注册中心原理剖析
Eureka注册中心原理
eureka本身有三层缓存,只读缓存,读写缓存,服务注册表和recentlyChangedQueue
服务向注册中心注册或修改时,会将信息写入最底层服务注册表,以及清空读写缓存缓存
后台会有定时线程默认30秒,将读写缓存中的数据同步到只读缓存中
readOnlyCacheMap是被动过期:本身是ConcurrentHashMap,默认是每隔30秒,执行一个定时调度的线程任务,TimerTask,有一个逻辑,会每隔30秒,对readOnlyCacheMap和readWriteCacheMap中的数据进行一个比对,如果两块数据是不一致的,那么就将readWriteCacheMap中的数据放到readOnlyCacheMap中来。
readWriteCacheMap是定时过期:本身是一个Guava Map(CacheBuilder)在构建的时候,指定了一个自动过期的时间,默认值就是180秒,所以你往readWriteCacheMap中放入一个数据过后,自动会等180秒过后,就会将这个数据过期
eureka client在服务启动注册时,会从eureka server端拉取全量注册列表。client启动后默认每隔30秒向eureka增量拉取注册列表
client拉取到增量注册表后,会与自己本地注册表合并,其次eureka server端还会返回server端全量注册表的hash值。合并过后client会计算合并之后本地注册表的hash值,和server端全量注册表hash值进行比对,如果发现client端和server端注册表hash值不同,则client会从server端拉取全量注册表
注册表只要发生修改会直接清空读写缓存
客户端心跳续约:eureka client默认每隔30秒向eureka发送心跳请求。eureka注册中心会有线程定时(默认30秒)检测当前存活的服务节点是否有发送对应心跳请求,如果超过90秒都没有发送心跳则将该节点移除
eureka server感知到服务上下线时,除了更新注册表和只读缓存还会将服务实例变更的信息放入recentlyChangedQueue中,后台有定时器每隔30s监测一遍该队列,将存活时间已经超过180s(3分钟)的实例信息从队列中移除。也就意味着这个队列中只保存最近3分钟服务实例的增量变更记录。client端拉取的过程其实是先从只读缓存中拉取数据,如果只读缓存中没有则找读写缓存,如果读写缓存还没有那么访问增量注册表,增量注册表其实就是这个队列中的信息,如果这个队列也是空的,说明最近没有服务实例状态变更,最后才会访问底层注册表获取全量信息
多级缓存的目的是为了解决多服务读写时对服务注册表加锁而引起的性能问题,读写缓存的存在可以解决对注册表的读取,因为定时线程只会在只读缓存和读写缓存间作同步,读写缓存的数据更新是靠注册表推送,所以注册表本身无需考虑读写并发问题
服务故障感知:
eureka server端有线程池会定时监测服务实例的续约心跳时间60s一次。client端默认30s续约一次,server端默认超过90s则将未续约的client摘除,但其实server端这里存在一个bug,真实应该是等待2 * 90s才会将服务摘除掉,源码注释写得很清楚,至于为什么没有修正不得而知。所以当一个服务挂掉后,默认需要等待2 * 90s(server端故障感知时间) + 30s(server端两级缓存同步时间) + 30s(client拉取注册表时间)= 4min左右client端才能感知到
如果server端感知到有多个client发生故障,最多会摘除注册表中15%的服务实例,所以如果没有一次性摘除,剩下的需要等到定时任务下次执行才会继续摘除,所以此处其实还会延续client对于故障服务实例的感知时间
自我保护机制
首先会判断上一次的整体client实际发送的心跳数是否小于整体client期望的一分钟心跳次数,如果小于就不让清理任何实例。此时eureka server认为自己的网络故障,导致大量服务实例无法发送心跳过来
期望的心跳次数如何计算:
从相邻server节点拷贝过来注册表,和自己本身注册表合并
注册表中服务实例数量 * 2 * 0.85 = 期望心跳次数
这个判断期望心跳次数设计太烂。按照源码意思,如果有10个client节点,每个节点30s同步一次心跳,也就意味着一分钟内应该有10 * 2 * 0.85= 20 * 0.85次心跳次数,但是如果把client向server端同步心跳的时间从30s调整为10s呢?这个判断直接挂掉
如果有服务上下线也需要更改每分钟期望心跳次数,源码中每上线一个服务实例,期望心跳数 = 期望心跳数 + 2(硬编码)
eureka server集群间的数据同步
