

Week 13 学习总结
本周主要介绍了Spark、流计算、大数据可视化、大数据相关算法以及机器学习相关知识点。
1 Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
1.1 Spark的特点
-DAG切分的多阶段计算过程更快速;
-使用内存存储中间计算结果更高效;
-RDD的编程模型更简单。
1.2 Spark WordCount编程示例

1.3 作为编程模型的RDD
RDD是Spark的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。
RDD既是Spark面向开发者的编程模型,又是Spark自身架构的核心元素。
我们知道,大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个Map阶段,一个Reduce阶段,可以理解成是面向过程的大数据计算。
我们在用MapReduce编程的时候,思考的是,如何将计算逻辑用Map和Reduce两个阶段实现,map 和reduce函数的输入和输出是什么,MapReduce是面向过程的。
而Spark则直接针对数据进行编程,将大规模数据集合抽象成一个RDD对象,然后在
这个RDD上进行各种计算处理,得到一个新的RDD,继续计算处理,直到得到最后的
结果数据。
所以Spark可以理解成是面向对象的大数据计算。我们在进行Spark编程的
时候,思考的是一个RDD对象需要经过什么样的操作,转换成另一个RDD对象,思考
的重心和落脚点都在RDD 上。
WordCount的代码示例里,第2行代码实际上进行了3次RDD转换,每次转换都得到
一个新的RDD,因为新的RDD可以继续调用RDD的转换函数,所以连续写成一行代码。
事实上,可以分成3行。
val rdd1 = textFile.flatMap(line => line.split(" "))
val rdd2 = rdd1.map(word =>(word,1))
val rdd3 = rdd2.reduceByKey(_+_)
RDD上定义的函数分两种,一种是转换(transformation)函数,这种函数的返回值还
是 RDD;另一种是执行(action)函数,这种函数不再返回 RDD。
RDD定义了很多转换操作函数,比如有计算map(func)、过滤 filter(func)、合并数据
集union(otherDataset)、根据Key聚合reduceByKey(func, [numPartitions])、连接
数据集join(otherDataset, [numPartitions])、分组 groupByKey([numPartitions])等
十几个函数。
1.4 作为数据分片的RDD
跟MapReduce一样,Spark也是对大数据进行分片计算,Spark分布式计算的数据分
片、任务调度都是以RDD为单位展开的,每个RDD分片都会分配到一个执行进程去处
理。
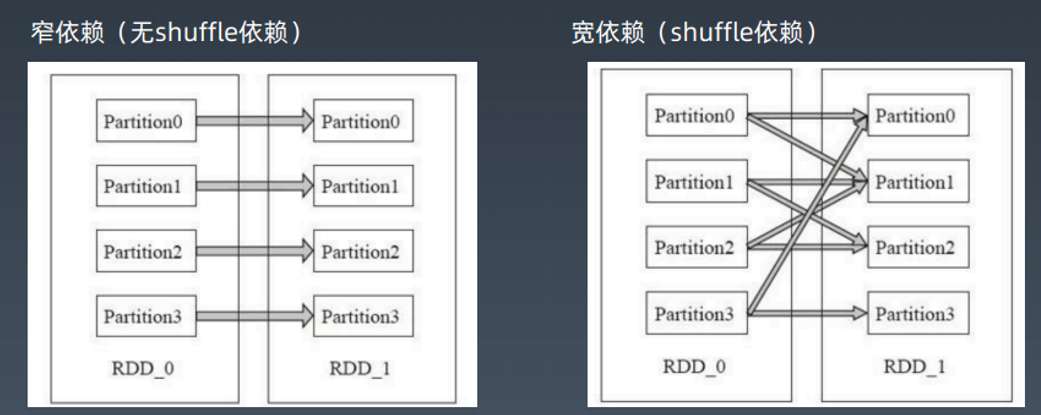
RDD上的转换操作又分成两种,一种转换操作产生的RDD不会出现新的分片,比如
map、filter等,也就是说一个RDD数据分片,经过map或者filter转换操作后,结
果还在当前分片。就像你用map 函数对每个数据加1,得到的还是这样一组数据,只是
值不同。实际上,Spark并不是按照代码写的操作顺序去生成 RDD,比如
rdd2 = rdd1.map(func)
这样的代码并不会在物理上生成一个新的RDD。物理上,Spark 只有在产生新的RDD
分片时候,才会真的生成一个RDD,Spark的这种特性也被称作惰性计算。
另一种转换操作产生的RDD则会产生新的分片,比如reduceByKey,来自不同分片的
相同Key必须聚合在一起进行操作,这样就会产生新的RDD分片。然而,实际执行过
程中,是否会产生新的RDD分片,并不是根据转换函数名就能判断出来的。
1.5 Spark的计算阶段
和MapReduce一个应用一次只运行一个map和一个reduce不同,Spark可以根据
应用的复杂程度,分割成更多的计算阶段(stage),这些计算阶段组成一个有向无环图
DAG,Spark任务调度器可以根据DAG的依赖关系执行计算阶段。
