架构师训练营第 1 期 -week9
问题 1
请简述 JVM 垃圾回收原理
垃圾回收就是清除 JVM 堆内不再被引用的对象
垃圾判定
可达性分析
从 GC Roots 对象出发一路向下遍历,将遍历到的对象标记为可达,其他对象即不可达。
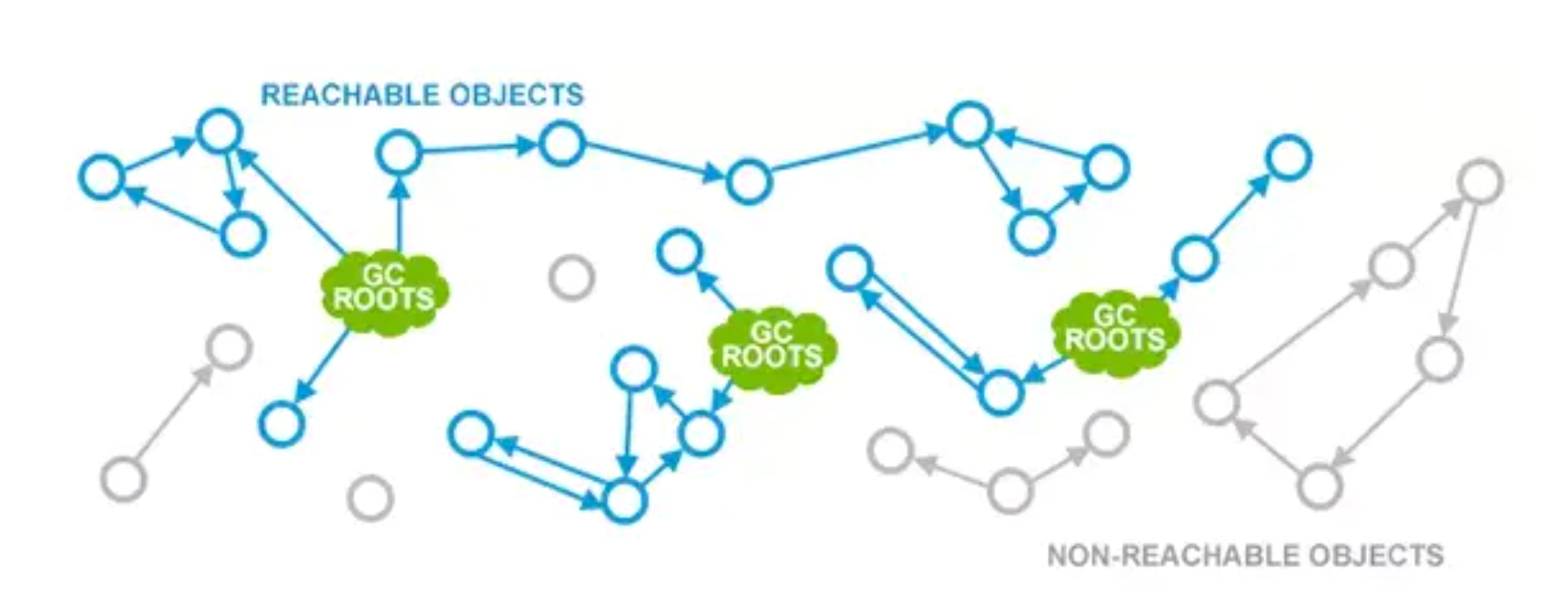
GC Roots包括:
所有的 Thread 对象
栈帧中的局部变量表
⽅法区中的静态成员
JNI 持有的引⽤
Monitor : 用于同步的监控对象
其他 JVM 持有的 GC Roots:用于 JVM 特殊目的由 GC 保留的对象,但实际上这个与 JVM 的实现是有关的。可能已知的一些类型是:系统类加载器、一些 JVM 知道的重要的异常类、一些用于处理异常的预分配对象以及一些自定义的类加载器等。
对象的死亡判定
不可达的对象进⼊死亡队列 ,垃圾回收器可能回调⽤其 fifinalize⽅法⼀次, ⽣存或者死亡
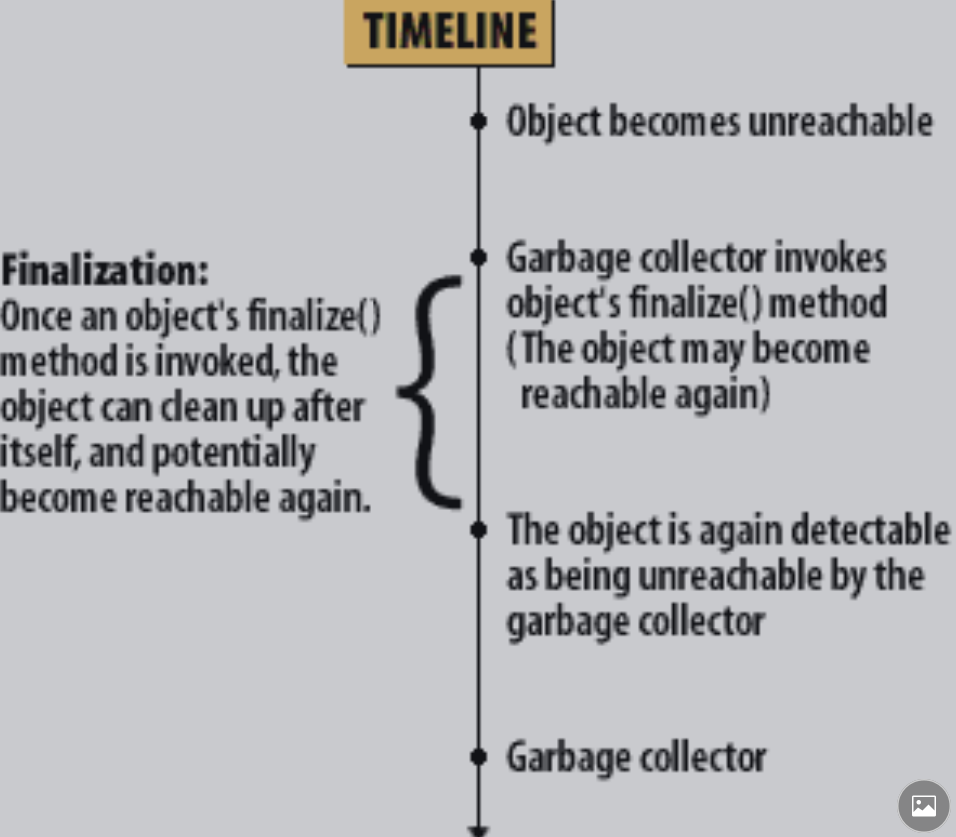
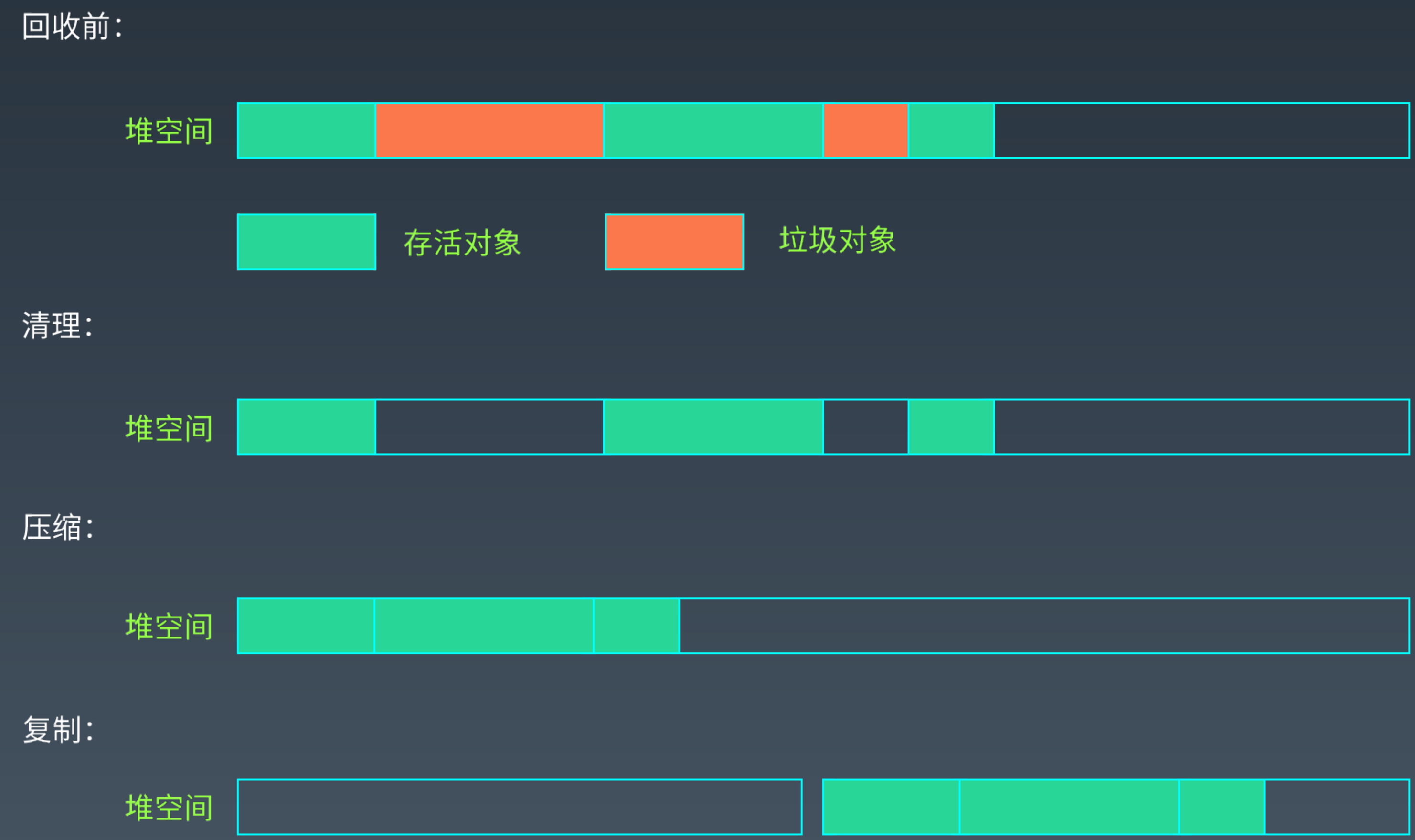
