深度解读:Apache DolphinScheduler 新架构与特性,性能提升 2~3 倍

引言
大数据任务调度作为大数据建设中的核心基础设施,在经过社区用户们长期的使用中,不少用户对调度也提出了很多新的要求,为此,Apache DolphinScheduler(Incubating)经过长达 5 个多月的辛苦努力, 终于发布了 1.3.2 正式版本。DolphinScheduler-1.3.2 有超过 30 名贡献者参与开发,性能较 1.2 版本有 2 ~ 3 倍的提升,相对 1.2 版本,1.3.x 增加了诸如 K8s支持、多目录管理等重要的新特性和新的任务类型。1.3.x 重要的改动如下:
架构升级:重构 worker server
移除基于 ZooKeeper 的任务队列
引入 Netty 进行 master 和 worker 间的通信
提供了三种 master 分发任务的算法:随机,轮询和资源线性加权
Worker 不再操作数据库,减轻数据库压力
新增任务类型
数据同步节点:新增了 DataX 和 Sqoop 节点,加强 DolphinScheduler 构建全流程ETL 工作流的能力
条件分支节点:提供了多个上游任务结果的复杂逻辑判断能力,根据用户自定义逻辑进行分支流转
易用性提升
资源中心支持目录管理:资源中心支持目录类型,用户可以分项目或模块进行资源文件管理
支持 Ambari 插件:支持使用 Ambari 进行 DolphinScheduler 的集群部署和管理
支持 K8s:DolphinScheduler 支持 K8s 部署。为了支持 k8s,worker 分组数据不再存储在 mysql,而通过配置文件中指定 worker 标签的方式,存储在 ZooKeeper 中
