第十三周 数据应用 (二)
大数据计算引擎 Spark
Spark 是 UC Berkeley AMP lab 所开源的类 Hadoop MapReduce 的通用并行框架, 专门用于大数据量下的迭代式计算。
Spark 通常来说运算比 Hadoop 的 MapReduce 框架快,原因是很简单: Hadoop 在一次 MapReduce 计算后会写入磁盘,所以 2 次运算间会有多余 IO 消耗;而 Spark 则是将数据一直缓存在内存中,直到计算结束再写入磁盘,多次运算的情况下, Spark 是比较快的。Spark 的主要特点还包括:
提供 Cache 机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的 IO 开销
提供了一套支持 DAG 图的分布式并行计算的编程框架,减少多次计算中间值写到 HDFS 的开销
使用多线程池模型减少 Task 启动开稍, shuffle 过程中避免不必要的 sort 操作并减少磁盘 IO 操作
Spark 执行过程
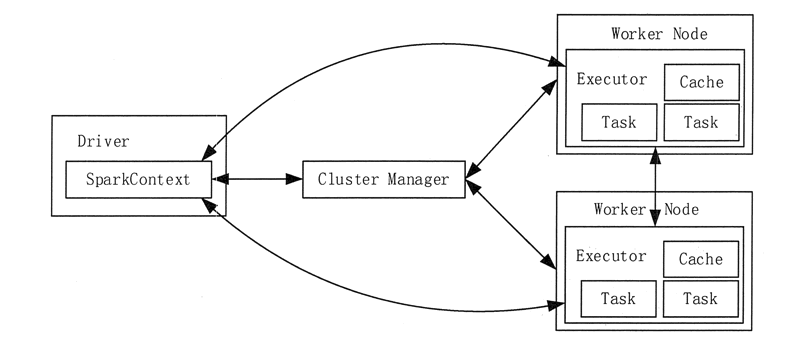
Spark 应用程序启动在自己的 JVM 进程中,即 Driver 进程。启动后 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位:task;
Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
Worker 收到信息后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
Spark 为什么更快
Spark 之所以更快,是因为以下特点:
DAG 切分的多阶段计算过程更快速
使用内存存储中间计算结果更高效
RDD 的编程模型更简单
RDD 是 Spark 的核心概念,是弹性分布式数据集(Resilient Distributed Datasets)的缩写。RDD 既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。
作为编程模型的 RDD
作为 Spark 编程模型的 RDD。我们知道,大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,可以理解成是面向过程的大数据计算。我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么,MapReduce 是面向过程的。
而 Spark 则直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。
作为数据分片的 RDD
跟 MapReduce 一样,Spark 也是对大数据进行分片计算,Spark 分布式计算的数据分片、任务调度都是以 RDD 为单位展开的,每个 RDD 分片都会分配到一个执行进程去处理。