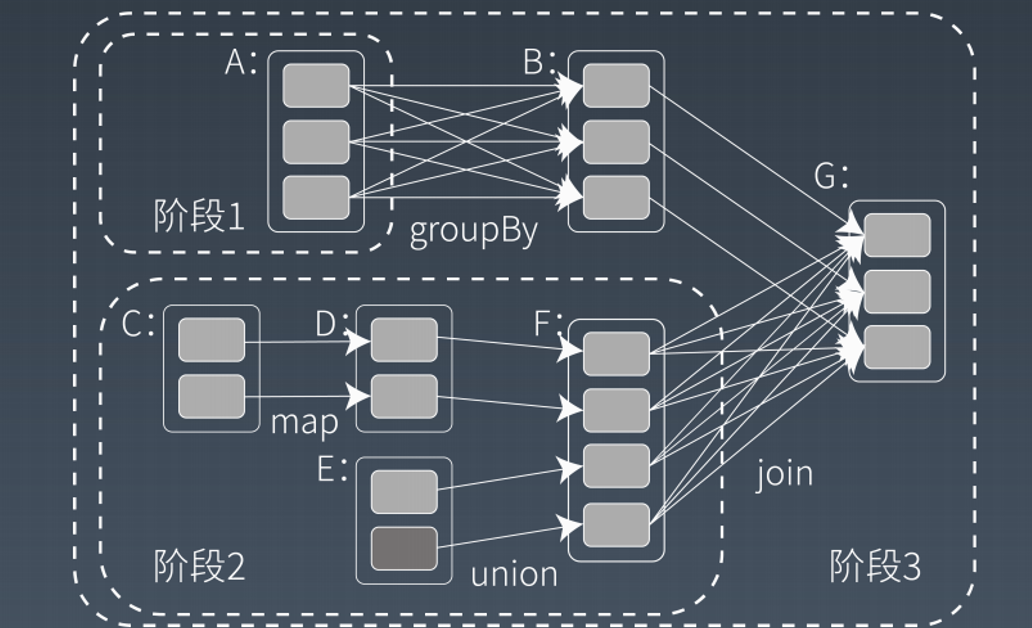
以上整个应用被切分成3个阶段,阶段3需要依赖阶段1和阶段2,阶段1和阶段2互不依赖。
Spark在执行调度的时候,先执行阶段1和阶段2,完成以后,再执行阶段3。
如果有更多的阶段,Spark的策略也是一样的。只要根据程序初始化好DAG,就建立了依赖关系,然后根据依赖关系顺序执行各个计算阶段,Spark大数据应用的计算就完成了。
Spark作业调度执行的核心是DAG,有了DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合
(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现了大数据的分布式计
算。
负责Spark应用DAG生成和管理的组件是DAGScheduler,DAGScheduler根据程序
代码生成 DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。
Spark也需要通过shuffle 将数据进行重新组合,相同Key 的数据放在一起,进行聚合、
关联等操作,因而每次shuffle 都产生新的计算阶段。这也是为什么计算阶段会有依赖关
系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执
行完毕才能进行shuffle,并得到数据。
计算阶段划分的依据是 shuffle,不是转换函数的类型,有的函数有时候有shuffle,有时候没有。
上例中 RDDB和RDD F进行join,得到RDD G,这里的 RDDF需要进行shuffle,
RDD B就不需要,
1.6 Spark的作业管理
Spark里面的RDD函数有两种,一种是转换函数,调用以后得到的还是一个RDD,RDD的计算逻辑主要通过转换函数完成。
另一种是action函数,调用以后不再返回RDD。比如count()函数,返回RDD中数据的元素个数; saveAsTextFile(path),将RDD数据存储到path路径下。Spark的DAGScheduler在遇到shuffle的时候,会生成一个计算阶段,在遇到action函数的时候,会生成一个作业(job)。
RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段会包含很多个计算任务(task)。
1.7 Spark的执行过程
Spark支持Standalone、Yarn、Mesos、Kubernetes等多种部署方案,几种部署方
案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。
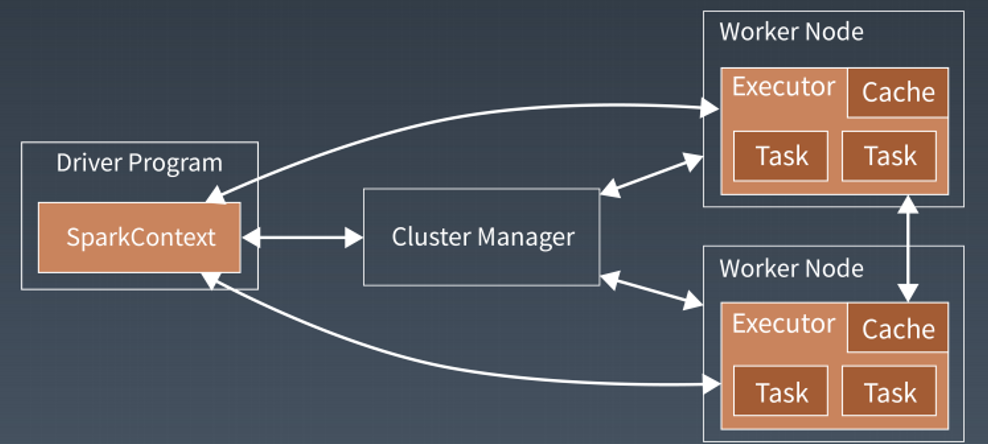
首先,Spark应用程序启动在自己的JVM进程里,即 Driver进程,启动后调用
SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造
执行的DAG图,切分成最小的执行单位也就是计算任务。
然后Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster
Manager收到请求以后,将Driver的主机地址等信息通知给集群的所有计算节点
worker。
Worker收到信息以后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己
的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的
Worker分配任务。
Worker收到任务后,启动Executor进程开始执行任务。Executor先检查自己是否有
Driver的执行代码,如果没有,从Driver下载执行代码,通过Java反射加载后开始执行。
2 流计算
实时计算系统特点:
-低延迟
-高性能
-分布式
-可伸缩
-高可用
2.1 Storm
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
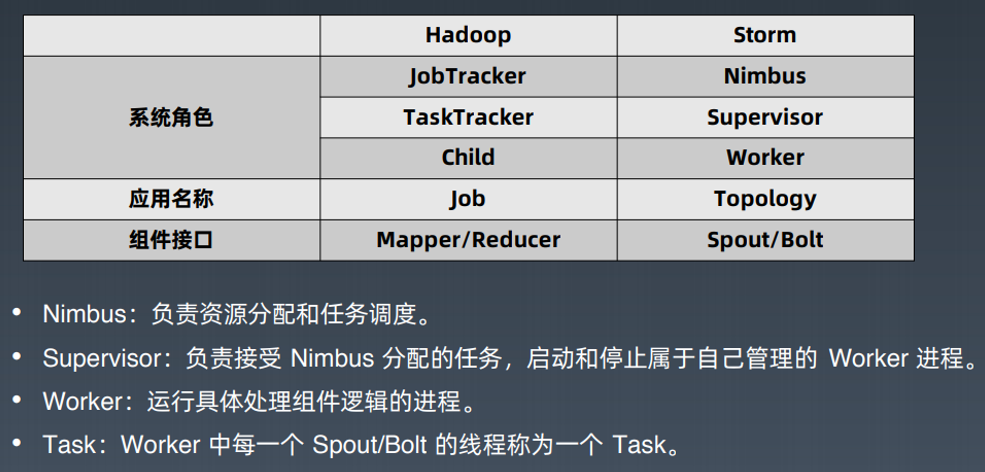

