

Python 处理 Word 文件的实用姿势

>我从不以强凌弱,欺负他之前,真不晓得他比我弱。
Office套件一直是微软的印钞机,但在2007版本前,它一直是微软的专用格式。
什么是专用格式?就是你只能用微软提供的Office软件打开自己的文档数据。
也就必须向微软付费,而且还不通用。
2002年Sun(后被Oracle收购)等公司组建了OASIS技术委员会,开始定义一种基于XML的开放标准文档格式:ODF标准。
这份标准引发了全球政府的关注,推动了文档标准化的进程。
微软随后也推出了自己的标准文档格式OpenXML,并从Office2007版开始正式支持。
此后,巨头们展开了激烈的文档标准之争。
现在,除了微软Office,我们还可以选择使用WPS,OpenOffice,或者MacOS上的Pages等工具处理文档。
OpenXML的文档基于XML和Zip压缩技术,有什么特殊呢?
首先可以观察到文件扩展名不一样,最后都带一个x,如docx、xlsx、pptx。
对于这类文件,你可以用压缩软件比如7-zip打开它,就可以看到其内部结构了。
一份docx文档解压后的格式:
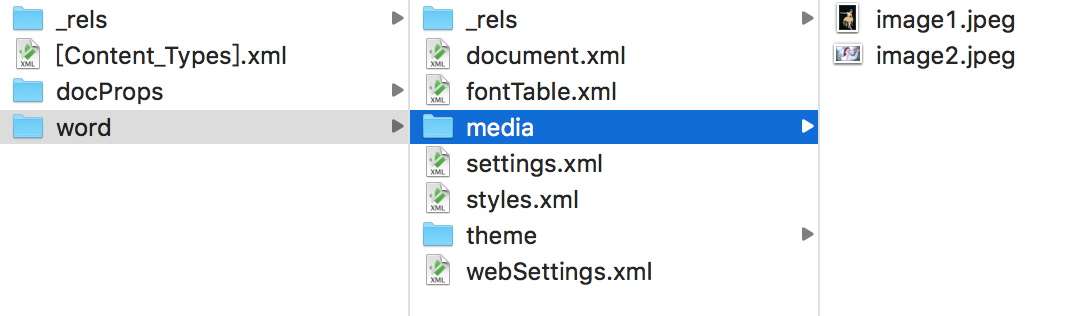
可以看到,文件内的图像等素材,其实都在压缩文件内的某个文件夹下。
pptx和xlsx文件类似,所以之前有朋友问:
“如何批量提取PPT内的图像?”
这就是答案。
剩下的还有一堆XML文档,之前说过都是文本文件,可以直接用文本编辑器打开。
当然,为了更快处理其中的信息,我们可以利用现成的模块。
Python中用于处理微软Office文档的模块对应有3个:
python-docx,处理标准
docx文档python-pptx,处理标准
pptx文档openpyxl,处理
xlsx文档
模块安装:
pip install python-docxpip install python-pptxpip install openpyxl
正常情况下,我们不会用编程来写文档,因为软件已经足够成熟,使用起来方便很多。
但是在两个情况下,用编程处理文档更有优势:
批量处理数据,如汇总文档中的图表等。
自动化生成,如按模板定期生成报告等。
这次,我们重点介绍python-docx处理微软的Word文档。
基本使用:自动生成文档
一个Word文档,主要由下面这些内容元素构成,每个元素都有对应的方法处理:
标题:
add_heading()段落:
add_paragraph()文本:
add_run(),其返回对象支持设置文本属性图片:
add_picture()表格:
add_table()、add_row()、add_col()
其中,段落和文本最通用,可以给段落赋予不同的样式,定义出“引用”、“项目符号”等元素。
引用:
style='Intense Quote'项目符号:
style='List Bullet/Number'
生成文档的过程,其实就是构造Document对象的过程,如添加标题、段落、图像、文字等元素,并为其设置格式,最后通过save()方法保存到磁盘。
定义样式
日常处理Word文档时,我们经常会先定义样式,这样就可以在全文档通用。
比如:首行缩进、设置间距、设置标题样式、自定义一些样式等。