RDD 上的转换操作又分成两种,一种转换操作产生的 RDD 不会出现新的分片,比如 map、filter 等,也就是说一个 RDD 数据分片,经过 map 或者 filter 转换操作后,结果还在当前分片。就像你用 map 函数对每个数据加 1,得到的还是这样一组数据,只是值不同。实际上,Spark 并不是按照代码写的操作顺序去生成 RDD,比如
rdd2 = rdd1.map(func)这样的代码并不会在物理上生成一个新的 RDD。物理上,Spark 只有在产生新的 RDD 分片时候,才会在物理上真的生成一个 RDD,Spark 的这种特性也被称作惰性计算。另一种转换操作产生的 RDD 则会产生新的分片,比如 reduceByKey,来自不同分片的相同 Key 必须聚合在一起进行操作,这样就会产生新的 RDD 分片。然而,实际执行过程中,是否会产生新的 RDD 分片,并不是根据转换函数名就能判断出来的。
流计算
什么是流计算
流计算,即是面向流数据的计算,针对于流计算系统而言,上游的流数据是实时,且持续的,例如某视频网站的视频点播事件,24 小时都在发生,点播事件是离散且无固定规律的,点播事件构成的流数据,将按照其发生的顺序发送至流系统被计算,只要网站不停运,点播事件流将绵延不绝的流向流系统,而流系统,也将根据这些事件流信息进行计算,形成分类推荐,以及对各个视频进行热度统计等。
目前主流的流式计算框架有 Storm、Spark Streaming 和 Flink 三种,其基本原理如下:
Apache Storm
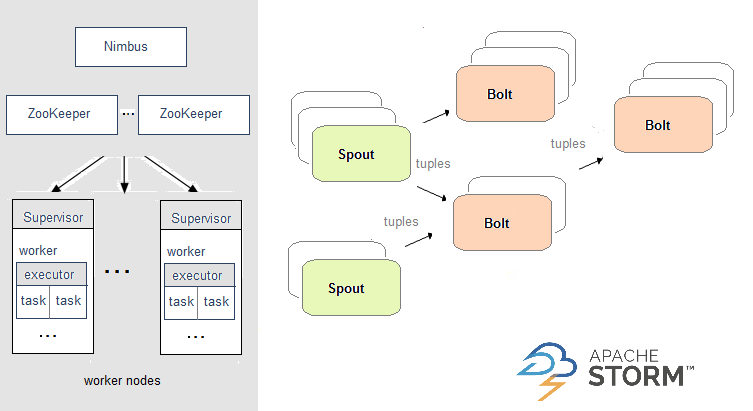
Storm 设计了一个实时计算结构——Topology,这个拓扑结构会被框架提交给计算集群(其中 Master 负责给 Worker 节点分配代码,Worker 节点负责执行代码)。在这个 Topology 结构中,包含 spout 和 bolt 两种角色:数据在 spouts 之间传递;而 bolt 则负责转换数据流。
Spark Streaming
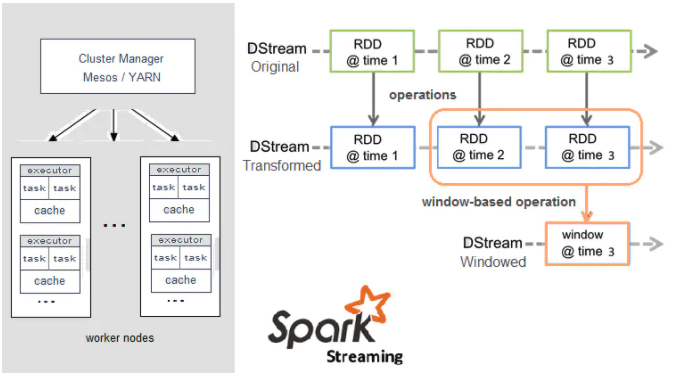
Spark Streaming 是 Spark API 的扩展,它在处理数据流之前会按照时间间隔对数据流进行分段切分。Spark 针对连续数据流的抽象被称为 DStream;它是一组小批量的 RDD,可以通过任意函数和滑动窗口进行转换,实现并行操作。
Apache Flink
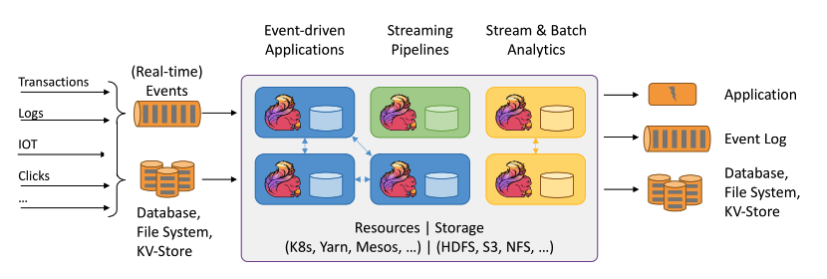
Flink 是针对流处理+批处理的计算框架:流处理的输入流是无界的;而批数据是一种特殊的流处理,输入流被定义为有界的。
Flink 程序由 Stream 和 Transformation 这两个基本构建块组成:Stream 是一个中间结果数据;而 Transformation 是一个操作,对一个或多个 Stream 进行计算,输出一个或多个结果 Stream。