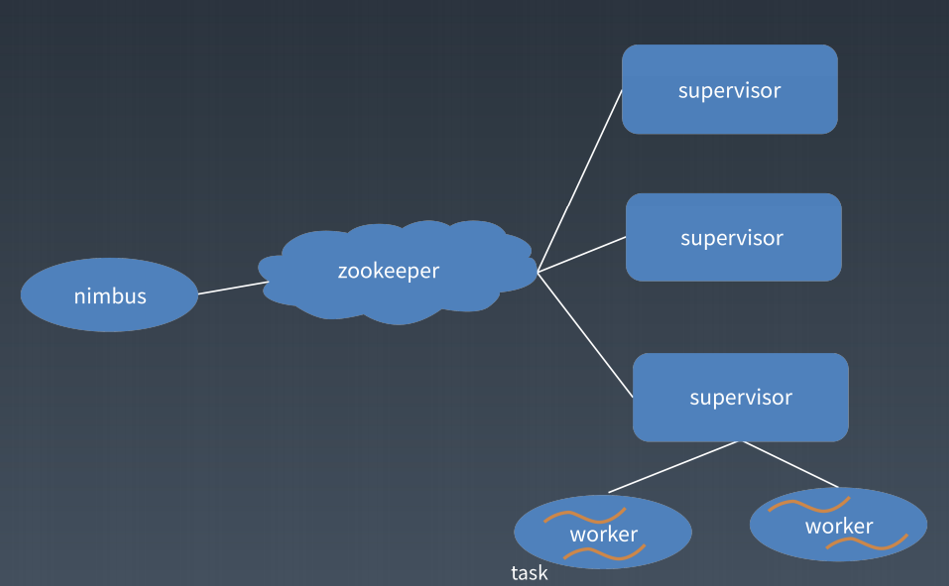
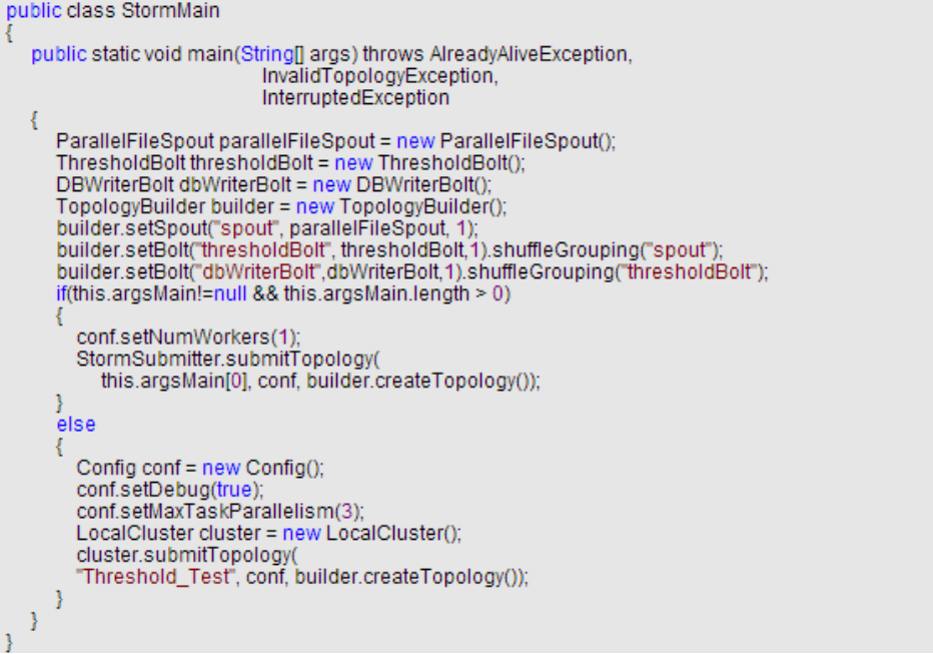
-代码示例:
2.2 Spark Streaming
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理。
支持多种数据源获取数据:

*如果上图中一批一批的数据都比较小时,Spark Engine执行起来就会很快,这样整个过程看起来就像是实时的流计算了,所以Spark Streaming也被称为类实时计算。
2.3 Flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
-Flink架构:
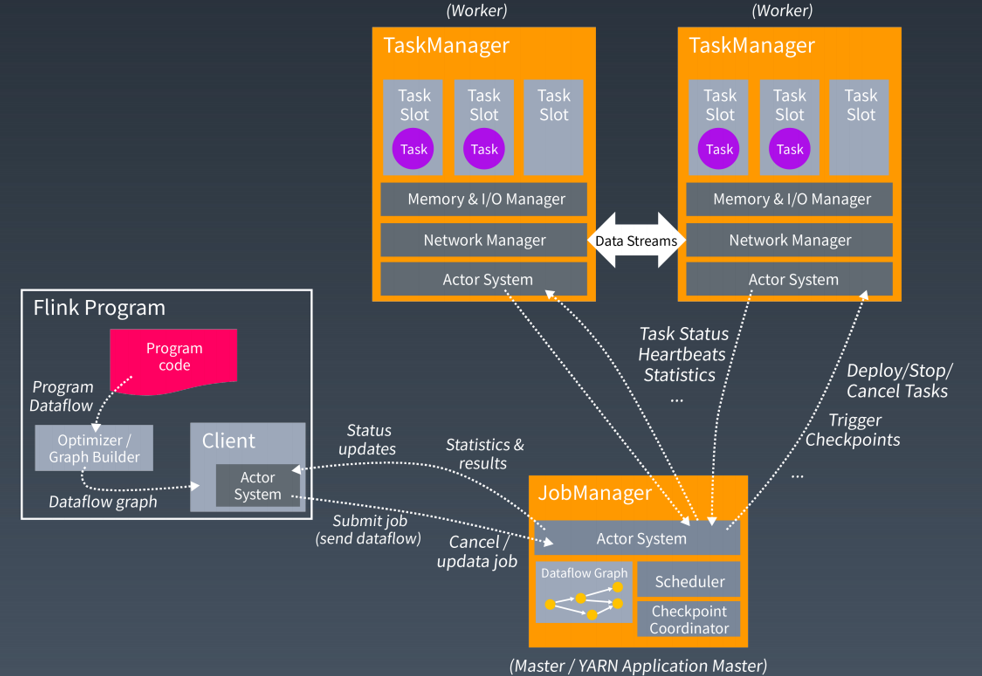

