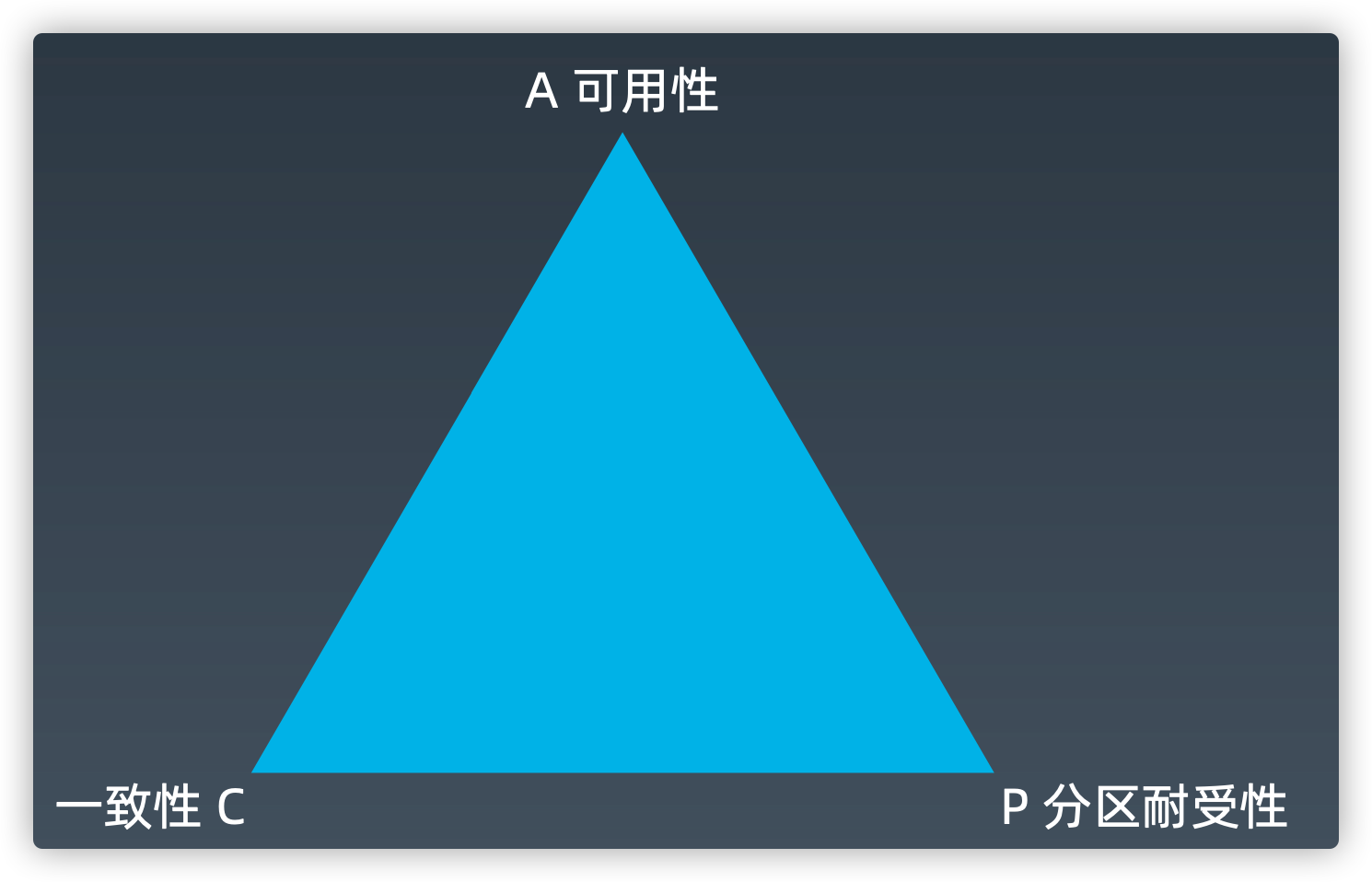
一致性Consistency
一致性是说,每次读取的数据都应该是最近写入的数据或者返回一个错误(Every read receives the most recent write or an error),而不是过期数据,也就是说,数据是一致的。
可用性Availability
可用性是说,每次请求都应该得到一个响应,而不是返回一个错误或者失去响应,不过 这个响应不需要保证数据是最近写入的(Every request receives a (non-error) response, without the guarantee that it contains the most recent write),也就是说系 统需要一直都是可以正常使用的,不会引起调用者的异常,但是并不保证响应的数据是最新的。
分区耐受性Partition tolerance
分区耐受性说,即使因为网络原因,部分服务器节点之间消息丢失或者延迟了,系统依然应该是可以操作的(The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes)。
CAP 原理
当网络分区失效发生的时候,我们要么取消操作,这样数据就是一致的,但是系统却不可用;要么我们继续写入数据,但是数据的一致性就得不到保证。
对于一个分布式系统而言,网络失效一定会发生,也就是说,分区耐受性是必须要保证 的,那么在可用性和一致性上就必须二选一。
当网络分区失效,也就是网络不可用的时候,如果选择了一致性,系统就可能返回一个 错误码或者干脆超时,即系统不可用。如果选择了可用性,那么系统总是可以返回一个 数据,但是并不能保证这个数据是最新的。
所以,关于 CAP 原理,更准确的说法是,在分布式系统必须要满足分区耐受性的前提下, 可用性和一致性无法同时满足。
针对 Doris 案例,请用 UML 时序图描述 Doris 临时失效的处理过程(包括判断系统进入临时失效状态,临时失效中的读写过程,失效恢复过程)。
作业二:根据当周学习情况,完成一篇学习总结
第6周 技术选型(二)
6.1 分布式关系数据库(上)
MySQL复制
Mysql主从复制
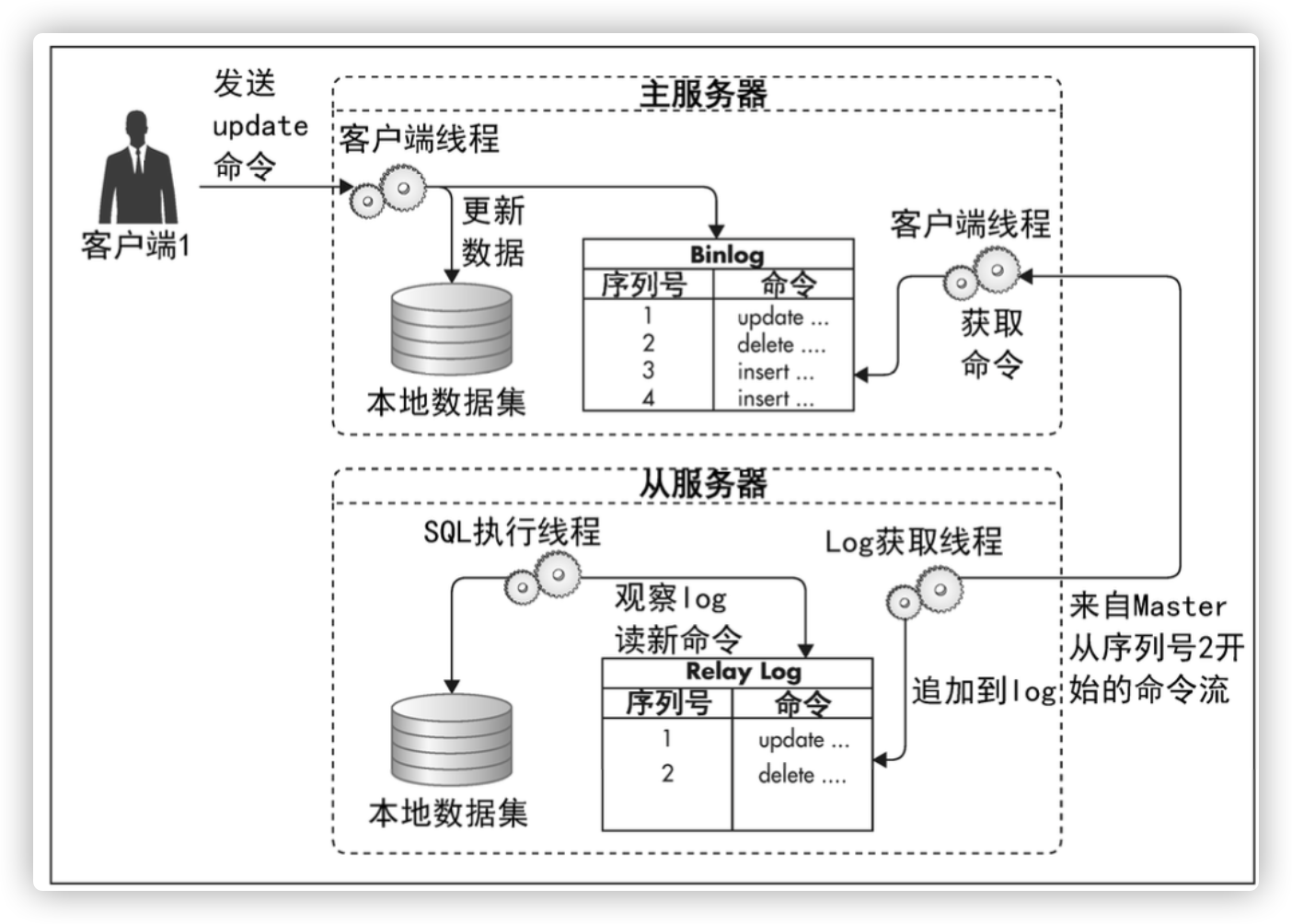
mysql一主多从复制
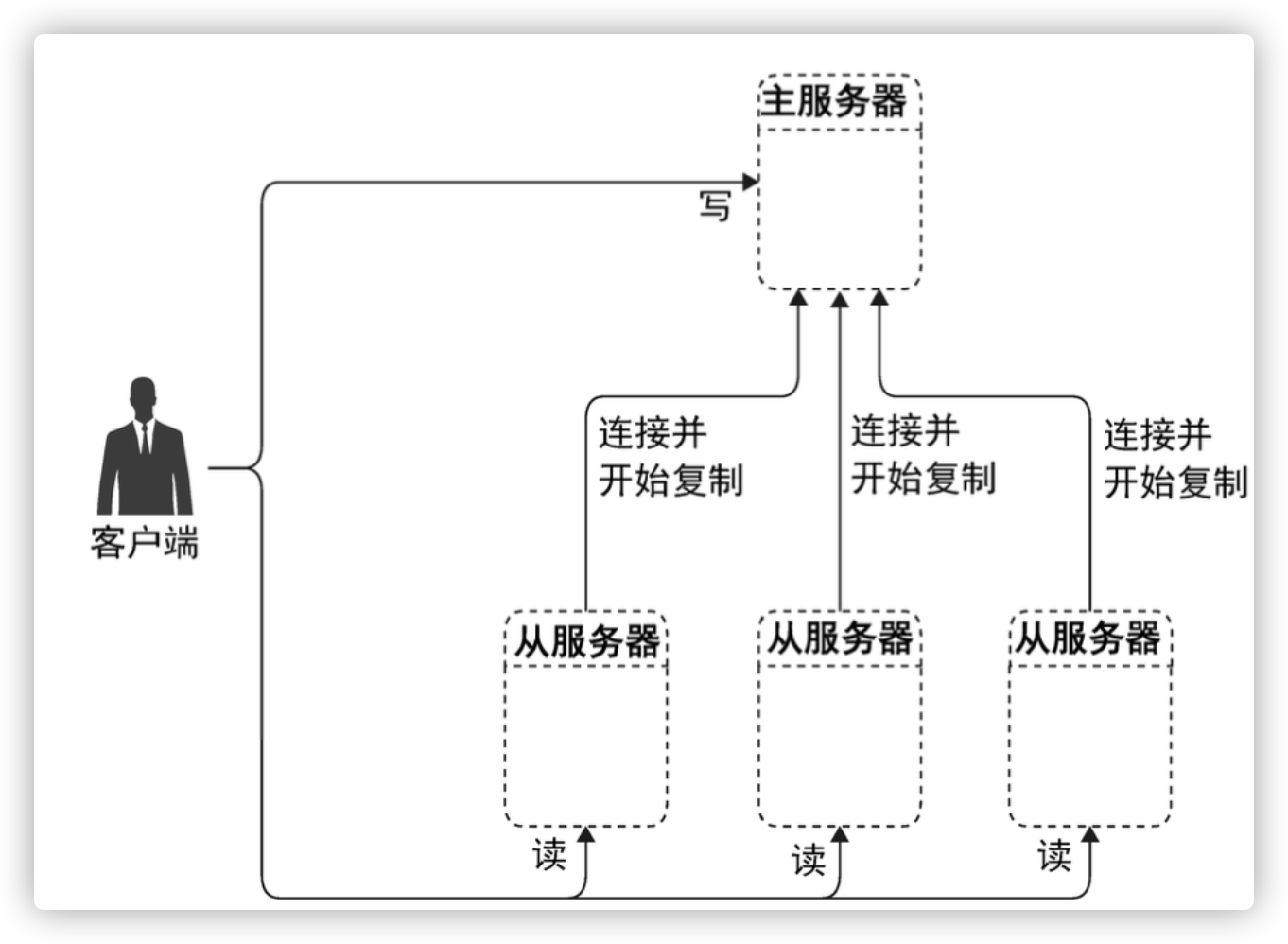
一主多从的有点
分摊负载
专机专用
便于冷备
高可用
MySQL主主复制
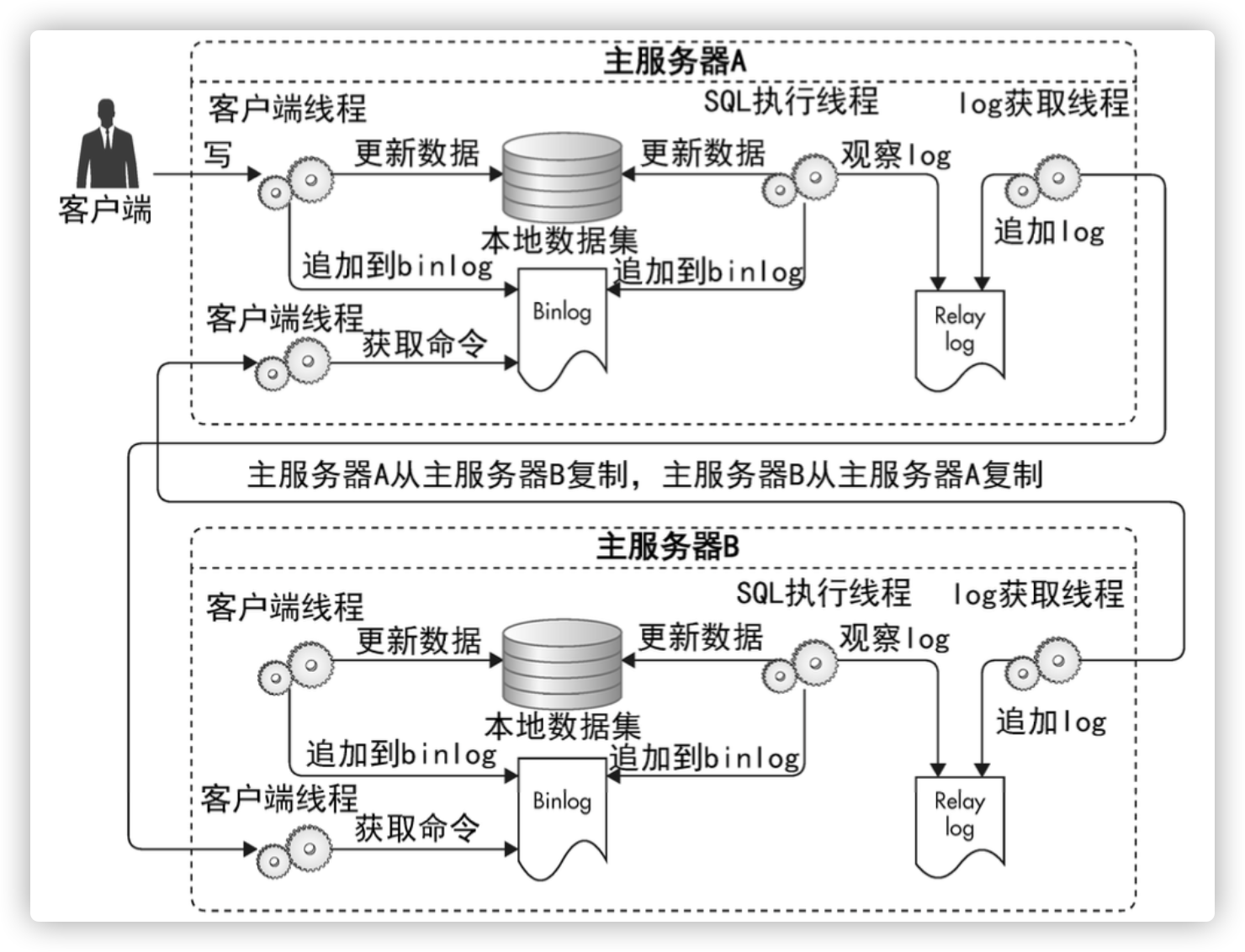
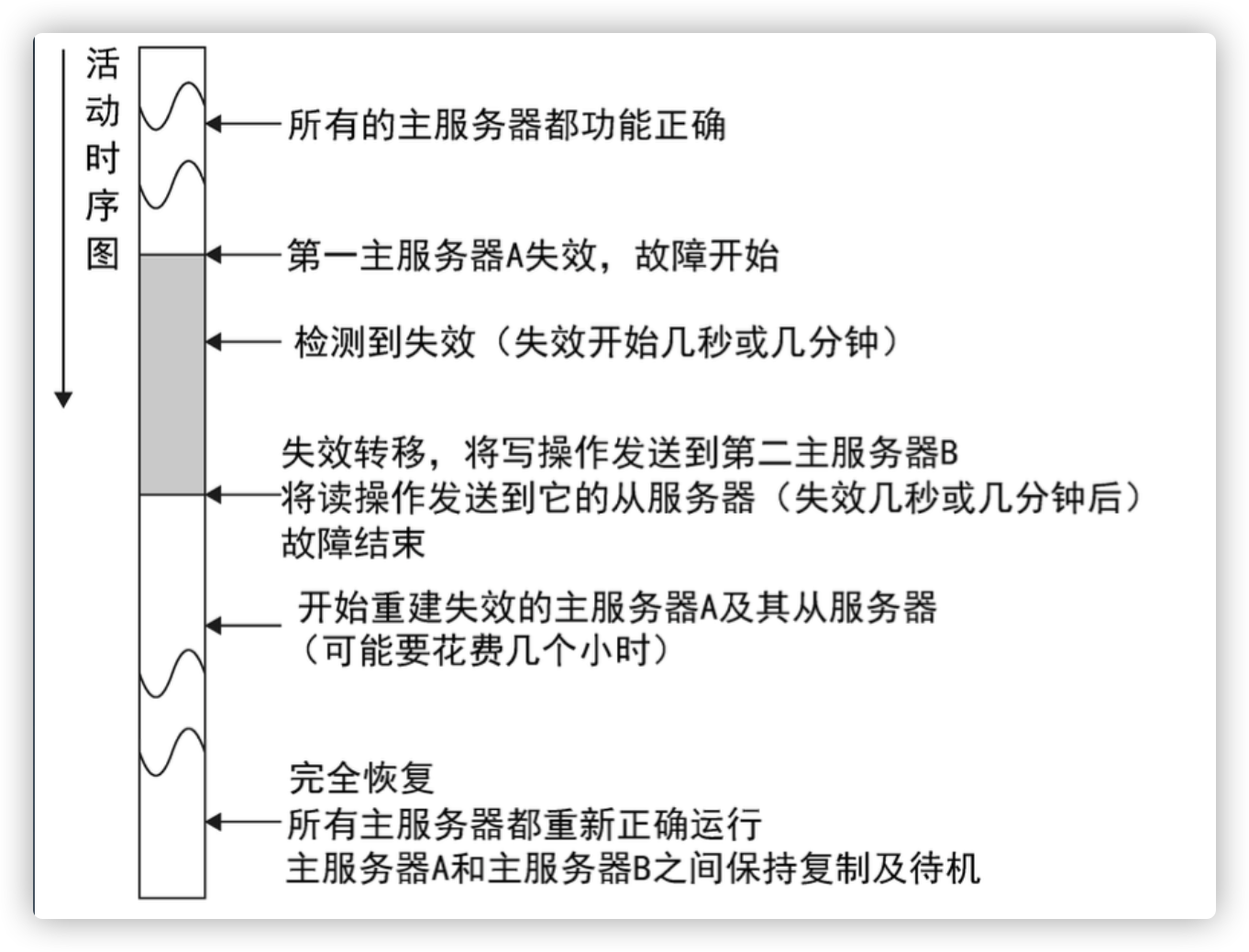
MySQL主主复制失效恢复
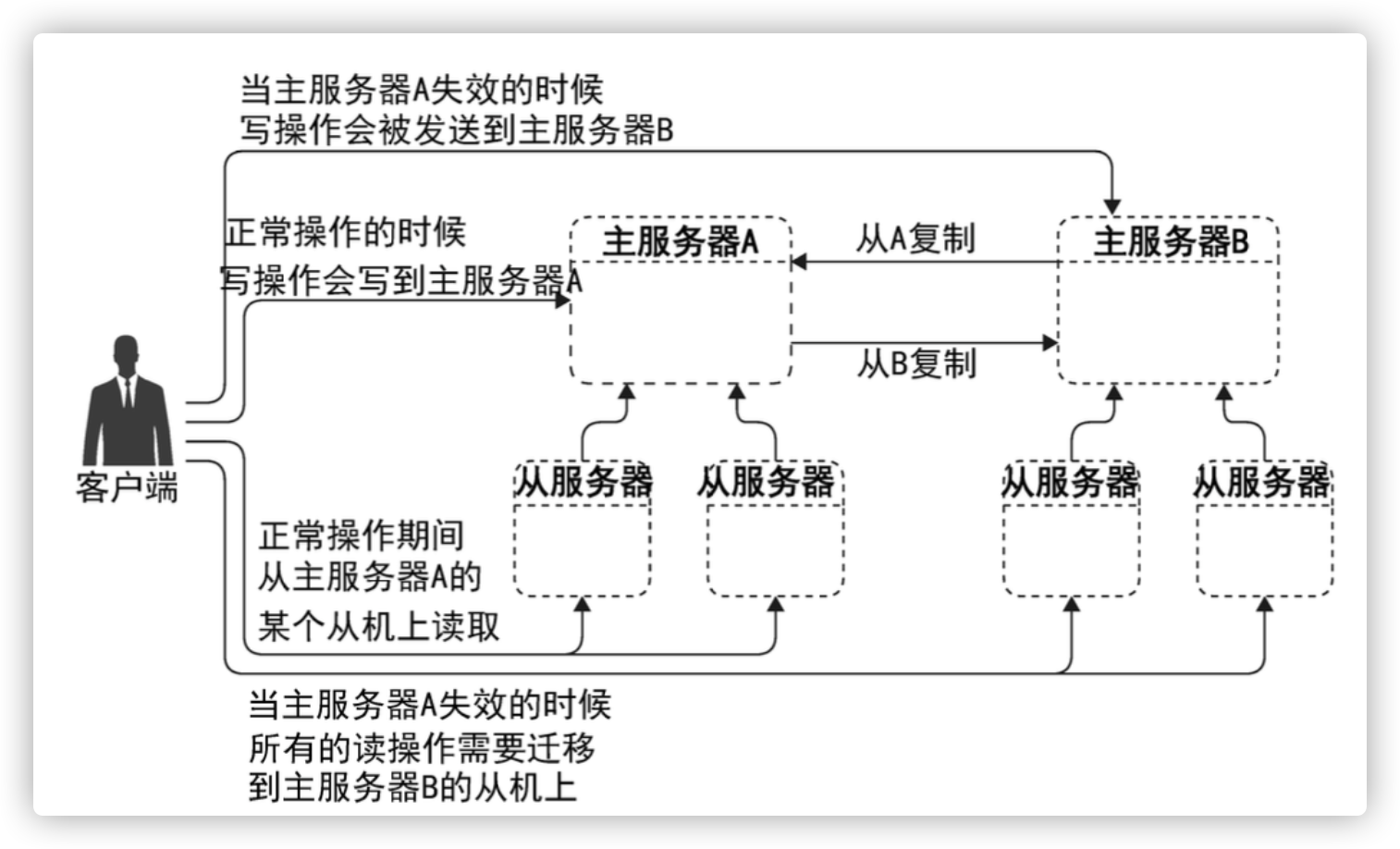
MySQL主主失效的维护过程
MySQL复制注意事项
主主复制的两个数据库不能并发写入
复制知识增加了数据读写并发处理能力,没有增加写并发能力和储存能力
更新表结构会导致巨大的同步延迟
数据分片
分片目标
分片特点
