

使用 PCA 进行降维可视化,了解特征分布
降维是数据挖掘流程中,一种对高维度特征数据预处理方法。降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以节省大量的时间成本。降维也成为应用非常广泛的数据预处理方法。另外,除了让算法运行更快,效果更好。降维还有一种场景,就是将数据可视化,根据数据分布情况进而选择合适算法。
降维算法主要有:主成分分析(PCA)、奇异值分解(SVD)、因子分析(FA)、独立成分分析(ICA)。本篇文章主要介绍利用 PCA 进行可视化。
在 sklearn 库,PCA 在 sklearn.decomposition.PCA 类:
class sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver=’auto’, tol=0.0,iterated_power=’auto’, random_state=None)
如果只是对数据进行可视化,其他参数可以忽略,按照默认参数值即可,主要调整 n_components 参数。 n_components 是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中需要确认的 k 值,一般输入[0, min(X.shape)]范围中的整数。这是一个需要我们人为设定的参数,数字设定会影响到模型表现。如果留下的特征太多,就达不到降维效果,如果留下特征太少,那新特征向量可能无法容纳原始数据集中的大部分信息。但是,在进行数据可视化观察数据分布时。因为数据往往都是二维状态,即 n_components 取值为 2。
案例说明
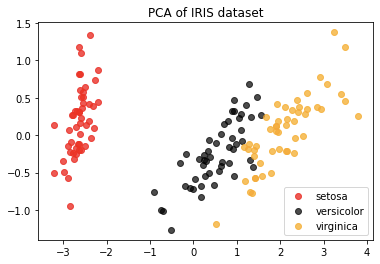
如图,降维后进行可视化,可以清楚看到鸢尾花数据集 3 种类型分布,观察分布可以得知,鸢尾花数据集使用聚类算法,应该会取得比较好的效果。
版权声明: 本文为 InfoQ 作者【黄大路】的原创文章。
原文链接:【http://xie.infoq.cn/article/d9caf8c63e1b2cd8a46bc7f01】。文章转载请联系作者。

公众号:Python面面观 2019.07.27 加入
标签:产品经理、数据挖掘










评论