server端启动后,首先会拉取集群中随机另一个server的服务列表到自己本地
默认10分钟server间相互进行数据同步
每次client端随机找一个server端申请注册、下线、心跳、数据状态变更后,被选择server会向其他所有server进行数据同步(也就意味着如果大规模集中上下线,数据同步会非常频繁)
Nacos注册中心原理
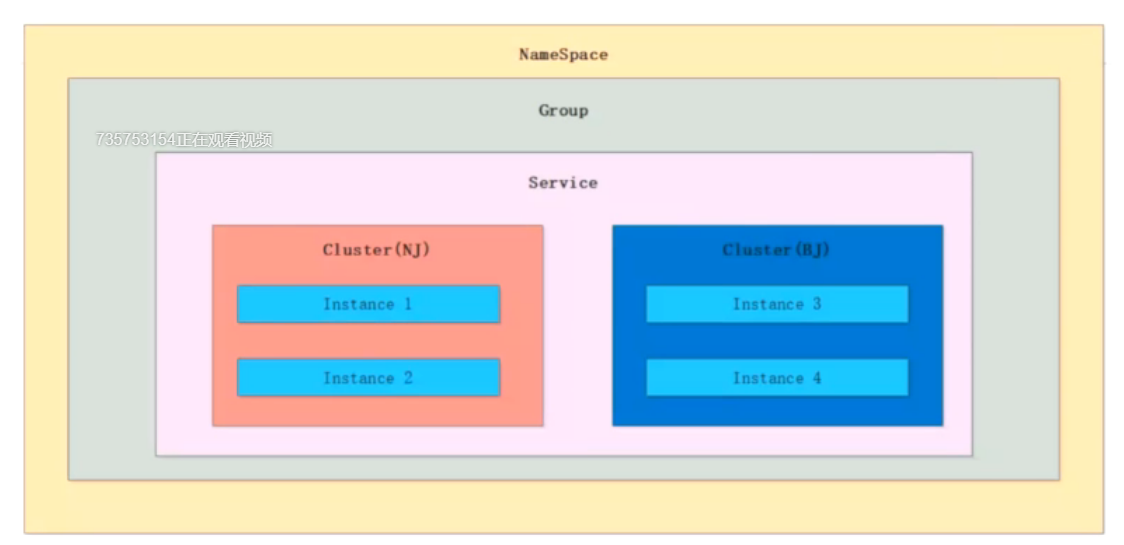
Nacos服务注册表结构:
本身结构是ConcurrentHashMap
Map<namespace, Map<group::serivceName, Service>>
Service结构:Map<clusterName, Cluster>
Cluster结构:Set<Instance>
AP模式(Distro协议)
接收到注册请求后首先判断是CP还是AP,AP模式下是临时节点,CP模式是持久化节点(持久化到磁盘文件)
服务注册后将变化的事件信息放入队列(BlockingQueue)中
会有后台线程不断从队列中取出事件信息,根据不同的事件,如注册节点是CHANGE事件,从注册表的map中取出服务名称对应的服务节点List<Instance>将新节点加入该List中;下线节点是DELETE事件,也就是将该节点从服务节点List移除,此处的事件类似Reactor模型的思想。
更新节点不管是注册还是删除,在nacos中走的其实都是同一个方法updateIps,使用copy on write的方式,更新时首先new一个新的HashMap<服务名称,List<Instance>>,将旧注册列表中该服务名称对应的所有节点信息put到这个map中,之后所有的修改都是更新该map中的List<Instance>,最终将Cluster中的临时节点集合指针直接指向这个更新后的集合
队列本身解决了多服务注册时的并发问题,无需加锁也不会发生写操作覆盖。
其核心思想就是防止读写并发冲突,把原数据复制一份,操作完成后在合并回真正的注册表内存中
本服务完成注册后,会将本次注册封装成一个延迟task放入nacos延迟任务类中的taskMap中,延迟时间为1s,如果有同服务名称多节点注册会将其合并为一个task,合并完成后如果更新节点数超过指定数量(默认1000),则会直接取消掉这个task的延迟时间,将其变为立即触发
后台会有线程每隔100ms从这个ConcurrentHashMap中拿出所有需要执行的task进行处理,此时向集群内其他注册中心通过http同步更新数据
服务节点默认5s向注册中心发送一次心跳,如果注册中心超过15s没有收到心跳就会将该服务节点标记为不健康,如果超过30s将该服务直接下线
总结:nacos的AP模式其实和eureka本身差别不大,但是一方面使用copy on write思想取代了eureka的三级缓存,大幅度提升了服务发现速度(从几十秒缩短到几秒),另一方面nacos采用的是多节点批量更新,解决了上万服务节点场景集中上线时,eureka各节点间频繁进行上下线同步更新通信,导致注册中心QPS飙升的问题,以此可以支持大规模服务节点的注册
CP模式(Raft协议)
注册时先判断当前节点是否是leader节点,如果不是leader会将本次注册请求转发到leader节点,只有leader节点才可以写数据
leader节点首先会将数据放入队列,之后通过队列消费将本次注册写入内存中
同时nacos也会将本次注册信息写入磁盘,通过磁盘保证数据持久化
主节点写入数据成功后,再将数据同步到其他从节点,此时使用CountDownLatch,构造参数为所有节点数 / 2 + 1,如果超过半数节点返回成功即通知客户端写入成功
RaftCore类中init方法,在初始化时会监测本机是否有已经持久化的磁盘文件,如果有会直接从其中恢复数据
选主
服务在等待一定随机时间后向其他节点发送投票信息,如果被超过半数以上节点选中,当前节点就会成为leader节点。
此时其他节点可能还在等待随机时间。
leader节点会向其他节点发送心跳,告知我已经成为leader节点。其他节点停止等待,变成flower节点
leader节点会不断向flower节点发送心跳,flower节点会等待一定时间,如果超过等待时间没有收到leader节点的心跳,则认为leader节点挂掉进而重新选举
版权声明: 本文为 InfoQ 作者【石印掌纹】的原创文章。
原文链接:【http://xie.infoq.cn/article/e5bbf7da955361d9dd071fa74】。文章转载请联系作者。

还未添加个人签名 2018.11.22 加入
还未添加个人简介









评论