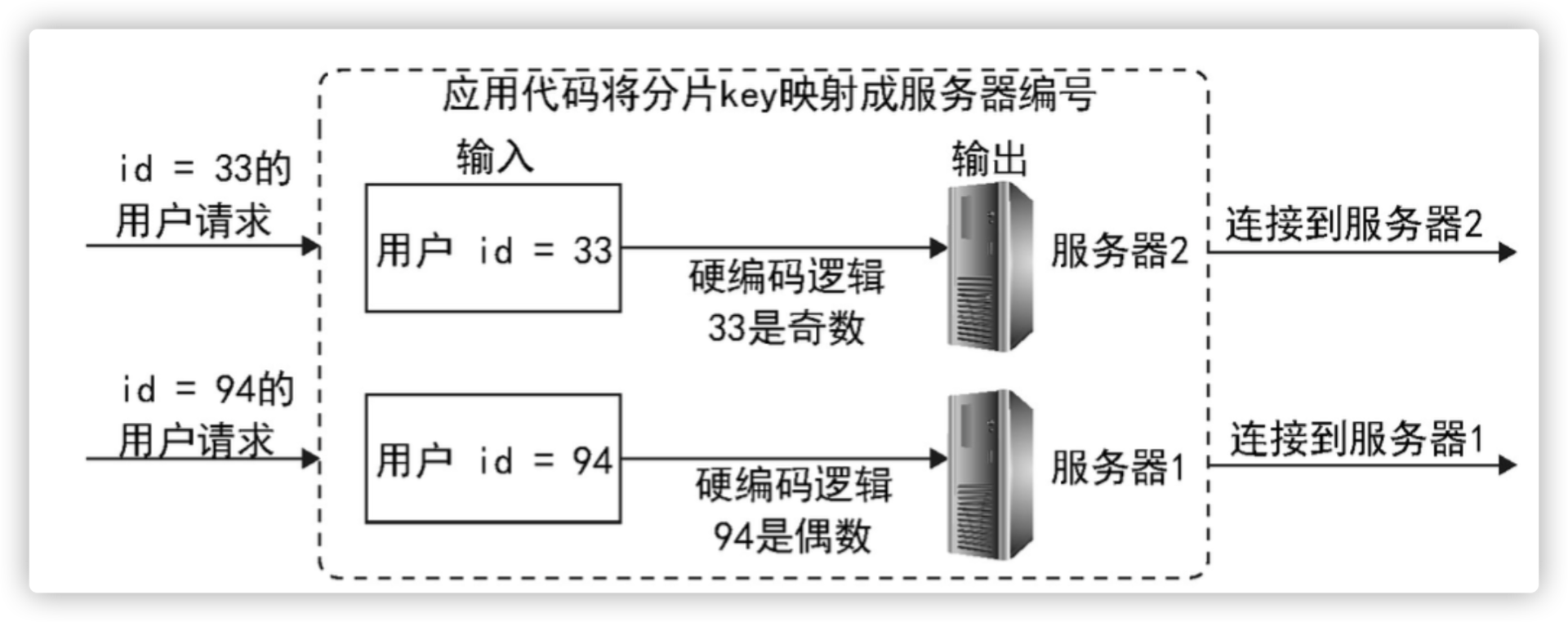
分片原理
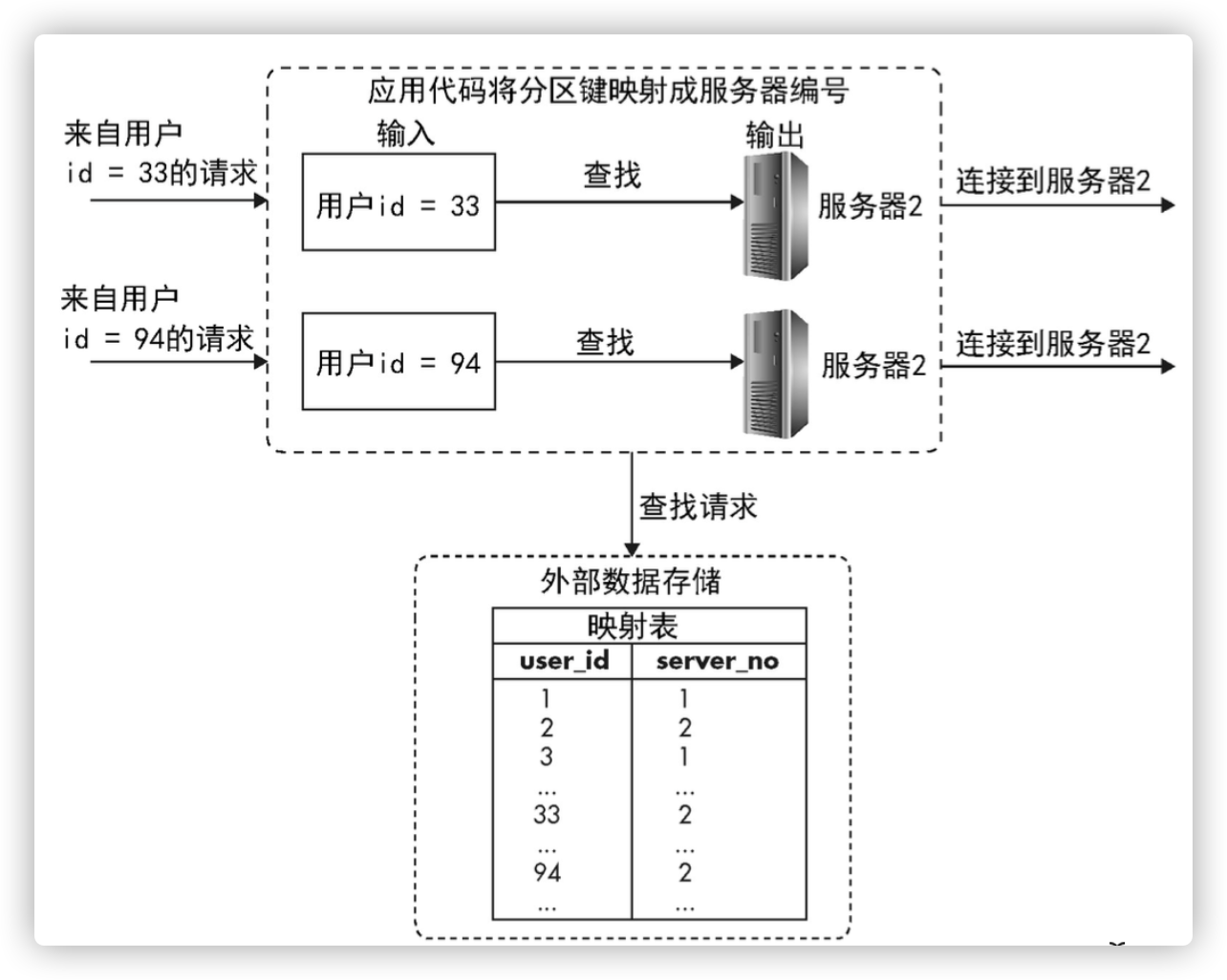
编码实现数据分片
映射表外部存储
6.2分布式关系数据库(下)
数据分片的挑战
需要大量的额外代码处理逻辑,因此变得更加复杂
无法执行多分片的联合查询
无法使用数据库的事务
随着数据的增长、如何增加更多的服务器
分布式数据库中间件
分布式数据库中间件mycat
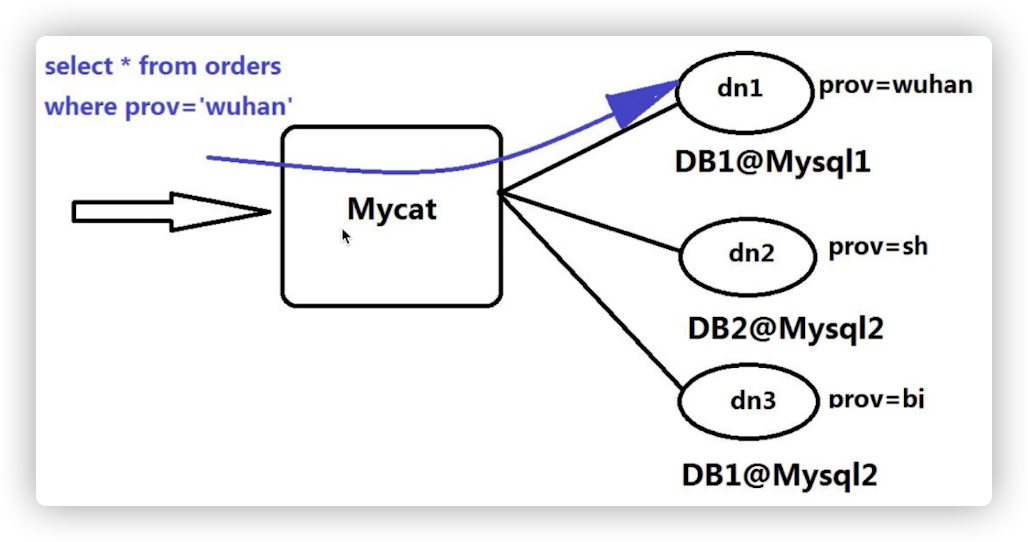
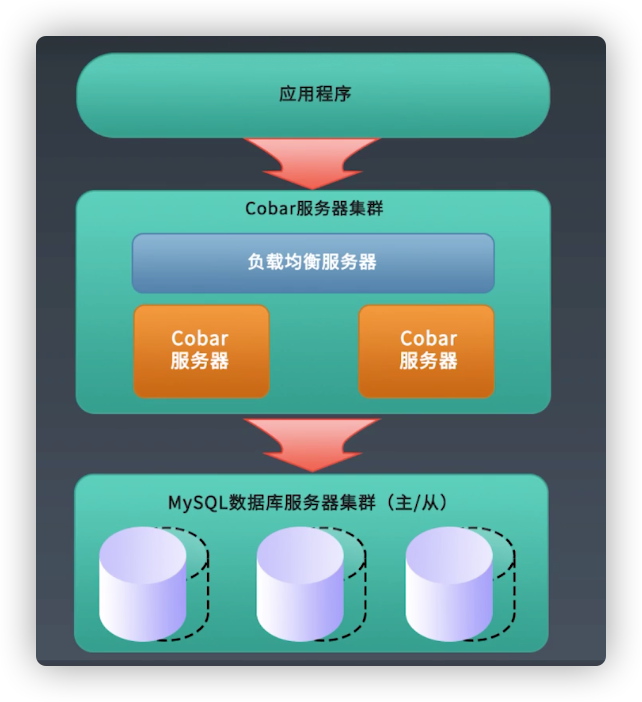
分布式数据库中间件Cobar架构
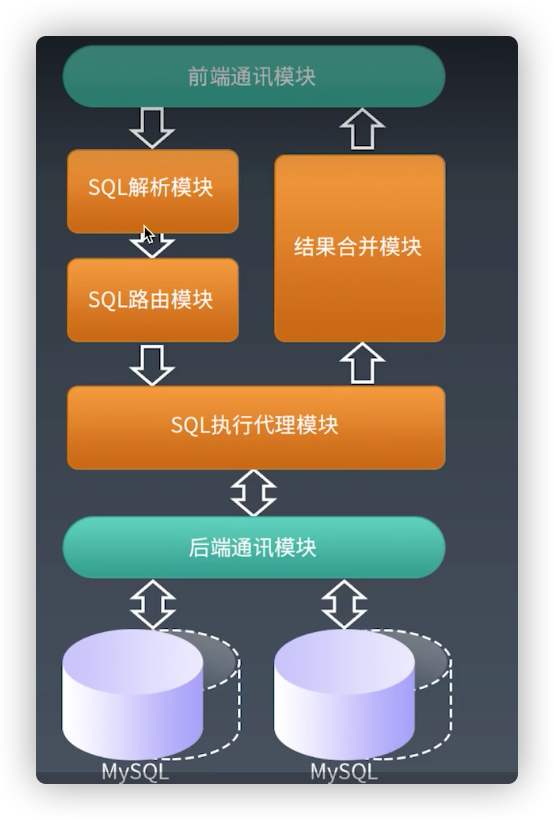
Cobar系统组件模型
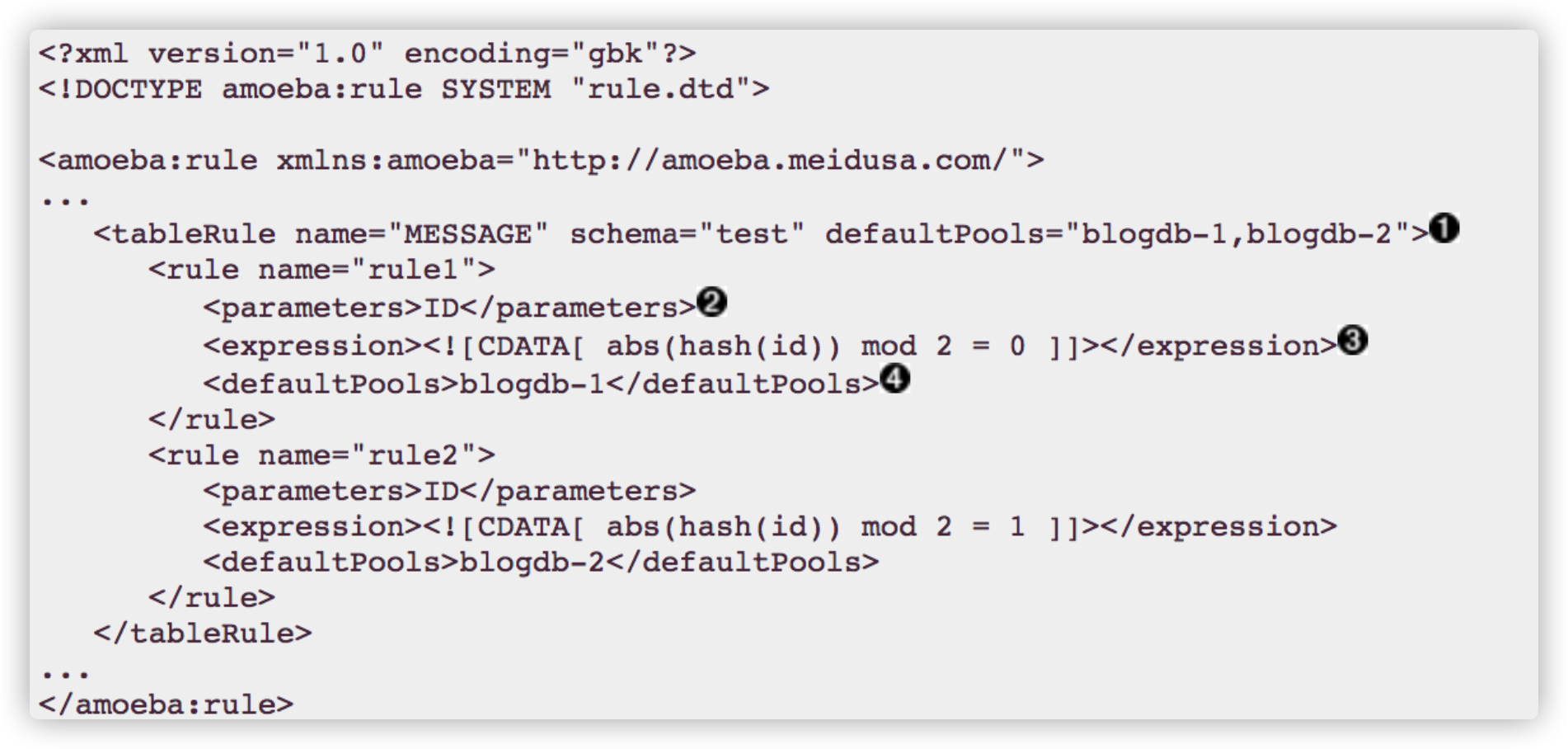
路由配置事例
如何做集群的伸缩
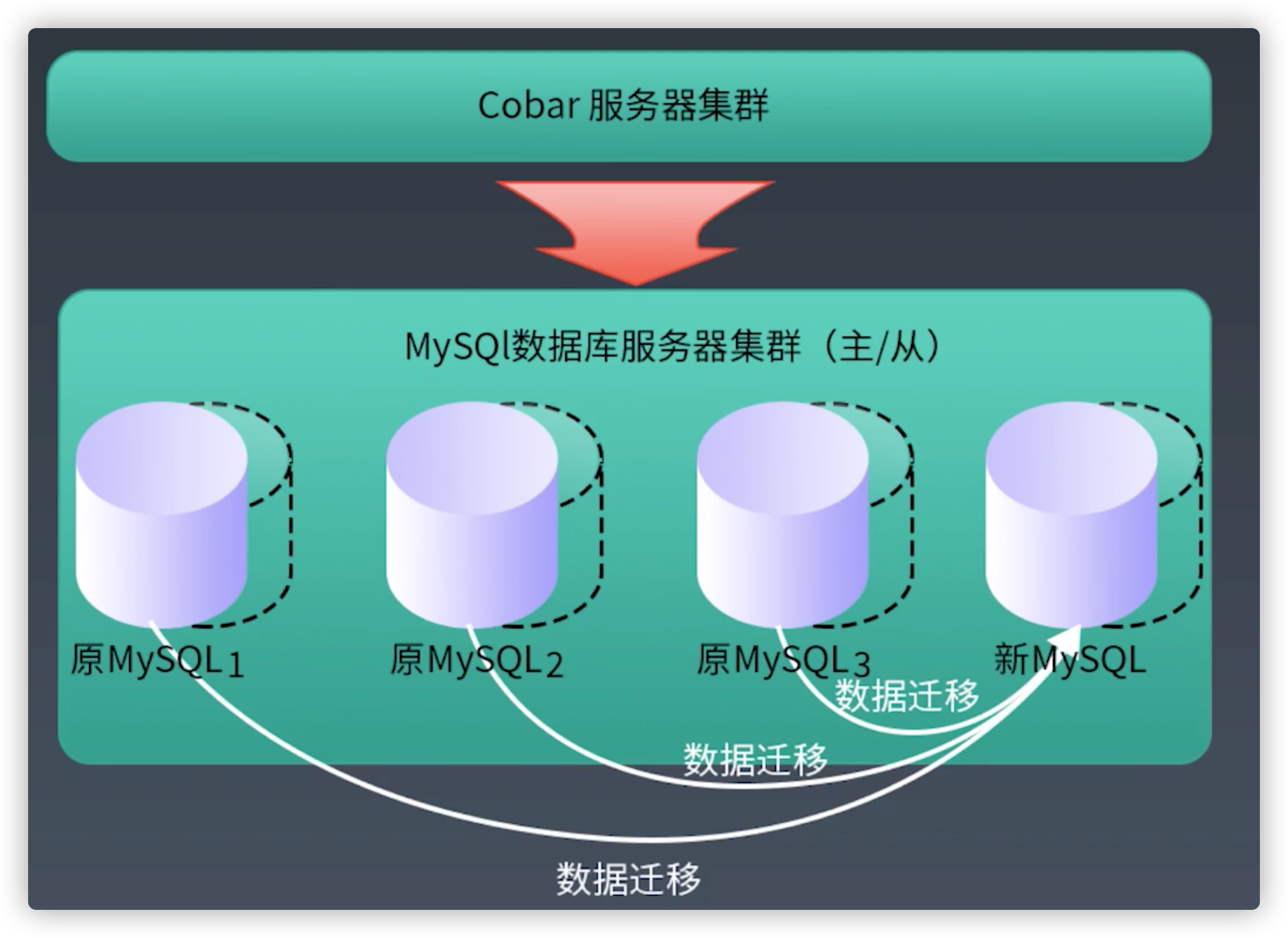
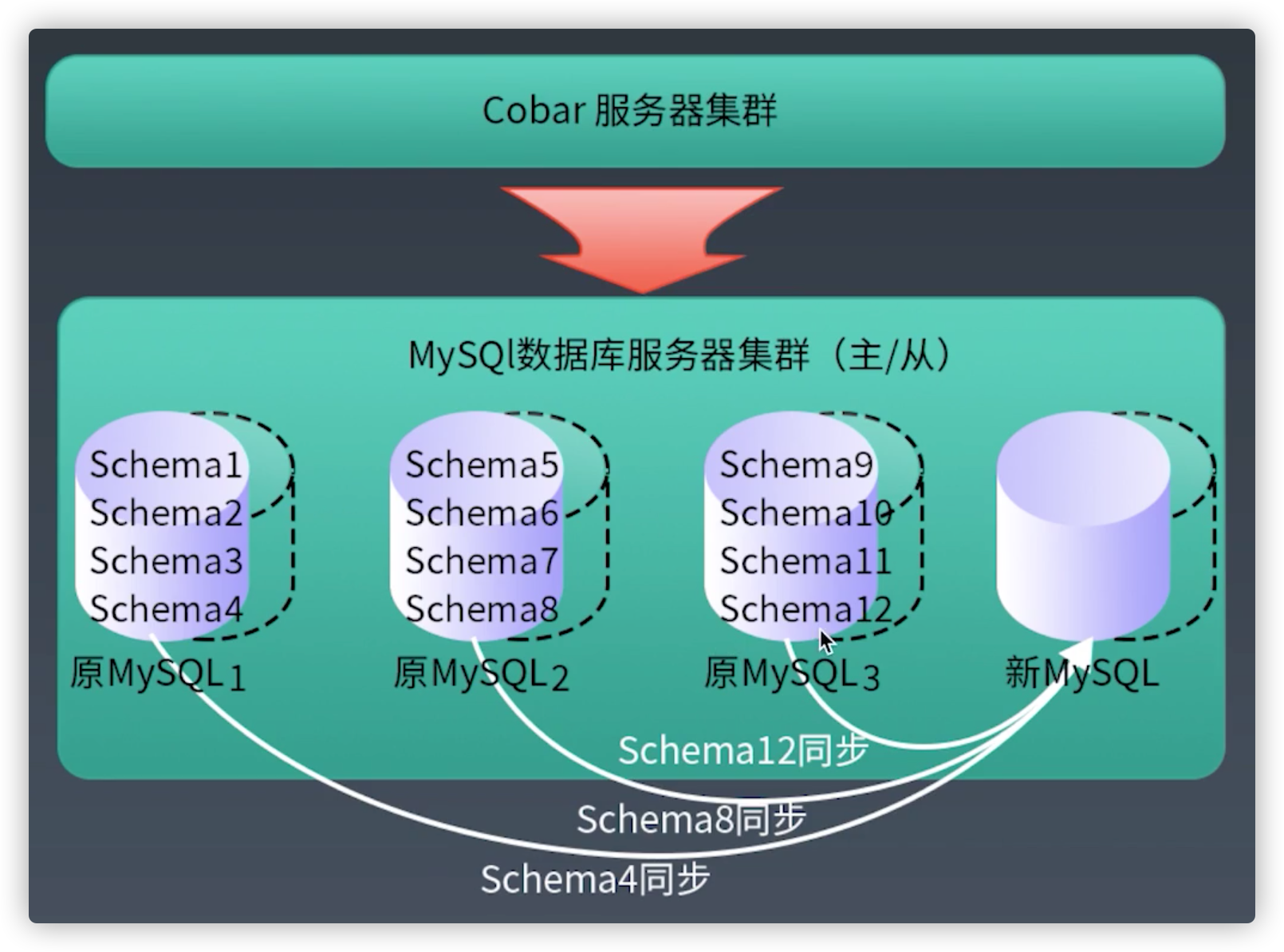
实践中的扩容策略
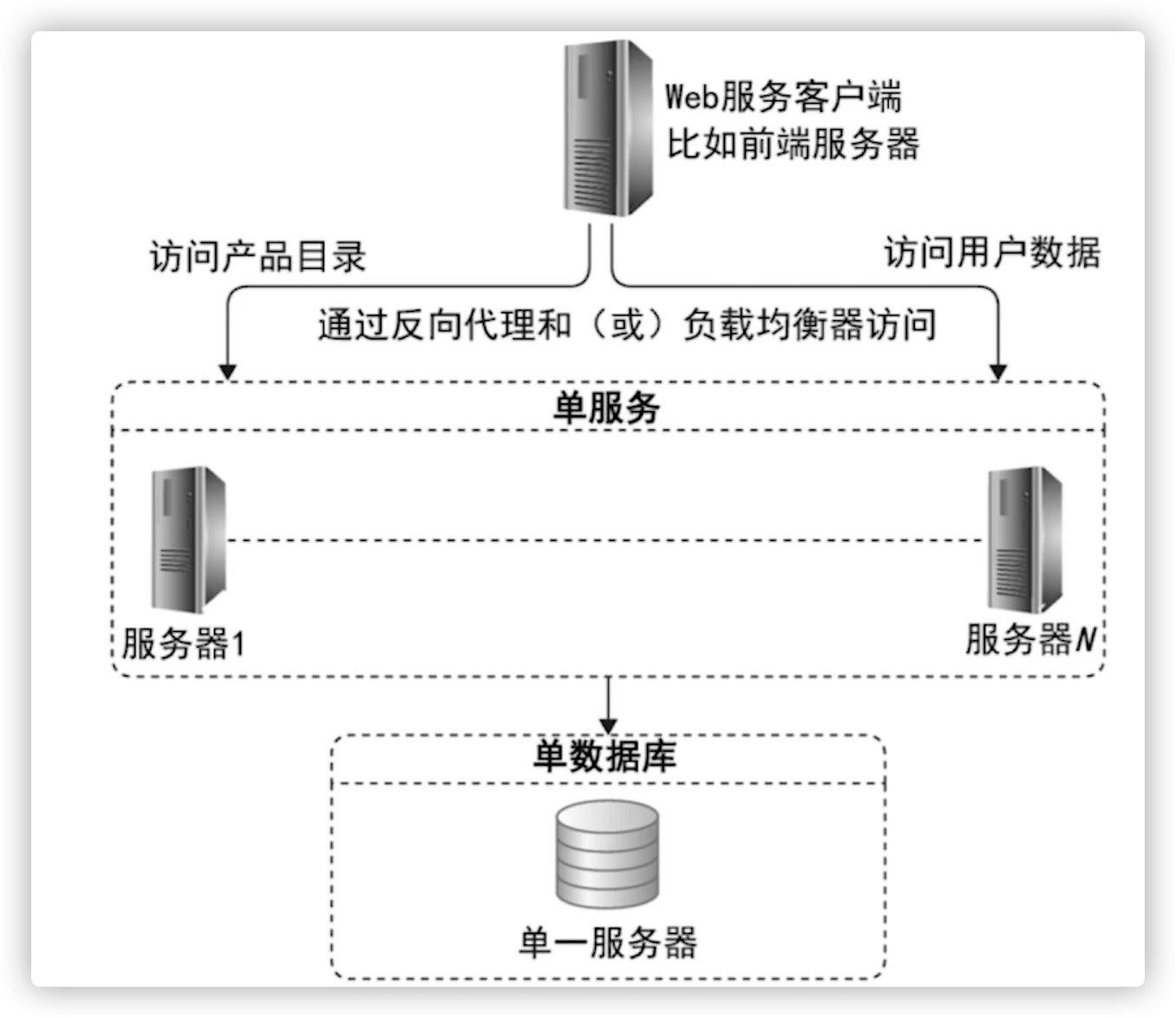
数据库部署方式
数据库部署方式--单一服务与单一数据库
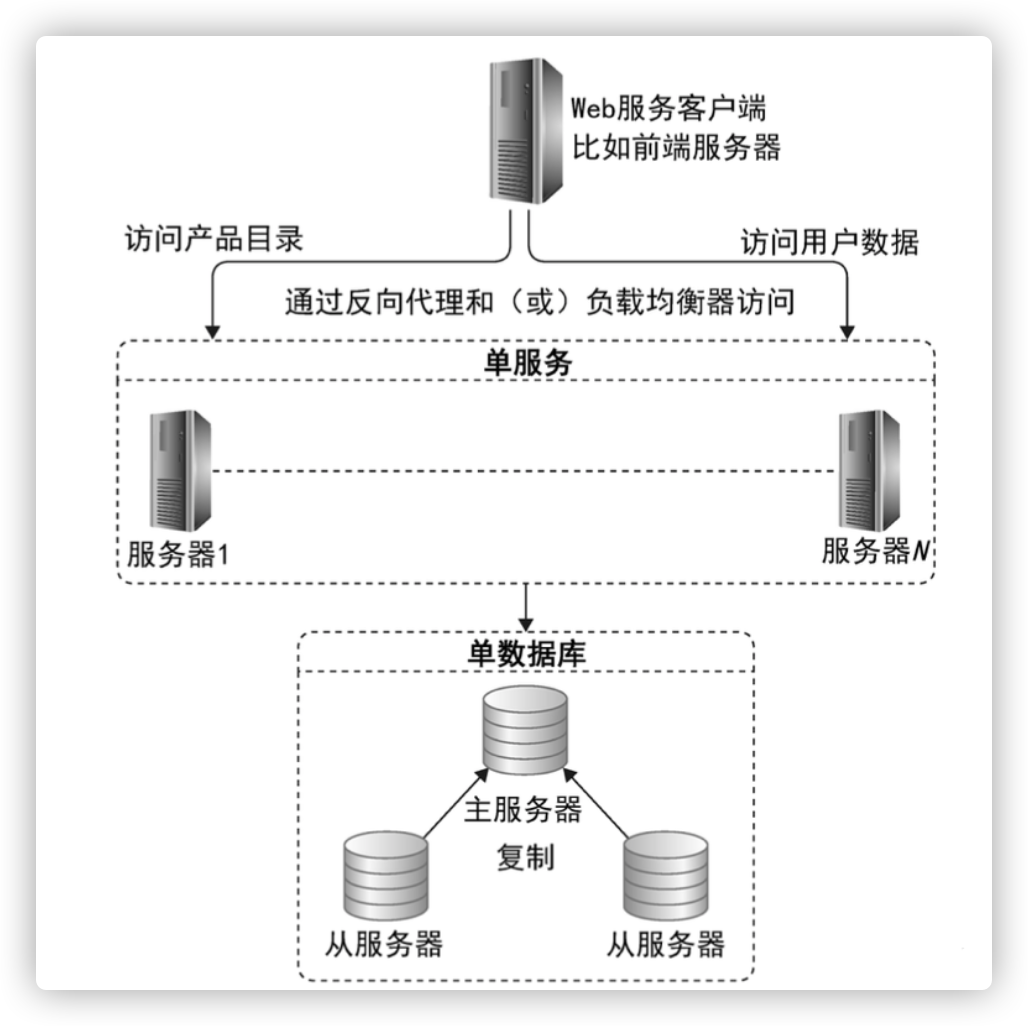
数据库部署方案--主从复制实现伸缩
数据库部署方案--两个web服务和两个数据库
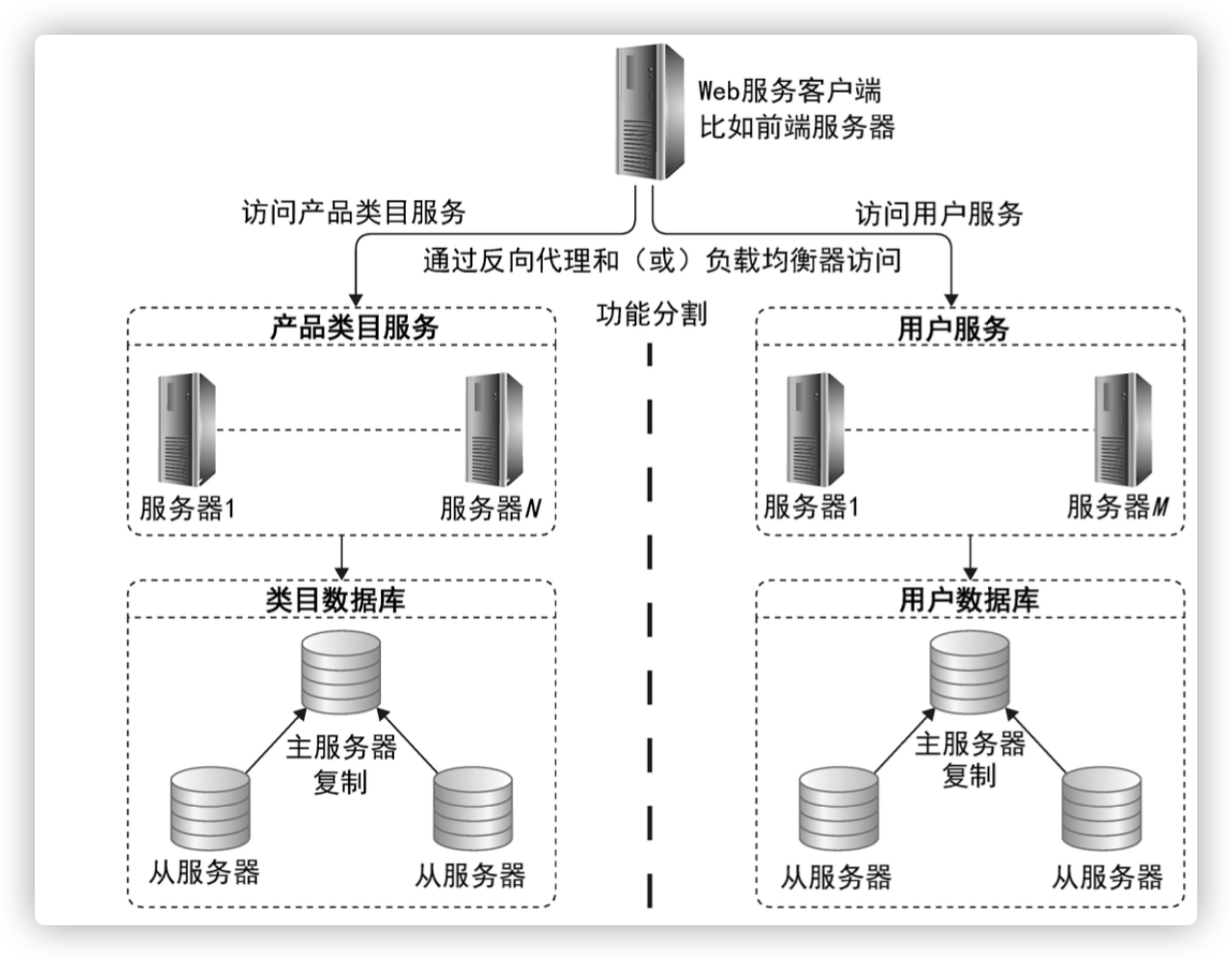
数据库部署方案--综合部署
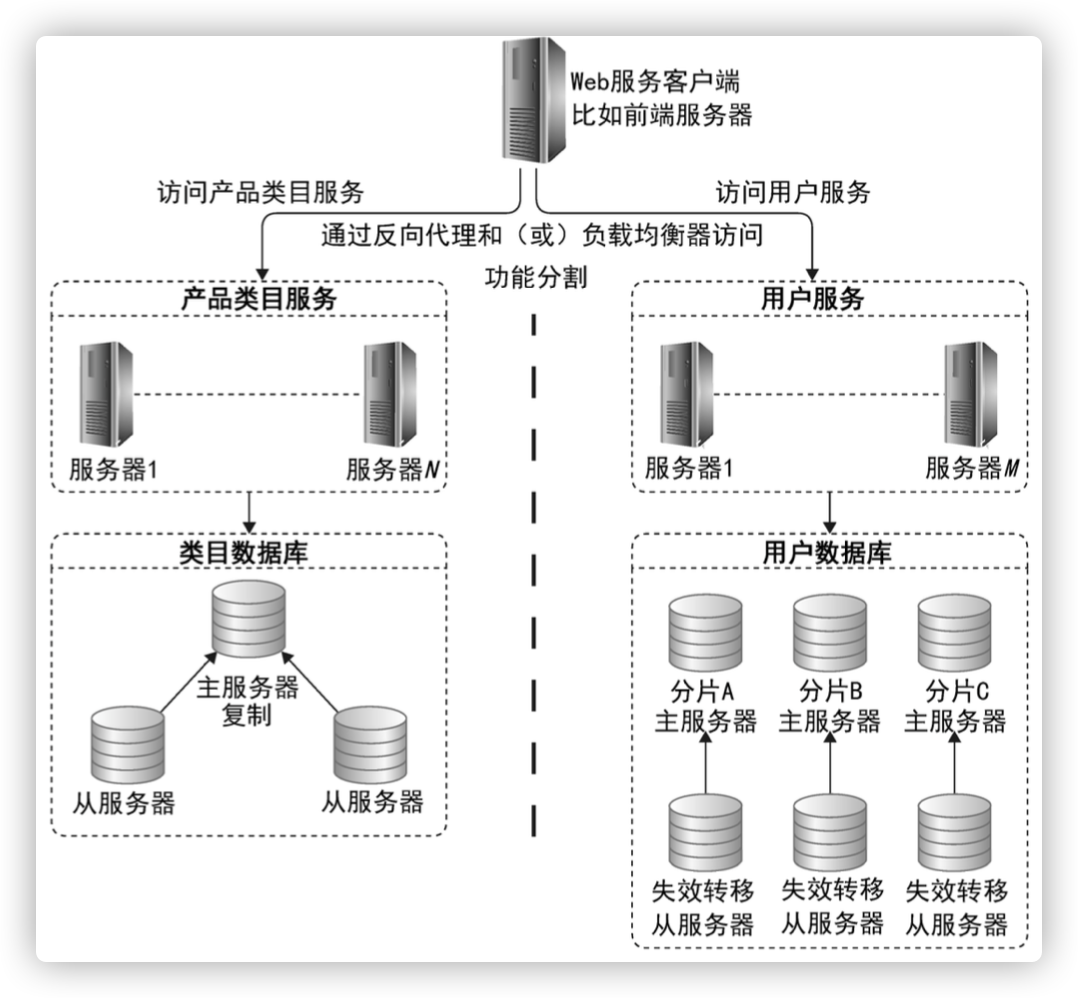
6.3 CAP原理和NoSQL架构
NoSQL
CAP原理
一致性Consistency
一致性是说,每次读取的数据都应该是最近写入的数据或者返回一个错误(Every read receives the most recent write or an error),而不是过期数据,也就是说,数据是一致的。
可用性Availability
可用性是说,每次请求都应该得到一个响应,而不是返回一个错误或者失去响应,不过 这个响应不需要保证数据是最近写入的(Every request receives a (non-error) response, without the guarantee that it contains the most recent write),也就是说系 统需要一直都是可以正常使用的,不会引起调用者的异常,但是并不保证响应的数据是最新的。
分区耐受性Partition tolerance
分区耐受性说,即使因为网络原因,部分服务器节点之间消息丢失或者延迟了,系统依然应该是可以操作的(The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes)。
CAP 原理
当网络分区失效发生的时候,我们要么取消操作,这样数据就是一致的,但是系统却不可用;要么我们继续写入数据,但是数据的一致性就得不到保证。