-Flink WordCount代码示例:

3 Impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
-架构:
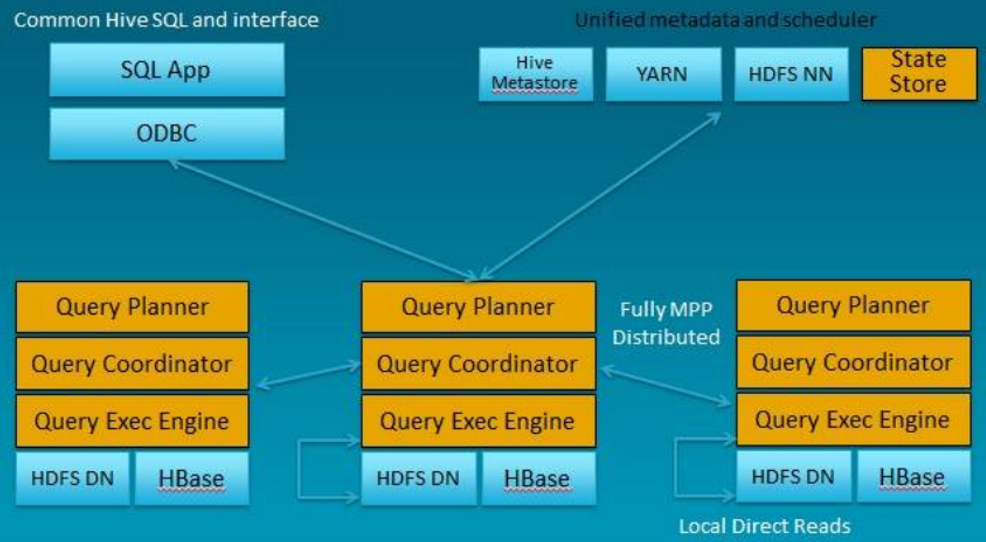
-功能:
· Impala可以根据Apache许可证作为开源免费提供。
· Impala支持内存中数据处理,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。 [2]
· 使用类SQL查询访问数据。
· Impala为HDFS中的数据提供了更快的访问。
· 可以将数据存储在Impala存储系统中,如Apache HBase和Amazon s3。
· Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
-优点:
1. Impala不需要把中间结果写入磁盘,省掉了大量的I/O开销。
2. 省掉了MapReduce作业启动的开销。MapReduce启动task的速度很慢(默认每个心跳间隔是3秒钟),Impala直接通过相应的服务进程来进行作业调度,速度快了很多。
3. Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。
4. 通过使用LLVM来统一编译运行时代码,避免了为支持通用编译而带来的不必要开销。
5. 用C++实现,做了很多有针对性的硬件优化,例如使用SSE指令。
6. 使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
4 HiBench
HiBench是一个大数据基准测试套件,可帮助评估大数据框架的速度,吞吐量和系统资源利用率。
包括Sort,WordCount,TeraSort,Sleep,SQL,PageRank,Nutch索引,Bayes,Kmeans,NWeight和增强型DFSIO等测试方向。
它支持的框架有:hadoopbench、sparkbench、stormbench、flinkbench、gearpumpbench。