简化配置文件:分离 install.sh 中的参数配置和集群部署配置,install.sh 仅进行集群部署,集群参数配置文件抽取到 conf/config/install_config.conf 中
工作流布局优化:提供一键美化工作流布局功能
其他特性(部分)
增加工作流复制功能
删除任务实例级联删除对应的任务实例日志
1.3.x 新特性解读
1、重构 Worker
DolphinScheduler 1.2 的整体架构
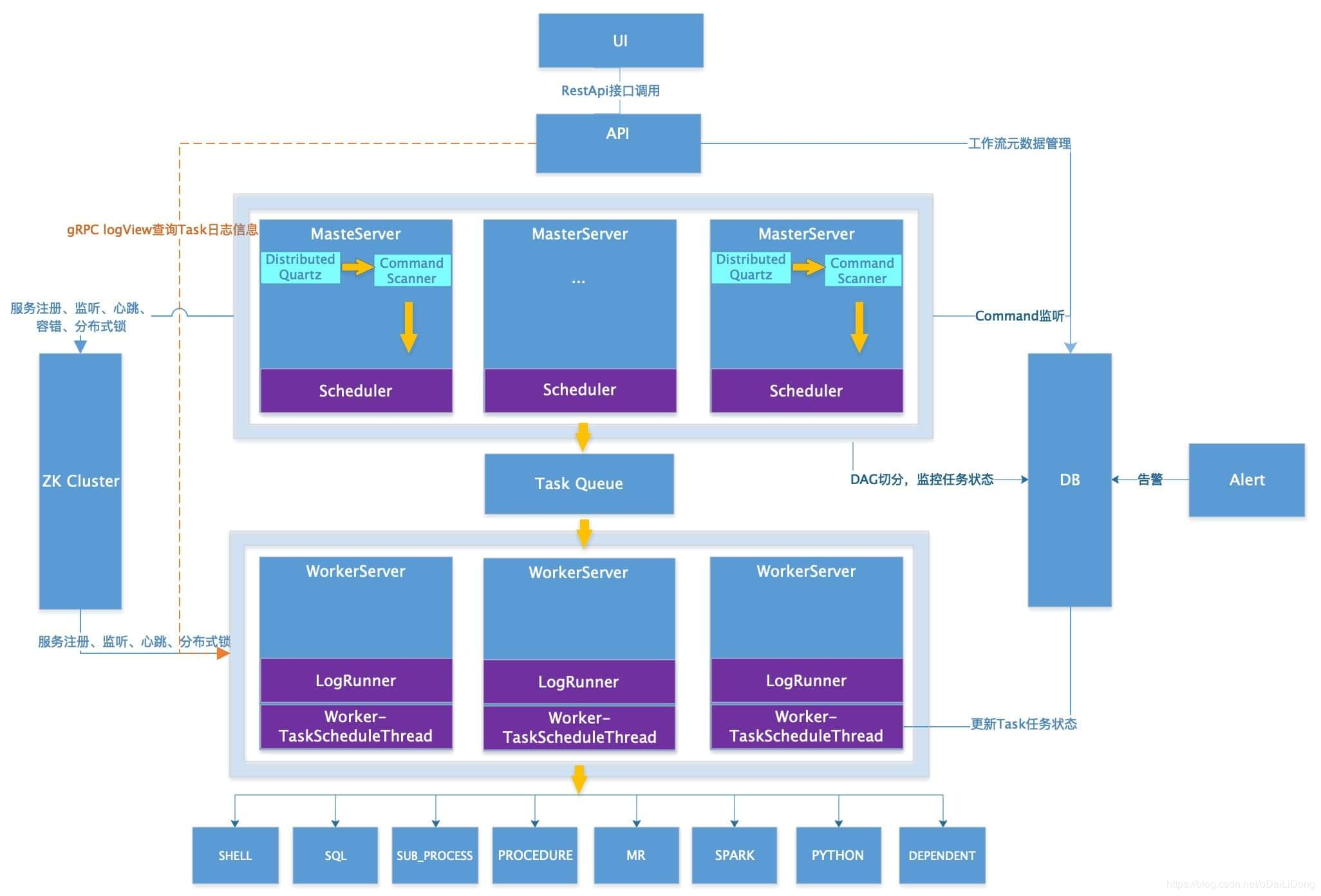
在 DolphinScheduler 1.2 中,master 和 worker 的职责分别如下:
master
master 采用分布式无中心设计理念,master 主要负责 DAG 任务切分、任务提交监控,并同时监听其它master 和 worker 的健康状态。
master 服务启动时向 Zookeeper 注册临时节点,通过监听 Zookeeper 临时节点变化来进行容错处理。
该服务内主要包含:
Distributed Quartz 分布式调度组件,主要负责定时任务的启停操作,当 quartz 调起任务后,Master内部会有线程池具体负责处理任务的后续操作
MasterSchedulerThread 是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作
MasterExecThread 主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理