回收的方法有三种,清理,压缩和复制。
清理:将垃圾对象占用的内存空间标记为空闲,并记录在一个空闲列表中,有内存申请需要时,才会把这些空间分配出去。
压缩:从堆内存的头部开始,将存活的对象拷贝到一段连续的内存中,那么剩下的空间就是可用的了,并且是连续的。
复制:将堆空间分为两部分,只在其中一部分中创建的对象,当这部分空间用完时,将标记的对象复制到另一个空间中,这样这个空间的内存就是可用的了。
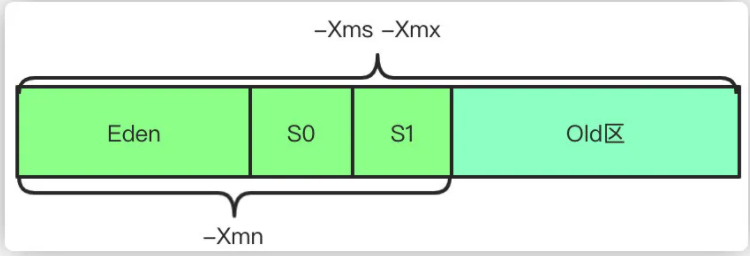
*JVM 分代垃圾回收 *
堆内存的空间分配如下
GC 的分代假设
GC 理论中有一个重要的思想,叫做分代。 研究表明,绝大多数对象都是朝生夕死的。程序中分配的对象,要么用过就扔,要么就能存活很久很久。
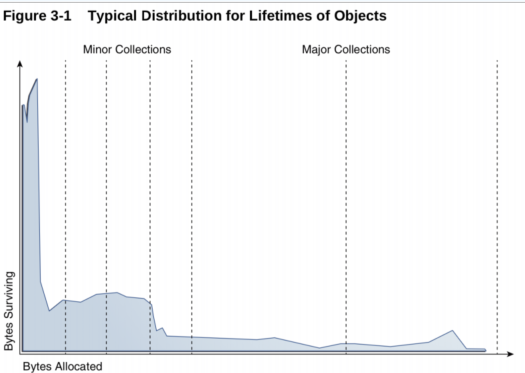
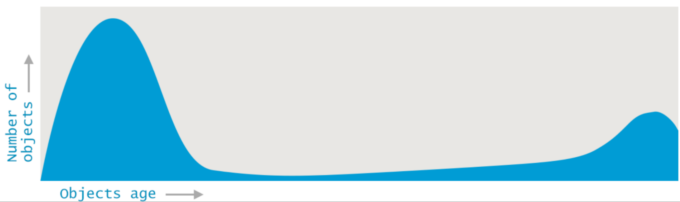
也就是说,将堆按照对象生命周期的长短分代有利于 GC 效率。因此,JVM 将 Heap 内存分为年轻代(Young generation)和老年代(Old generation, 也叫 Tenured)两部分。