5 大数据可视化
5.1 互联网运营常用数据指标
-新增用户数:
新增用户数是网站增长性的关键指标,指新增加的访问网站的用户数(或者新下载App的用户数),对于一个处于爆发期的网站,新增用户数会在短期内出现倍增的走势,是网站的战略机遇期,很多大型网站都经历过一个甚至多个短期内用户暴增的阶段。
新增用户数有日新增用户数、周新增用户数、月新增用户数等几种统计口径。
-用户留存率:
新增的用户并不一定总是对网站(App)满意,在使用网站(App)后感到不满意,可能会注销账户(卸载App),这些辛苦获取来的用户就流失掉了。
网站把经过一段时间依然没有流失的用户称作留存用户,留存用户数比当期新增用户数就是用户留存率。
用户留存率=留存用户数/当期新增用户数
计算留存有时间窗口,即和当期数据比,3天前新增用户留存的,称作3日留存;相应
的,还有5日留存、7日留存等。新增用户可以通过广告、促销、病毒营销等手段获取,
但是要让用户留下来,就必须要使产品有实打实的价值。用户留存率是反映用户体验和
产品价值的一个重要指标,一般说来,3日留存率能做到40%以上就算不错了。和用户留存率对应的是用户流失率。
用户流失率=1-用户留存率
-活跃用户数:
用户下载注册,但是很少打开产品,表示产品缺乏黏性和吸引力。活跃用户数表示打开使用产品的用户数,根据统计口径不同,有日活跃用户数、月活跃用户数等。提升活跃是网站运营的重要目标,各类App常用推送优惠促销消息给用户的手段促使用户打开产品。
-PV:
打开产品就算活跃,打开以后是否频繁操作,就用PV这个指标衡量,用户每次点击,每个页面跳转,被称为一个PV(Page View)。
PV是网页访问统计的重要指标,在移动App上,需要进行一些变通来进行统计。
-GMV:
GMV即成交总金额(Gross Merchandise Volume),是电商网站统计营业额(流水)、反