对于一个分布式系统而言,网络失效一定会发生,也就是说,分区耐受性是必须要保证 的,那么在可用性和一致性上就必须二选一。
当网络分区失效,也就是网络不可用的时候,如果选择了一致性,系统就可能返回一个 错误码或者干脆超时,即系统不可用。如果选择了可用性,那么系统总是可以返回一个 数据,但是并不能保证这个数据是最新的。
所以,关于 CAP 原理,更准确的说法是,在分布式系统必须要满足分区耐受性的前提下, 可用性和一致性无法同时满足。
CAP原理与数据一致性冲突
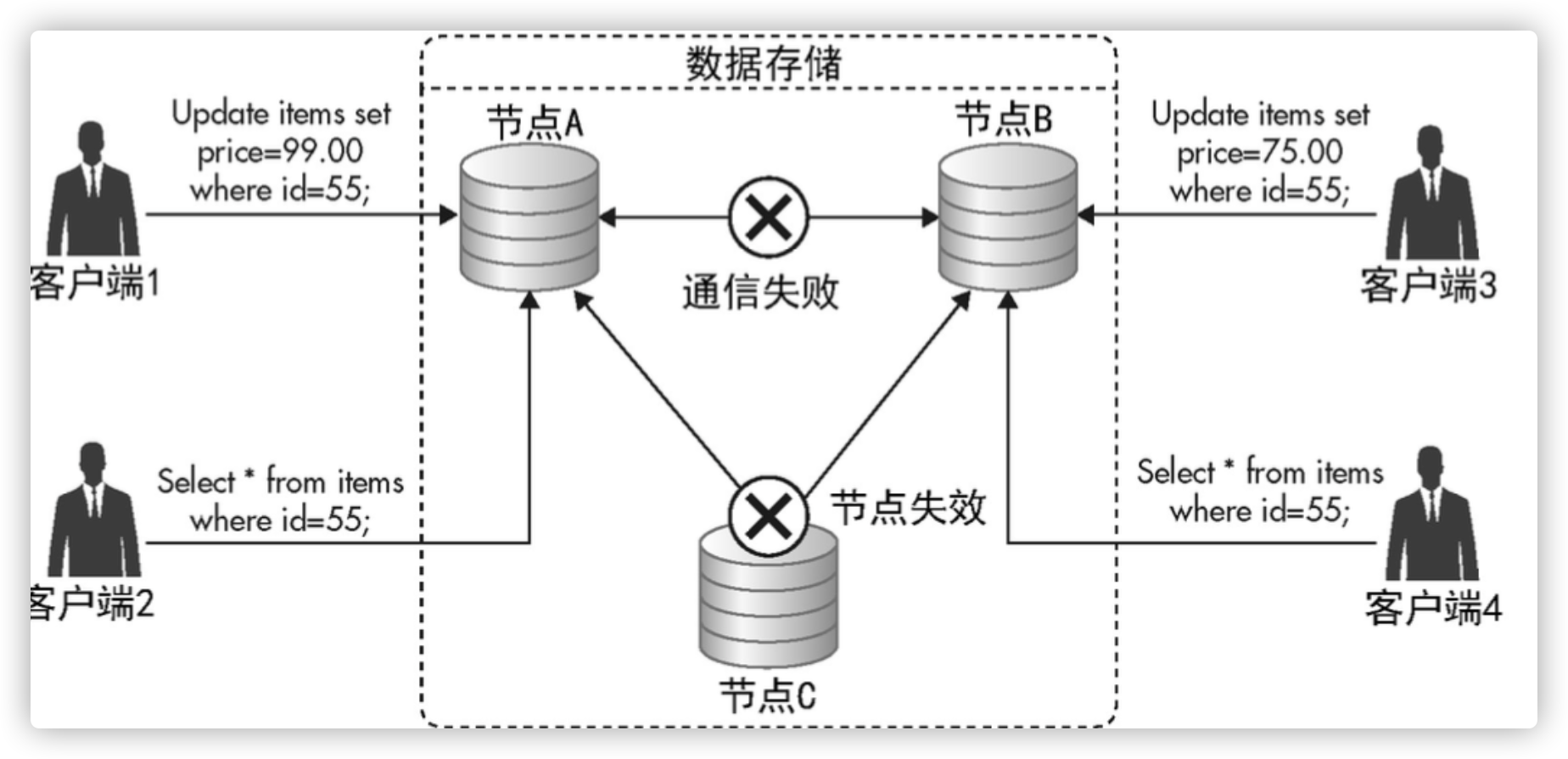
最终一致性
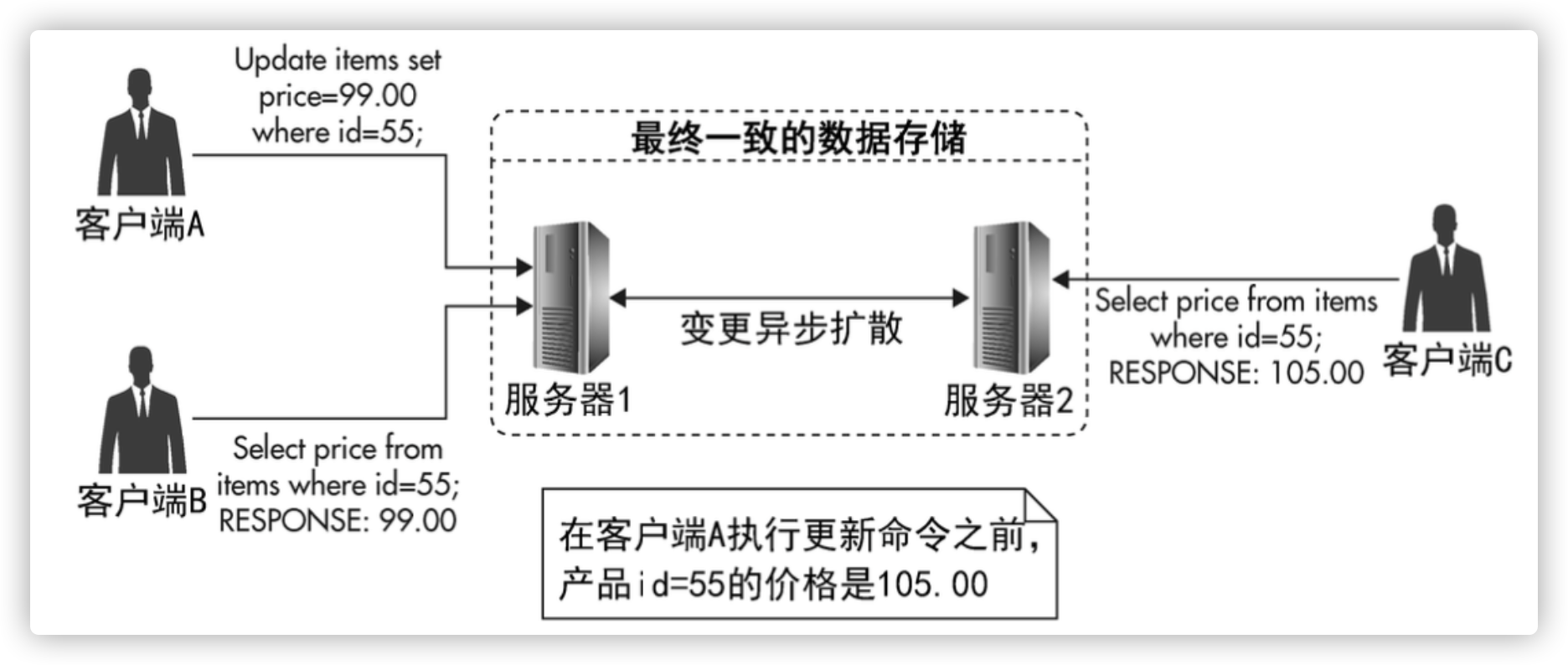
最终一致写操作
简单冲突处理策略:根据时间戳,最后写入覆盖
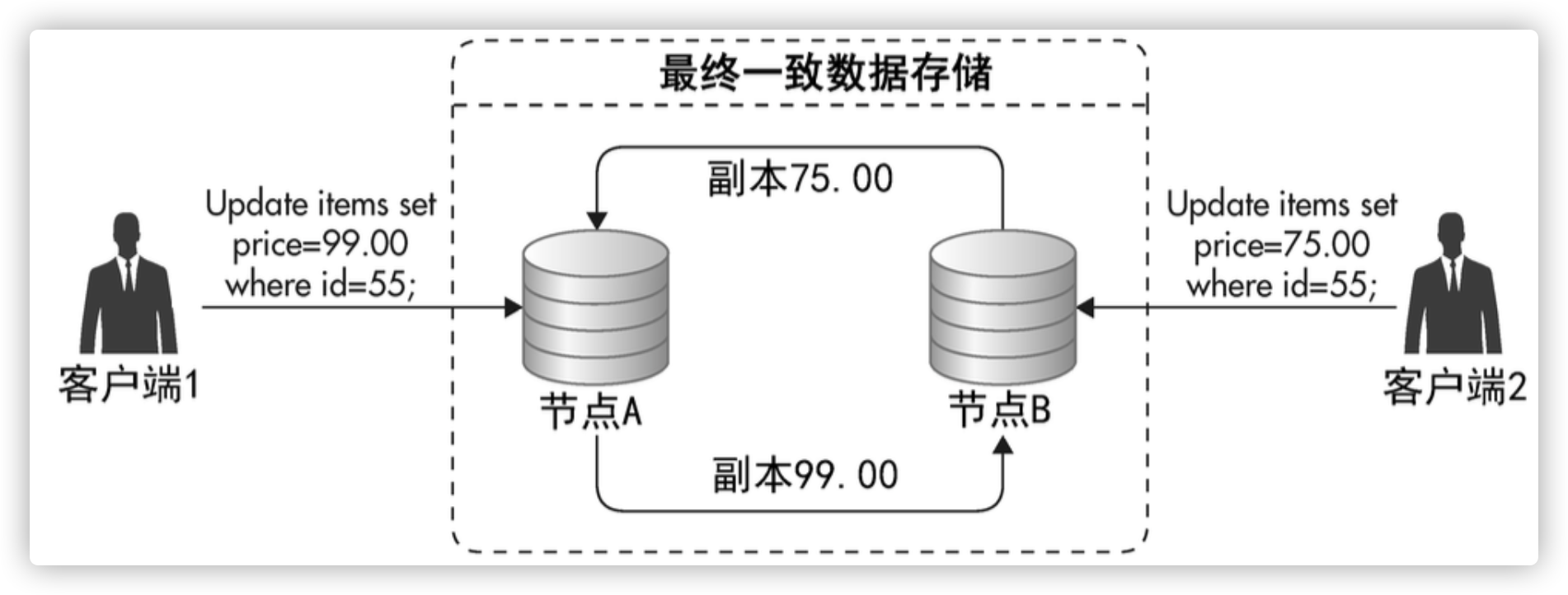
客户端冲突解决
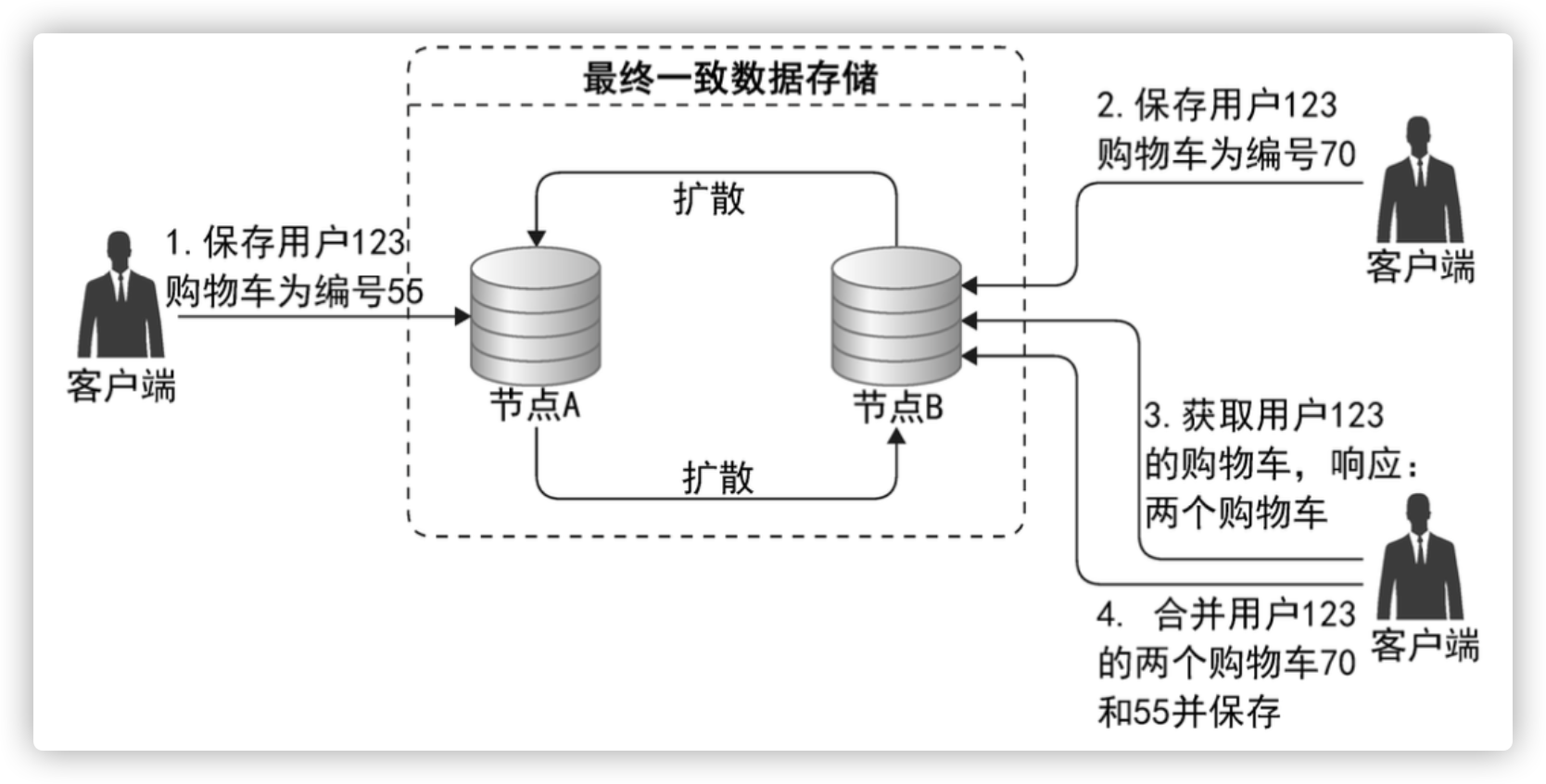
投票解决冲突(Cassandra)
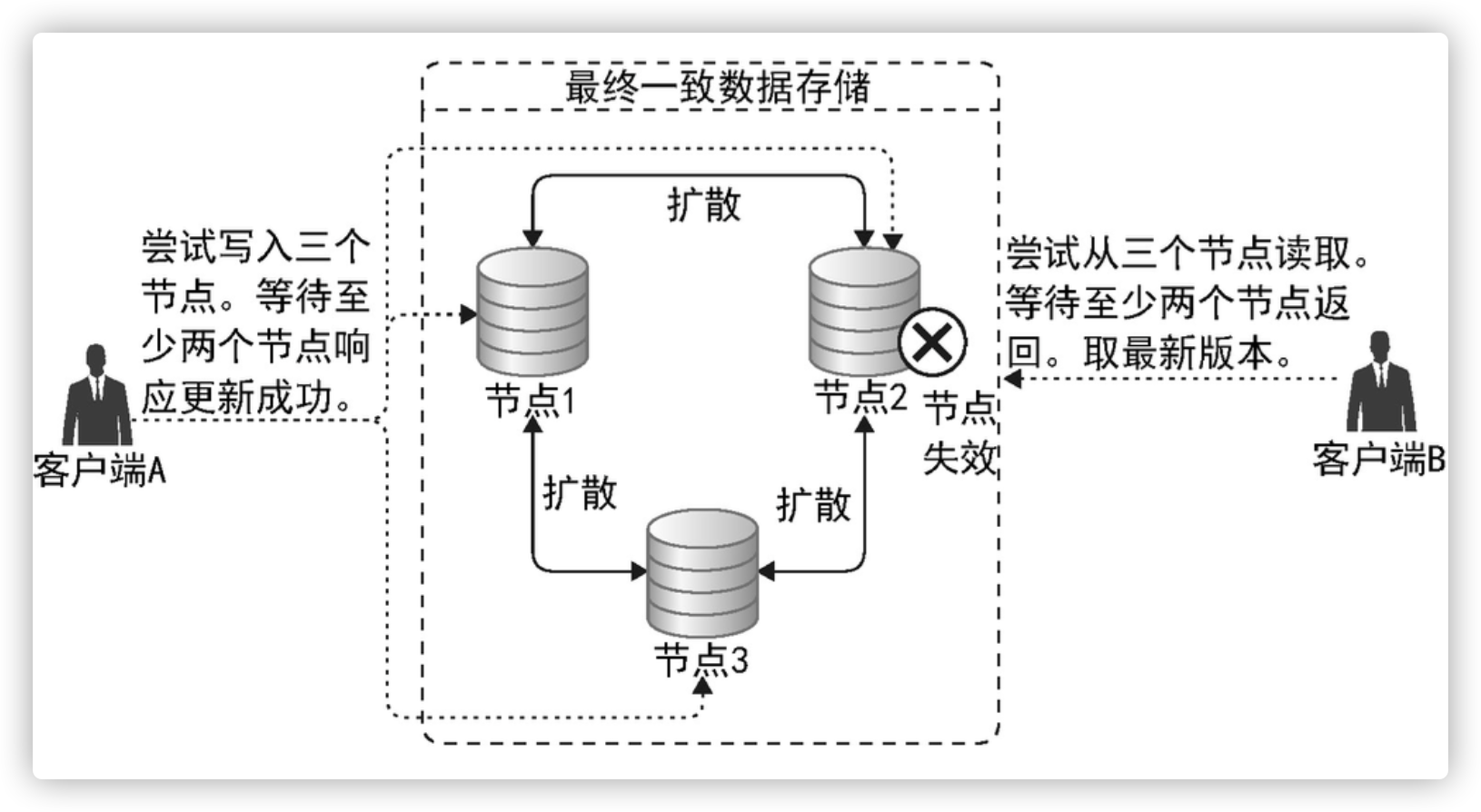
Cassandra分布式架构
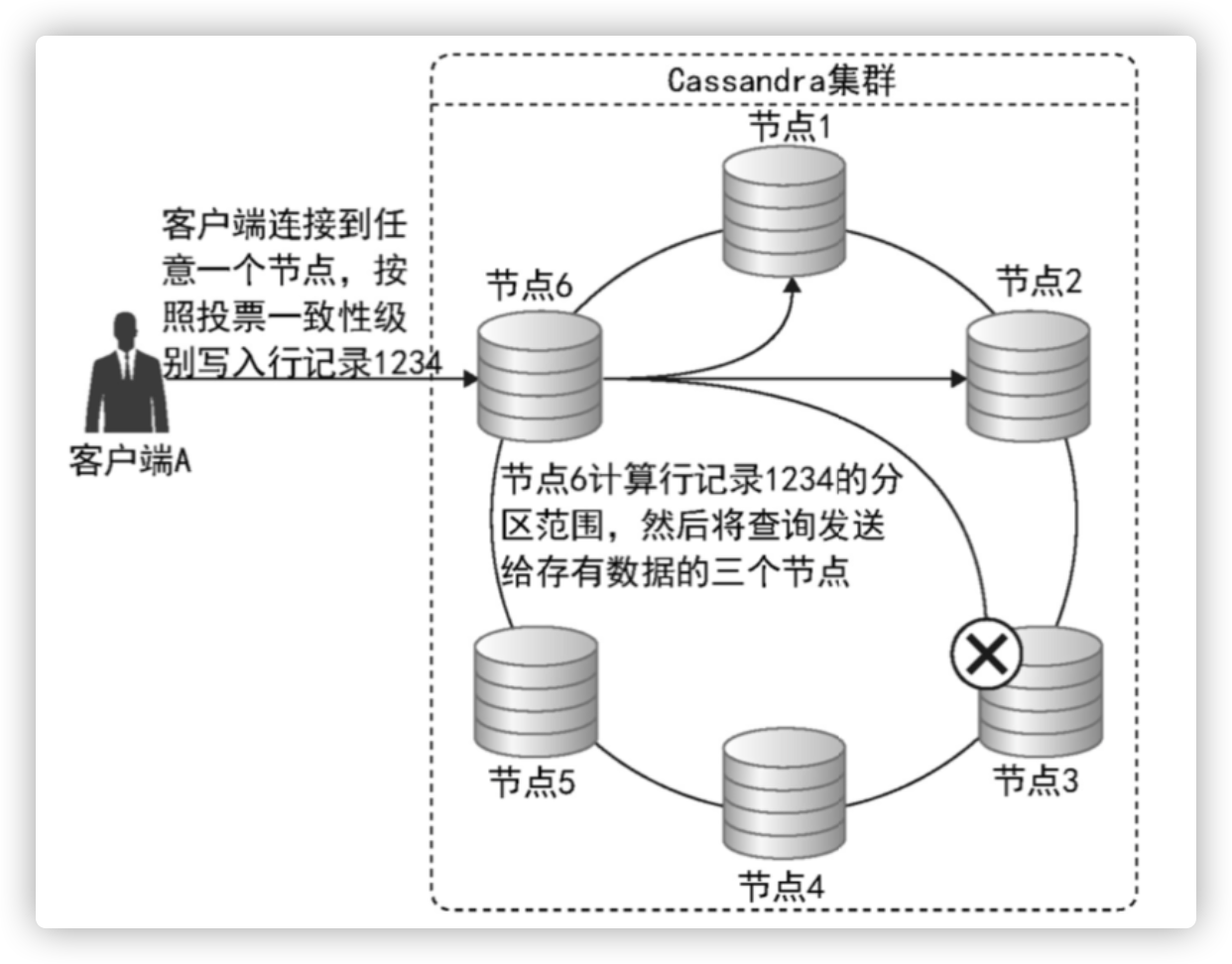
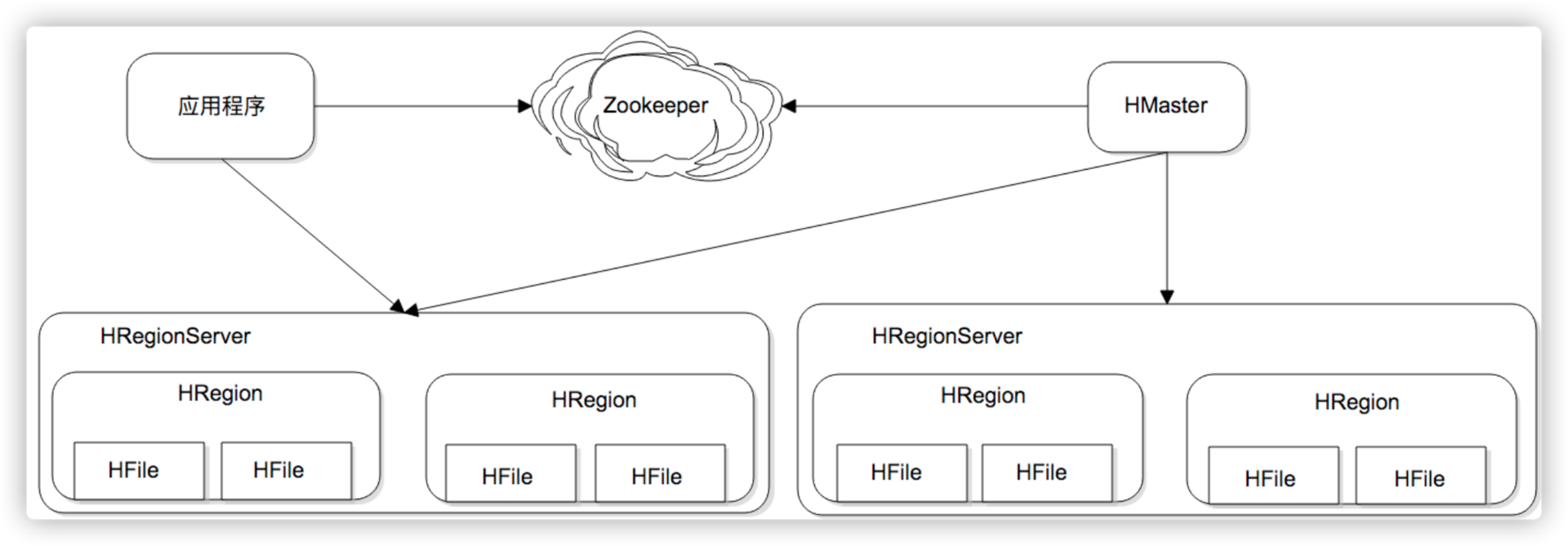
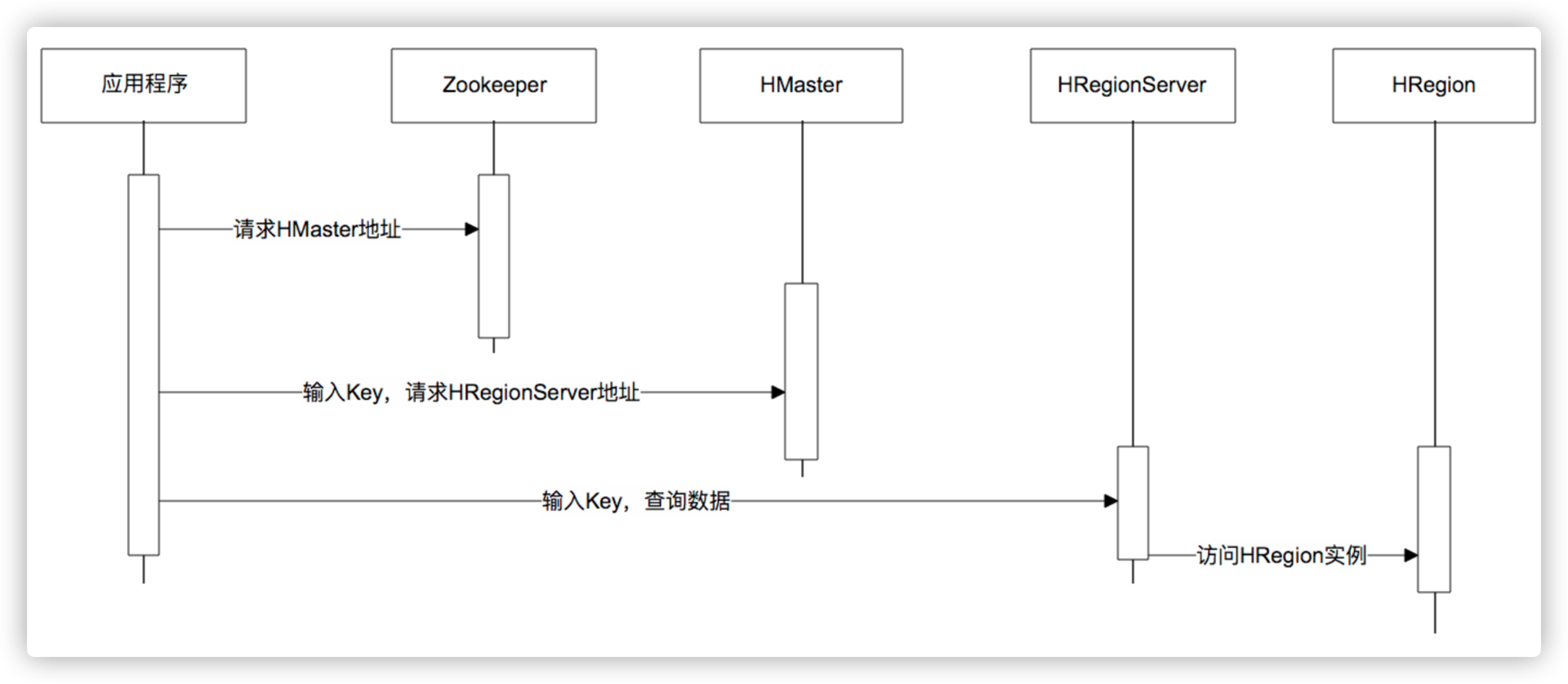
Hbase架构
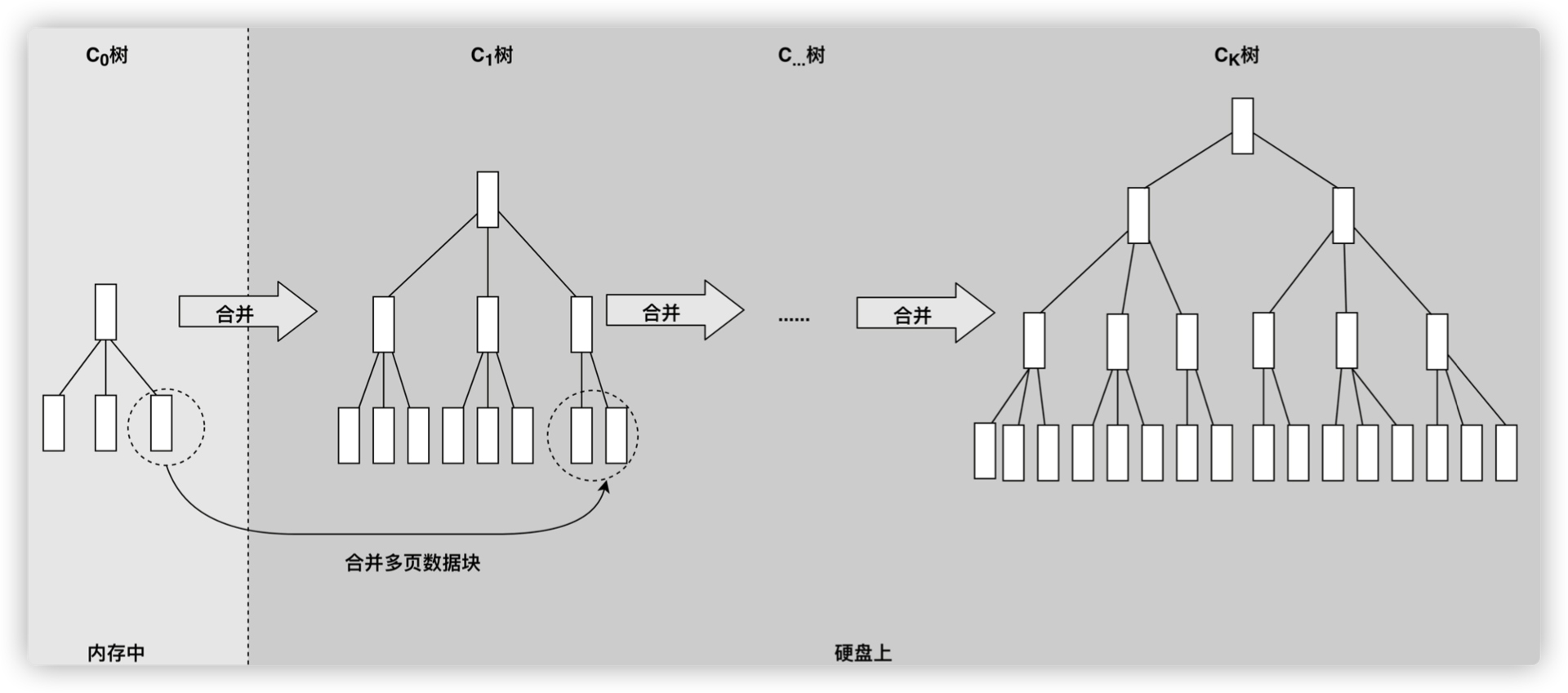
Log Structed Merge Tree(LSM 树)
ACID 与 BASE ACID
原子性(Atomicity): 事务要么全部完成,要么全部取消。 如果事务崩溃,状态回到 事务之前(事务回滚)。
隔离性(Isolation): 如果2个事务 T1 和 T2 同时运行,事务 T1 和 T2 最终的结果是 相同的,不管 T1和T2谁先结束,隔离性主要依靠锁实现。
持久性(Durability): 一旦事务提交,不管发生什么(崩溃或者出错),数据要保存 在数据库中。
一致性(Consistency): 只有合法的数据(依照关系约束和函数约束)才能写入数据 库。
BASE
基本可用(Basically Available)系统在出现不可预知故障时,允许损失部分可用性,如响应时间上的损失或功能上的损失。
Soft state(弱状态)软状态,指允许系统中的数据存在中间状态,并认为该中间状态的 存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步 的过程存在延时。
Eventually consistent(最终一致性)指系统中所有的数据副本,在经过一段时间的同步 后,最终能够达到一个一致的状态,因此最终一致性的本质是需要系统保证数据能够达 到一致,而不需要实时保证系统数据的强一致性。
6.4 ZooKeeper与分布式一致性架构
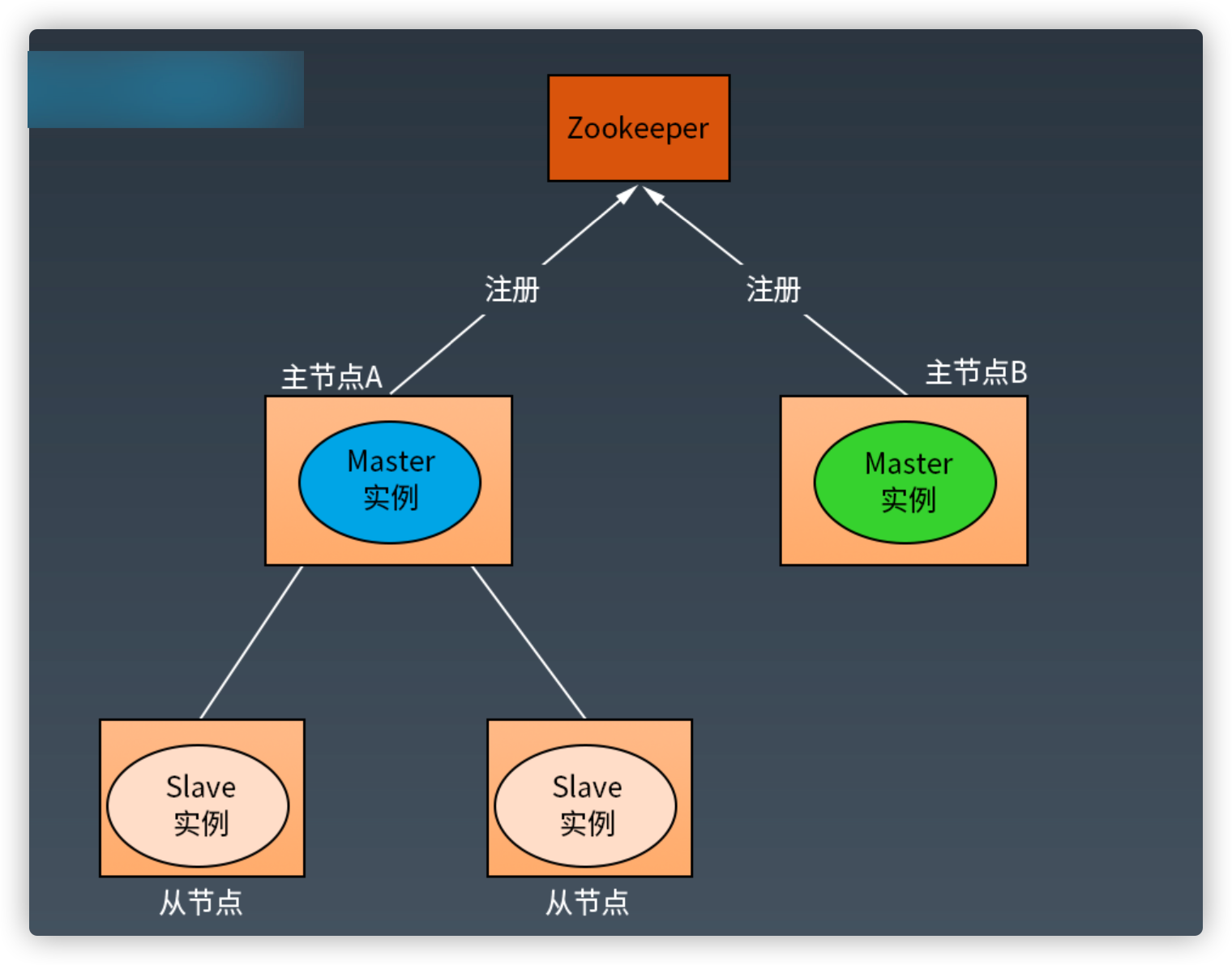
分布式系统脑裂
