服务频繁出现 100 毫秒的延迟,原因是什么?

背景说明
陌陌的微服务框架支持 Redis 协议调用方式, 在使用 Redis 协议调用 MOA 服务时, 每个请求会被包装为一个消息, 这个消息会用一个唯一 ID 来标识,ID 是由机器名称+进程 ID+消息产生的时间戳组成,当请求消息经过网络到达服务端应用后,MOA 框架在处理消息前会先用当前时间减去消息的产生时间,如果差值大于 100 毫秒则会记录该请求到慢请求文件中。正常请求下该文件几乎不会产生数据,但是最近多名业务侧同学反馈慢请求文件数据较多,导致 TP90 数据飙高,希望帮忙排查原因。
排查过程
是否是容器问题?
陌陌的应用层全部跑在 Docker 容器上,为了排查容器自身因素,将该服务的部分实例迁到了 VM 上,对比发现 VM 上的实例基本上没有慢请求日志,所有基本确定该问题跟 Docker 容器相关。
网络不稳?
2018-12-18 12:23:40,822 REQUEST: Command [id=xxxxxxx-kube-node-web-php-
198861545107020.6728, action=/service/xxxx-action-service, source=127.0.0.1, thread=, params={args=[ap6896299708], m=getXxxRecReadNum}] ### waitedTime: 103 ms
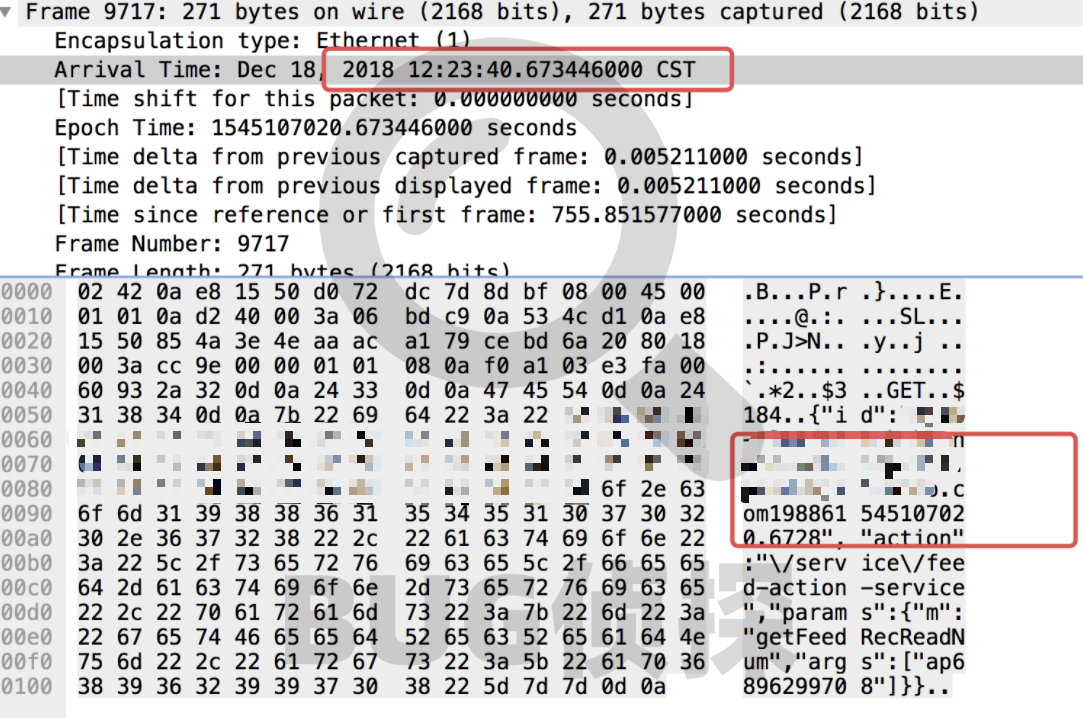
对比消息产生时间和服务端接收到数据包时间可知消息传递的网络耗时几乎可忽略,排除网络不稳定带来的影响。
网卡到 socket 读缓存区慢了?
通过上面 tcpdump 结果来说,数据从网卡到 ReveiveQ 再到用户态获取数据这一个过程也是及时的,为了再次验证这个结论,运维同学通过 systemtap 工具在 tcp_v4_do_rcv 调用时,将 skb 的内容打印出来,并将调用时间打印出来,通过比较系统调用时间和 skb 中的消息时间比对发现基本一致。
Read 系统调用不及时?
hack read 系统,在 read 调用时, 对比 read 触发的时间和 read 到的消息题中的时间已经延迟较大,这个值几乎跟应用层面记录的 waitedTime 一致。至此可以确定是发起 read 调用时就已经出现了时延。
原因分析
一. Read 调用不及时原因
当消息到达 Socket ReceiveQ 时,epollwait 系统调用的阻塞会被唤醒,同时给应用层返回指定 socket 的 readable 事件,Netty IO 线程响应可读事件进行 read 调用,但是实际却没有立刻进行 read 调用。大都数情况下是因为在 IO 线程中执行了耗时操作,导致 worker eventloop group 中没有可用线程去拉取数据,但是显然这和 MOA 的实现机制是冲突的,业务处理逻辑在业务线程中执行,IO 线程并没有耗时操作。还有就是 GC 导致整个应用 STW,通过查看应用日志的确找到了相关线索,在实例 GC 日志上偶尔刷出了 100ms+的 YoungGC 日志,YGC 的执行会 STW,线上服务使用的是 ParNew 并发收集策略,频率基本跟服务耗时突刺吻合。所以问题转变为为什么出现 100msGC。
二. 100ms YGC 的原因
对比 GC 日志,发现单次耗时超过 100ms 的 GC 与正常较少耗时的 YGC 相比,GC 前后的内存占用情况并没有较大差异,即并不是因为单次 GC 的内存大导致 GC 耗时增加。
在一筹莫展之际,运维同事发现了一个现象就是 ParallelGCThreads 线程数出乎意料的多,调整 ParallelGCThreads,限制在 4 个线程,问题解决!但是这个数字怎么算出来的呢?我们看下 GC 线程数据的计算规则:cpu 核数小于 8 gc 线程数等于 cpu 核数,大于 8 的时候=8+(cpu 数-8)*⅝。同时运维同学给出信息,JDK 8u131 版本开始增加了识别 Docker 资源的改进,但不能识别 cpu shares 或 cpu quotas 配置的 CPU 资源,内存资源的识别也没有默认开启,需指定相关参数,这个问题在 JDK 8u191 版本得到了改进,能够正确识别 Docker 的 CPU 、内存资源配置信息。至此 100msGC 的原因得到了确认是因为 JDK 版本不能正确识别 DockerCPU 配置,导致整 ParallelGCThreads 个数异常增大,导致 YGC 突刺。为什么整 ParallelGCThreads 个数多导致 YGC 突刺?
三. ParallelGCThreads 个数多导致 YGC 突刺的原因
发现 linkedin 同样遇到了这样的问题,并将详细的原因做了描述(详见引用一)
在 CFS(引用二)中, 一个 cgroup 被分配确定的 cpu 配额(cfs_quota),这些配额快速被活跃的 JVM GC 多线程用尽,最终导致应用资源被限制。
举例说明:
如果一个应用在一个调度周期内积极的使用 CPU 资源达到 CPU 配额,那么这个应用会被限制(没有更多的 CPU 给它)然后导致在这个应用被暂停在整个调度周期剩余的时间中。
多线程的 JVM GC 使得问题变的更差,因为 cfs_quota 是统计这个应用的所有线程,因此 CPU 配额会被更快的使用掉,JVM GC 有多个并行阶段是不会 STW (stop the world)的,但是这些运行的多线程会导致 CPU 配额更快被消耗完而受到 cgroup 限制,引起应用发生 STW。
作者详细举例阐述了上面的内容:
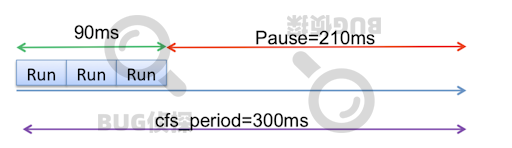
理想情况下,CPU 调度程序会调度应用程序在每个 CFS 周期内稀疏运行,以便应用程序不会长时间暂停。如下图所示,应用程序计划在 300 毫秒 CFS 期间运行 3 次。计划运行之间存在应用程序暂停,预期应用程序暂停为 70 毫秒(假设应用程序完全使用 90 毫秒 CPU 配额)。

