第十二周学习总结
第一题
(至少完成一个)
在你所在的公司(行业、领域),正在用大数据处理哪些业务?可以用大数据实现哪些价值?
分析如下 HiveQL,生成的 MapReduce 执行程序,map 函数输入是什么?输出是什么,reduce 函数输入是什么?输出是什么
我们还真用到了大数据,公司有一个大数据平台名叫 dataone,公司的产品叫苍穹,前端同学在苍穹代码里面做埋点,然后传输数据到 dataone 平台里面,实时传输,然后后端我们这边用 hive 来聚合分组,分析用户行为:项目名称叫产品运营分析。主要分析内容为:产品应用、用户、服务提单、用户行为分析。所有的都是基于用户的行为,然后实时传输过来,然后离线分析。
用户分析
用户登录
用户使用设备
各产品使用情况
客户分析
客户环境
服务、运维
服务提单
产品分析
应用评价
价值:为公司决策、产品方向、用户使用情况提供数据支撑,公司才开始做,也不知道这些数据到底能干啥,领导的意思,先收集,先有量,在考虑后续使用。后面可以详细整理一下,作为小组分享内容。
第二题
分析如下 HiveQL,生成的 MapReduce 执行程序,map 函数输入是什么,输出是什么?reduce 函数输入是什么,输出是什么?
Page_view 表和 user 表结构与数据示例如下:
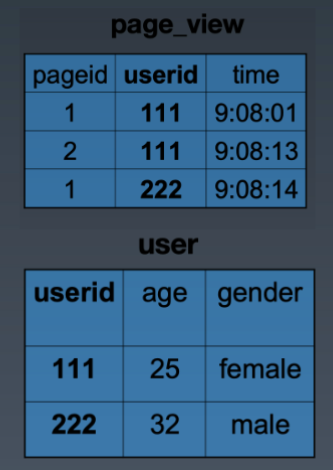
page_view & user
Map 函数
首先,我们看到该题中 page_view & user 两表的 JOIN 操作是通过 userid 关联的,所以 Map 操作必然是以 userid 为 key 值输出:
page_view 表

page_view 表关联的 Map 函数:
map(key: Offset, value: LineOfPageView, ...)key 是 value 所在行的偏移量,一般可以不管
value 是 page_view 表中某一行的文本内容,这里可以通过分词器提取出
pageid和userid等信息
map 函数输出格式:{key: UserId, value: <TableId, PageId>}
key 就是 userid 的值
value 是一个键值对,键是表编号(我这里用
pv缩写示意一下),值就是 pageid
输出如下所示:
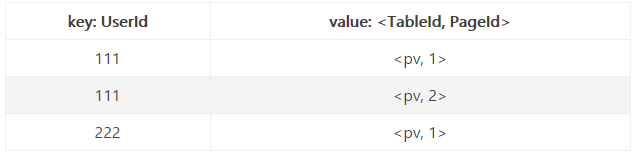
user 表

该表关联的 Map 函数是map(key: Offset, value: LineOfUser, ...),几乎和上表一样:
key 是偏移量
value 是表中某一行的文本内容,通过分词器可以提取出
userid和age等信息
map 函数输出格式:{key: UserId, value: <TableId, Age>}
key 就是 userid
value 也是一个键值对,键也是表编号(用
u缩写示意),值就是 age
输出如下所示:

Shuffle
Shuffle 会将上述 Map 输出结构按 Key 值(userid)排序以及合并,会生成如下两张表的内容再交给不同的 Reduce 服务计算:
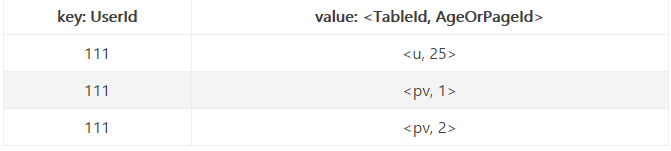
和

Reduce 函数
输入就是上面 Shuffle 的输出:
reduce(Key: UserId, values: <TableId, AgeOrPageId>[], ...)
key 就是 UserId
values 是一系列键值对(
<u, age>或是<pv, pageid>)的数组
输出
先利用不同的表编号(pv或u),从 values 中过滤出 ages 和 pageIds 两个数组;然后对 ages 和 pageId 这两个数组做 combination 操作(两 for 循环),得到所有的<pageid, age>键值对的列表,这个列表就是 Reduce 的输出。最后输出结果如下:
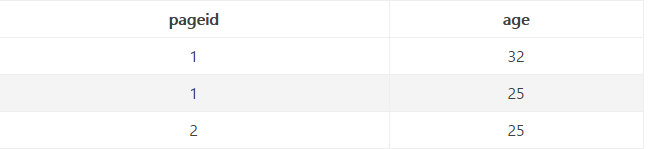
PS:不懂 MapReduce 过程,百度的。。。

还未添加个人签名 2018.07.18 加入
还未添加个人简介









评论