处理表格样式时,可以使用内置的样式支持,这样可以省不少功夫。
如何查看已有的样式呢?可以生成一个测试文档,把里面所有样式都用一遍。
提取文档中的表格数据
普通的表格数据提取相对方便,但是遇到合并单元格,就会麻烦一些。
表格的3个关键概念:cell(单元格)、row(行)、col(列)。
比如:
提取单元格内容:
table.cell(i, j).text()获取表格行数:
table.rows获取表格列数:
table.columns
提取文档内的表格数据
遍历表格有3种方式:按二维矩阵索引、按行、按列:
需要注意的是:不同的迭代方式,同一个单元格内存地址会不同。
原因是python-docx内部使用了列表生成器和切片器来返回当前行/列的单元格。
python-docx中table部分源代码:
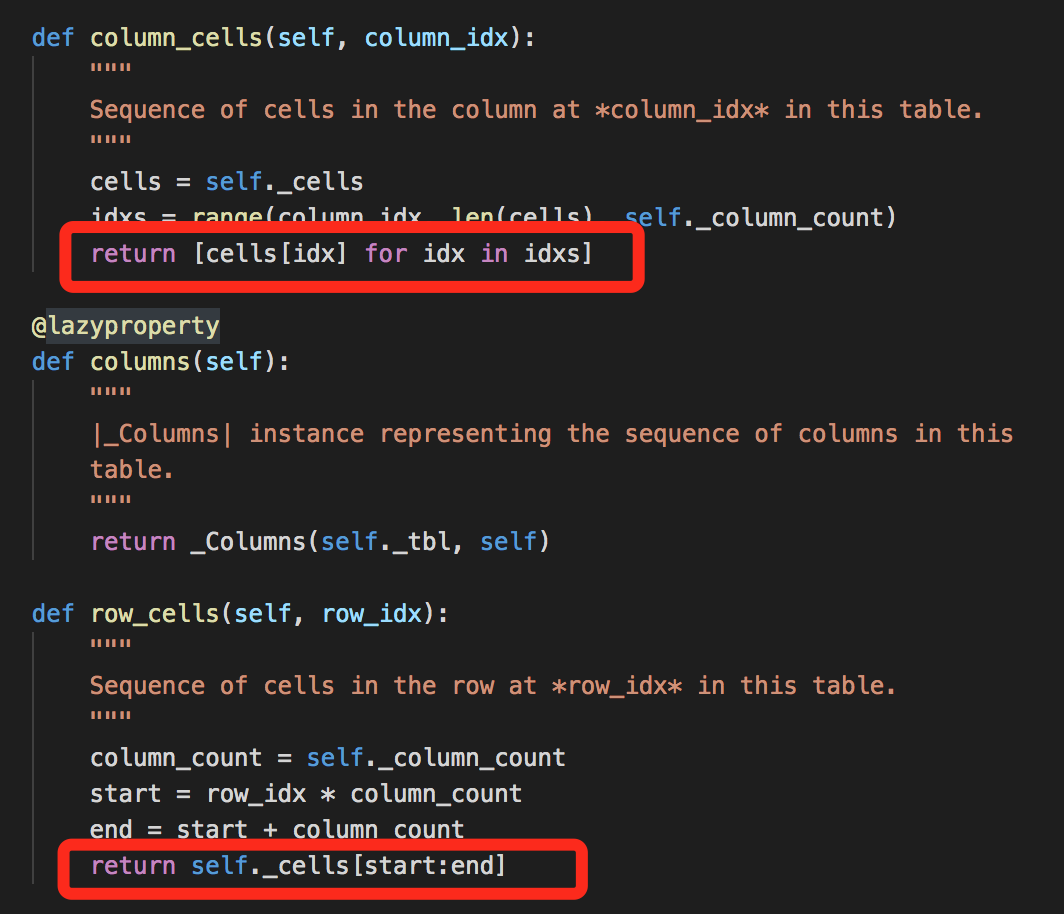
所以,对于单元格合并,不同合并方式(按行/列)在不同迭代中会有不同效果。
同一行两个单元格合并,按
row.cells迭代,其内存地址相同;同一列两个单元格合并,按
colums.cells迭代,其内存地址相同;如果按
table.cell(i, j)迭代,每个单元格内存地址都不同。
提取合并单元格的表格数据
如果我们按常规方式去遍历包含合并单元格的表格,就会获得重复的数据。
想要忽略重复数据,关键是识别重复的单元格。
那我们怎么样判断两个单元格是被合并的呢?
有两个思路:
自定义一个二维状态矩阵,标记每个单元格是否在行内/列内被合并过。
虽然合并单元格的cell内存地址不同,但其
cell._tc值相同。
第一种方式就是先按行迭代,记下那些相同内存地址的单元格,再按列迭代,记下相同内存的单元格。
最后按二维矩阵方式迭代每个单元格,根据之前记下的标记,判断是否有被合并过。
下面给出第二种方式:
添加文件头和尾
有些文档,想要在文件头或尾著名作者、来源、版本等信息。
可以这样设置:
模块能力之外
python-docx目前的版本是0.8.10,功能也并非能100%与Word等软件看齐。比如对于超链接的处理,它目前无能为力,这时就需要根据OpenXML文件规范来手动处理,可以借助docx.oxml包处理XML原始文档。
添加超链接
提取文档内的超链接
提取文档内图片
同理,如果你想用Python提取文档内图片,可以用类似的方法。
总结
本文主要介绍了docx文档的处理方法,包括生成文档、定义样式、素材和表格数据提取等。
当我们需要的处理功能,超出了python-docx模块的能力范围之外,就只能手动处理OpenXML文档本身,这时候可以边参考OpenXML格式标准边测试。
OpenXML标准官网:http://officeopenxml.com/
但,大部分情况下,模块现有的功能,已足够我们应付日常办公的自动化。
Python1024学习群,有兴趣的可以加入,前100名免费。
群内分享源代码、Notebook、测试数据等。

版权声明: 本文为 InfoQ 作者【程一初】的原创文章。
原文链接:【http://xie.infoq.cn/article/f5727eae62dd41b71670bfe8e】。文章转载请联系作者。

公众号:只差一个程序员了 2018.05.15 加入
技术运营,增长黑客。









评论