映网站营收能力的重要指标。
和GMV配合使用的还有订单量(用户下单总量)、客单价(单个订单的平均价格)等。
-转化率:
转化率是指在电商网站产生购买行为的用户与访问用户之比。
转化率=有购买行为的用户数/总访问用户数
用户从进入网站(App)到最后购买成功,可能需要经过复杂的访问路径,每个环节都
有可能会离开:进入首页想了想没什么要买的,然后离开;搜索结果看了看不想买,然
后离开;进入商品详情页面,看看评价、看看图片、看看价格,然后离开;放入购物车
后又想了想自己的钱包,然后离开;支付的时候发现不支持自己喜欢的支付方式,然后
离开...
一个用户从进入网站到支付,完成一笔真正的消费,中间会有很大概率流失,网
站必须要想尽各种办法:个性化推荐、打折促销、免运费、送红包、分期支付,以留住用户,提高转化率。
5.2 常用可视化图表
-折线图
-散点图
-热力图
-漏斗图
-饼状图
-柱状图
6 大数据算法和机器学习
6.1 网页排名算法PageRank
PageRank,网页排名,又称网页级别,Google 左侧排名或佩奇排名,是一种由搜索
引擎根据网页之间相互的超链接计算的技衍,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。
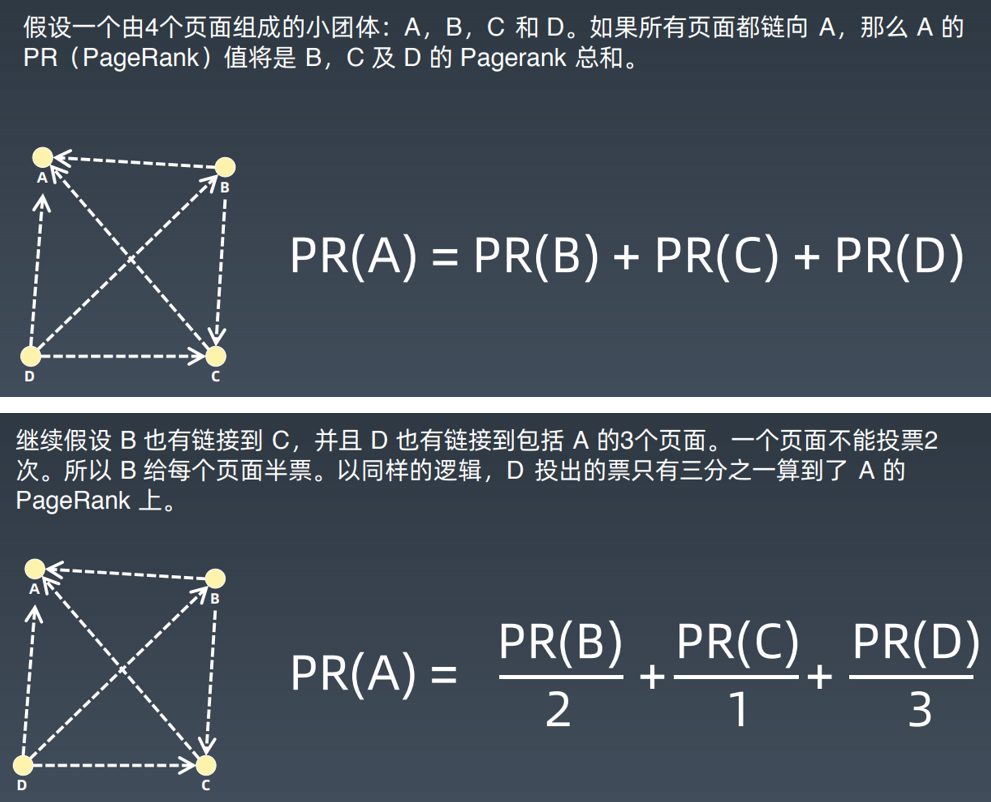

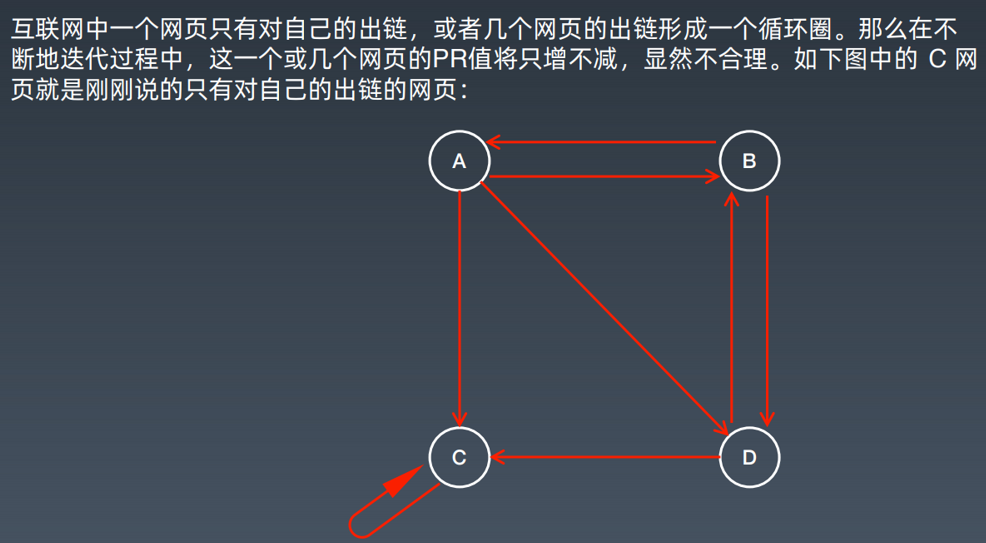


6.2 KNN分类算法
KNN 算法,也叫K近邻(K Nearest Neighbour)算法。
对于一个需要分类的数据,将其和一组已经分类标注好的样本集合进行比较,得到距离最近的K个样本,K个样本最多归属的类别,就是这个需要分类数据的类别。
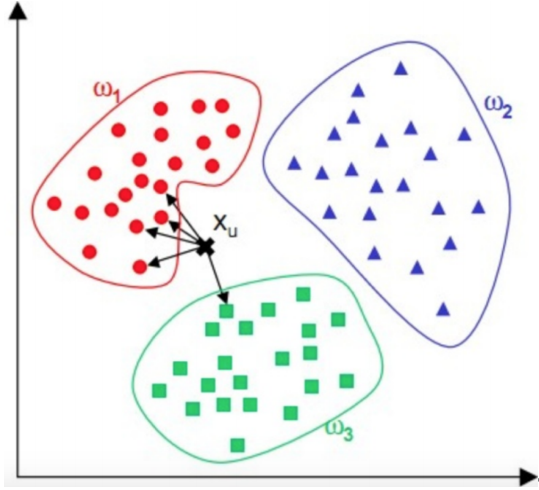

