架构师训练营第 1 期 - 第 9 周学习总结
本周学习了数据库的基本原理、JVM 虚拟机架构、JVM 垃圾回收原理、Java 代码优化技巧
一、数据库的基本原理
数据库主要由连接器、语法分析器、语义分析与优化器、执行引擎这 4 个部分组成。一条 SQL 语句被发送到连接器,然后经过语法分析器生成抽象语法树 AST,AST 经过语义分析与优化器进一步优化,然后再发送给执行引擎,执行引擎会生成逻辑执行计划,再转化为物理执行计划,物理执行计划会查询或者修改底层的物理数据结构。
连接器
连接器会为每个连接请求分配专门的内存空间用于回话上下文管理。一般建立数据库连接比较消耗资源,所以应用程序启动时一般会初始化一些数据库连接放到数据库连接池里面,这样客户端执行 SQL 语句的时候,就不需要再建立连接了,直接从数据库连接池里面获取。
语法分析器
语法分析器根据 SQL 语句的语法规则,生成一个抽象语法树,如果 SQL 语句不符合语法规则,会提示错误。
语义分析与优化器
语义分析与优化器会将各种复杂嵌套的 SQL 语义进行等价转化,并利用索引等信息进一步优化。
执行引擎
执行引擎对 SQL 语句生成执行计划,执行计划包括访问了哪个物理表,用了哪些索引,需要处理的行数。
为什么 PrepareStatement 更好
PrepareStatement 会预先提交有占位符的 SQL 到数据库进行预处理,提前生成执行计划,然后客户端替换占位符的参数,执行真正的 SQL,因为已经有了执行计划,执行引擎可以直接执行,效率会更高。
PrepareStatement 可以防止 SQL 注入攻击
B+树
B+树是一种专门针对磁盘存储而优化的 N 叉排序树,以树节点为单位存储在磁盘中,从根开始查找所需数据所在的节点编号和磁盘位置,将其加载到内存中然后继续查找,直到找到所需的数据。
合理使用索引
虽然添加索引可以提高数据库的查询性能,但是也不能盲目添加索引,一个表不能添加太多的索引,否则增删改表记录时,会更新大量的索引,比较耗时。所以,删除不用的索引,避免不必要的增删开销。使用更小的数据类型创建索引会提升创建的效率。
数据库事务
数据库事务具有 ACID 特性:
A 代表原子性,事务要么都成功,要么都不成功,事务回滚时,数据回到事务开始之前的状态。
C 代表一致性,依照关系约束和函数约束保持数据的一致
I 代表隔离性,2 个事务同时发生时,不会相互干扰,可以独立的进行。当操作的是通过一个表时,通过数据库读写锁保证隔离性
D 代表持久性,一旦事务提交成功,数据会持久的保存到数据库中
数据库事务日志
进行事务操作时,事务日志文件会记录更新前的数据记录,然后再更新数据库中的记录,如果全部记录都更新成功,那么事务正常结束,REDO Log 中记录了更新后的数据记录。如果记录更新失败,那么事务回滚,根据 UNDO Log 中记录的数据进行回复,这样数据恢复到事务提交前的状态,仍然保持数据一致性。
二、JVM 虚拟机架构
Java 是跨平台的语言,Write Once,Run Everywhere。不同平台下面生成的字节码是一样的,Windows 下面生成的字节码,可以在 Linux 下面的 JVM 里面执行,JVM 屏蔽了底层实现,实现了 Java 的跨平台。Java 虚拟机的组成架构如下所示:
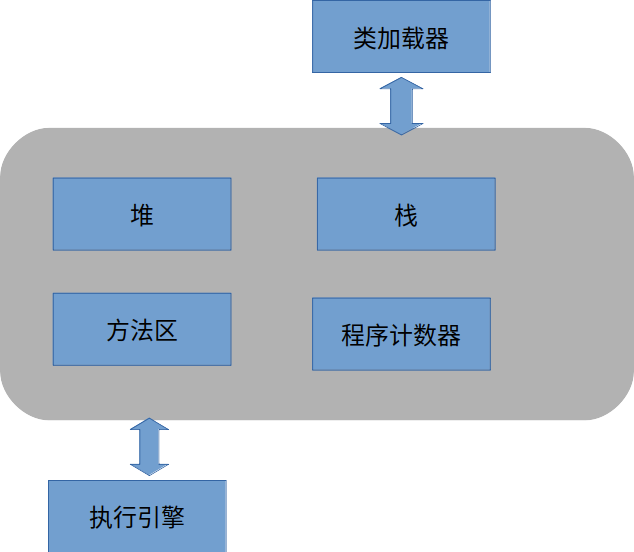
类加载器
类加载器负责把类加载到 JVM 中,也就是把字节码文件加载到 JVM 中。
类加载的双亲委托模型:低层次的类加载器,不能覆盖更高层次的类加载器已经加载的类。如果低层次的类加载器想加载一个类,需要委托给它的上级类加载器来加载,只有上级类加载器没有加载过这个类,才允许当前类加载器加载。所以,JDK 中的类总是由 Bootstrap 类加载器加载,因为 Bootstrap 类加载器是最顶层的类加载器,其他类加载器无法加载 JDK 中的类。同样的,Platform 类加载器会加载 ext 路径下面的类。