在一个分布式系统中,不同服务器获得了互相冲突的数据信息或者执行指令,导致整个 集群陷入混乱,数据损坏,本称作分布式系统脑裂。
数据库主主备份
分布式一致性算法PaxOS
三个角色
Proposer
Acceptor
LLearner
投票
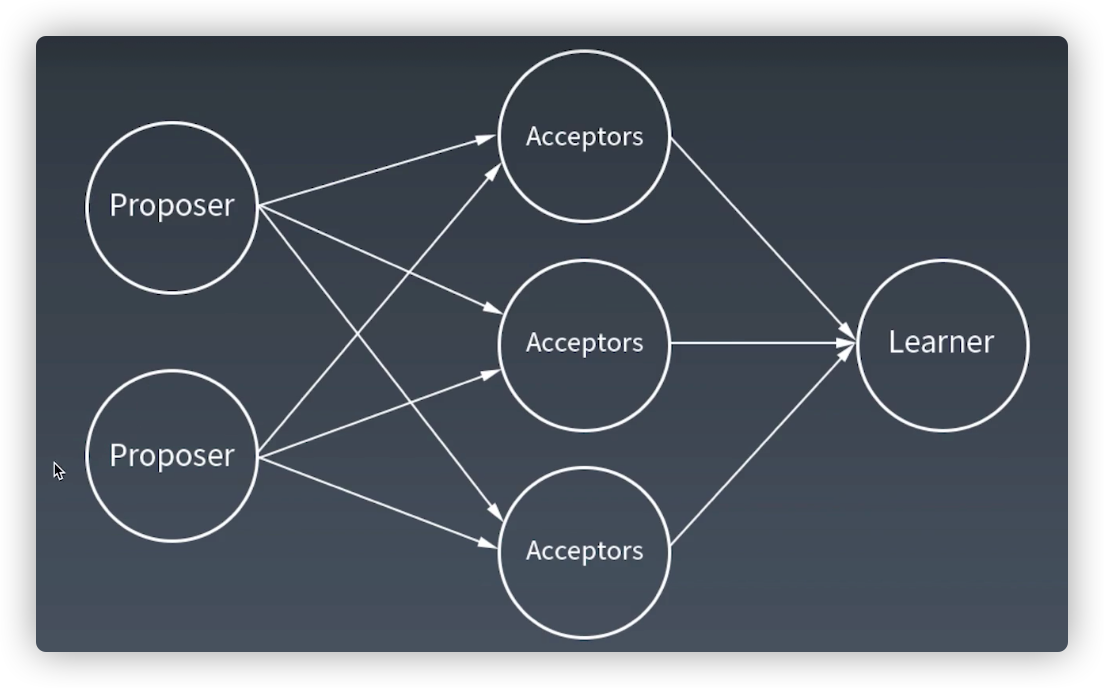
三个阶段
第一阶段:Prepare 阶段。Proposer 向 Acceptors 发出 Prepare 请求,Acceptors 针对 收到的 Prepare 请求进行 Promise 承诺。
第二阶段:Accept 阶段。Proposer 收到多数 Acceptors 承诺的 Promise 后,向 Acceptors 发出 Propose 请求,Acceptors 针对收到的 Propose 请求进行 Accept 处理。
第三阶段:Learn 阶段。Proposer 在收到多数 Acceptors 的 Accept 之后,标志着本次 Accept 成功,决议形成,将形成的决议发送给所有 Learners。
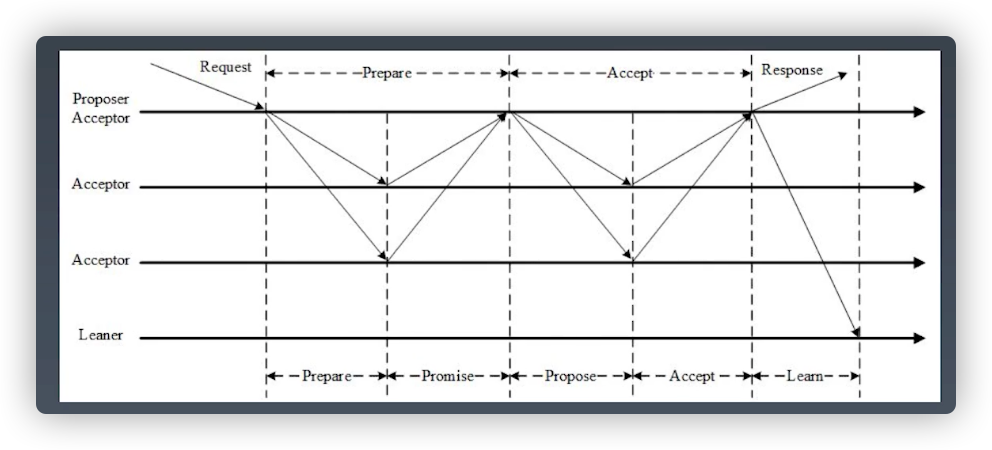
Proposer 生成全局唯一且递增的 Proposal ID (可使用时间戳加Server ID),向所有 Acceptors 发送 Prepare 请求,这里无需携带提案内容,只携带 Proposal ID 即可。
Acceptors 收到 Prepare 和 Propose 请求后
不再接受 Proposal ID 小于等于当前请求的 Prepare 请求。
不再接受 Proposal ID 小于当前请求的 Propose 请求。
Zab协议
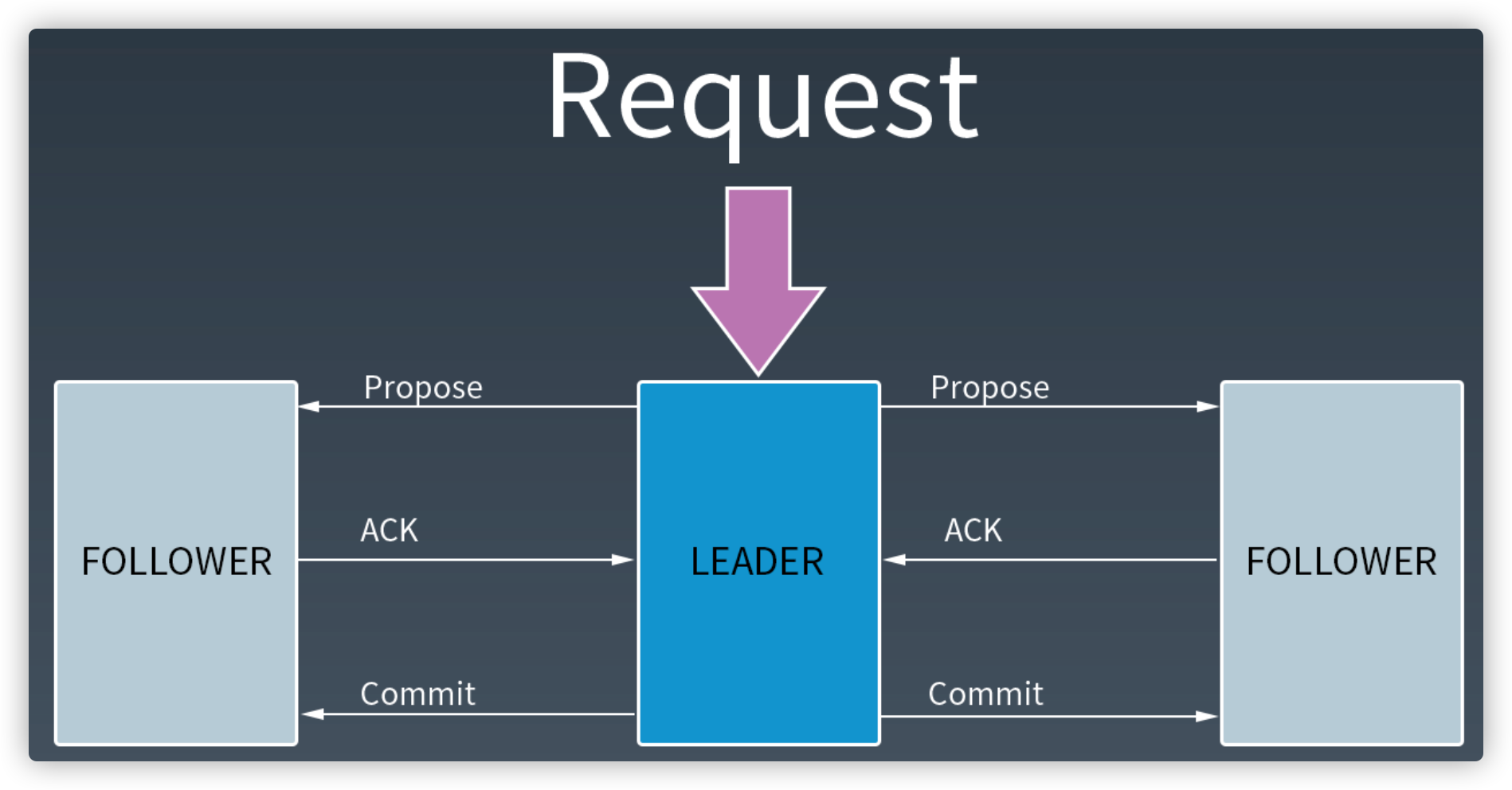
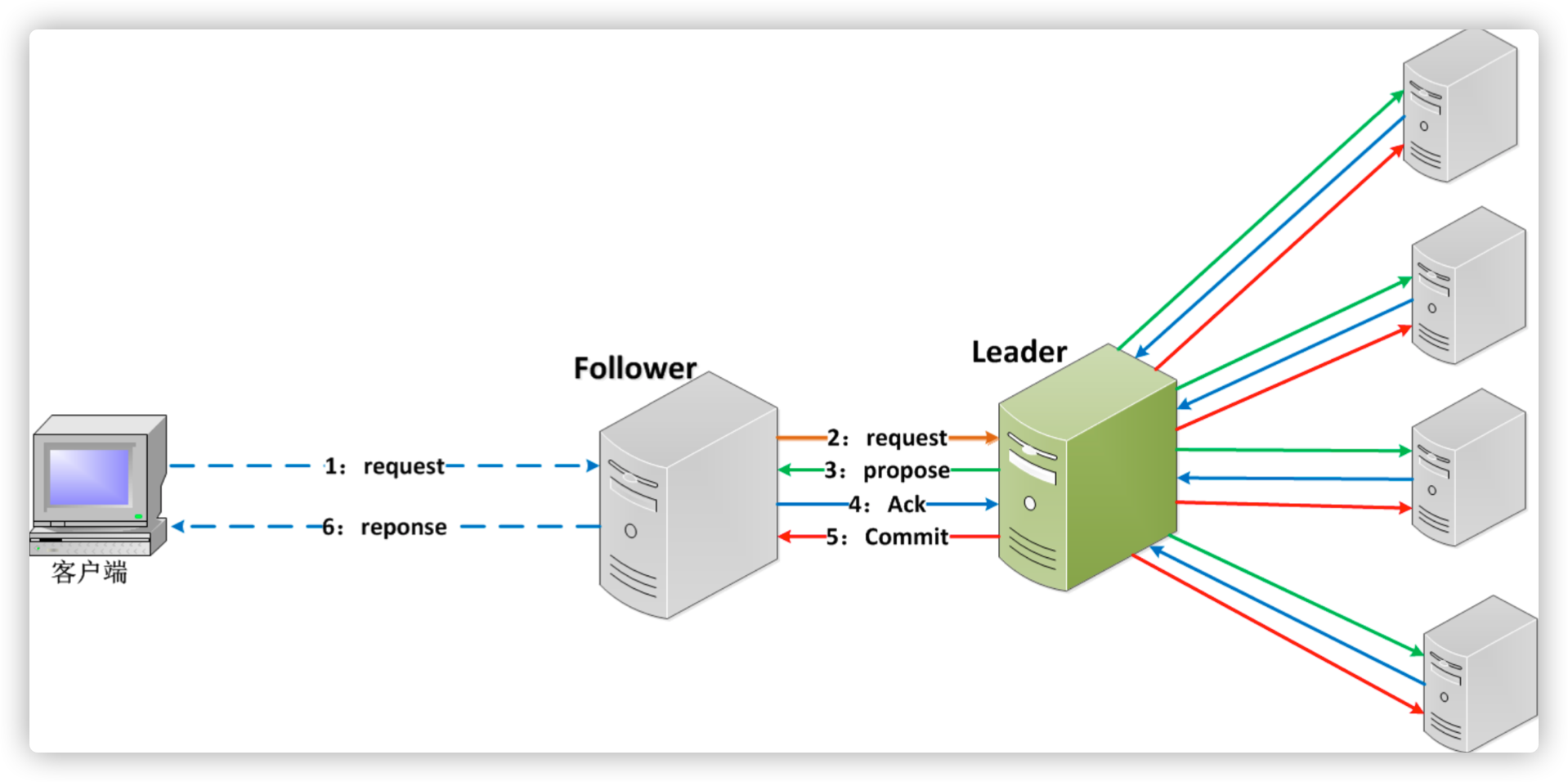
ZooKeeper架构
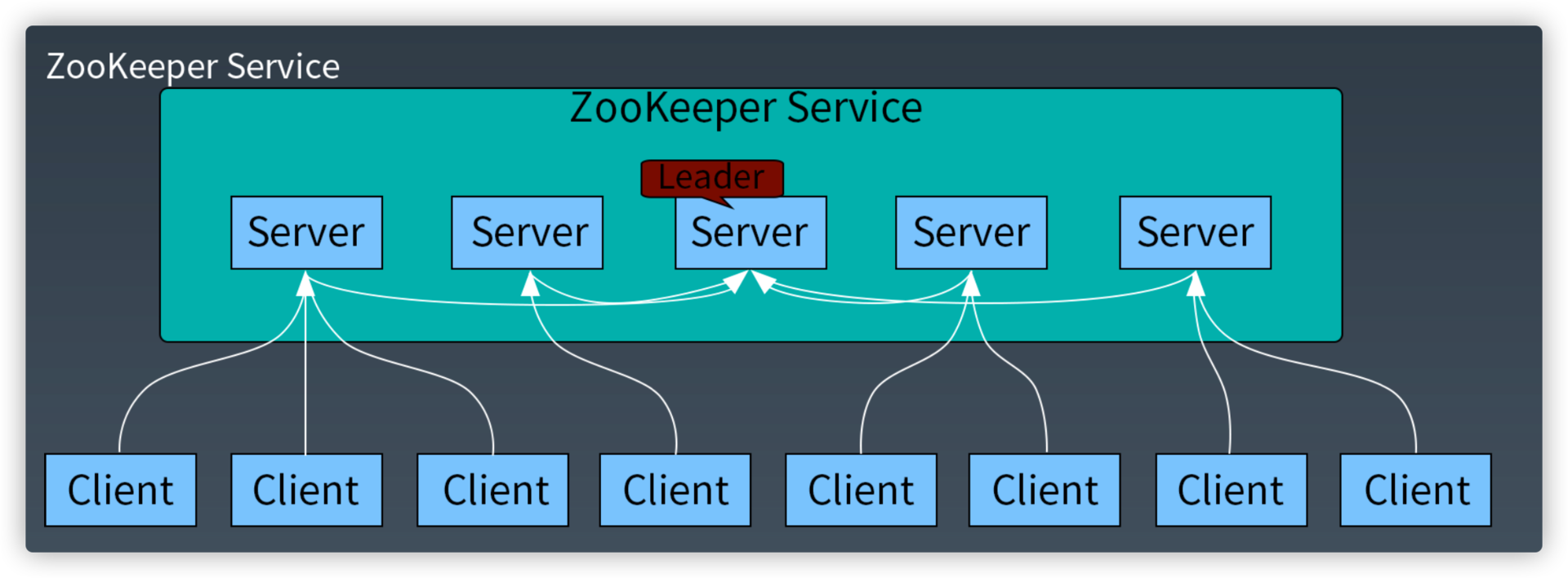
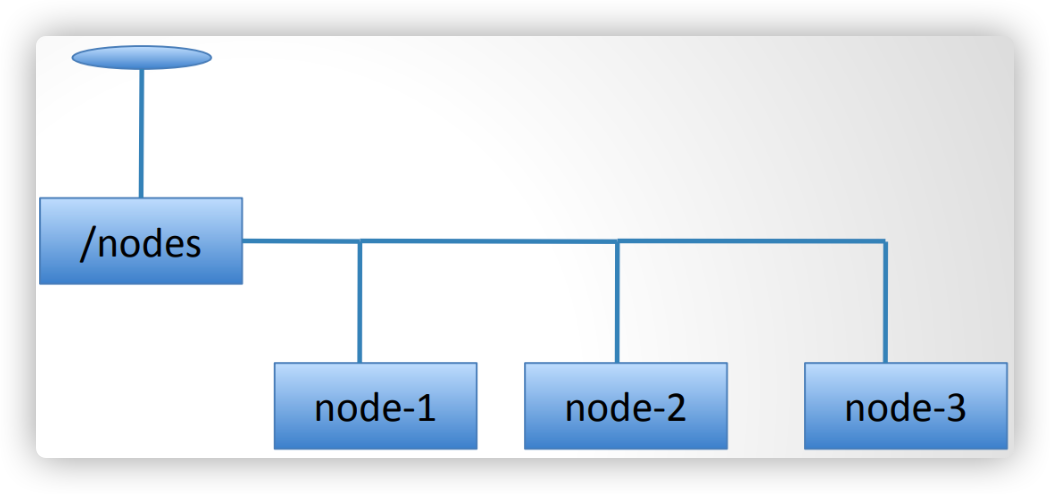
ZooKeeper 的树状记录结构
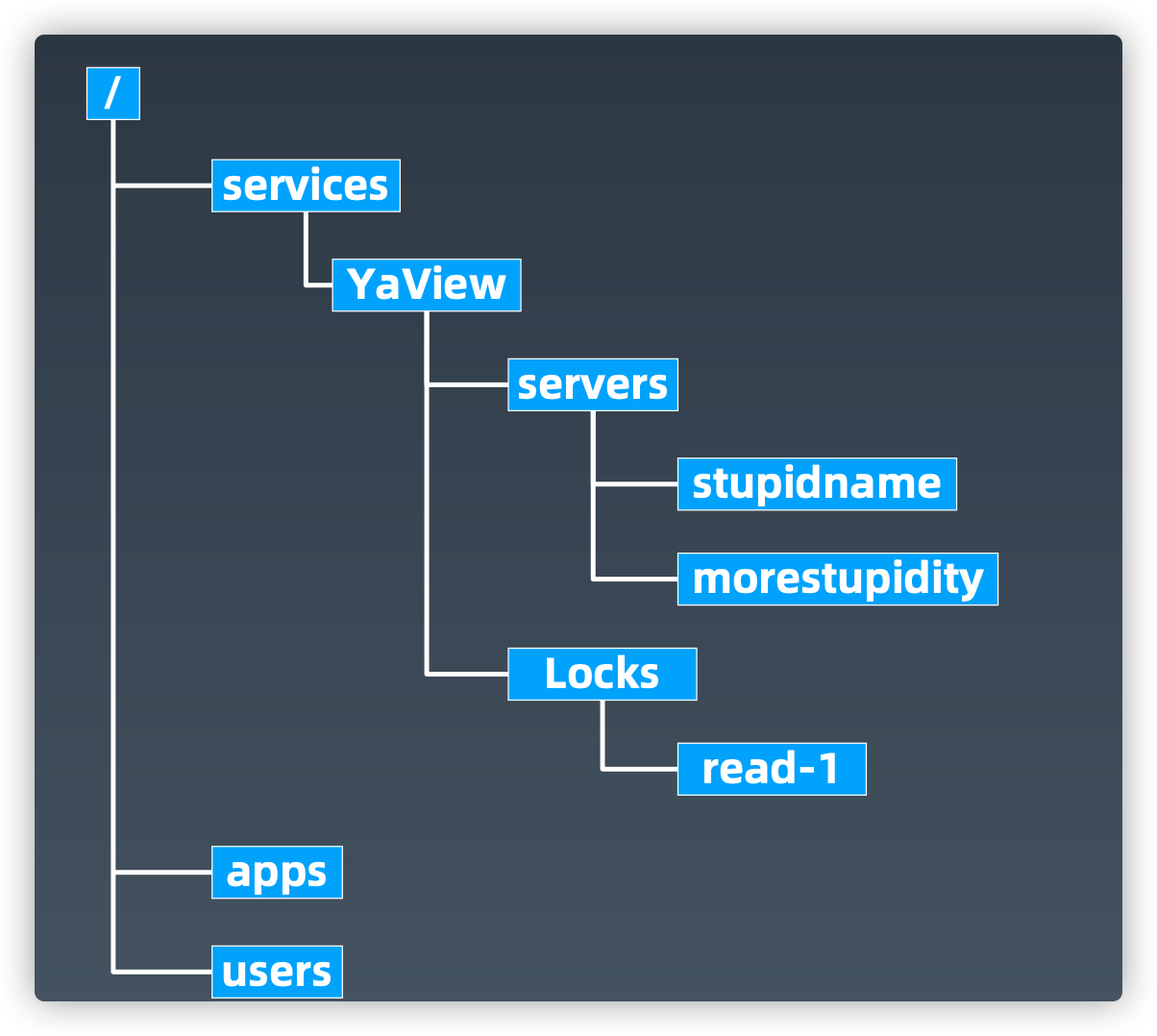
ZooKeeper API
String create(path, data, acl, flags)
void delete(path, expectedVersion)
Stat setData(path, data, expectedVersion) (data, Stat) getData(path, watch)
Stat exists(path, watch)
String[] getChildren(path, watch)
void sync(path)
List multi(ops)
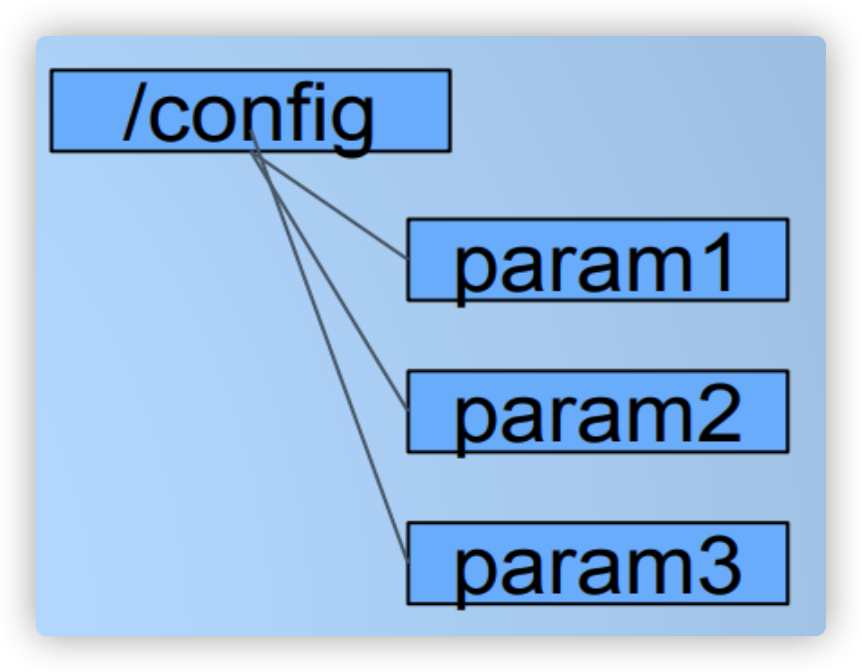
配置管理
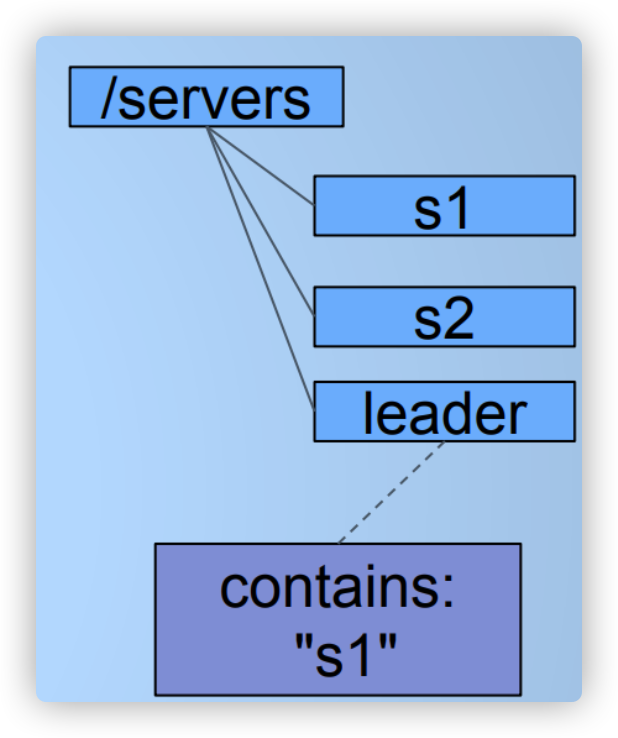
选 master
选 master(Python)