大数据分析和可视化
大数据可视化
数据可视化,是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
它是一个处于不断演变之中的概念,其边界在不断地扩大。主要指的是技术上较为高级的技术方法,而这些技术方法允许利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。与立体建模之类的特殊技术方法相比,数据可视化所涵盖的技术方法要广泛得多。
大数据数据可视化的过程
数据的可视化
指标的可视化
数据关系的可视化
背景数据的可视化
转换成便于接受的形式
聚焦
集中或者汇总展示
扫尾的处理
完美的风格化
互联网运营常用数据指标
新增用户数
新增用户数是网站增长性的关键指标,指新增加的访问网站的用户数(或者新下载 App 的用户数),对于一个处于爆发期的网站,新增用户数会在短期内出现倍增的走势,是网站的战略机遇期,很多大型网站都经历过一个甚至多个短期内用户暴增的阶段。新增用户数有日新增用户数、周新增用户数、月新增用户数等几种统计口径。
用户留存率
新增的用户并不一定总是对网站(App)满意,在使用网站(App)后感到不满意,可能会注销账户(卸载 App),这些辛苦获取来的用户就流失掉了。网站把经过一段时间依然没有流失的用户称作留存用户,留存用户数比当期新增用户数就是用户留存率。
用户留存率= 留存用户数/ 当期新增用户数
计算留存有时间窗口,即和当期数据比,3 天前新增用户留存的,称作 3 日留存;相应的,还有 5 日留存、7 日留存等。新增用户可以通过广告、促销、病毒营销等手段获取,但是要让用户留下来,就必须要使产品有实打实的价值。用户留存率是反映用户体验和产品价值的一个重要指标,一般说来,3 日留存率能做到 40% 以上就算不错了。和用户留存率对应的是用户流失率。
用户流失率= 1 - 用户留存率
活跃用户数
用户下载注册,但是很少打开产品,表示产品缺乏黏性和吸引力。活跃用户数表示打开使用产品的用户数,根据统计口径不同,有日活跃用户数、月活跃用户数等。提升活跃是网站运营的重要目标,各类 App 常用推送优惠促销消息给用户的手段促使用户打开产品。
PV
打开产品就算活跃,打开以后是否频繁操作,就用 PV 这个指标衡量,用户每次点击,每个页面跳转,被称为一个 PV(Page View)。PV 是网页访问统计的重要指标,在移动 App 上,需要进行一些变通来进行统计。
GMV
GMV 即成交总金额(Gross Merchandise Volume),是电商网站统计营业额(流水)、反映网站营收能力的重要指标。和 GMV 配合使用的还有订单量(用户下单总量)、客单价(单个订单的平均价格)等。
转化率
转化率是指在电商网站产生购买行为的用户与访问用户之比。
转化率= 有购买行为的用户数/ 总访问用户数
数据可视化图表与数据监控
折线图
