关于编码

字符集
ASCII
ASCII 码是美国定义的字符编码,包含26个大小写中英文字符、10个阿拉伯数字、33个英文标点符号和33个不可见字符,共128个字符。例如常见的 48 ~ 57 分别表示 0 ~ 9 ,65 ~ 90 分别表示 A ~ Z ,97 ~ 122 分别表示 a ~ z 等等
为什么是128?因为一个字节占8位,从左至右,第一位统一为0,后面7个位置,用二进制最多表示128(0 ~ 2^8 - 1)个字符,这些字符涵盖了英文中的所有用到的字符
如果将第一个位置也作为正常二进制使用的话,那128(2^8)到255(2^9 - 1)表示的就是欧洲国家常用的一些字符,例如é 、Ä 等等
GB2312
那对于中文而言,ASCII 和扩展的欧洲码无法满足汉字的使用,于是产生了 GB2312 字符集,采用两个字节进行编码,即两个8位字节,对几千个常用简体字进行了编码,为了满足常用繁体字,扩展出了 BIG-5。再之后 GBK 的出现,将 GB2312 和 BIG-5 容纳,仍保留两个字节进行编码的方式
ANSI
微软为了打入多个国家市场,产出了 ANSI ,仅仅实现了不同的二进制在不用的国家采用不同的编码规则,并没有统一各个国家的编码规范,所以同一篇文档,在不同格式下会出现乱码。换句话说,ANSI 仅仅是对当前文档尝试采用当前国家的编码规则进行编码而已
Unicode
为了统一各个国家的字符集,解决乱码问题,Unicode联盟 提出了 Unicode 字符集,取代现存的各个国家独有的字符集,致力于统一字符编码
UCS
而ISO(国际标准化组织)也制定了一套通用字符集,即UCS,并制定了 ISO 10646 标准
鉴于统一且通用的目的,Unicode 和 UCS 在保持独立存在和独立发布的基础上,严格保证了两个标准下的所有字符都在相同的位置和具有相同的名字,在一定意义上,保持了通用性
编码存储
以上提到的 ASCII 、GBK 、Unicode 等都是字符集,而经常被提及的 UTF-8 则是对这些字符集的存储方式,UTF 即 Unicode Transformation Format,8 代表了存储的字节位数,8个位数即1个字节,相对应的 UTF-16 和 UTF-32 则分别表示两个字节和四个字节
UTF-8 的编码存储规则如下
单字节,字节的第一位固定为0,和
ASCII码一致多字节,N 个字节时,第一个字节的前 N 位为1,第 N+1 位为0;第二个字节(包含)之后,均以
10开头,字节的其余空位,从右至左依次填写字符的二进制码,空位用 0 补齐
Unicode 和 UTF-8 的对应关系如下图
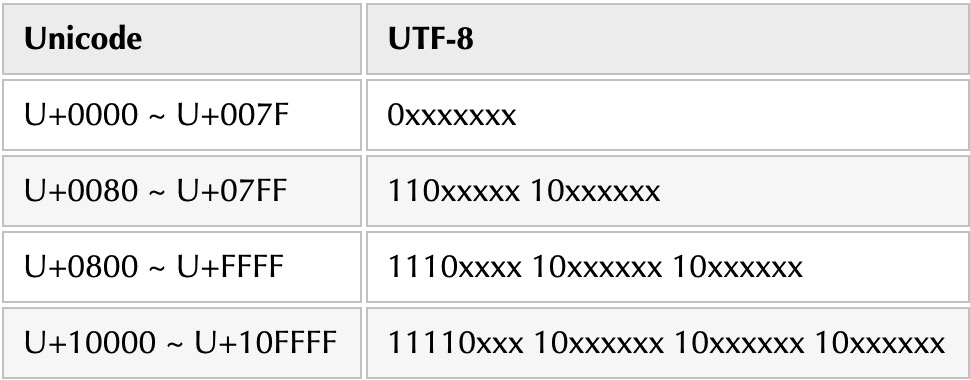
举个例子,严 的 Unicode 码为 4E25 ,转化为二进制为 100111000100101,汉字 严 的 Unicode 码在 U+0800 ~ U+FFFF 范围之内,对应的 UTF-8 属于第三层 1110xxxx 10xxxxxx 10xxxxxx ,用严 的二进制码依次从右至左的替换 x ,得到结果 11100100 10111000 10100101 ,再转换为十六进制,得到最终结论E4B8A5
转码和解码
上面 严 的例子得出的结果看上去比较陌生,那看下面的结果
是不是很熟悉呢?E4B8A5 和 %E4%B8%A5 只是用 % 做了分隔
了解了以上内容,就可以准确的进行 Unicode 和 UTF-8 的转换,同时可以校验一个 UTF-8 结果是否准确,是否符合转换规则,也解释了为什么一个汉字用三个字节的十六进制表示
参考
https://juejin.im/post/6884571798751412238
http://www.ruanyifeng.com/blog/2007/10/asciiunicodeand_utf-8.html
版权声明: 本文为 InfoQ 作者【西贝】的原创文章。
原文链接:【http://xie.infoq.cn/article/d5a4531d156140aaac396ced2】。文章转载请联系作者。

还未添加个人签名 2019.02.15 加入
还未添加个人简介









评论