第一个问题发生在应用程序耗尽 90ms 的所有 cpu 配额时,例如在某些 CFS 时段的前 90ms 内。然后,由于配额被占用,在剩余的 210ms 期间,应用程序暂停,用户经历 210ms 延迟。请注意,多线程应用程序的问题更严重,因为 CPU 配额可以更快地用完。
GC STW 暂停期间,Java 应用程序更严重,因为 JVM 可以使用多个 GC 线程并行收集垃圾。
对于流行的 JVM 垃圾收集器,如 CMS 和 G1,GC 有多个阶段; 某些阶段是 STW,其它阶段是 concurrent(非 STW)。尽管并发 GC 阶段(使用并发 GC 线程)旨在避免 JVM STW,但 cgroup 的使用完全违背了这个目的。在并发 GC 阶段使用的 CPU 时间也会计入 cgroup 的 CPU 使用计算,这实际上会导致应用程序遇到更大的 STW 暂停。
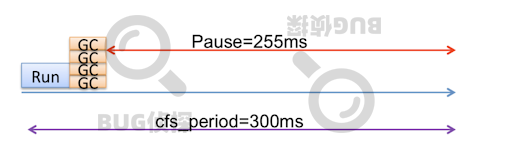
由于 JVM GC 和 CFS 调度之间的交互,在 Linux cgroup 中运行的 Java 应用程序可能会遇到更长的应用程序暂停。为缓解此问题,作者建议使用以下调整:
a: 充分配置 CPU 资源(即 CFS 配额)。显然,分配给 cgroup 的 CPU 配额越大,cgroup 被限制的可能性就越小。
b: 适当调整 GC 线程。
结论总结
至此,整个排查过程就结束了,导致应用被暂停执行的根本原因是:因为 JVM GC 机制和 CFS 调度的互相影响,导致更长的 STW 耗时,进而对应用产生影响。
完善公司体系内的 Docker 容器监控,增加 CPU 受限监控。
名词解释
MOA MOA 的全称是 Momo (Service) Oriented Architecture,是由陌陌技术团队研发的一个 RPC 服务框架。该框架于 2012 年底投入使用,目前是陌陌实现远程调用、跨语言通信等最重要的基础框架之一
引用
Application Pauses When Running JVM Inside Linux Control Groups :
CFS :
https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
版权声明: 本文为 InfoQ 作者【BUG侦探】的原创文章。
原文链接:【http://xie.infoq.cn/article/e4db2b4be0d537a3e94ee9447】。文章转载请联系作者。

还未添加个人签名 2021.06.08 加入
专注于发掘程序员/工程师的有趣灵魂,对工作中的思路与总结进行闪光播报。









评论