自定义类加载器:可以自定义自己的类加载器,实现在一个 JVM 中加载一个类的不同版本,在 JVM 中,即使是同一个类,只要加载这个类的类加载器不同,那么 JVM 会认为它们是不同的类。还可以扩展加载源从网络数据库中加载字节码。还可以定义类加载器实现对字节码的加密和解密操作。
堆
每个 JVM 实例都会有一个唯一的堆。应用程序在运行期间所创建的所有类实例或对象都放在这个堆中,并有所有的应用线程共享。
JVM 为每个线程分配一个堆栈,当程序运行过程中要创建对象时,先在堆中创建对象并获取对象的引用地址,然后堆栈中分配一个指向该引用地址的指针。
方法区和程序计数器
方法区主要存放类加载器加载的字节码,但是每个类对应的类对象是分配在堆内存中的。程序运行的时候,以线程为单位运行,当前方法执行到哪一行,这个信息是存放在程序计数器里面的。
线程栈
所有在方法内定义的基本类型变量,都会被每个运行这个方法的线程放入自己的栈中,线程的栈是线程私有的,因为是私有的,所以是线程安全的。方法执行的时候,所有的局部变量和调用的返回值都保存在一个叫做栈帧的数据结构中,当方法 A 调用方法 B 时,线程把方法 B 的栈帧压入栈顶,当执行完之后,方法 B 的栈帧弹出栈顶。
线程工作内存和 volatile
在 Java 内存模型中,当线程操作主内存中的变量时,线程是把主内存中的变量拷贝到自己的工作内存中进行操作的。当多个线程并发写同一个变量时,因为工作内存缓存的原因,一个线程可能会覆盖另一个线程修改后的结果。通过 volatile 修饰之后,当线程对 volatile 变量写入前,JVM 会强制线程从主内存中刷新变量,当写入后,也会刷新修改后的值到主内存中。
三、JVM 垃圾回收原理
JVM 垃圾回收是指对堆中的不再使用的垃圾对象回收,释放 JVM 的内存。JVM 通过可达性分析来判断对象是否是垃圾对象。具体是通过 GC root 根对象出发,最终能够引用到的对象就是还在使用的对象,否则就是垃圾对象。
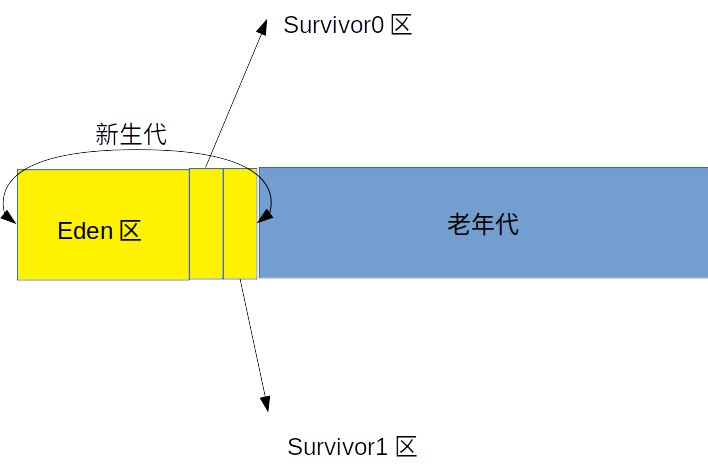
JVM 分代回收
应用程序运行期间,大量的对象都是朝生夕死的对象,通过把堆空间分成新生代和老年代,提前对新生代进行垃圾回收,可以提升垃圾回收的效率。
对象首先被分配在新生代的 Eden 区,当 Eden 区满了之后,JVM 会触发 Young GC 把还在使用的对象复制到 Survivor0 区,并释放 Eden 区的空间,当 Eden 区再次满了之后,触发 Young GC 把还在使用的对象复制到 Survivor1 区中,这样来回几次,还在使用的对象最终会被复制到老年代
当老年代的空间满了之后,会触发 Full GC,这个时候,所有的新生代空间得到释放,老年代中的垃圾对象会被回收,同时还在使用的对象都复制到老年代中。Full GC 和 Young GC 都会触发 Stop the world,但是 Young GC 的时间相对较短,而 Full GC 的时间相对较长,应用程序应当尽量避免经常性的 Full GC
垃圾收集器
垃圾收集器有串行收集器、并行收集器、CMS 收集器、G1 收集器。
串行收集器就是单线程进行垃圾回收,效率低下,现在基本不用。
并行收集器就是多线程进行垃圾回收,比串行性能高,但是每次都是垃圾回收的时候再检查对象可达性,性能有待提高。
CMS 收集器就是解决这个问题,CMS 利用了标记清除算法,有初始标记、再标记、预清理、重新标记、清除、并发重置阶段,本质上是为了提前清除垃圾对象,减小垃圾回收的压力,减少 GC 的次数。
G1 收集器默认情况下是把堆的空间分成 2048 的大小相等的分区,每个分区隶属于新生代或者老年代,并不要求所有新生代的分区或者老年代的分区是连续的,控制的垃圾回收的内存区域粒度更细,提高了垃圾回收的效率,是 Java 9 之后默认的垃圾回收器。
JVM 调优参数
-Xms 可以指定初始堆空间大小