MasterTaskExecThread 主要负责任务的持久化
worker
worker 也采用分布式无中心设计理念,worker 主要负责任务的执行和提供日志服务。worker 服务启动时向 Zookeeper 注册临时节点,并维持心跳。
该服务包含:
FetchTaskThread 主要负责不断从 Task Queue 中领取任务,并根据不同任务类型调用TaskScheduleThread 对应执行器。
LoggerServer 是一个 RPC 服务,提供日志分片查看、刷新和下载等功能
在 1.2 版本实现的架构中,任务队列的实现基于 ZooKeeper。master 将任务数据存放到 ZooKeeper 中,然后 worker 节点通过分布式锁的方式去消费任务队列,延迟了任务开始执行的时间。为保证任务队列的性能,ZooKeeper 的节点中并未存储执行任务所需的全部数据。许多任务的元数据如租户,队列和任务实例信息等都需要由 worker 操作数据库进行获取,增加了数据库的负担。所以在 1.3 的架构设计中,我们着重考虑到减少 worker 的压力,设计了如下新架构
DolphinScheduler 1.3 新架构
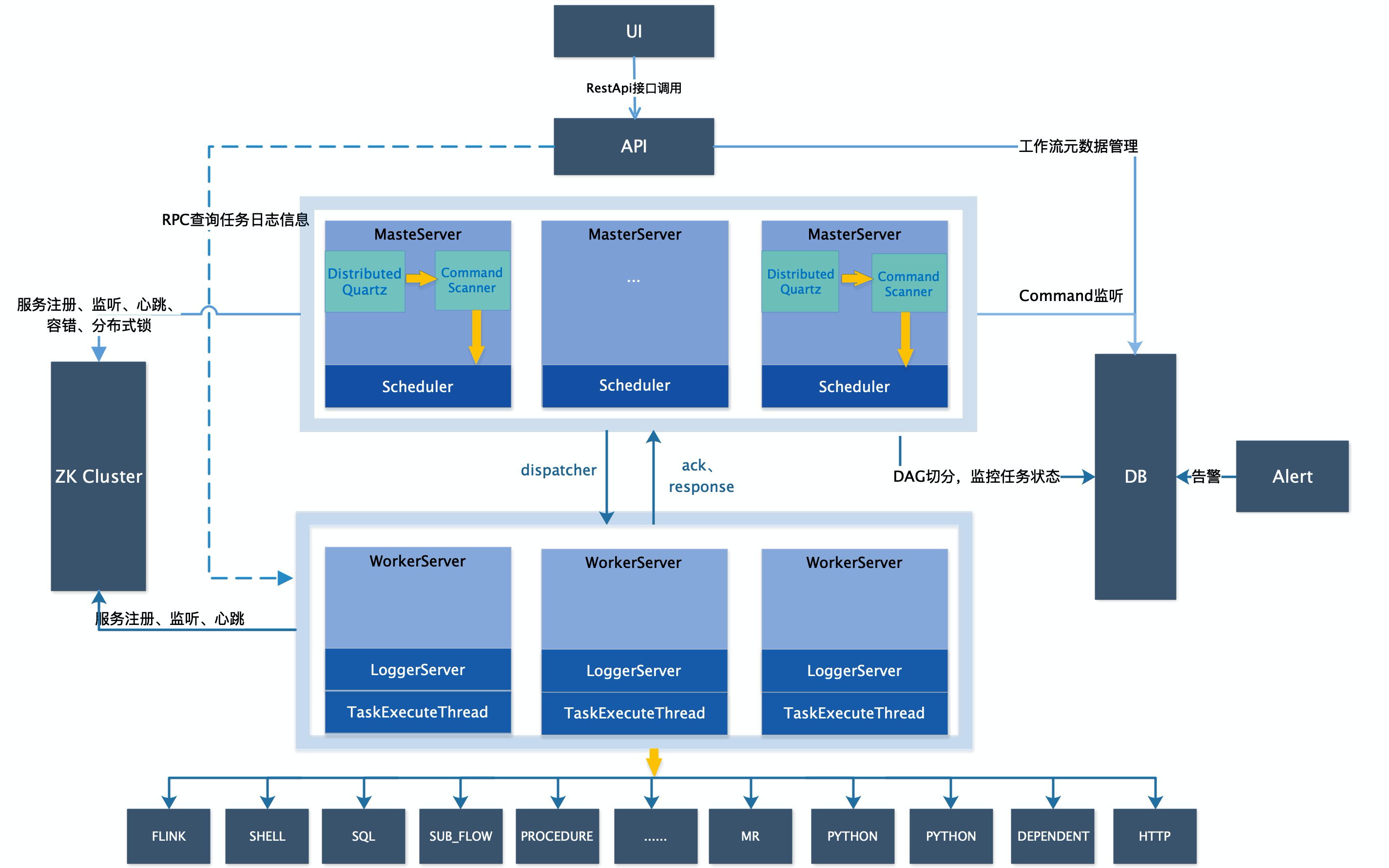
在 DolphinScheduler 1.3 中,任务队列基于 Netty 实现,master 保留了原有的逻辑,当 master 节点切分出任务节点后,使用配置的任务分发策略直接发送目标 worker 节点进行执行。worker 节点在启动的时候将节点信息和分组信息注册到 ZooKeeper 中,供 master 节点进行调用。性能优化的核心是去除了 worker节点的 ZooKeeper 操作和数据库操作。1.3 的架构分层详细图如下:
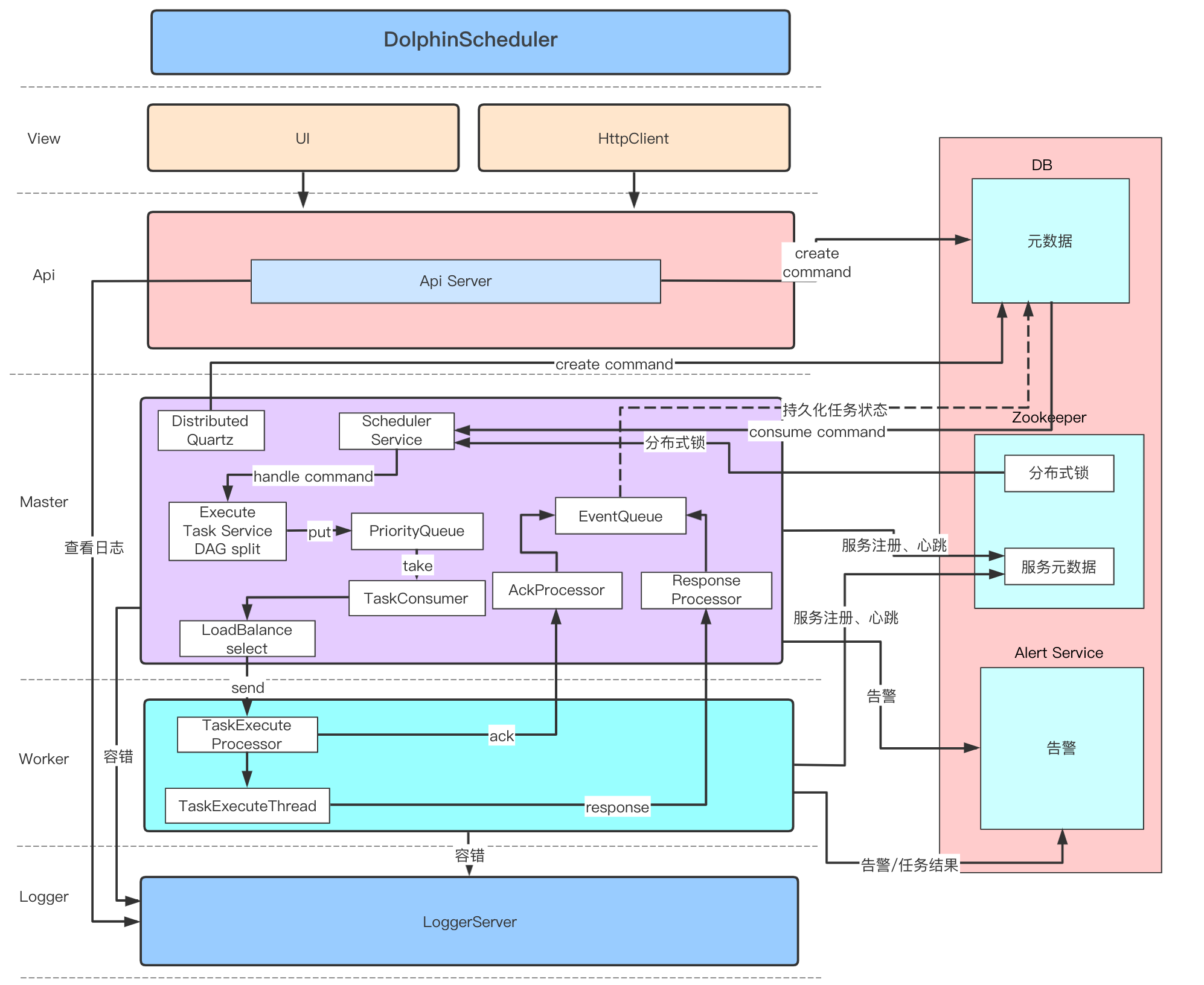
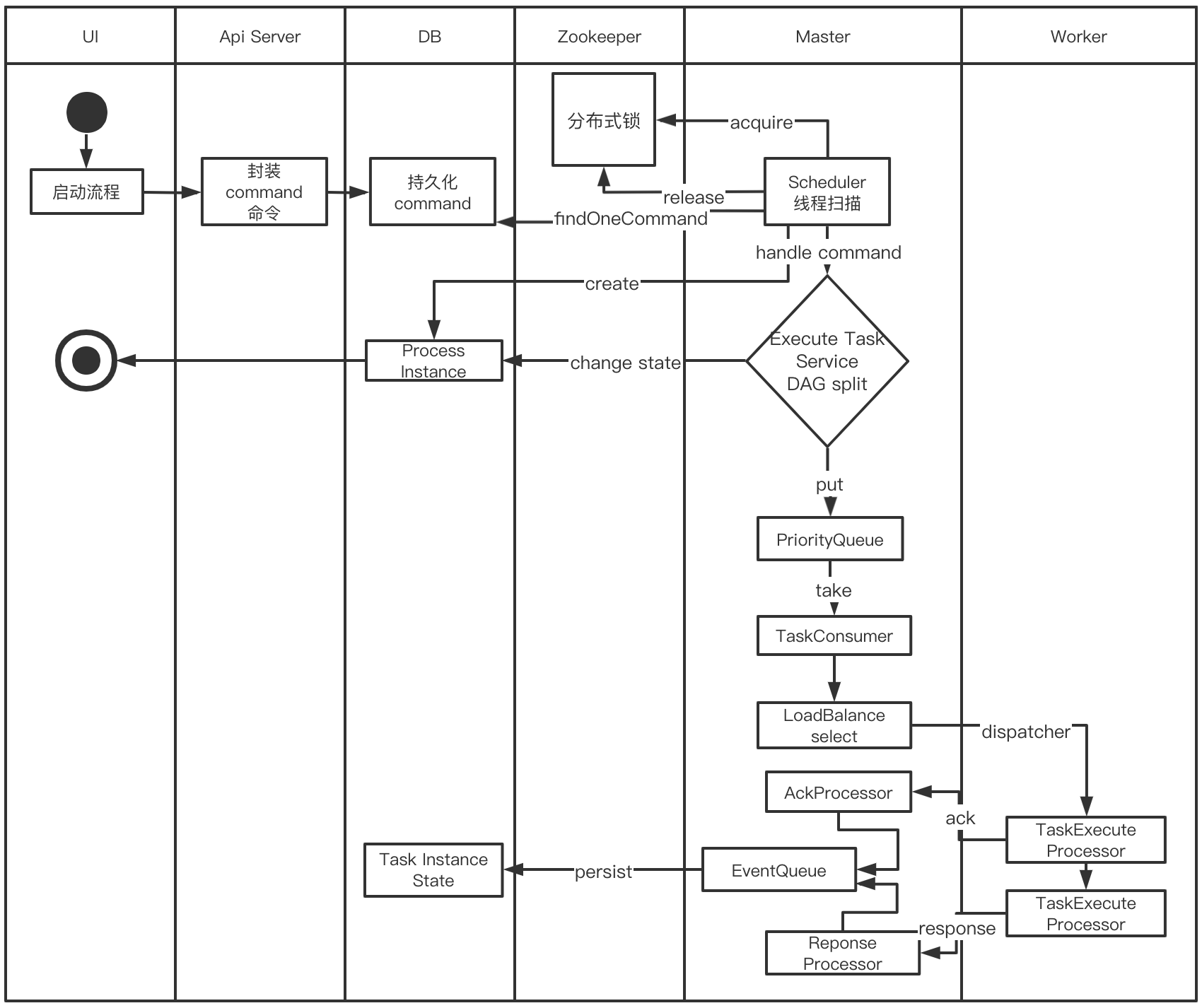
1.3 整个系统运作过程的活动图如下:
更多详细信息参见 issue:https://github.com/apache/incubator-dolphinscheduler/issues/1658
2、新增任务类型
数据同步节点
DolphinScheduler 作为一个数据处理调度系统支持了多种 ETL 功能节点,如 SQL 节点,存储过程节点和 Spark 节点等。在整个 ETL 流程中,多源异构数据的集成是基础。因此,在1.3.1版本中DolphinScheduler 集成了成熟的数据交换引擎 DataX 和 Sqoop 以支持多源异构数据源间的传输交换。目前,DolphinScheduler 已打通整个数据摄取-数据处理-数据结果同步的 ETL 流程。使用数据同步节点,可以避免在shell脚本中直接配置数据源的连接信息,所有的数据源权限均受 DolphinScheduler 管控。
DataX 节点
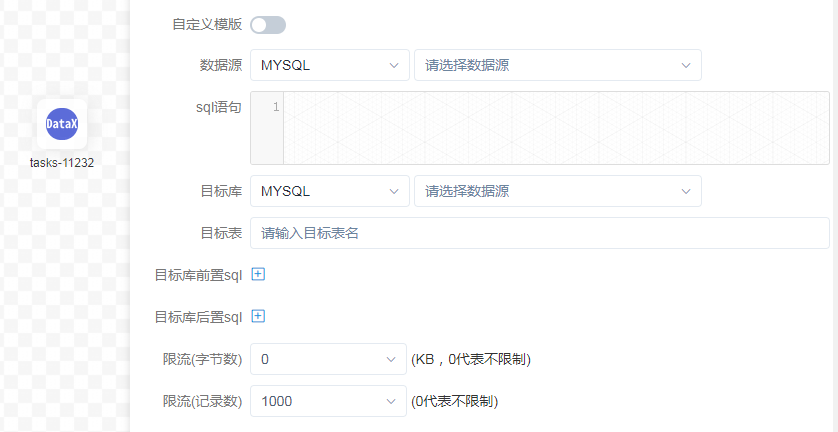
Sqoop节点
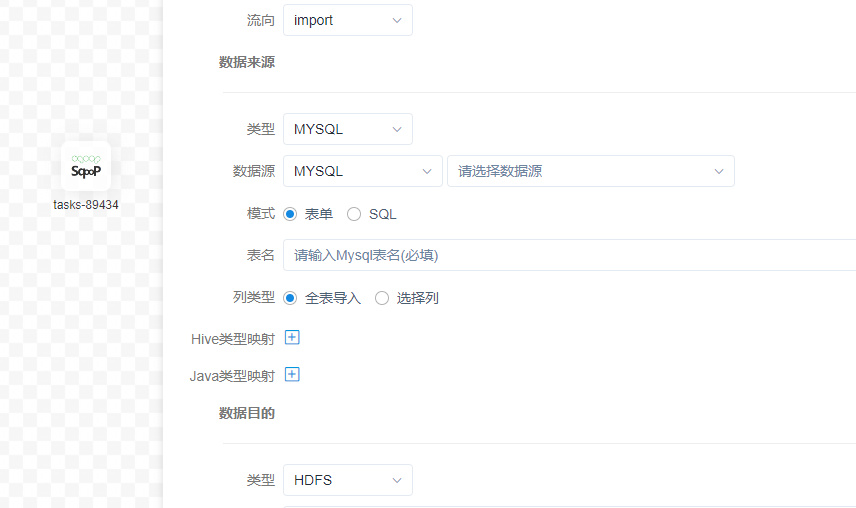
条件分支节点
Dolphin Scheduler 1.3.1 支持条件分支节点,用户可以在自定义参数中定义分支流转的判断逻辑,根据上游任务的执行情况,决定后续执行的分支。