年轻代还划分为 3 个内存池,新生代 (Eden space) 和存活区 (Survivor space), 在大部分 GC 算法中有 2 个存活(Survivor)区 (S0, S1),在我们可以观察到的任何时刻,S0 和 S1 总有一个是空的,但一般较小,也不浪费多少空间。
为什么要有 Survivor 区?
如果没有 Survivor,Eden 区每进行一次 Minor GC,存活的对象就会被送到老年代。老年代很快被填满,触发 Major GC(因为 Major GC 一般伴随着 Minor GC,也可以看做触发了 Full GC)。老年代的内存空间远大于新生代,进行一次 Full GC 消耗的时间比 Minor GC 长得多。
Survivor 的存在意义,就是减少被送到老年代的对象,进而减少 Full GC 的发生。Survivor 的预筛选保证,只有经历 16 次 Minor GC 还能在新生代中存活的对象,才会被送到老年代。
为什么要设置两个 Survivor 区
设置两个 Survivor 区最大的好处就是解决了碎片化,下面我们来分析一下。
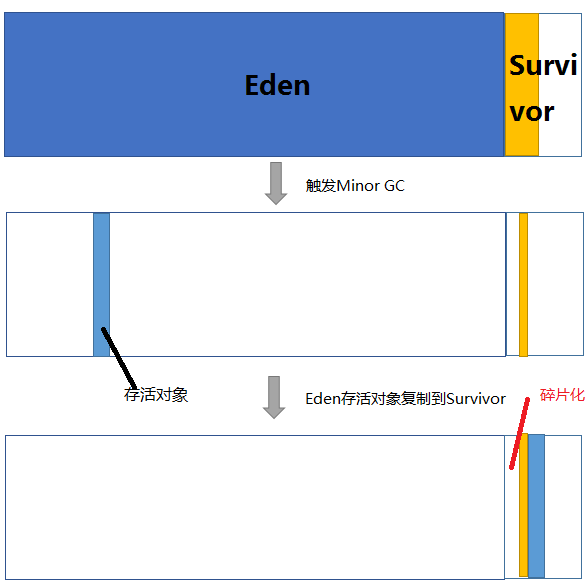
为什么一个 Survivor 区不行?前面知道了必须设置 Survivor 区。假设现在只有一个 survivor 区,我们来模拟一下流程:
- 刚刚新建的对象在 Eden 中,一旦 Eden 满了,触发一次 Minor GC,Eden 中的存活对象就会被移动到 Survivor 区。
- 这样继续循环下去,下一次 Eden 满了的时候,问题来了,此时进行 Minor GC,Eden 和 Survivor 各有一些存活对象,如果此时把 Eden 区的存活对象硬放到 Survivor 区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
下图中色块代表对象,白色框分别代表 Eden 区(大)和 Survivor 区(小)。Eden 区理所当然大一些,否则新建对象很快就导致 Eden 区满,进而触发 Minor GC,有悖于初衷。
为什么一个 Survivor 区使用压缩方式解决碎片化不行呢?