-数据的距离算法:

6.3 TF-IDF算法

6.4 贝叶斯分类算法

6.5 K-means 聚类算法
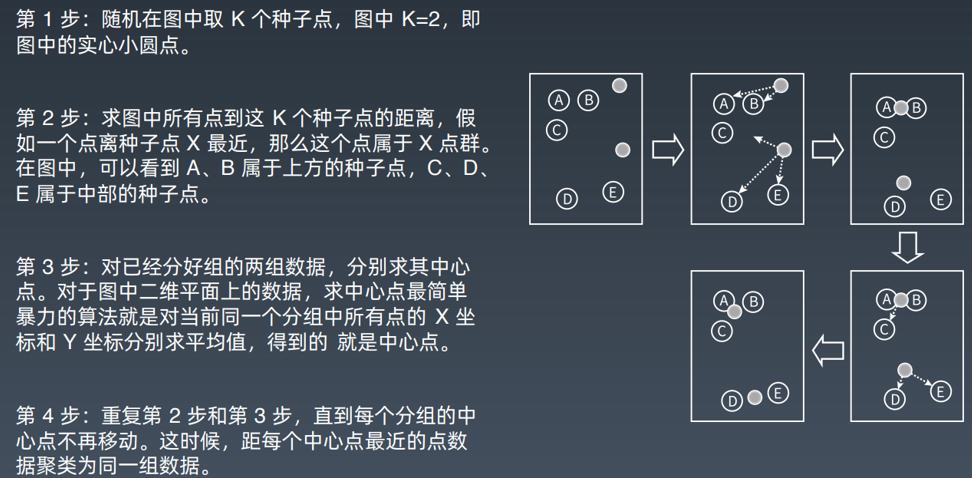
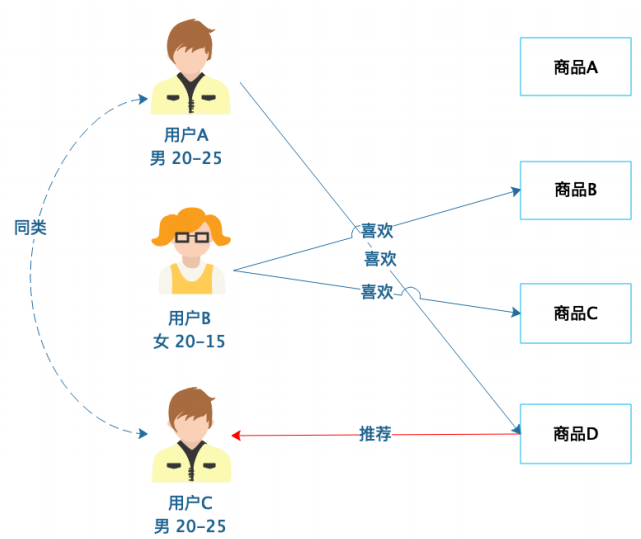
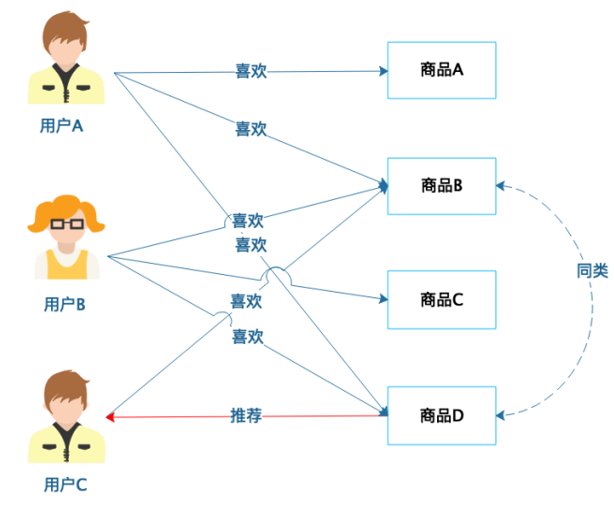
6.6 推荐引擎算法
-基于人口统计的推荐:
-基于商品属性的推荐:
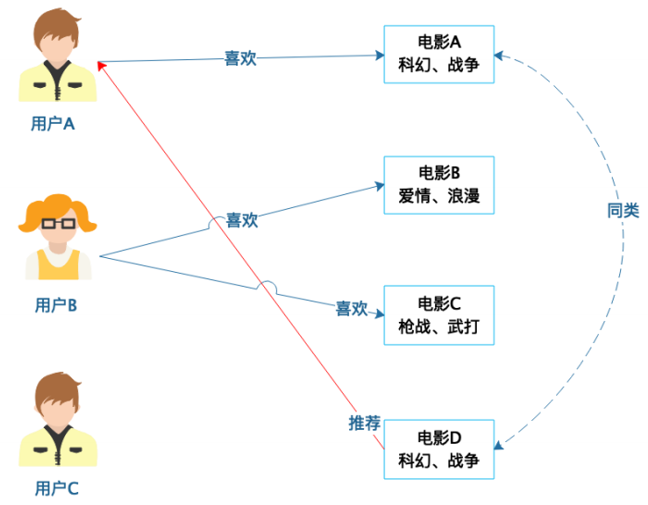
-基于用户的协同过滤推荐:
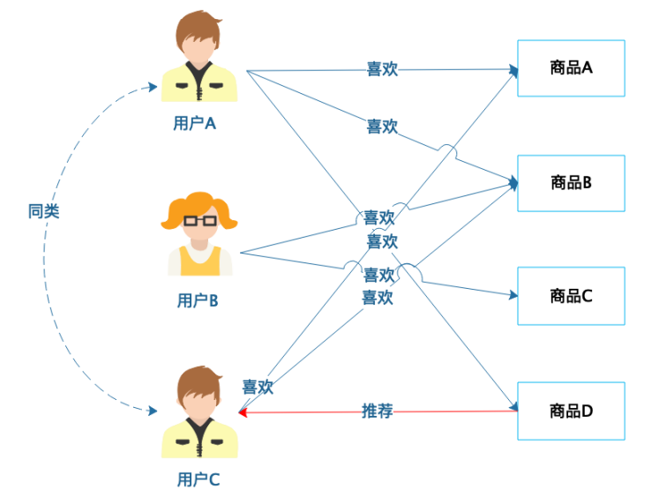
-基于商品的协同过滤推荐:
7 机器学习
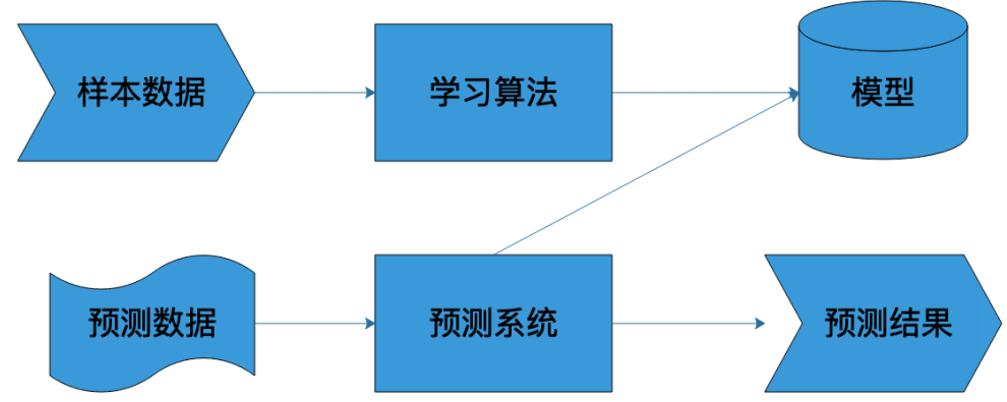
7.1 机器学习系统的架构
7.2 样本
样本就是通常我们常说的“训练数据”,包括输入和结果两部分。比如我们要做一个自
动化新闻分类的机器学习系统,对于采集的每一篇新闻,能够自动发送到对应新闻分类
频道里面,比如体育、军事、财经等。这时候我们就需要批量的新闻和其对应的分类类
别作为训练数据。通常随机选取一批现成的新闻素材就可以,但是分类需要人手工进行标注,也就是需要有人阅读每篇新闻,根据其内容打上对应的分类标签。
T=(x1,y1),(x2,y2),....(xn,yn)
其中xn表示一个输入,比如一篇新闻;yn表示一个结果,比如这篇新闻对应的类别。
7.3 算法

