

Hash 一致性算法的 Java 实现
发布于: 2020 年 07 月 06 日
一致性hash算法,可以用在分布式缓存、数据库的分库分表、负载均衡算法等场景中
节点
import java.util.HashMap;import java.util.Map;/** * Created by weiyuan on 2020/07/06 */public class Node { private String ip; /** * 节点存储数据 */ private Map<String,Object> data = new HashMap<String,Object>(); public Node(String ip) { this.ip = ip; } public <T> void put(String key, T value) { data.put(key, value); } public void remove(String key){ data.remove(key); } public <T> T get(String key) { return (T) data.get(key); } public String getIp() { return ip; } public void setIp(String ip) { this.ip = ip; } public Map<String, Object> getData() { return data; } public void setData(Map<String, Object> data) { this.data = data; }}集群
import java.util.ArrayList;import java.util.List;/** * Created by weiyuan on 2020/07/06 */public abstract class Cluster { protected List<Node> nodes; public Cluster() { this.nodes = new ArrayList<>(); } public abstract void addNode(Node node); public abstract void removeNode(Node node); public abstract Node get(String key); /** * 这里选用FNV1_32_HASH算法,因String重写的hash算法会产生负数, * 而且算出的hashCode值分布比较集中,数据分布不均匀 * @param str * @return */ public static int getHash(String str) { final int p = 16777619; int hash = (int) 2166136261L; for (int i = 0; i < str.length(); i++) hash = (hash ^ str.charAt(i)) * p; hash += hash << 13; hash ^= hash >> 7; hash += hash << 3; hash ^= hash >> 17; hash += hash << 5; // 如果算出来的值为负数则取其绝对值 if (hash < 0) hash = Math.abs(hash); return hash; }}取模算法
/** * Created by weiyuan on 2020/07/06 */public class NormalHashCluster extends Cluster { public NormalHashCluster() { super(); } @Override public void addNode(Node node) { this.nodes.add(node); } @Override public void removeNode(Node node) { this.nodes.removeIf(o -> o.getIp().equals(node.getIp())); } @Override /** * 取模算法,求请求资源分发到哪个集群节点 */ public Node get(String key) { long hash = getHash(key); long index = hash % nodes.size(); return nodes.get((int)index); }}Hash一致算法
import java.util.SortedMap;import java.util.TreeMap;import java.util.stream.IntStream;/** * Created by weiyuan on 2020/07/06 */public class ConsistencyHashCluster extends Cluster { private SortedMap<Long, Node> virNodes = new TreeMap<Long, Node>(); private int virNodeCount; private static final String SPLIT = "#"; public ConsistencyHashCluster(int virNodeCount) { super(); this.virNodeCount = virNodeCount; } @Override public void addNode(Node node) { this.nodes.add(node); IntStream.range(0, virNodeCount) .forEach(index -> { long hash = getHash(node.getIp() + SPLIT + index); virNodes.put(hash, node); }); } @Override public void removeNode(Node node) { nodes.removeIf(o -> node.getIp().equals(o.getIp())); IntStream.range(0, virNodeCount) .forEach(index -> { long hash = getHash(node.getIp() + SPLIT + index); virNodes.remove(hash); }); } @Override /** * 虚拟节点算法,求请求资源分发到哪个集群节点 */ public Node get(String key) { long hash = getHash(key); SortedMap<Long, Node> subMap = hash >= virNodes.lastKey() ? virNodes.tailMap(0L) : virNodes.tailMap(hash); if (subMap.isEmpty()) { return null; } return subMap.get(subMap.firstKey()); }}测试验证算法机器压力分布情况
import org.junit.Test;import java.util.stream.IntStream;/** * Created by weiyuan on 2020/07/06 */public class HashTest { @Test public void hashTest(){// Cluster cluster = new NormalHashCluster(); Cluster cluster=new ConsistencyHashCluster(150); cluster.addNode(new Node("192.168.0.1")); cluster.addNode(new Node("192.168.0.2")); cluster.addNode(new Node("192.168.0.3")); cluster.addNode(new Node("192.168.0.4")); IntStream.range(0, (int)(Math.pow(2,23) - 1)) .forEach(index -> { Node node = cluster.get("Test Data" + index); node.put("Test Data" + index, "Test Data"); }); System.out.println("数据分布情况:"); cluster.nodes.forEach(node -> { System.out.println("IP:" + node.getIp() + ",数据量:" + node.getData().size()); }); //缓存命中率 long hitCount = IntStream.range(0, (int)(Math.pow(2,23) - 1)) .filter(index -> cluster.get("Test Data" + index).get("Test Data" + index) != null) .count(); System.out.println("缓存命中率:" + hitCount * 1f / (int)(Math.pow(2,23) - 1)); cluster.addNode(new Node("192.168.0.5")); long hitCount1 = IntStream.range(0, (int)(Math.pow(2,23) - 1)) .filter(index -> cluster.get("Test Data" + index).get("Test Data" + index) != null) .count(); System.out.println("增加节点后缓存命中率:" + hitCount1 * 1f / (int)(Math.pow(2,23) - 1)); }}取模
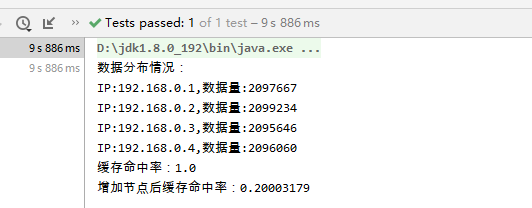
一致性(虚拟节点取150)
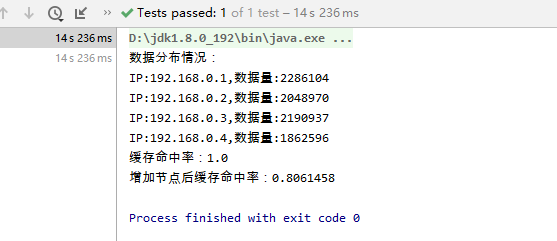
总结:通过采取虚拟节点的方法,一个真实结点不再固定在Hash换上的某个点,而是大量地分布在整个Hash环上,可以极大的提高缓存的命中率,减少在增加节点、删除节点时,数据迁移的成本。
划线
评论
复制
发布于: 2020 年 07 月 06 日 阅读数: 86

wei
关注
还未添加个人签名 2018.05.31 加入
还未添加个人简介










评论