
RocketMQ 在物流行业的应用与运维

本文作者:丁威 - 中通快递资深架构师,《RocketMQ 技术内幕》作者,Apache RocketMQ 社区首席布道师,公众号「中间件兴趣圈」维护者。
01 物流行业的业务特点

物流行业有三大业务特点:业务量庞大、实效性容忍度高以及业务复杂度极高。
作为快递行业龙头企业,中通的日均订单量早已高达 5000 万,双 11 期间可达日均到 2 亿+,日均消息流转超过万亿。
在快递行业的实际日常业务中,比如早上 10 点下单,可能需要下午 2 点钟揽件,因此我们能够容忍分钟级甚至小时级的延迟。针对包裹拦截、路由变更等场景需要保证一定的时效性,但大多情况下只需尽可能保证即可。
中通快递为加盟制,其转运中心、分布中心以及网点都不在一家公司,因此业务逻辑、管控、结算等都较为复杂。
快递行业的业务系统结算、订单、运单采集等等对解耦性要求很高。此外,双十一期间流量可能为平时的 3-4 倍,因此也需要应对突发流量的能力。而 RocketMQ 的能力与我们的业务场景非常吻合,因此在快递行业的应用也是极为广泛。
02 RocketMQ 在订单中心运用案例
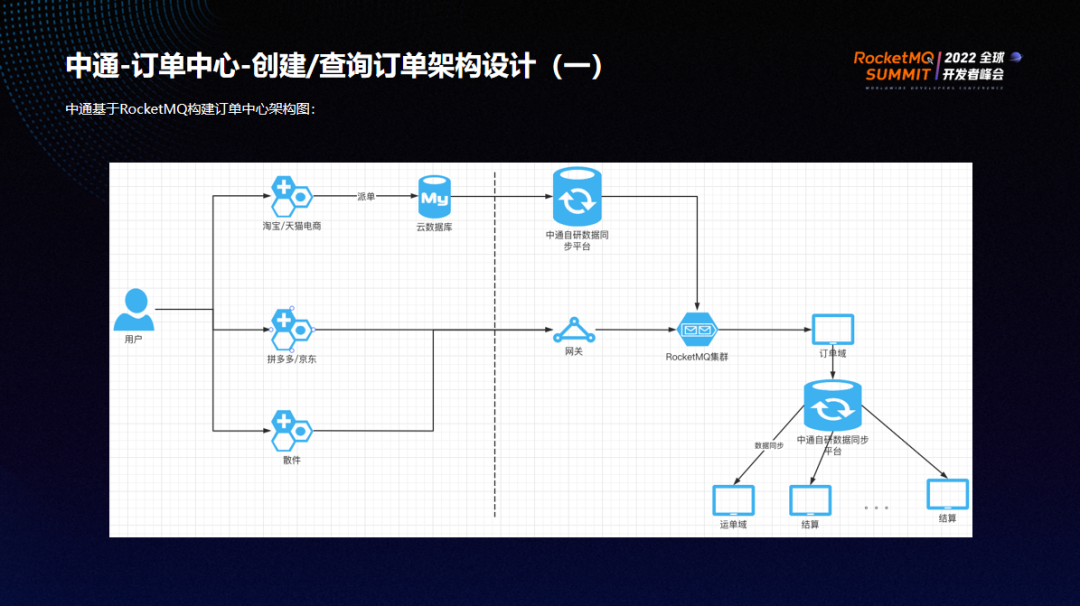
中通基于 RocketMQ 构建订单中心的架构图如上。
用户在天猫或淘宝用电商平台进行下单后,订单会派至云服务器,中通自研的数据同步平台负责定位云服务器的变动日志,通过变动日志将其传入 RocketMQ。
第二层链路为拼多多和京东等厂家,通过网关进入 RocketMQ。
第三层为散件用户,也是通过网关进入 RocketMQ。
流量到达 RocketMQ 以后,由订单域的消费者消费 消费者消息并写入数据库。后续的很多系统比如运单域、结算都需要这份数据,为了解耦,需要通过同步平台将数据在同步到另外 topic,供各个业务系统进行订阅以及数据分发。
上述架构的关键在于如何保证 MQ 服务器性能与数据可靠性。比如 MQ 使用的刷盘策略是同步还是异步?是否开启 transientStorePoolEnable 提高性能?复制策略是同步还是异步?是否需要 Dledger? 如何优雅运维?