集群管理(负载均衡与失效转移)
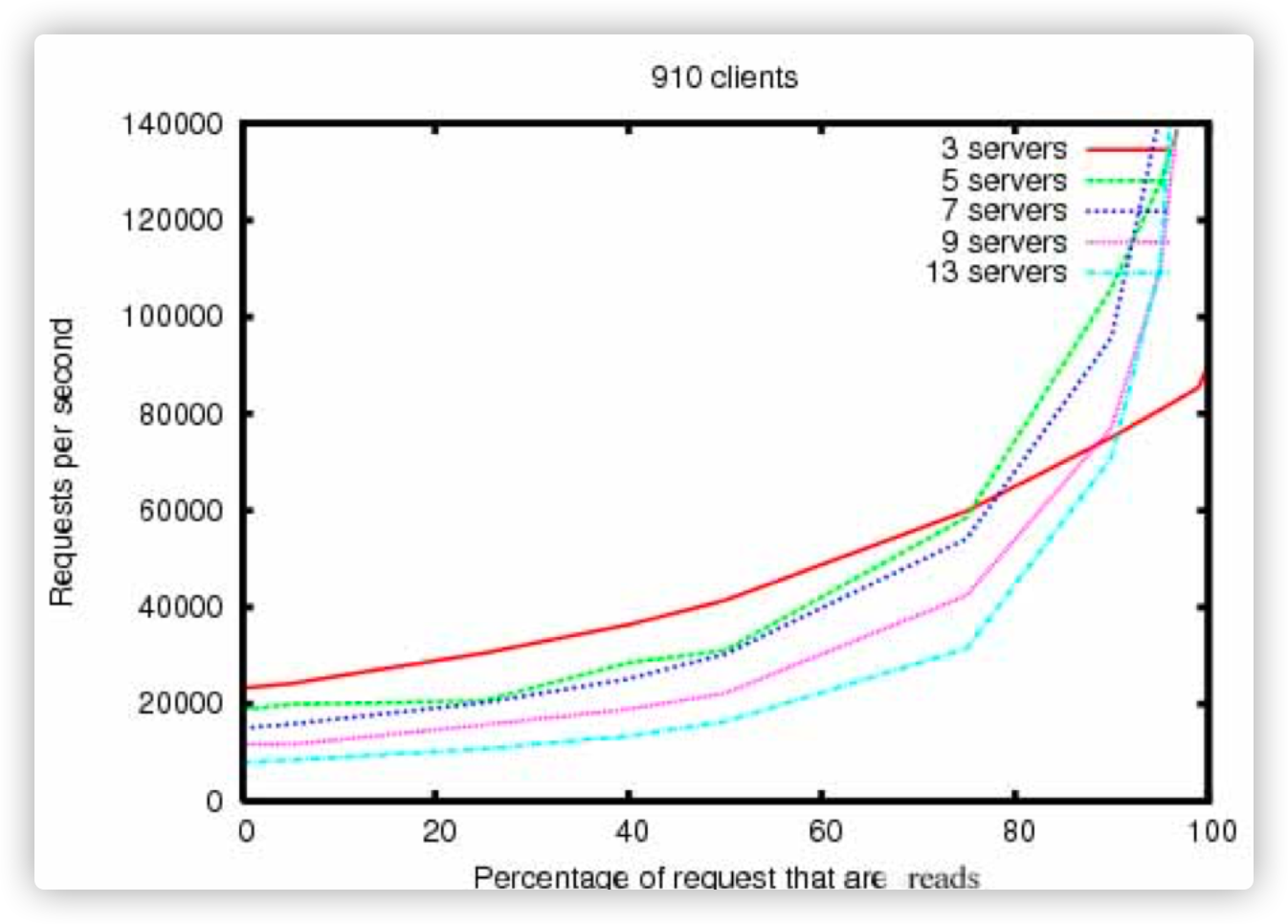
ZooKeeper 性能
6.5 搜索引擎的基本架构
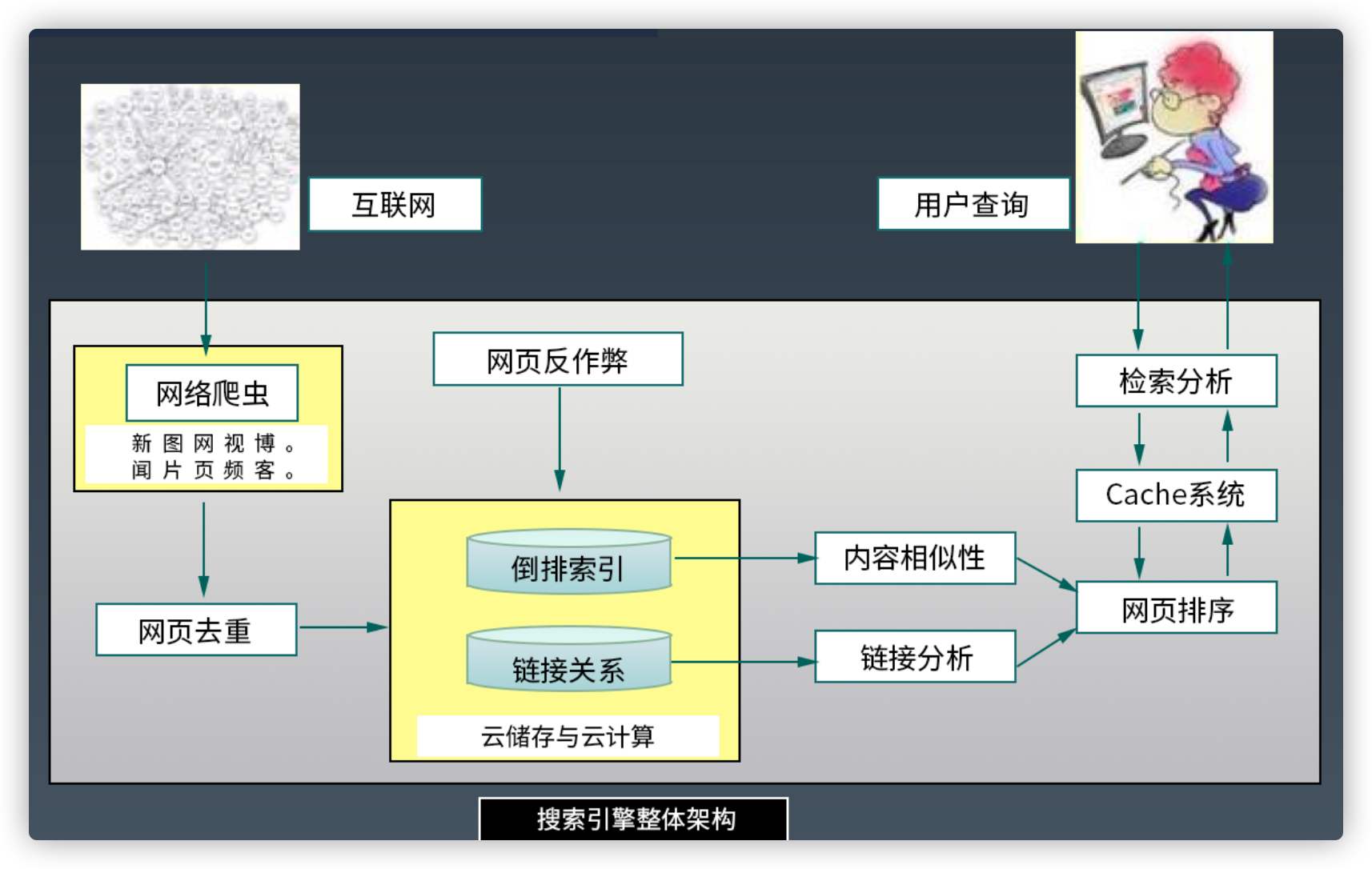
互联网搜索引擎整体架构
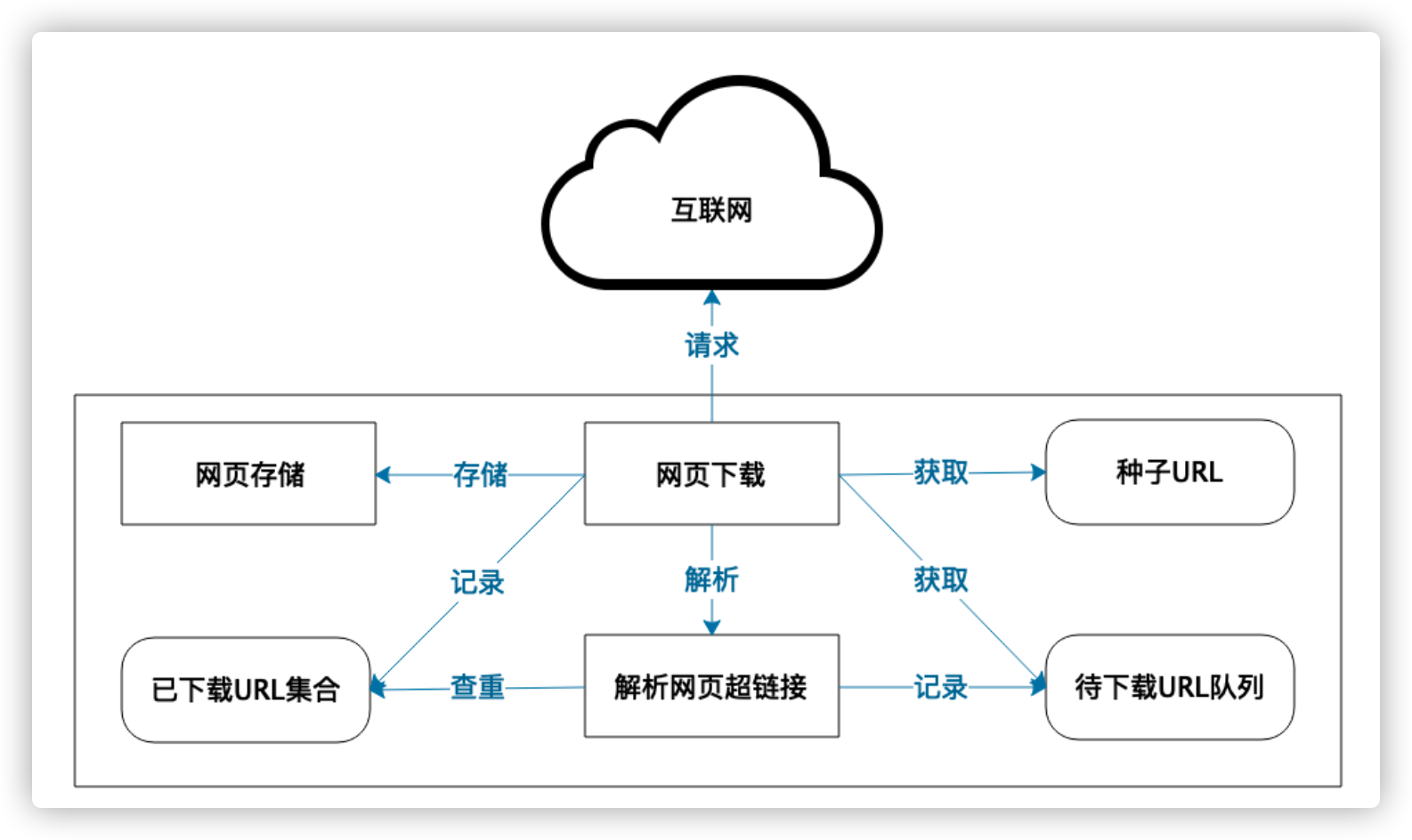
爬虫系统架构
爬虫禁爬协议