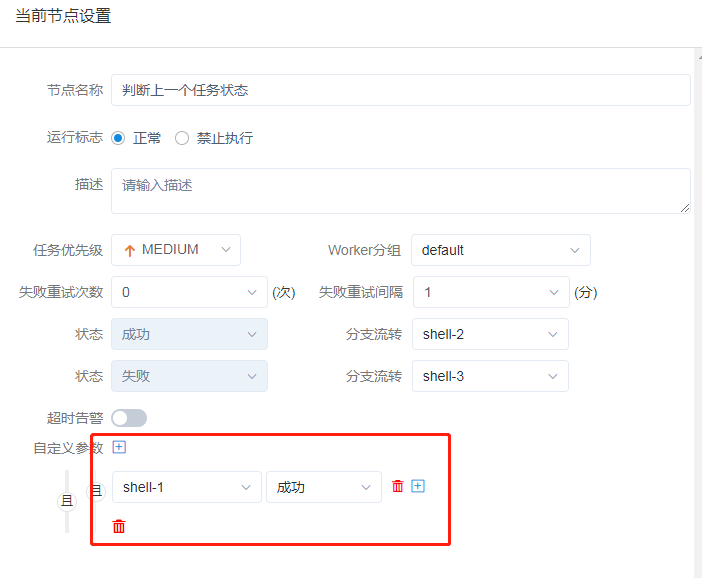
注意,条件节点是一种逻辑判断任务,不会分发到 worker 去执行,是在 master 上执行的一个逻辑节点。
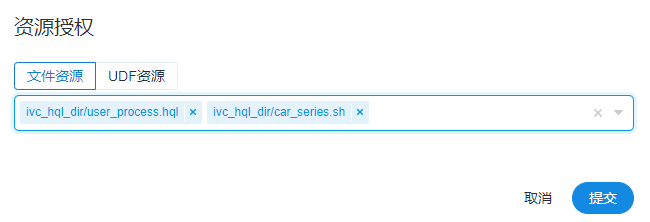
3、资源中心支持目录结构
DolphinScheduler 1.3.1 支持了资源中心目录化和授权资源使用目录树的功能,极大的改善了资源文件的使用体验。资源中心目录化使得分项目管理资源文件成为可能而不是将租户的所有资源文件都放在一个目录下。资源中心支持授权整个目录给用户,提高了多文件授权的操作效率。使用目录树的方式进行资源文件授权,可以避免 1.2 版本一个一个寻找资源文件的耗时操作。
4、支持 Ambari 插件
Ambari 插件可以让 DolphinScheduler 和 Ambari 轻松集成,利用 Ambari 的能力可以使部署和管理 DolphinScheduler 更加简单,也更容易扩/缩容,
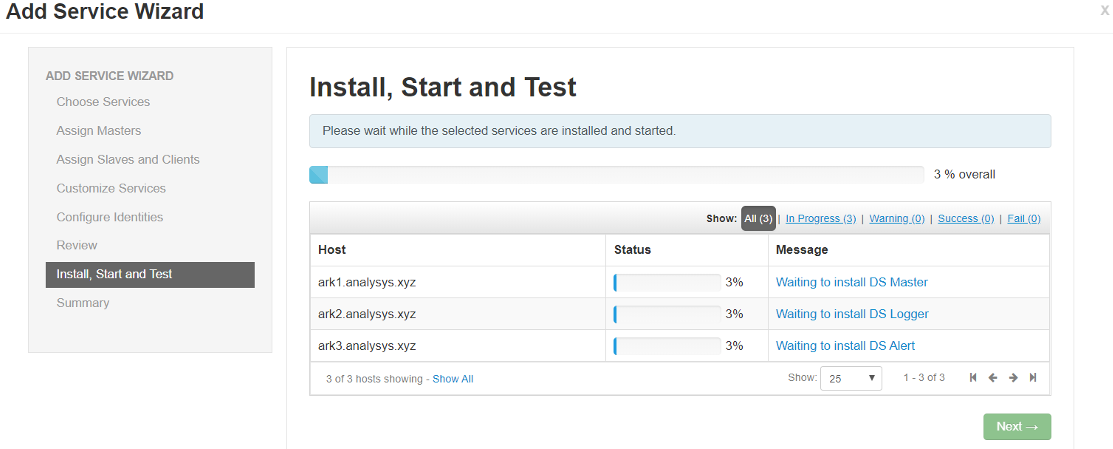
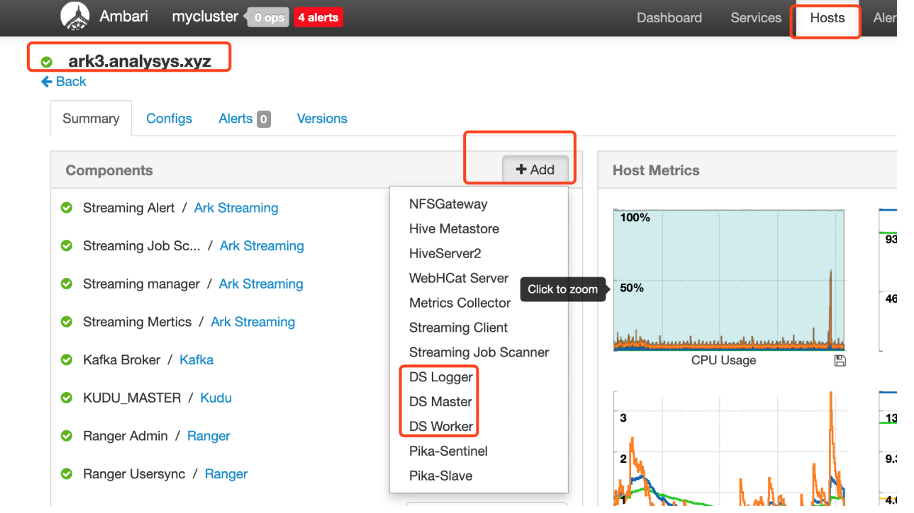
5、支持 K8s
1.3.1 也提供了对 K8s 的支持,后续也会推出 DolphinScheduler 的 Docker 官方镜像,更方便大家部署 DolphinScheduler,这块的详细文档请参考:[ K8s Readme ](https://github.com/apache/incubator-dolphinscheduler/blob/1.3.1-release/docker/kubernetes/dolphinscheduler/README.md)