折线图是用的最多的可视化图表之一,通常横轴为时间,用于展示在时间维度上的数据变化规律,正向指标(比如日活跃用户数)斜率向上,负向指标(比如用户流失率)斜率向下,都表示网站运营日趋良好,公司发展欣欣向荣。
散点图
数据分析的时候,散点图可以有效帮助分析师快速发现数据分布上的规律与趋势,可谓肉眼聚类算法。
热力图
热力图用以分析网站页面被用户访问的热点区域,以更好进行页面布局和视觉展示。在地图上展示的热力图则表示了该地区的拥堵和聚集状态,方便用户进行出行规划。
漏斗图
漏斗图可谓是网站数据分析中最重要的图表,表示在用户的整个访问路径中每一步的转化率。
PageRank
作业二里面已经做了详细分析: https://xie.infoq.cn/article/0b1f4a3cb2c5dd48b317167b3
分类和聚类算法
KNN
最近邻居法(KNN 算法,又译 K-近邻算法)是一种用于分类和回归的非参数统计方法。对于一个需要分类的数据,将其和一组已经分类标注好的样本集合进行比较,得到距离最近的 K 个样本,K 个样本最多归属的类别就是这个需要分类数据的类别。
在 KNN 分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k 个最近邻居(k 为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若 k = 1,则该对象的类别直接由最近的一个节点赋予。
在 KNN 回归中,输出是该对象的属性值。该值是其 k 个最近邻居的值的平均值。
算法比较简单,我们举个例子如下:中心的黑圈白点就是要分类的数据,如果 k=3,它就被分配给红色,因为有两个点是红的,且只有一个点是绿的;如果 k=5,它就被分配给红色,因为三个点是绿的,两个点是红的。
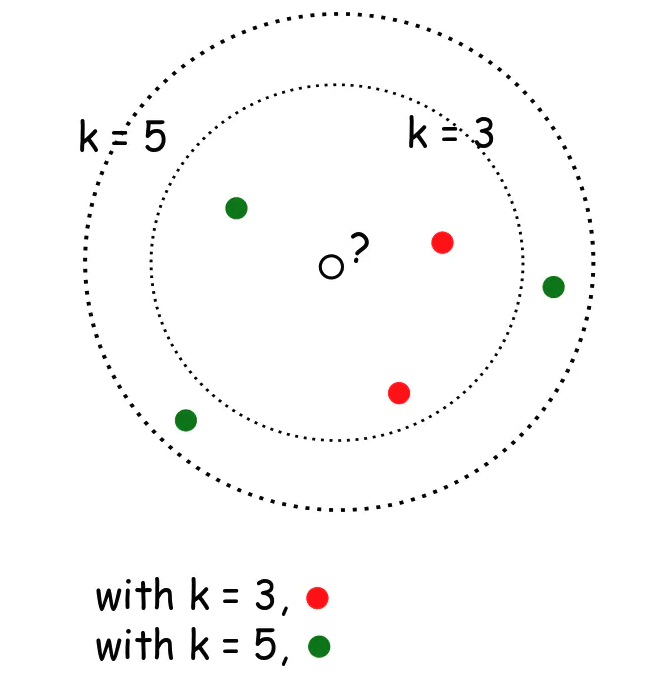
数据的距离算法
对于数据 xi 和 xj,若其特征空间为 n 维实数向量空间 Rn,即 xi=(xi1,xi2,…,xin),xj=(xj1,xj2,…,xjn)
欧氏距离计算公式
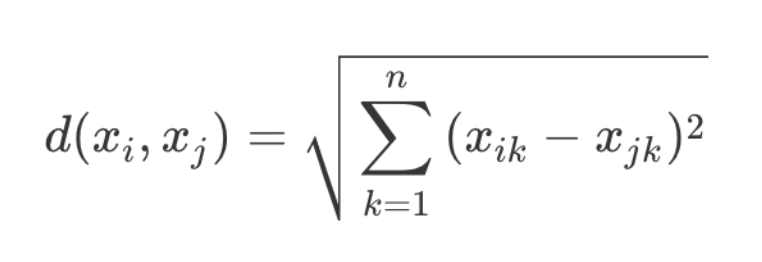
余弦相似度计算公式
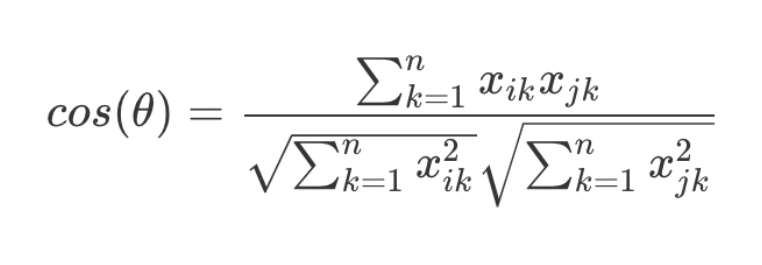
提取文本的特征值 TF-IDF 算法
TF 是词频(Term Frequency),表示某个单词在文档中出现的频率。

IDF 是逆文档频率(Inverse Document Frequency),表示这个单词在所有文档中的稀缺程度。

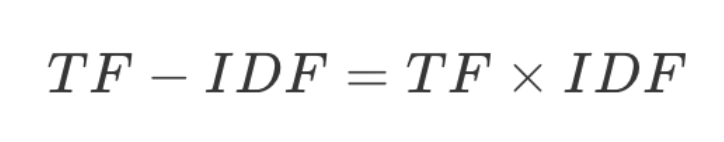
贝叶斯分类算法
贝叶斯公式
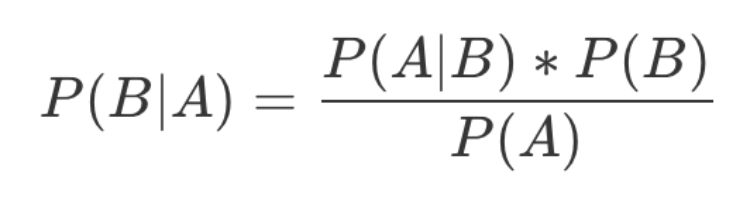
K-means
K-平均算法作为一种聚类分析方法流行于数据挖掘领域。k-means 聚类的目的是:把 n 个点划分到 k 个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。