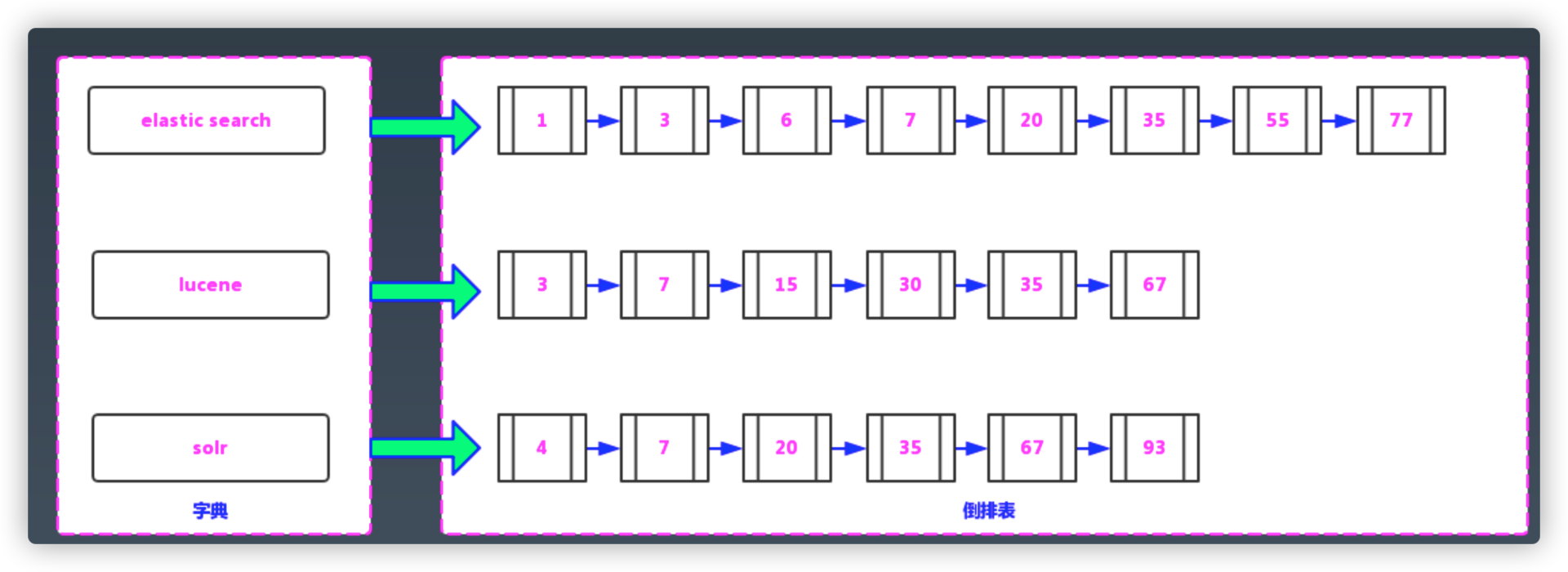
文档矩阵与倒排索引

文档与倒排索引

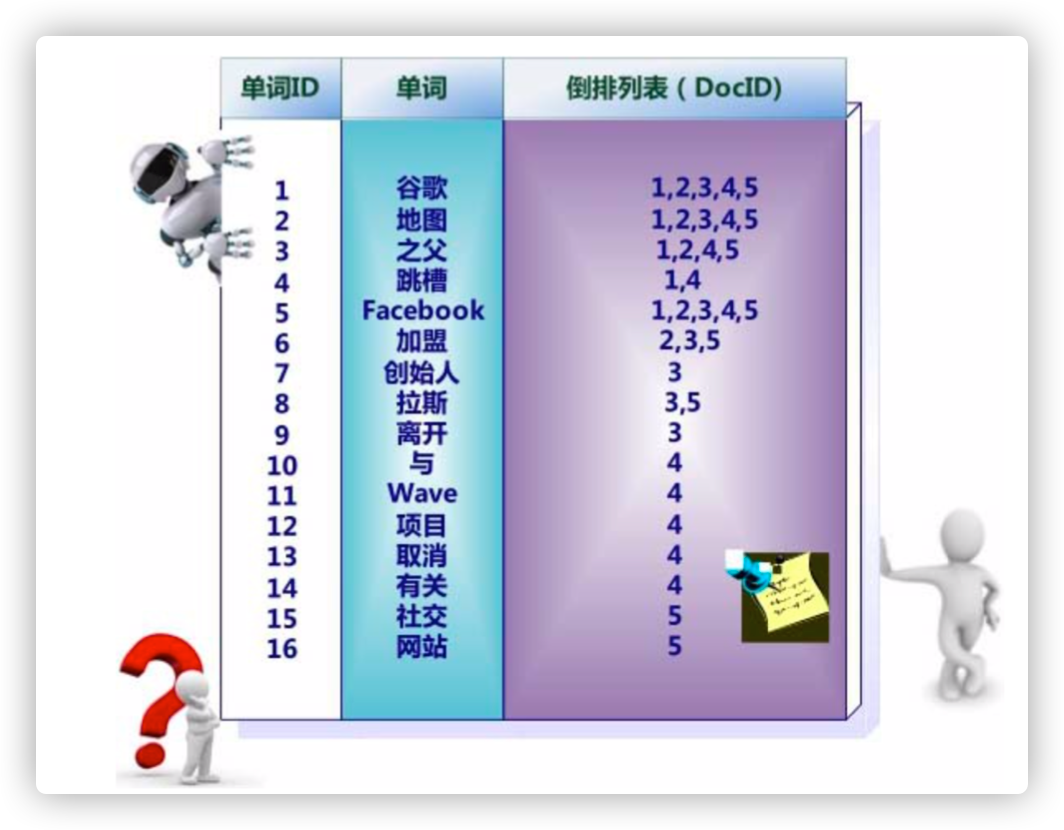
带词频的倒排索引
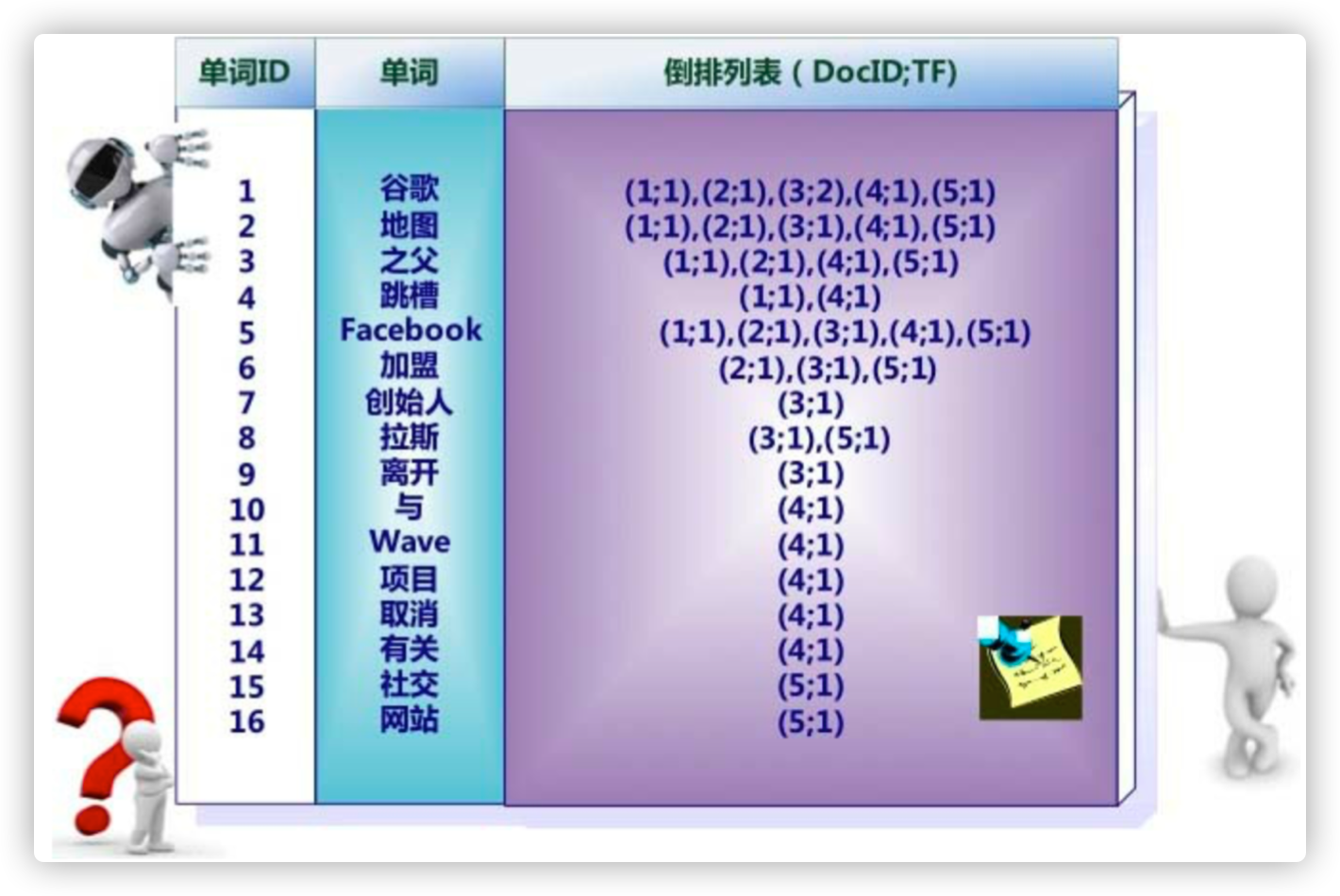
带词频与位置的倒排索引

Lucene 架构
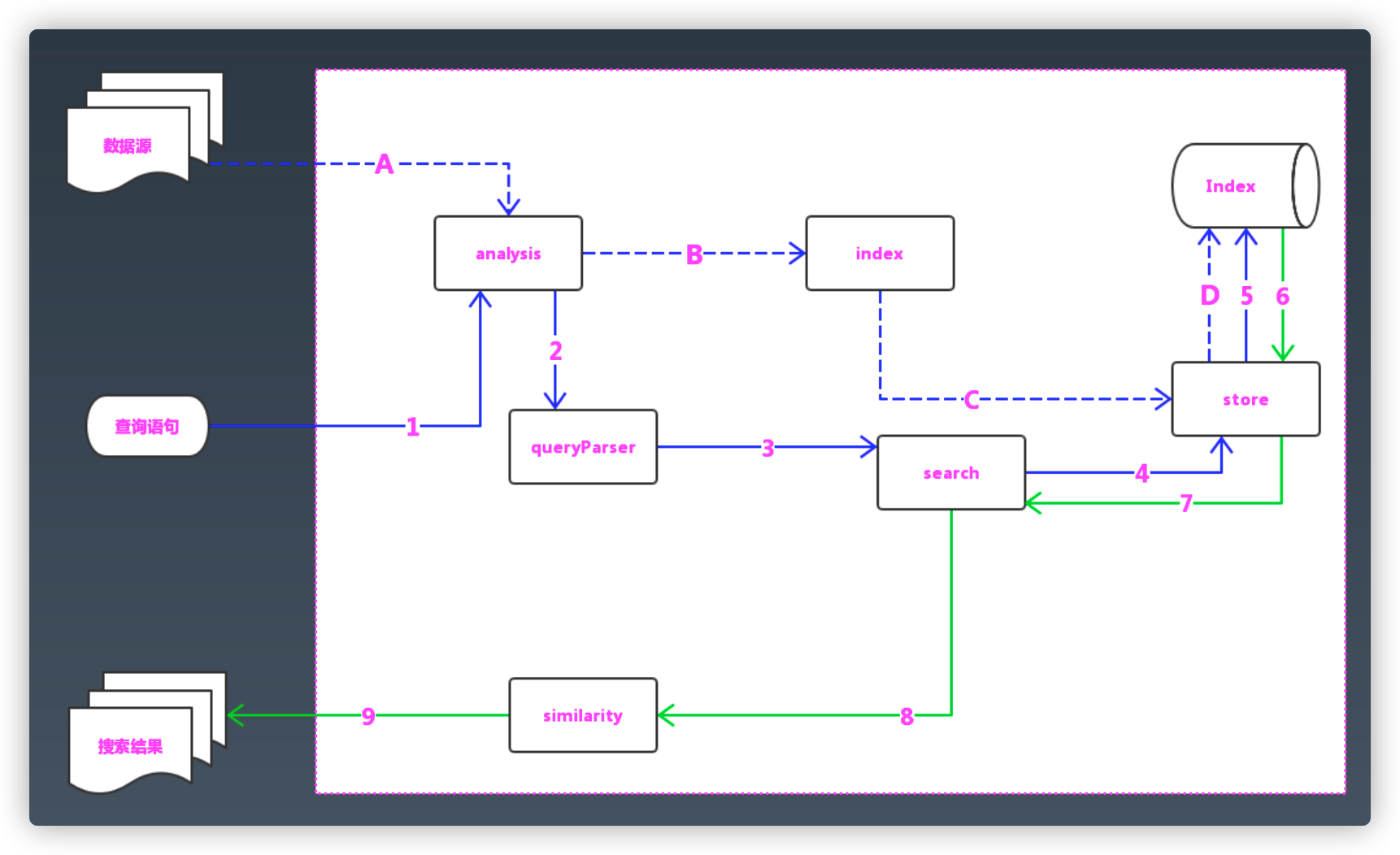
Lucene 倒排索引
Lucene 索引文件准实时更新
索引有更新,就需要重新全量创建一个索引来替换原来的索引。这种方式在数据量很大
时效率很低,并且由于创建一次索引的成本很高,性能也很差。
Lucene 中引入了段的概念,将一个索引文件拆分为多个子文件,每个子文件叫做段,每 个段都是一个独立的可被搜索的数据集,索引的修改针对段进行操作。
新增:当有新的数据需要创建索引时,原来的段不变,选择新建一个段来存储新增的数据。
删除:当需要删除数据时,在索引文件新增一个 .del 的文件,用来专门存储被删除的数据 ID。当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删 除的数据过滤掉。被删除的数据在进行段合并时才会被真正被移除。
更新:更新的操作其实就是删除和新增的组合,先在 .del 文件中记录旧数据,再在新段中添 加一条更新后的数据。
为了控制索引里段的数量,我们必须定期进行段合并操作
ElasticSearch 架构
索引分片,实现分布式
索引备份,实现高可用
API 更简单、更高级
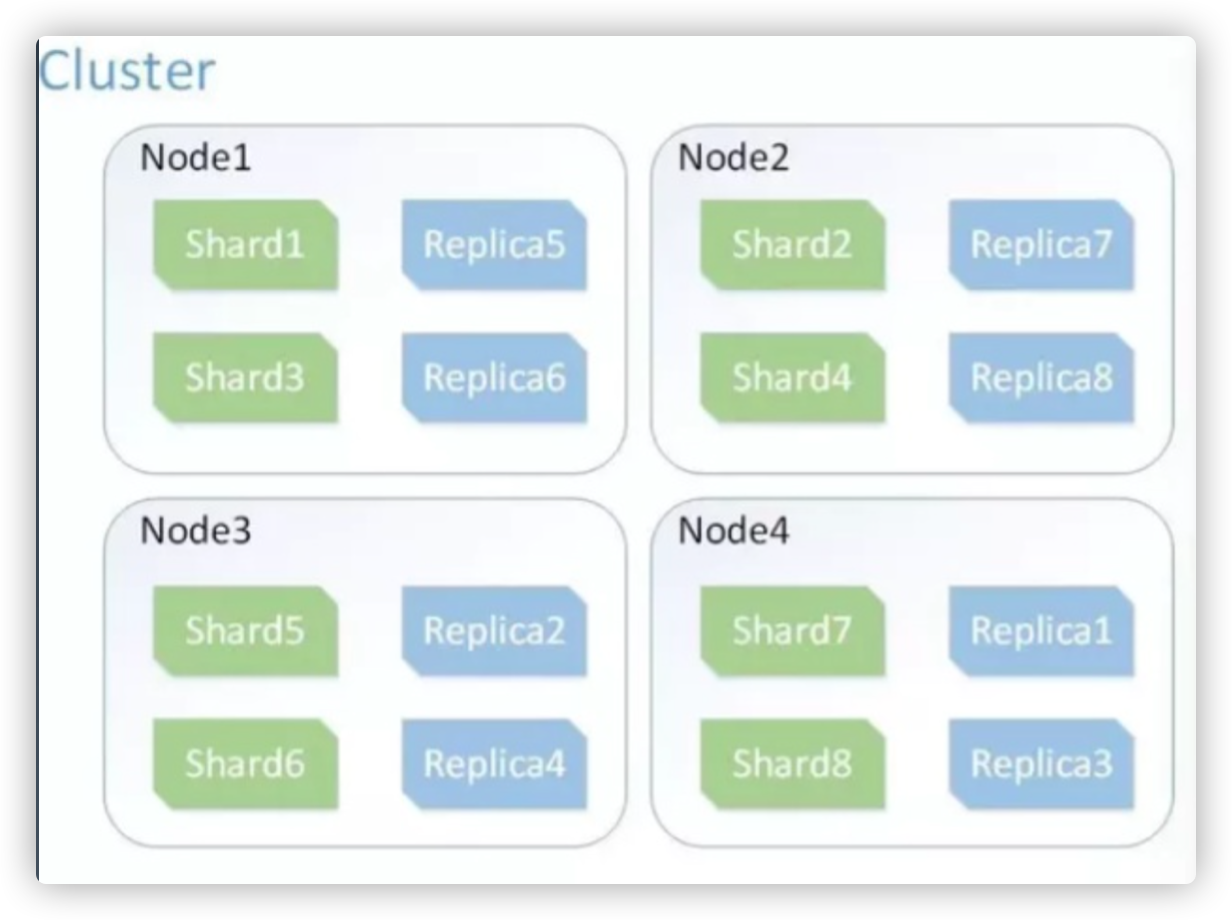
ES 分片预分配与集群扩容

源码
https://github.com/itisaid/sokeeper Web 应用
https://github.com/itisaid/cmdb 爬虫、倒排索引构建
一个智能助理机器人案例
https://github.com/zhihuili/robot
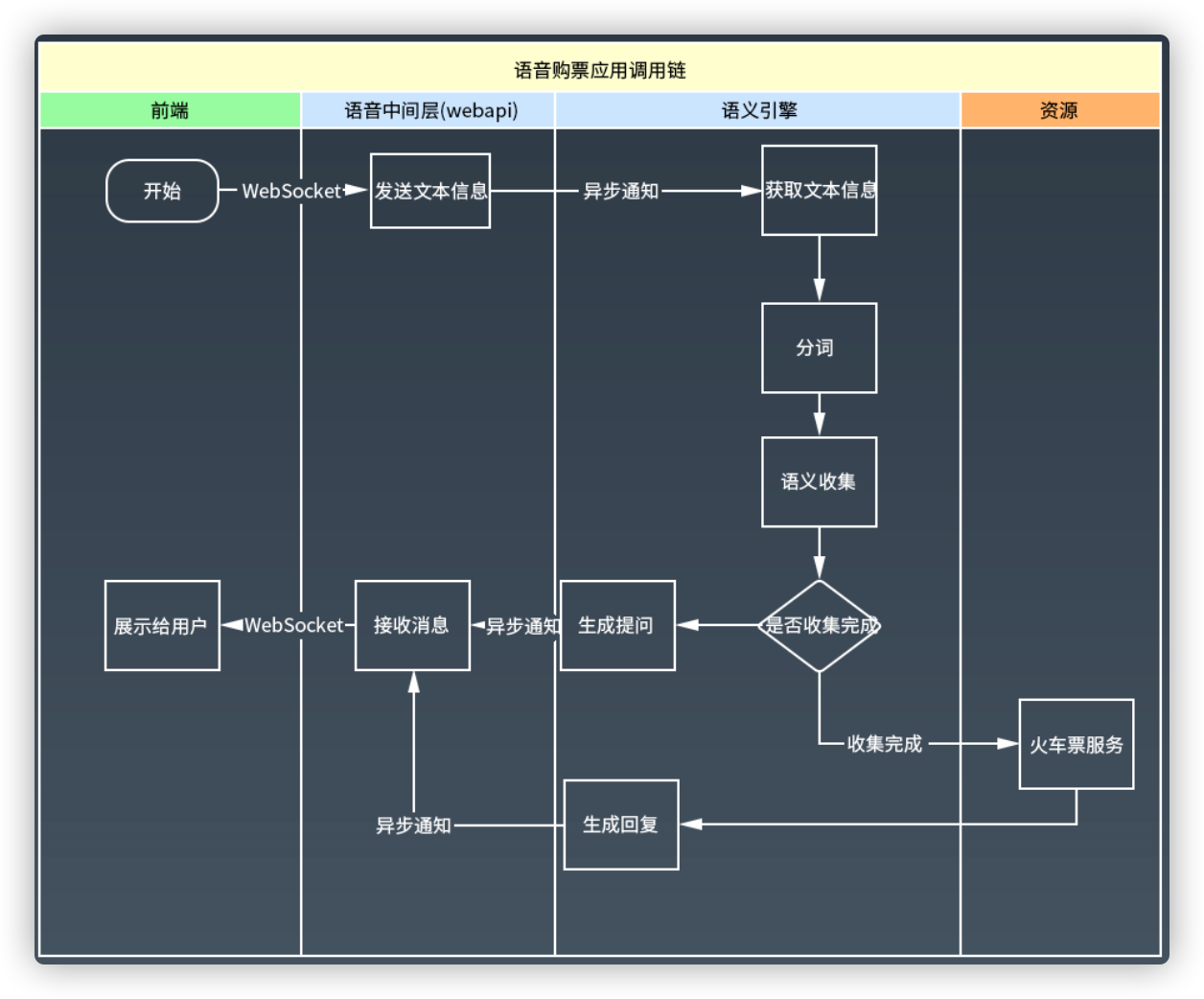
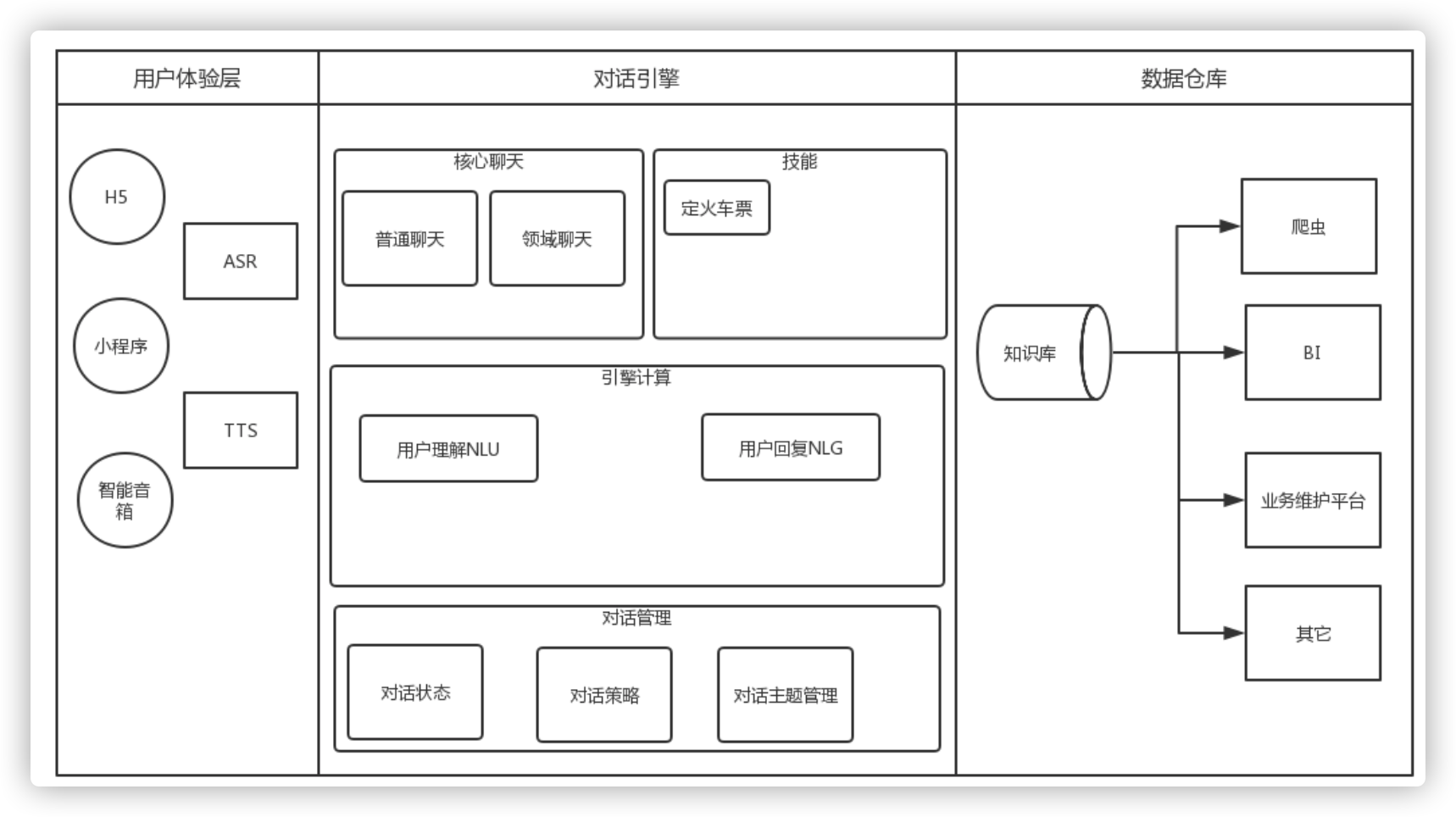
6.6 NoSQL案例:Doris分析案例(一)
Doris – 海量 KV Engine
当前状态