6、其他一些重要的特性:
批量导出和导入工作流
流程定义复制
删除流程实例级联删除任务日志
DAG 图一键格式化,非常适合通过 open API 调用的场景
流程图美化
简化配置,优化部署体验
完善自动化 CI、CD
1.3.2 版本带来的新特性
新特性:
Worker Server 可以设置多个 worker groups
JVM 参数优化
给流程图连线添加标签
值得注意的是 1.3.2 版本修复了 1.3.1 的 20 多个 bug ,其中需要关注的是
[#3058] The task running order in the process instance does not follow the topological order in the process definition
该 bug 是在打开任务节点,没有正常关闭窗口,然后又新建一个流程定义导致新建的流程定义的前置节点的信息丢失。这可能造成 1.3.1 版本的流程图运行错乱的问题
此外,1.3.2 也带来了 4 项功能改进和增强,具体变化请参考:
https://github.com/apache/incubator-dolphinscheduler/releases/tag/1.3.2
Apache DolphinScheduler社区介绍
Apache DolphinScheduler 是一个非常多样化的社区,至今贡献者已120多名, 他们分别来自 30 多家不同的公司。 微信群用户3000人。
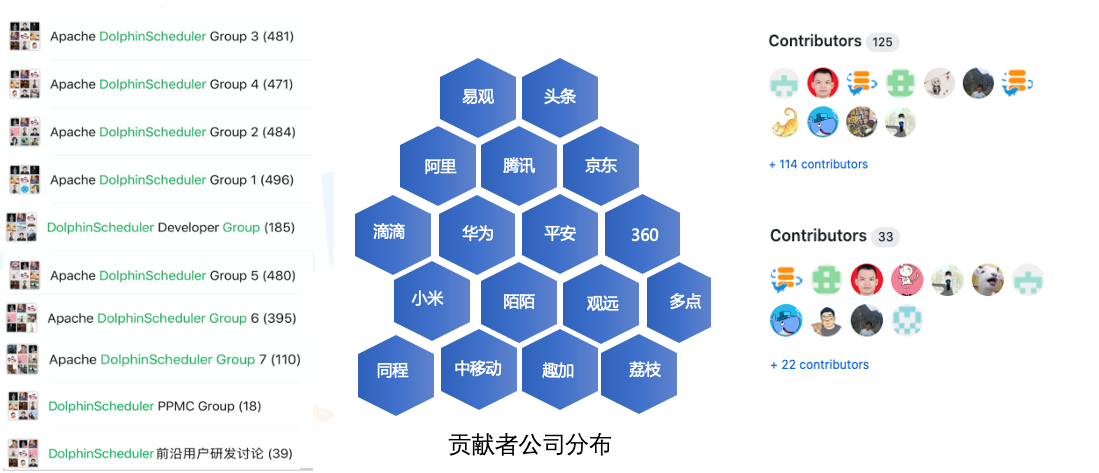