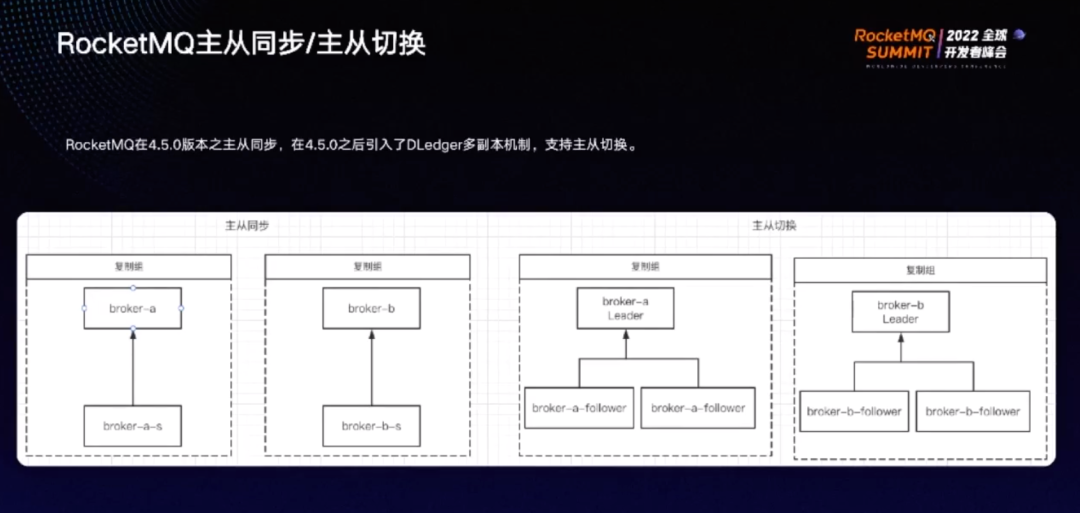
RocketMQ 在 4.5.0 版本之前即支持主从同步,4.5.0 版本之后引入 Dledger 多副本机制,支持了主从切换。一个复制组内有主节点和从节点,不同复制组之间负载均衡。通常情况下由主节点承担数据的读和写,当主节点较为繁忙时,读取可转发到从节点上。同时如果主节点故障,从节点依然能进行消费,以保证消息发送和消息消费的高可用。
一个复制组故障后,请求会全部打到另外的复制组上,导致其因流量过大而出现故障。因此,在实际环境中一般建议部署成四个复制组,以应对流量暴增的情况。
RocketMQ 4.5.0 之后引入了 Dledger 多副本机制,支持主从切换,不同复制组之间依然负载均衡。主节点负责读和写,从节点只负责复制数据。当复制组内主节点宕机后,会在该复制组内出发重新选主,选主完成后即可继续提供消息写功能,不会将流量转移到别的复制组,保证了发送和消费的高可用。
但 Dledger 多副本机制依然存在缺点,三台机器中只有主节点才能读和写,从节点只负责切换,主节点承担了较大压力。如果能让从节点也承担读写请求,按照主从同步模型,主节点宕机后将请求转换到从节点上,才能实现真正的高可用。
物流行业一般选择主从同步模式,因为主从切换的意义不大,而且浪费机器。
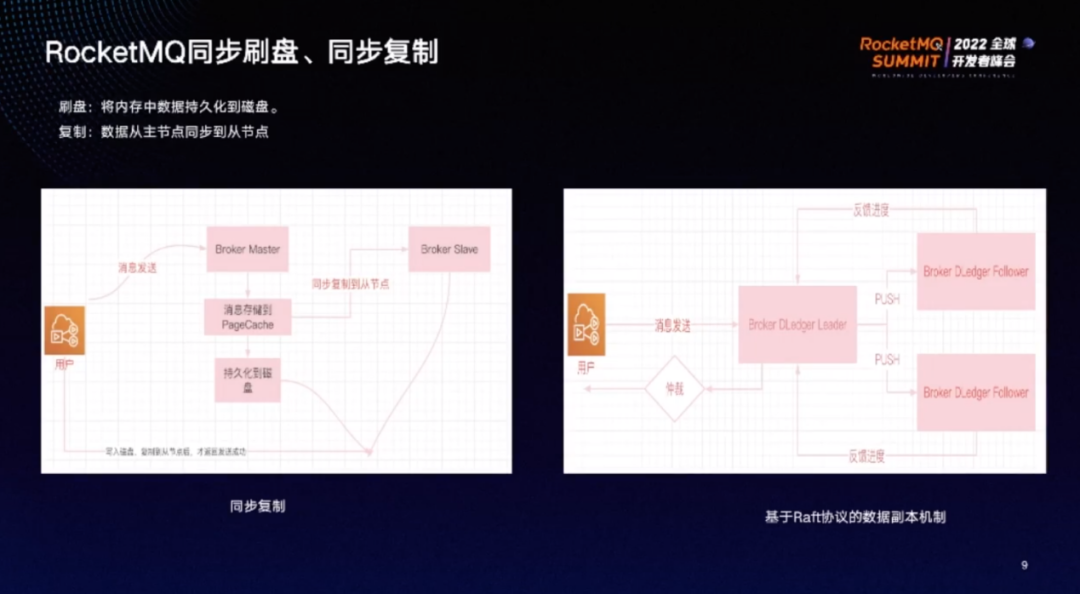