产品需求

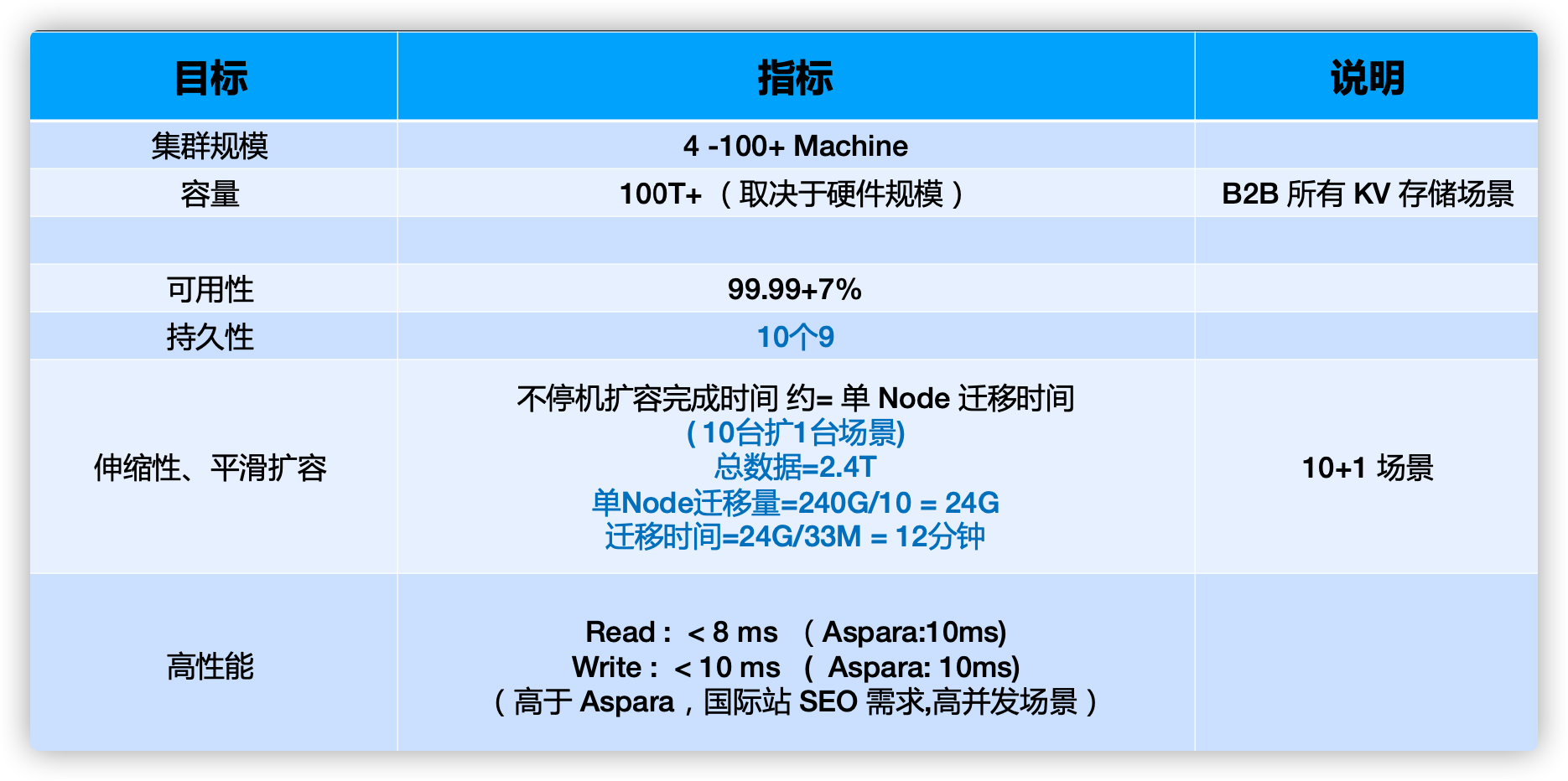
产品目标

技术指标
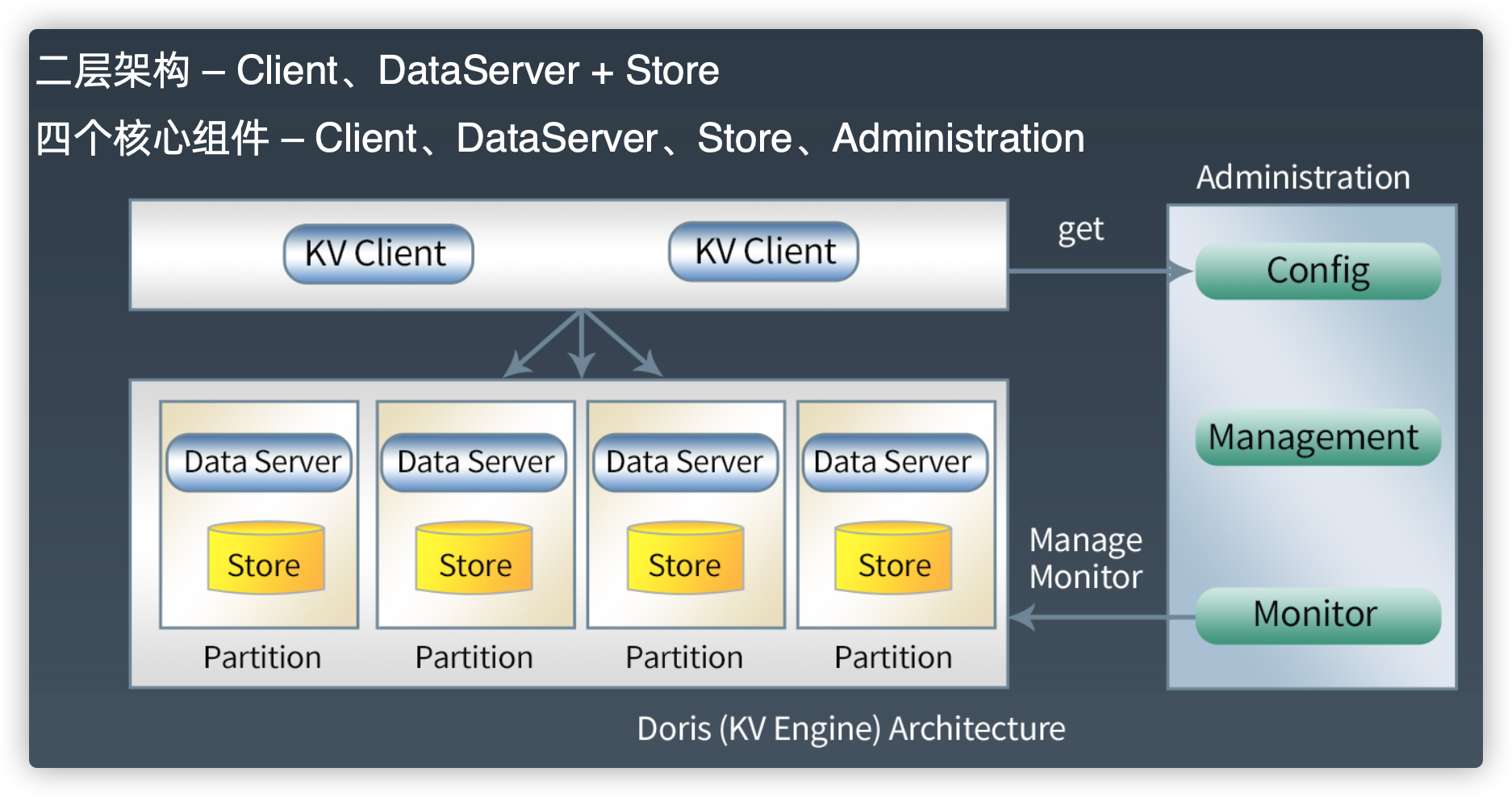
逻辑架构
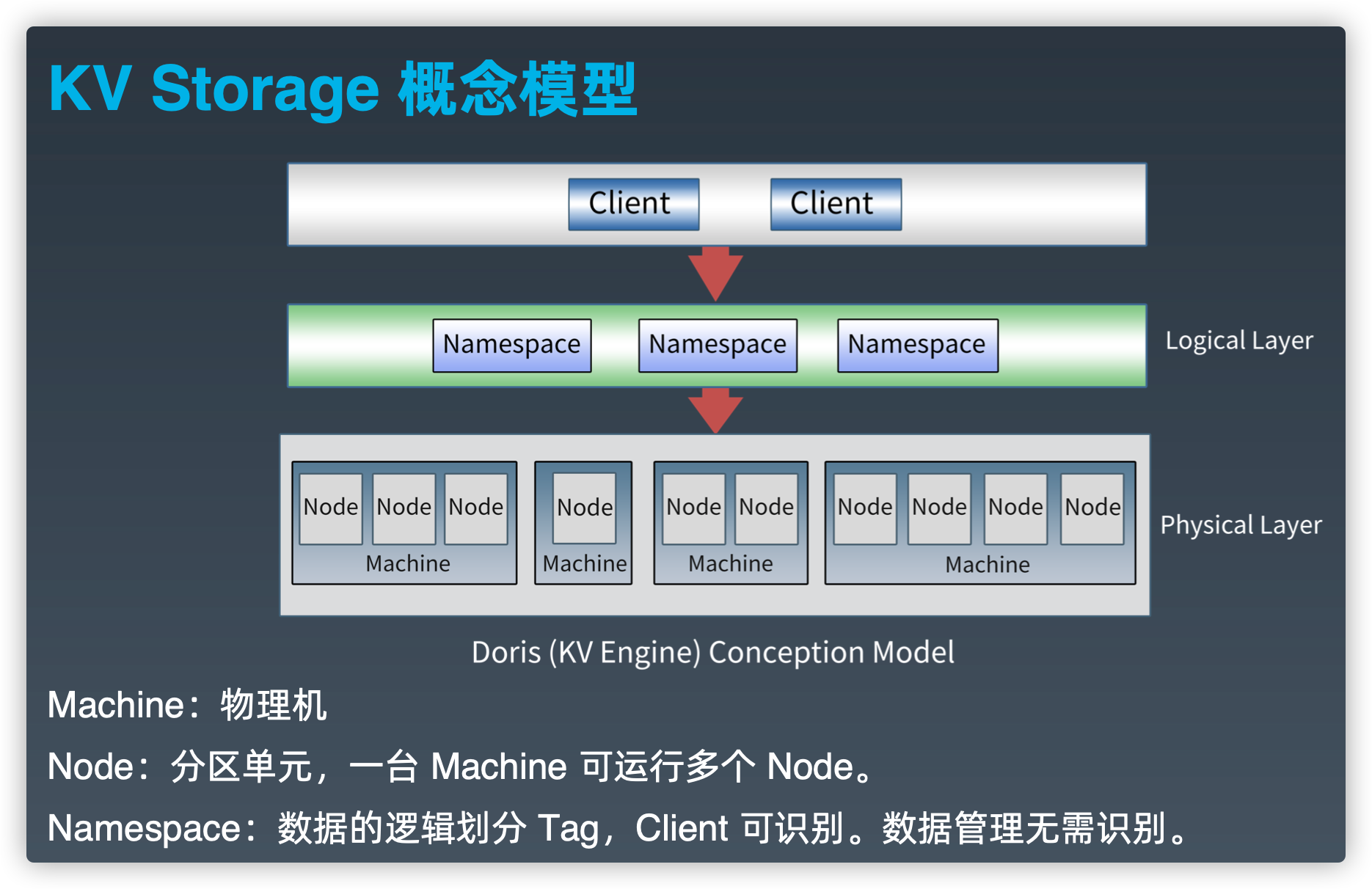
KV Storage概念模型
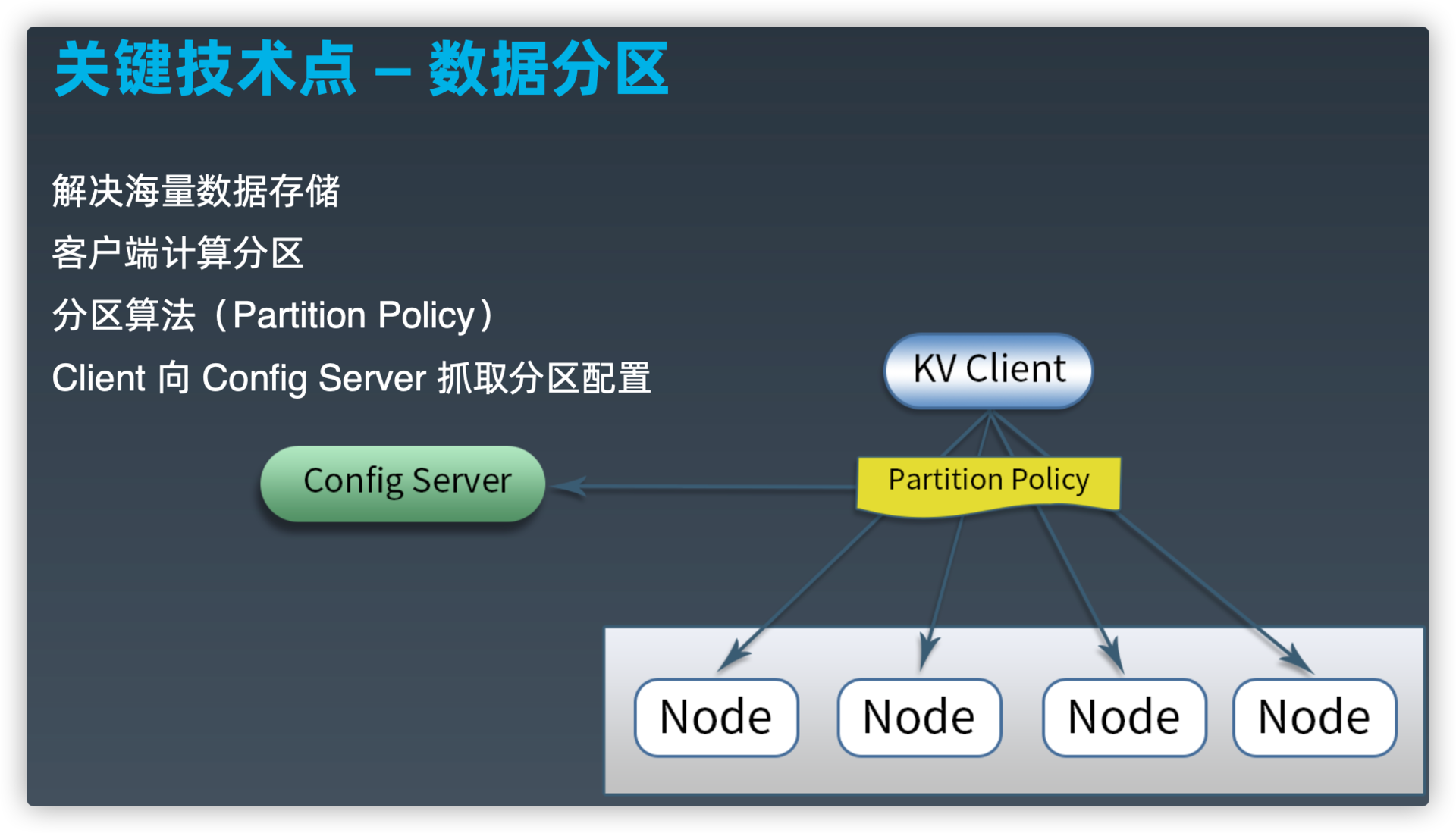
关键技术点--数据分区
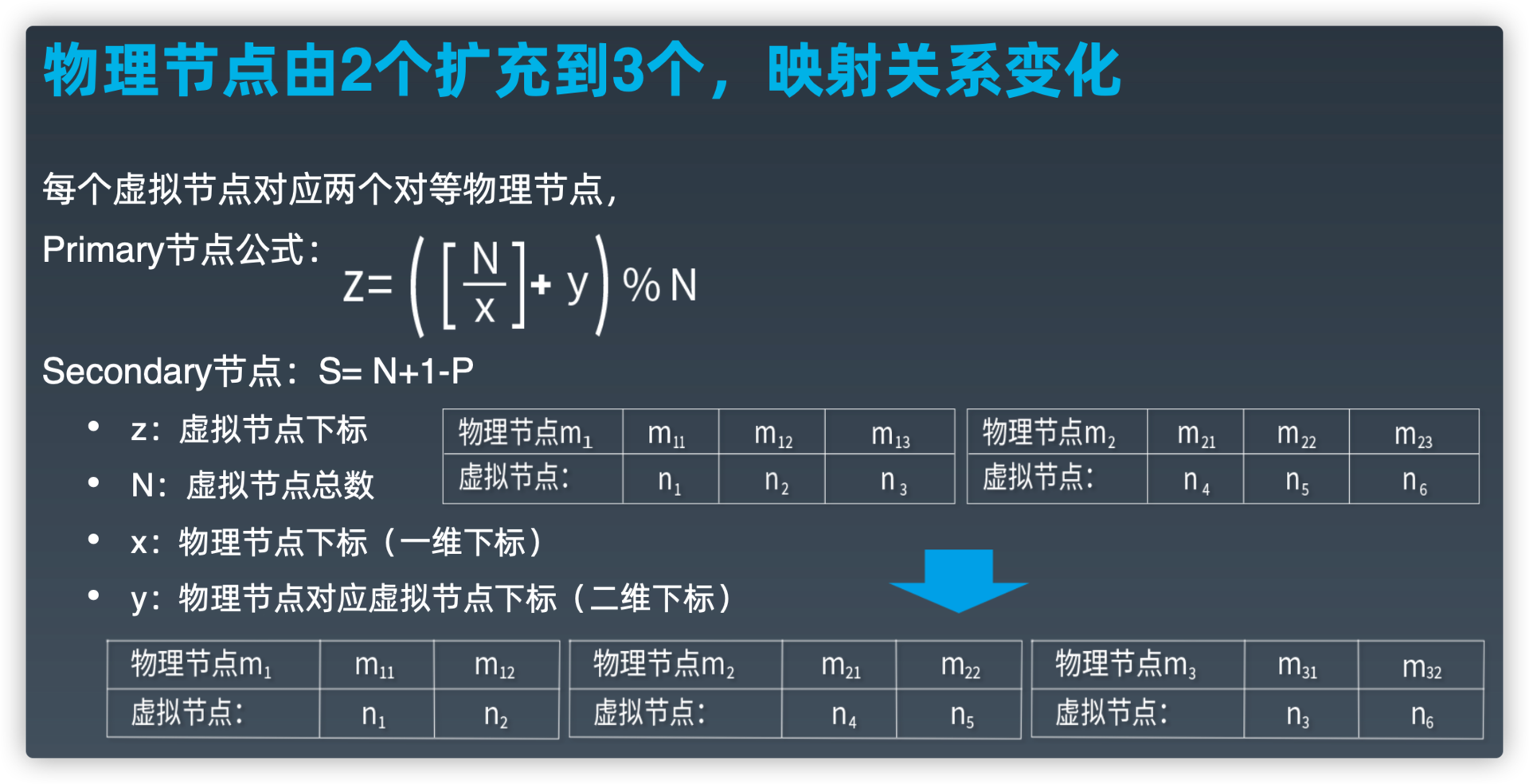
基于虚拟节点的分区算法
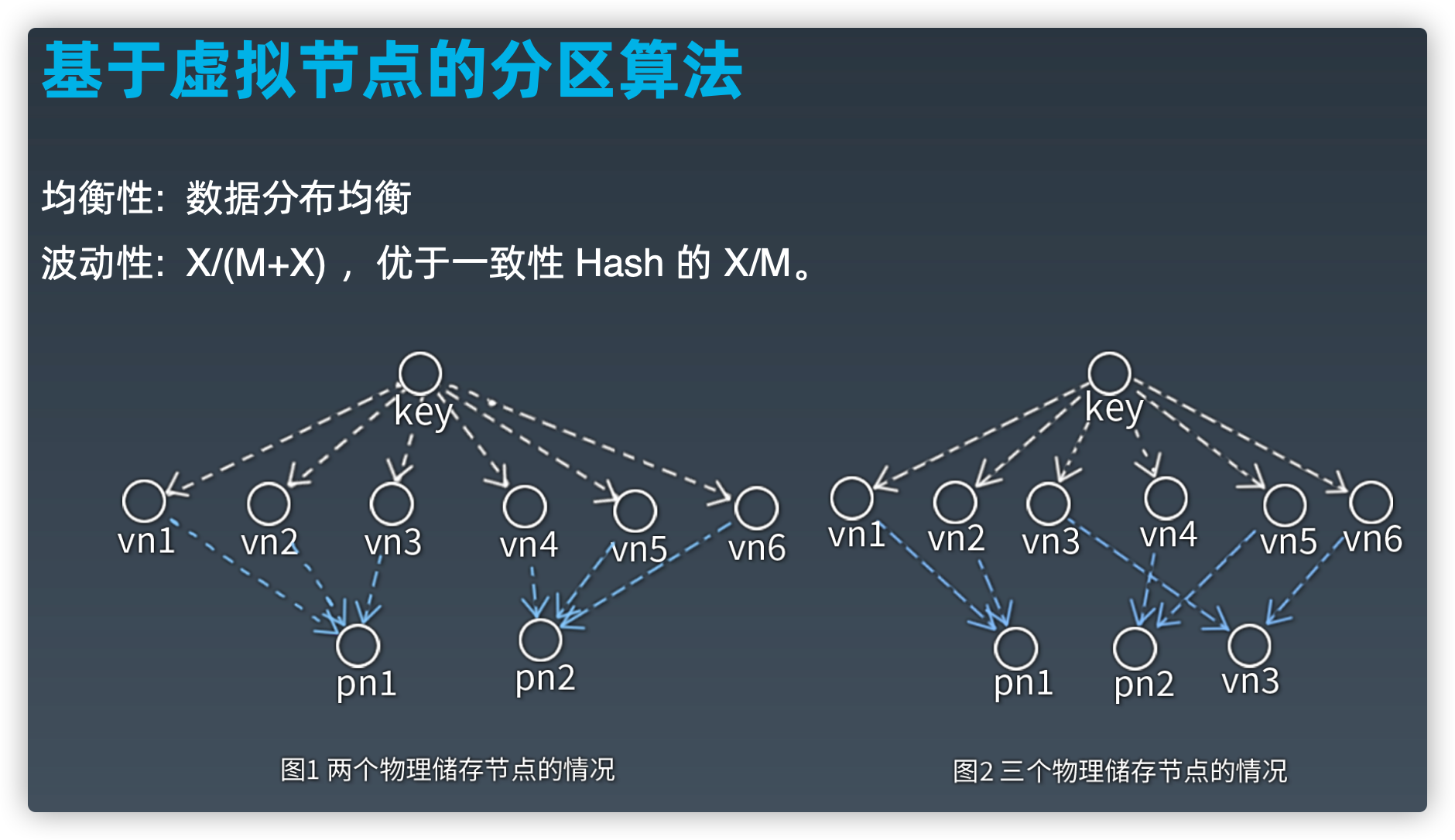
物理节点由2个扩充到3个,映射关系变化
6.7 Doris分析案例(二):高可用与集群扩容如何设计?
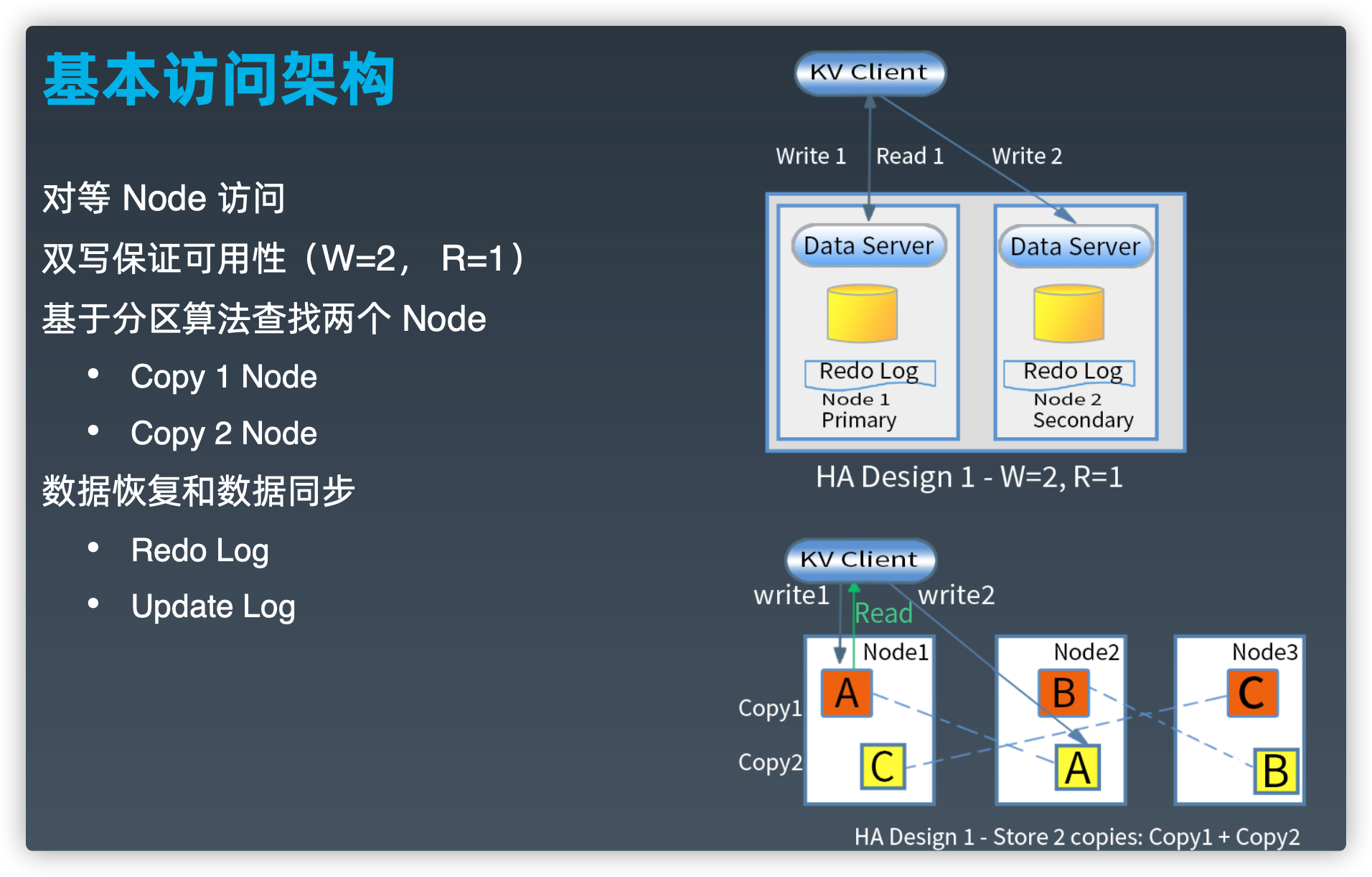
基本访问架构
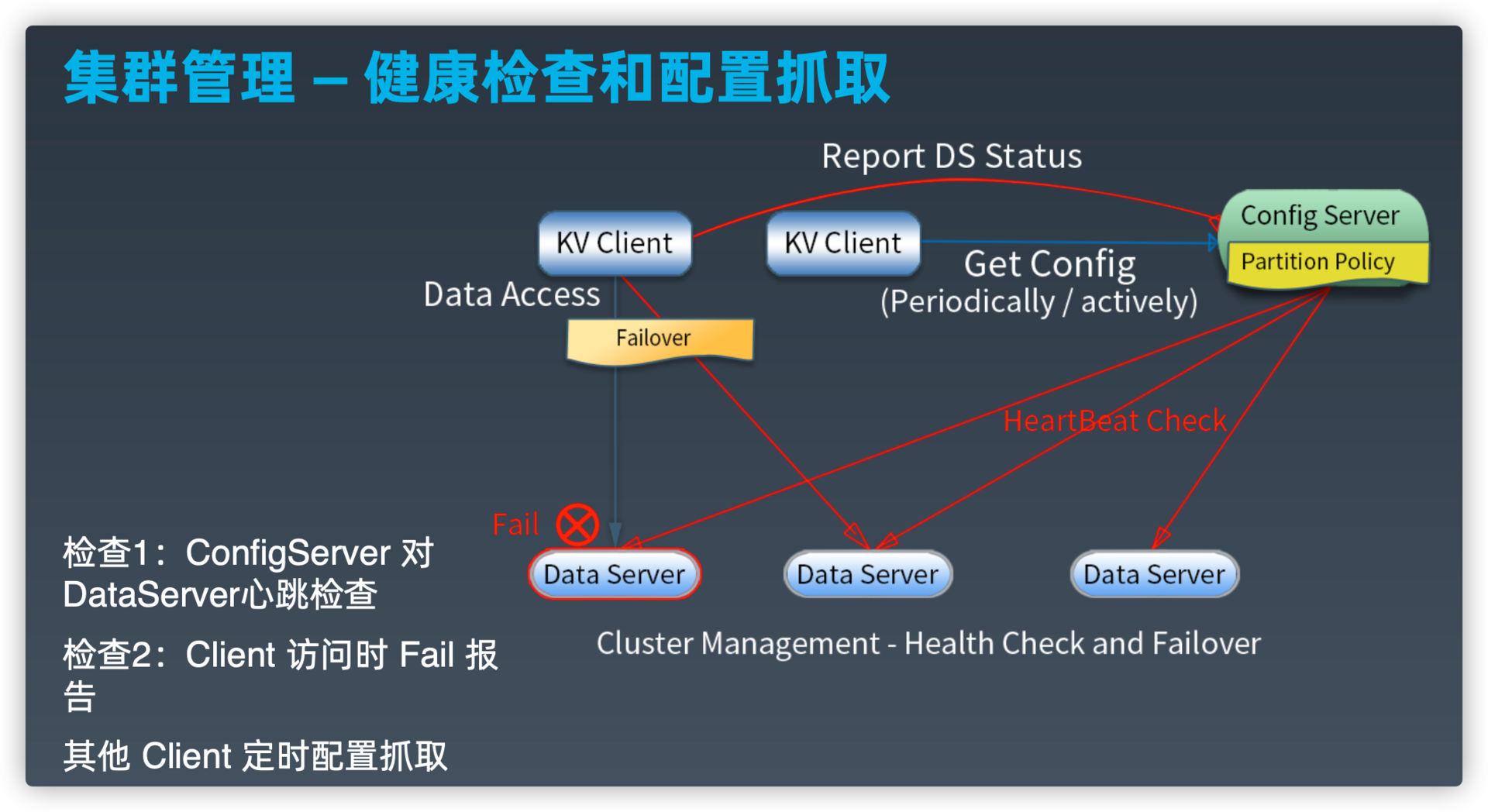
集群管理--健康检查和配置抓取
关键技术点