K-means 聚类的问题事实上是 NP hard 问题,不过存在一种高效的启发式算法。我们简单介绍一下算法的主要步骤:
给定 K 值:就是设定总共分成多少个聚类
随机选定 K 个中心点(质心)
计算每一个点到这 K 个质心的距离
将每个点聚类为离它最近的一个质心的所在类别中
经过上一次分类后,对同一类的数据求平均值,将这个平均值作为新的聚类质心
重复 3、4、5,直到质心不在变化为止
经过如上步骤,我们就可以得到稳定的 K 个聚类了:

推荐引擎算法
推荐引擎算法,就是很多网站中一个叫“猜你喜欢”的算法。虽然,具体算法模型我们不得而知,但是常用推荐值机通常有这么几种:
基于人口统计学的推荐:根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户
基于内容的推荐:根据推荐物品或内容的元数据,发现物品或者内容的相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品
基于项目的协同过滤推荐:根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐
混合的推荐机制:就是通过加权、切换、区分、分层等等手段混合上述推荐机制
机器学习与神经网络算法
机器学习系统架构
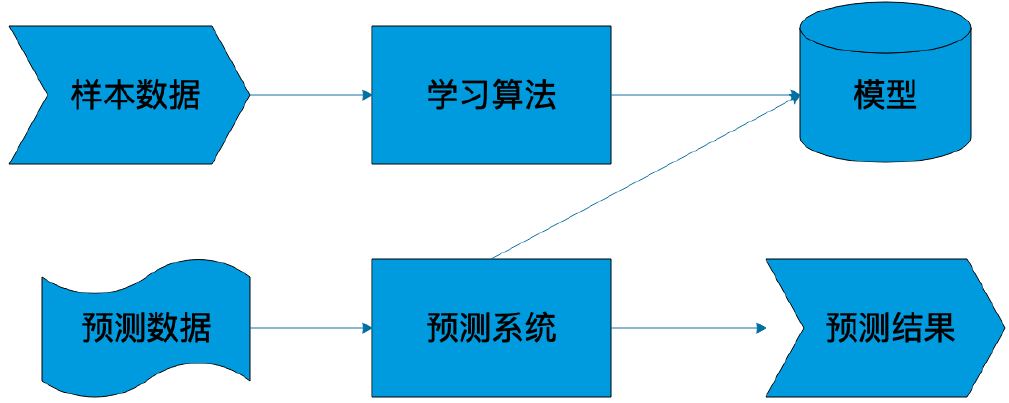
样本
样本就是通常我们常说的“训练数据”,包括输入和结果两部分。比如我们要做一个自动化新闻分类的机器学习系统,对于采集的每一篇新闻,能够自动发送到对应新闻分类频道里面,比如体育、军事、财经等。这时候我们就需要批量的新闻和其对应的分类类别作为训练数据。通常随机选取一批现成的新闻素材就可以,但是分类需要人手工进行标注,也就是需要有人阅读每篇新闻,根据其内容打上对应的分类标签。
T=(x1,y1),(x2,y2),…,(xn,yn) 其中 xn 表示一个输入,比如一篇新闻;yn 表示一个结果,比如这篇新闻对应的类别。
模型
模型就是映射样本输入与样本结果的函数,可能是一个条件概率分布,也可能是一个决策函数。一个具体的机器学习系统所有可能的函数构成了模型的假设空间,数学表示是:
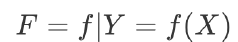
其中 X 是样本输入,Y 是样本输出,f 就是建立 X 和 Y 映射关系的函数。所有 f 的可能结果构成了模型的假设空间 F。
很多时候 F 的函数类型是明确的,需要计算的是函数的参数,比如确定 f 函数为一个线性函数,那么 f 的函数表示就可以写为:
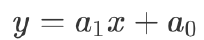
这时候需要计算的就是 a1 和 a0 两个参数的值。这种情况下模型的假设空间的数学表示是:
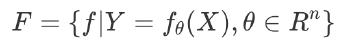
其中θ 为 f 函数的参数取值空间,一个 n 维欧氏空间,被称作参数空间。