用户发送消息时,消息会先到 broker master,然后存储到 PageCache,再用同步或异步的方式写磁盘。为了保证消息绝对不丢,会使用同步刷盘,同时将数据复制到从节点。一份数据在多个地方存储,能够避免单点故障导致数据丢失。
Dledger 模式是基于 Raft 协议的数据副本机制,要求复制组内超过一半的节点成功写入,数据才算写入成功,可以保证强一致性。
使用同步复制、同步刷盘,消息延迟一定会比不使用此模式更大。
RocketMQ 为了提高写入性能,在内核层提供了读写分离的机制,引入了 transientStorePoolEnable。默认情况下,消息会先进入 PageCache,再通过同步/异步刷盘进入磁盘文件。而 transientStorePoolEnable=true 时,消息会先进入堆外内存,然后通过 FileChannel 块提交的方式批量提交到 FileChannel,再通过异步刷盘批量进入磁盘文件。
堆外内存技术可以保证数据常驻内存中,不会因为内存紧张而将数据交换到其他内存,做出这种方式,能够提高更高的写入性。同时,写入流程没有经过 PageCache,但依然从 PageCache 读取,在内核层实现了读写分离的方式。其优点为性能较高,投入资源较少。缺点是容易丢消息,因为存在堆外内存中的消息可能会出现没有批量提交到磁盘的情况,从而造成消息丢失。

性能与数据丢失如何权衡?