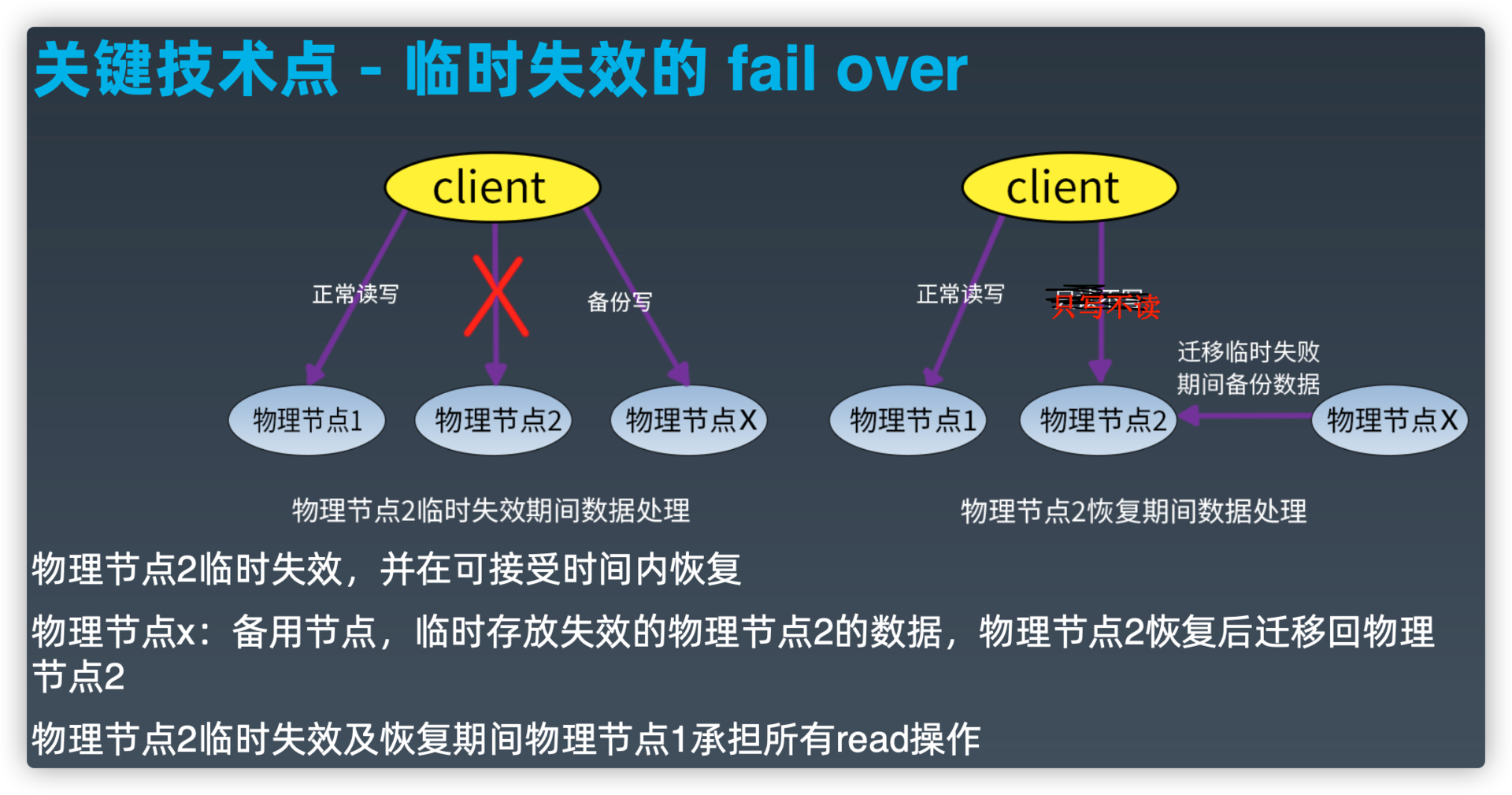
关键技术点--临时失效的fail over
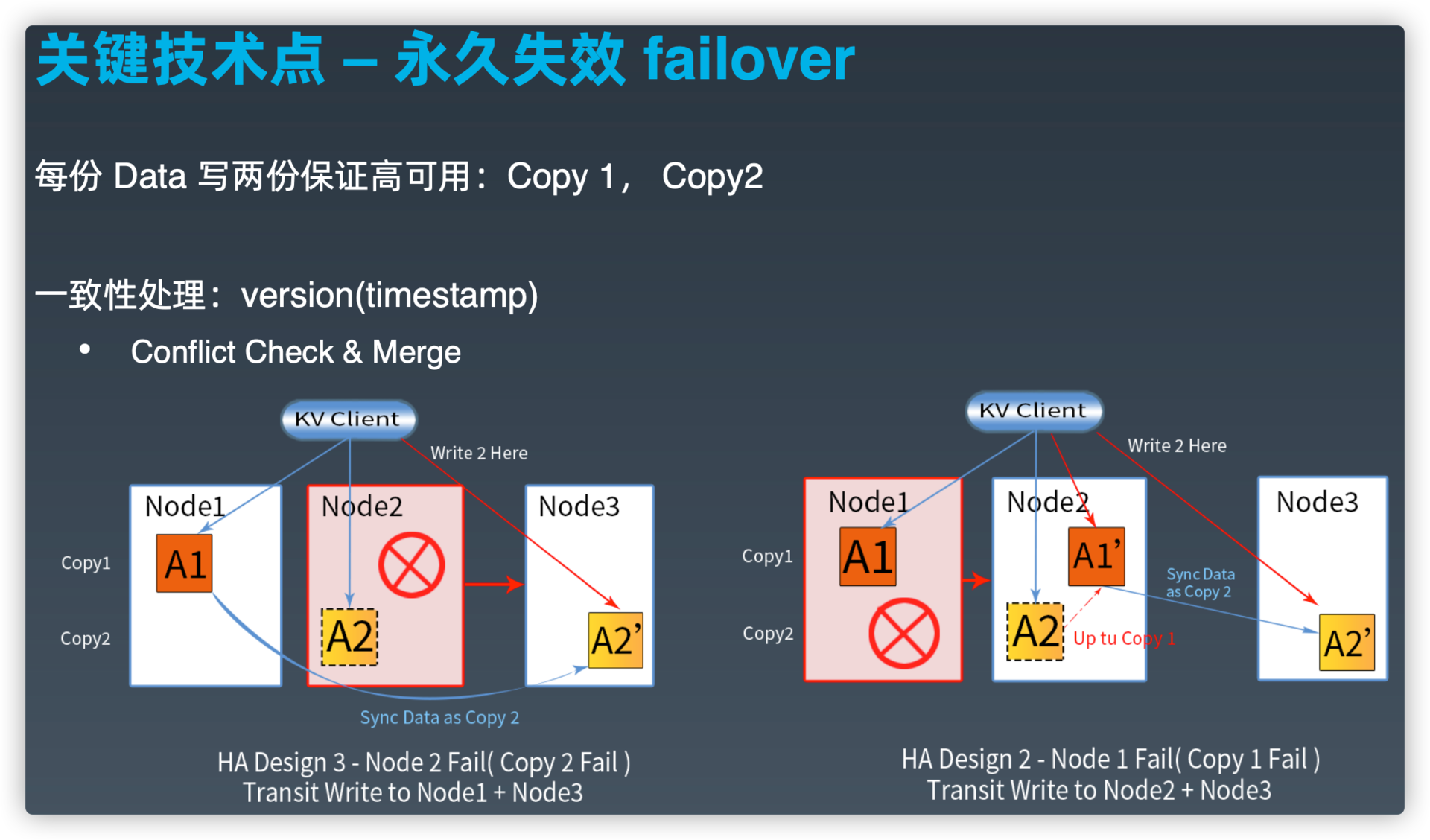
关键技术点--永久失效failover
6.8 Doris分析案例(三):扩容伸缩是如何设计的?
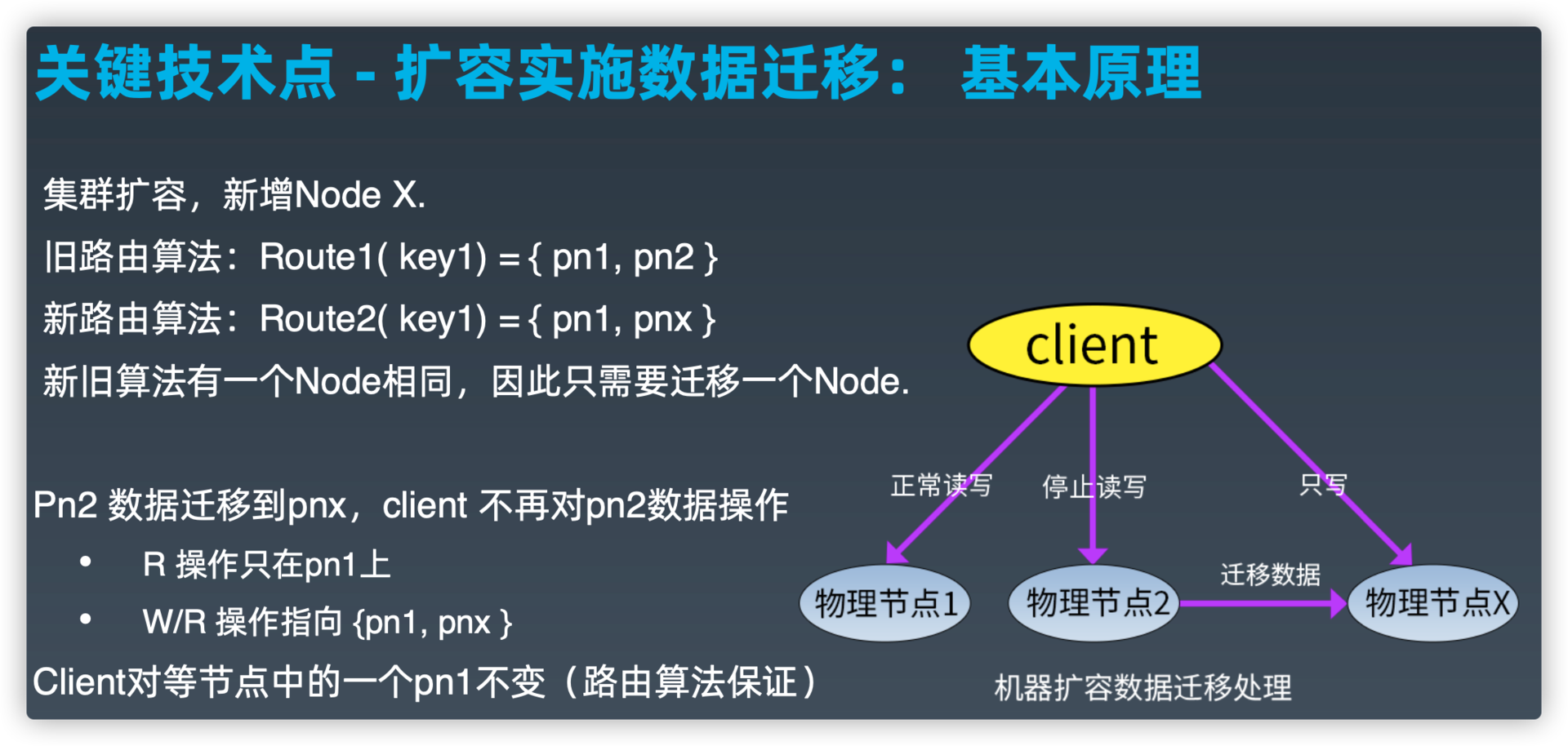
关键技术点--扩容实施数据迁移:基本原理
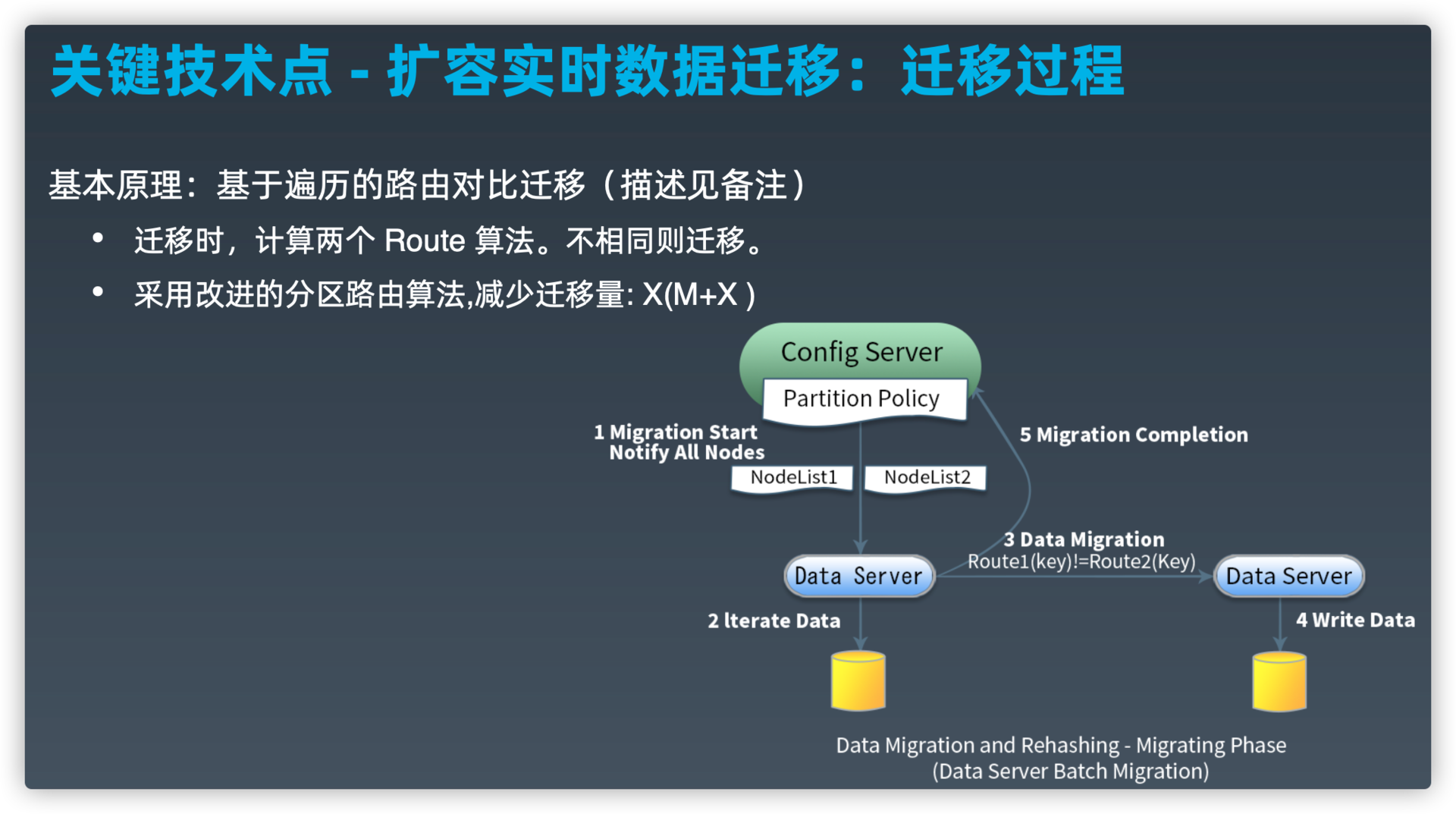
关键技术点--扩容实时数据迁移:迁移过程
数据可识别功能--逻辑数据结构

产品规划
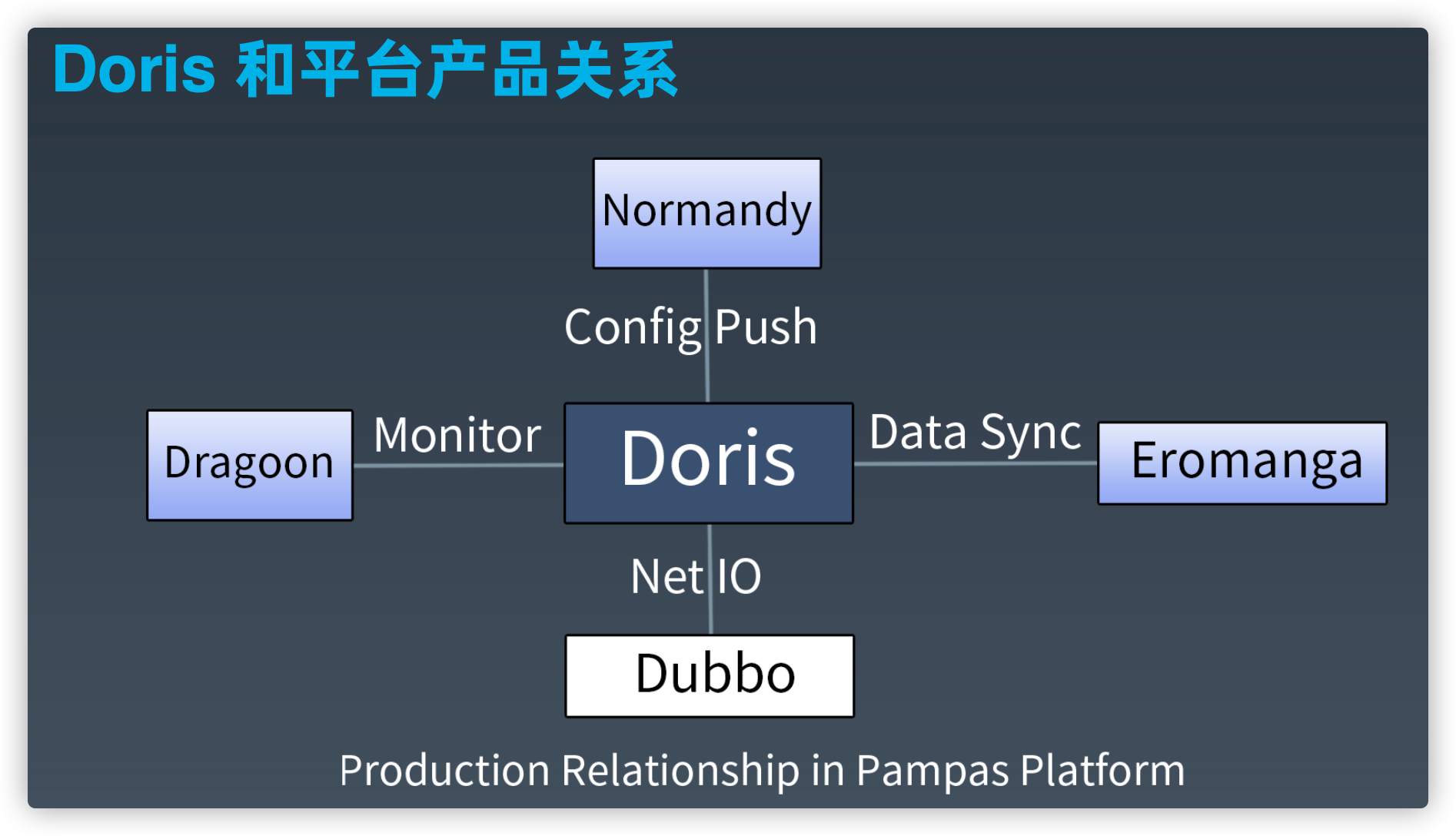
Doris和平台产品关系
产品规划(功能和版本)
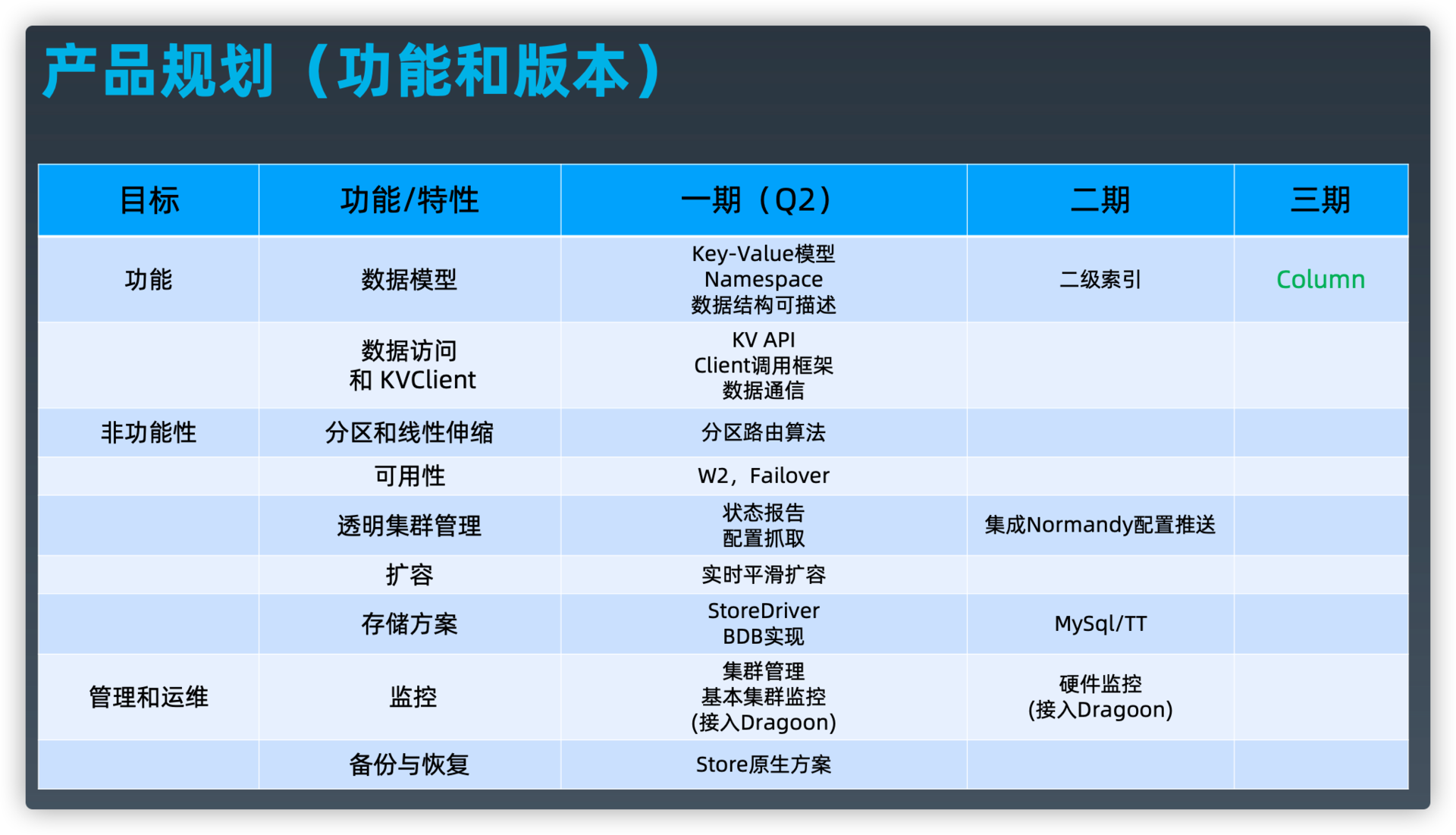
Doris Q2研发计划--功能需求

Doris Q2研发计划

Doris 0.1.0 项目计划
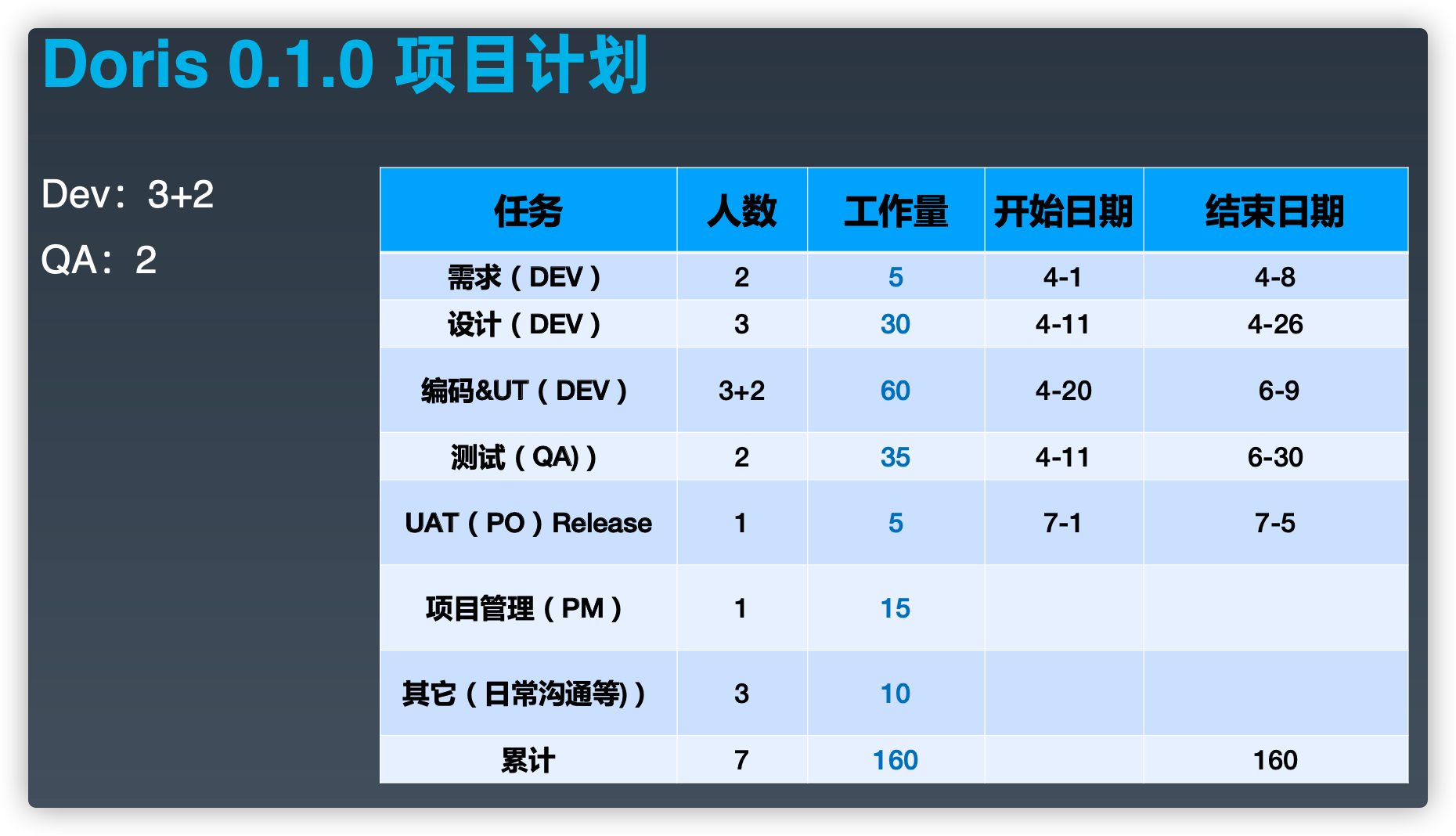
实施加护 Q3-Q4

Doris项目专利
基于虚拟节点的一致性 Hash 算法

还未添加个人签名 2020.03.17 加入
还未添加个人简介









评论