对比两个 Survivor 区使用的复制算法,也就是说为什么要用复制算法而不用标记 - 整理算法呢?其实这是空间换时间
标记 - 整理:首先需要标记,然后还要将对象进行移动,这是效率比较低的。
复制算法不需要标记,遍历一次就可以直接完成复制。
标记 - 整理实际上和复制算法一样也是进行了对象的复制,只不过前者是将对象都复制到一个区域的集中一端,而复制算法是将对象复制到另一半等大区域。但是标记 - 整理还多了一次标记的操作,显然效率比复制算法低。
经过上面的分析,显然复制算法是最好的一种选择。但 jvm 的设计者显然不会像传统的那样将 eden 和 survivor 分成两个同等大小的区间,这样无疑浪费了很多空间,所以才会出现 8:1:1 的这种设计,from 和 to 就是复制算法中那两个等大的空间,不得不说这种设计是十分巧妙的,很有效率地实现了新生代的垃圾回收工作。
GC 过程
在 Eden 区中申请空间创建对象
Eden 满了以后,遍历 Eden 区判断哪些对象可回收,启动 young GC
将标记的对象拷贝到 from 区,Eden 区变空
一段时间后 Eden 区满,将 Eden 区和 From 区的标记对象拷贝到 To 区,From 区和 Eden 区变空
再一段时间后 Eden 区满,将 Eden 去和 To 区的标记对象拷贝到 From 区,To 区和 Eden 去变空
多次拷贝后仍被标记的对象,就会被拷贝到老年代
垃圾回收器的算法
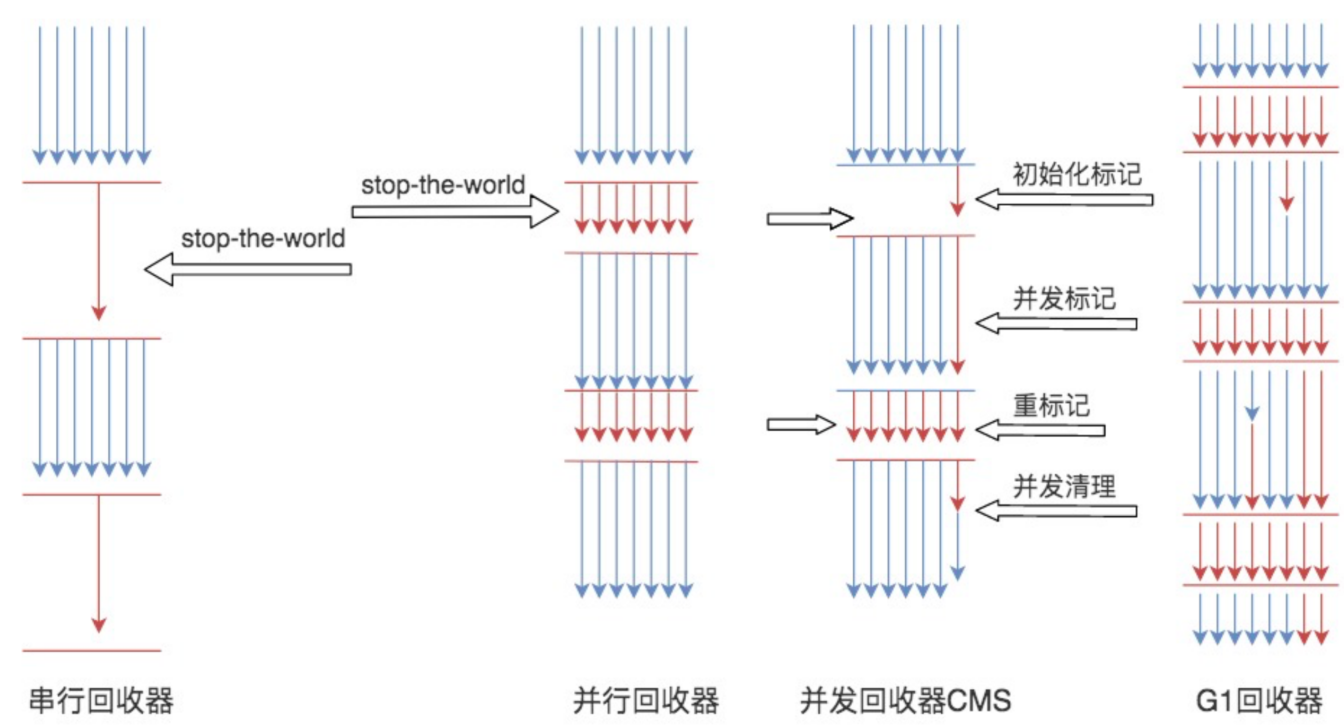
串行回收器:单独启动一个线程专门用于垃圾回收,当 GC 时所有线程都停止工作『stop the world』,等待这个线程的 GC 完成
并行回收器:并行是指可以启动多个线程进行垃圾回收;当 GC 发生时,仍然会『stop the world』,但可以根据 cpu 核心数,启动多个线程进行 GC,效率更高。