7.4 模型

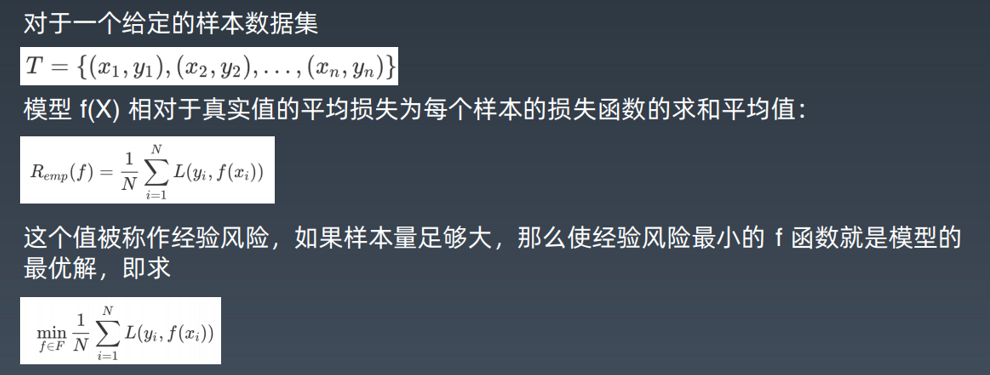

7.5 机器学习的数学原理
给定模型类型,也就是给定函数类型的情况下,如何寻找使结构风险最小的函数表达式。
由于函数类型已经给定,实际上就是求函数的参数。各种有样本的机器字习算法基本上
都是在各种模型的假设空间上求解结构风险最小值的过程,理解了这一点也就理解了各种机器学习算法的推导过程。
机器学习要从假设空间寻找最优函数,而最优函数就是使样本数据的函数值和真实值距
离最小的那个函数。给定函数模型,求最优函数就是求函数的参数值。给定不同参数,
得到不同函数值和真实值的距离,这个距离就是损失,损失函数是关于模型参数的函数,距离越小,损失越小。最小损失值对应的函数参数就是最优函数。
数学上求极小值就是求一阶导数,计算每个参数的一阶导数为零的偏微分方程组,就可
以算出最优函数的参数值。这就是为什么机器学习要计算偏微分方程的原因。
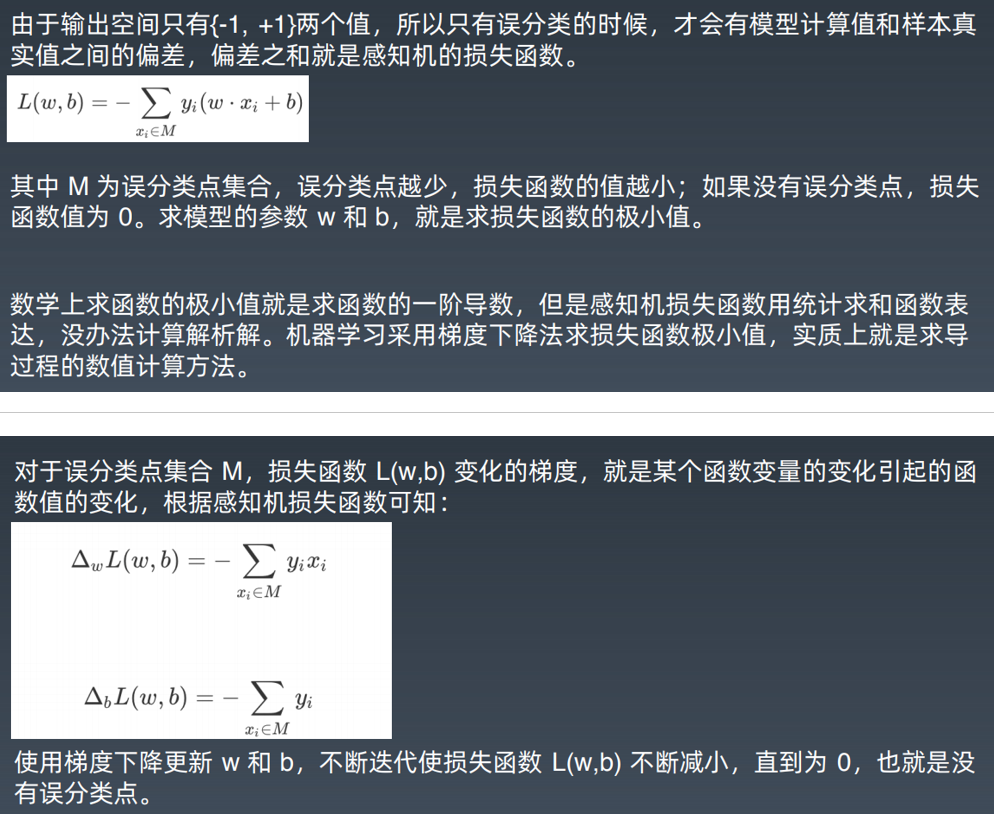
7.6 感知机


7.7 神经网络
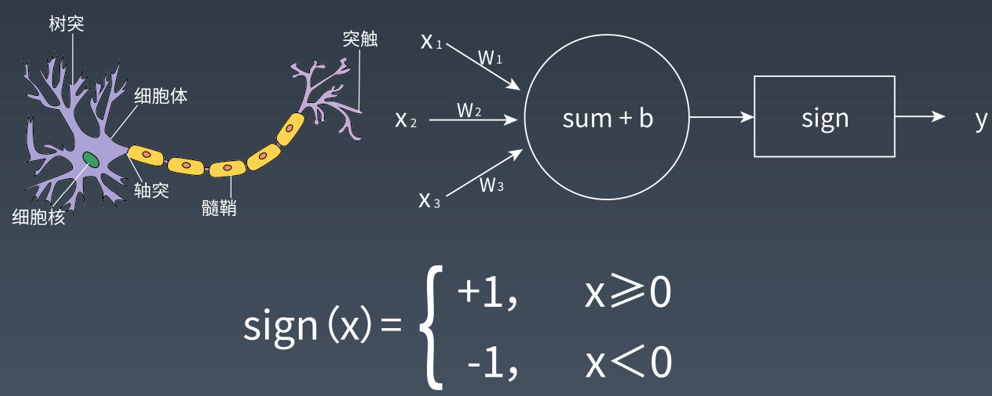
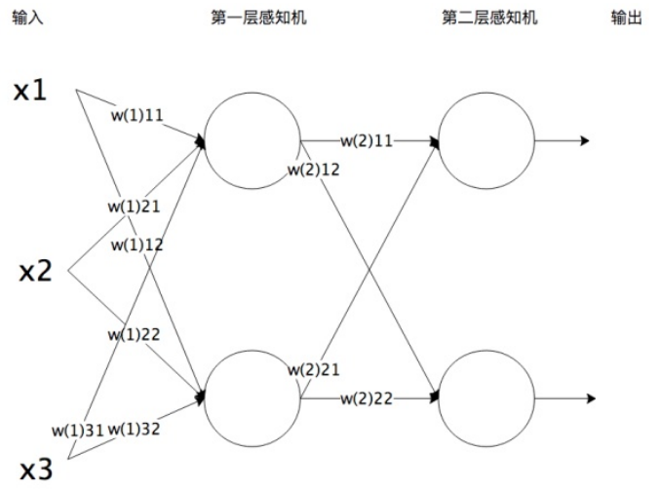
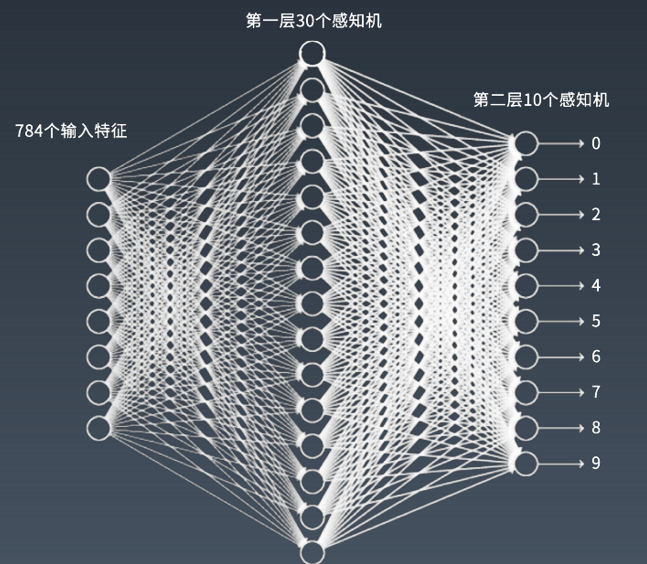
-神经网络在手写数字识别中的应用:


还未添加个人签名 2020.05.04 加入
还未添加个人简介










评论