算法
算法就是要从模型的假设空间中寻找一个最优的函数,使得样本空间的输入 X 经过该函数的映射得到的 f(X),和真实的 Y 值之间的距离最小。这个最优的函数通常没办法直接计算得到,即没有解析解,需要用数值计算的方法不断迭代求解。因此如何寻找到 f 函数的全局最优解,以及使寻找过程尽量高效,就构成了机器学习的算法。
如何保证 f 函数或者 f 函数的参数空间最接近最优解,就是算法的策略。机器学习中用损失函数来评估模型是否最接近最优解。损失函数用来计算模型预测值与真实值的差距,常用的有 0-1 损失函数、平方损失函数、绝对损失函数、对数损失函数等。以平方损失函数为例,损失函数如下:

对于一个给定的样本数据集,模型 f(X) 相对于真实值的平均损失为每个样本的损失函数的求和平均值,这个值被称作经验风险,如果样本量足够大,那么使经验风险最小的 f 函数就是模型的最优解。
但是相对于样本空间的可能取值范围,实际中使用的样本量总是有限的,可能会出现使样本经验风险最小的模型 f 函数并不能使实际预测值的损失函数最小,这种情况被称作过拟合,即一味追求经验风险最小,而使模型 f 函数变得过于复杂,偏离了最优解。这种情况下,需要引入结构风险以防止过拟合。
在经验风险的基础上加上λJ(f),其中 J(f) 表示模型 f 的复杂度,模型越复杂,J(f) 越大。要使结构风险最小,就要使经验风险和模型复杂度同时小。求解模型最优解就变成求解结构风险最小值。
机器学习的数学原理
给定模型类型,也就是给定函数类型的情况下,如何寻找使结构风险最小的函数表达式。由于函数类型已经给定,实际上就是求函数的参数。各种有样本的机器学习算法基本上都是在各种模型的假设空间上求解结构风险最小值的过程,理解了这一点也就理解了各种机器学习算法的推导过程。
机器学习要从假设空间寻找最优函数,而最优函数就是使样本数据的函数值和真实值距离最小的那个函数。给定函数模型,求最优函数就是求函数的参数值。给定不同参数,得到不同函数值和真实值的距离,这个距离就是损失,损失函数是关于模型参数的函数,距离越小,损失越小。最小损失值对应的函数参数就是最优函数。
数学上求极小值就是求一阶导数,计算每个参数的一阶导数为零的偏微分方程组,就可以算出最优函数的参数值。这就是为什么机器学习要计算偏微分方程的原因。
感知机
感知机是一种比较简单的二分类模型,将输入特征分类为+1、-1 两类,就像下图所示的,一条直线将平面上的两类点分类。
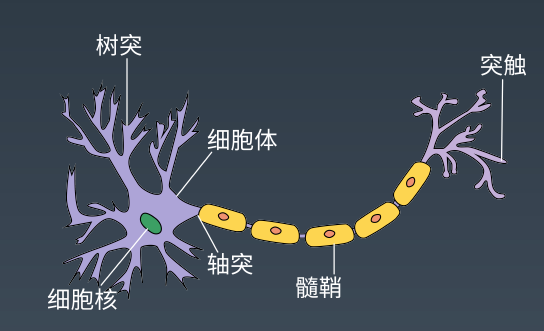
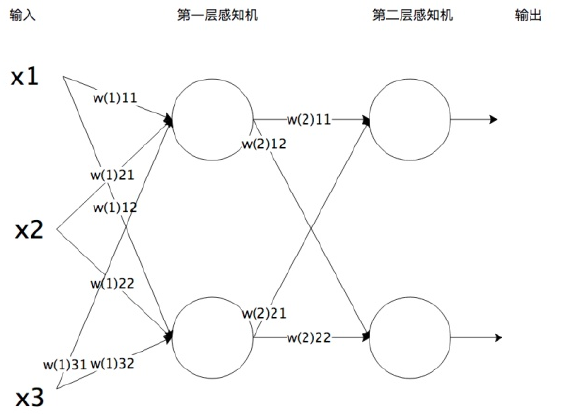
神经网络
版权声明: 本文为 InfoQ 作者【9527】的原创文章。
原文链接:【http://xie.infoq.cn/article/ef606a5f70682501185a0a8ff】。文章转载请联系作者。

还未添加个人签名 2020.04.22 加入
还未添加个人简介









评论