并发垃圾标记清理(CMS):并发是指 GC 线程和业务线程可以同时工作,同时也就意味着可能会出现重标记,重标记期间还是会发生『stop the world』,比并行回收器,对业务线程影响较小,但更耗资源。
G1 回收器:jdk1.7 高版本开始引入 G1,是目前比较高效的算法
问题 2
设计一个秒杀系统,主要的挑战和问题有哪些?核心的架构方案或者思路有哪些?
主要问题
高并发
超卖
恶意请求
链接暴露
解决方案
独立部署
给秒杀系统部署一个单独的服务,至少保证秒杀系统挂了,站点的其他服务依旧可行
扩容
就是加机器了。购置机器来不及时将非核心应用集群的冗余服务器下线,加入到秒杀集群。
业务简化
梳理业务链路,尽量简化步骤。比如填写下单地址就可以秒杀峰值完毕后进行。
静态化资源
前后端分离,页面尽可能的静态化,减少动态数据请求。把能静态的资源 ——html、js、css、img 等等 —— 全部放到 CDN 上。
加盐:
通俗来说就是秒杀请求的 URL 必需带一个加密的参数,比如添加一个动态生成的 token,经后端校验请求才能通过。这个主要是防止事先暴露 URL。
限流
前端限流:按钮在秒杀开始前必须是 disabled 的,开始后每次点按钮要隔两秒才能再点,或是秒杀开始三秒后的点击全部导航到其他页面
后端限流:加个计数器,比如卖 100 个产品,10000 后的请求都 return false,后端直接关闭无效请求。
应急预案
- 壁虎断尾策略
所有办法均失效的情况下,例如流量耗尽。
- 非核心应用集群统统停止服务,如资讯,论坛,博客等社区系统。
- 保住首页,Offer Detail,旺铺页面等核心应用的可用性
- 万能出错页面:秒杀活动已经结束
- 任何出错都 302 跳转到此页面
- 位于另外集群

还未添加个人签名 2018.08.08 加入
还未添加个人简介









评论