部分用户案例(排名不分先后)
已经有近 400 多家企业和科研机构在使用 DolphinScheduler,来处理各类调度和定时任务,另有 800 多家公司开通了海豚调度的试用:

Apache DolphinScheduler 能力
以DAG图的方式将Task按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
支持丰富的任务类型:Shell、MR、Spark、Flink、SQL(mysql、postgresql、hive、sparksql)、Python、Http、Sub_Process、Procedure等
支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill任务等操作
支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败
支持工作流全局参数及节点自定义参数设置
支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑
支持任务日志在线查看及滚动、在线下载日志等
实现集群HA,通过Zookeeper实现Master集群和Worker集群去中心化
支持对
Master/Workercpu load,memory,cpu在线查看支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计
支持补数
支持多租户
支持国际化
加入 Apache DolphinScheduler
在使用 DolphinScheduler 的过程中,如果您有任何问题或者想法、建议,都可以通过Apache 邮件列表或者github issue参与到 DolphinScheduler 的社区建设中来。
欢迎加入贡献的队伍,加入开源社区从提交第一个 PR开始,
- 找到带有”easy to fix”标记或者一些非常简单的issue(比如拼写错误等),先通过第一个PR熟悉提交流程,如果有任何疑问,欢迎联系
邮件订阅方式:
https://dolphinscheduler.apache.org/zh-cn/docs/development/subscribe.html
github:
https://github.com/apache/incubator-dolphinscheduler
官方网站
https://dolphinscheduler.apache.org/en-us/
欢迎下载试用,在试用过程中发现任何问题,可以通过邮件列表或 github 上新建 issue 进行反馈!
版权声明: 本文为 InfoQ 作者【海豚调度】的原创文章。
原文链接:【http://xie.infoq.cn/article/da4c73d68a8ac94ea5cf85c0e】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

Apache DolphinScheduler 2017.12.12 加入
Apache DolphinScheduler(incubator) - 大数据任务调度系统,主要解决大数据处理中错综复杂的依赖关系,直观监控任务健康状态等问题。4000人用户社区,已有IBM、腾讯、美团、360等400多家公司使用,欢迎大家对比哈









评论