-Xmx 可以指定最大堆大小
-Xmn 可以指定初始新生代大小
-Xss 可以指定线程堆栈大小
JVM 性能诊断工具
jps 用来查看主机上当前有哪些 Java 进程,并获取这些 Java 进程的 pid,利用 pid 可以进行后续的分析
jstat 可以用来查看 Java 进程对应的垃圾回收信息。比如 jstat -gcutil <pid>可以查看当前 JVM 内存的使用情况和 GC 的次数
jmap 可以用来输出 JVM 堆内存,生成堆转储文件。比如 jmap -histo <pid>可以生成堆内存对象的直方图。jmap -dump:format=b,file=xxx <pid>可以生成 dump 文件用于分析内存泄露
jstack 可以用来输出 JVM 线程堆栈信息,通过主机的 top 命令找到消耗 cpu 最多的线程 id,然后在线程堆栈文件中查找具体是属于哪个线程。
JConsole 和 JVisualVM 都是用来监控 JVM 运行情况的可视化工具
四、Java 代码优化技巧
使用多线程
现在的主机都是多核的,可以启动多线程来提高程序处理的速度。
公式有:启动线程数=【任务执行时间 / (任务执行时间 - IO 等待时间)】* CPU 内核数
最佳启动线程数是和 CPU 内核数成正比,和 IO 阻塞时间成反比。如果是 CPU 密集型的任务,那么启动线程最多不超过 CPU 的内核数,因为即使再多的线程,也得等待 CPU 处理完前面的任务。
如果是 IO 密集型的任务,那么启动多线程可以有效提升性能,提高系统吞吐能力和响应速度。
竞态条件与临界区
当多线程同时访问同一个共享资源时,如果对访问顺序敏感,那么就存在竞态条件。导致竞态条件发生的代码区称作临界区。在代码中,可以考虑使用 synchronized 关键字或者 java.util.concurrent.Lock 对临界区资源加锁,保证代码同步执行,避免竞态条件。
线程安全
允许被多个线程安全执行的代码称作线程安全的代码
如果方法局部变量是基础类型的变量,因为是存储在线程自己的堆栈中,不会被多个线程共享,所以,基础类型的局部变量是线程安全的。
方法局部的对象引用如果在方法中不会逃逸,那么它也是线程安全的。
对象成员变量因为是在堆内存中,如果多个线程同时更新同一个对象的成员变量,那么可能会导致并发,不是线程安全的。
Java 内存泄露
Java 内存泄露是指程序创建的对象长期占据堆内存的空间,空间无法得到释放,导致 JVM 可用内存慢慢减小,最终导致 JVM 崩溃或者 JVM 性能低下。比如一些长生命周期对象,静态容器,缓存等,即使没有使用,也保持对它们的引用,容易导致内存泄露
合理使用线程池和对象池
线程的创建和销毁比较耗费系统资源,所以应当尽量避免频繁的创建和销毁线程,可以创建线程池,通过提交异步任务到线程池中执行任务
数据库连接或者其他创建代价比较大的对象在创建后,可以放入对象池中,下次使用时,直接从对象池中获取
对象内容清除,可以利用 ThreadLocal 实现对象内容清除
使用合适的 JDK 容器类
LinkedList 和 ArrayList 的区别及使用场景
HashMap 的算法实现以及应用场景
使用 concurrent 包中的并发容器类替代线程不安全的容器类,比如 CopyOnWriteArrayList,ConcurrentHashMap 等
缩短对象生命周期
缩短对象生命周期,加速垃圾回收
减少对象驻留内存的时间
使用时才创建对象,用完就释放
注意创建对象的步骤(静态代码块 -> 静态成员变量 -> 父类构造方法 -> 子类构造方法)
使用 I/O buffer 及 NIO
延迟写与提前读策略
异步无阻塞 IO 通信
组合代替继承
减少对象耦合
避免太深的继承层次带来的对象创建性能损失
合理使用单例模式
无状态对象
线程安全

还未添加个人签名 2019.05.24 加入
还未添加个人简介









评论