我们认为,性能要追求(资源投入少),数据库正确性也要保证。
首先考虑数据发生丢失的概率以及数据找回的成本是否可控,如果数据找回难度低,则毫不犹豫地选择性能优先。比如,数据存储在 binlog 中,一般保存 15 天。则该情况下集群可以使用异步复制和异步刷盘。并推荐开启 transientStorePoolEnable=true。即使集群服务节点异常导致机器断电等情况造成消息丢失,依然可以通过消息回溯找到断电前的数据。且发生此类情况的概率较低,没有必要为低概率事件牺牲性能。
此外,应避免人为因素(集群运维)导致数据丢失,进一步降低人工介入次数。比如开启 transientStorePoolEnable=true,堆外内存重启时导致数据丢失。发生上述情况时,可通过以下方案保证内存不丢失:
①关闭一组 broker 的写权限,只保留其读权限,即原先存在的消息依然可以消费。
②待 broker 写入 TPS 为 0 后,停止 broker。
③运维操作结束后,启动 broker。
④开启 broker 写权限。
消息发送者或消费者查询信息时,不会访问关闭了写权限的 broker。比如有四台 broker,每个 broker 有四个队列,关闭其中一台的写权限后,返回的只剩 12 个队列。通过此方式,可以平缓地将流量停止。流量停止后,堆外内存中的数据必然会被刷到磁盘中,以此保证数据不丢失。
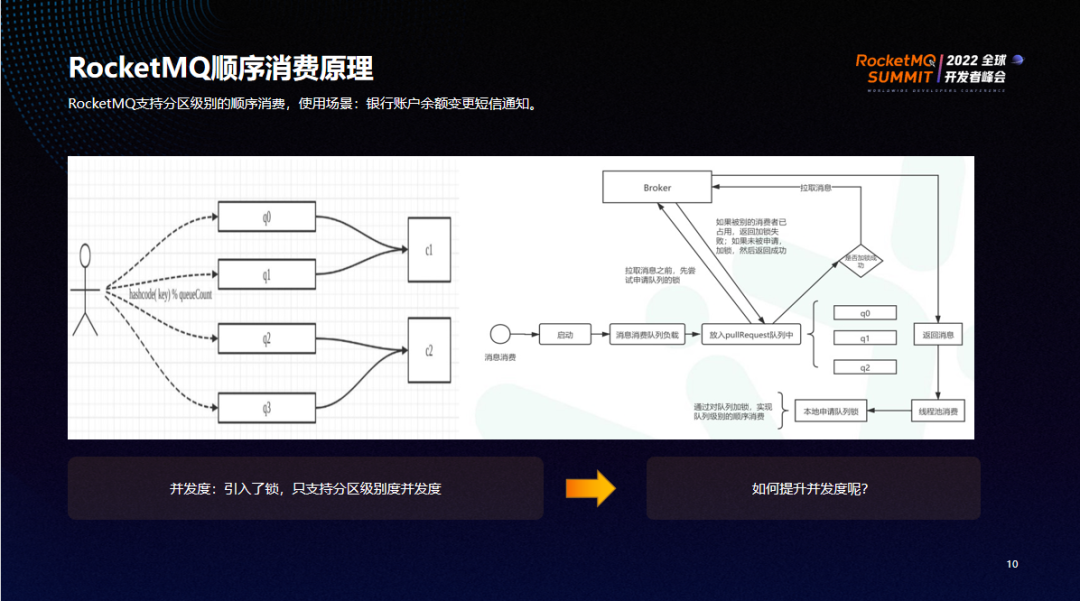
RocketMQ 支持分区级别的顺序消费,以银行账户余额变更短信通知为例:
发送方按照 key (银行账号)进行哈希取模,取完后变为 q0、q1、q2、q3。然后保证同一 key 的消息能进入到同以队列,消费者使用顺序消费的模式能够保证单个分区中的消息按顺序依次进入。
RocketMQ 主要通过锁一致来实现顺序消费。消费者在拉消息前,会先在 broker 服务器锁定队列,锁定成功则可以进行消费;否则不会消费,等待下一次消息队列。
消息进入 pullRequest 队列后,消费者首先会在本地锁定队列,比如消费者分到 q0 和 q1,则会先申请 q0 的锁再进行消费以及申请 q1 的锁再进行消费。
上述流程中,RocketMQ 只支持分区级的并发度。比如消费者被分配了 30 个线程,实际只能有两个线程同时工作。该策略会导致如果消息队列有积压,调整消费者线程数没有任何效果。
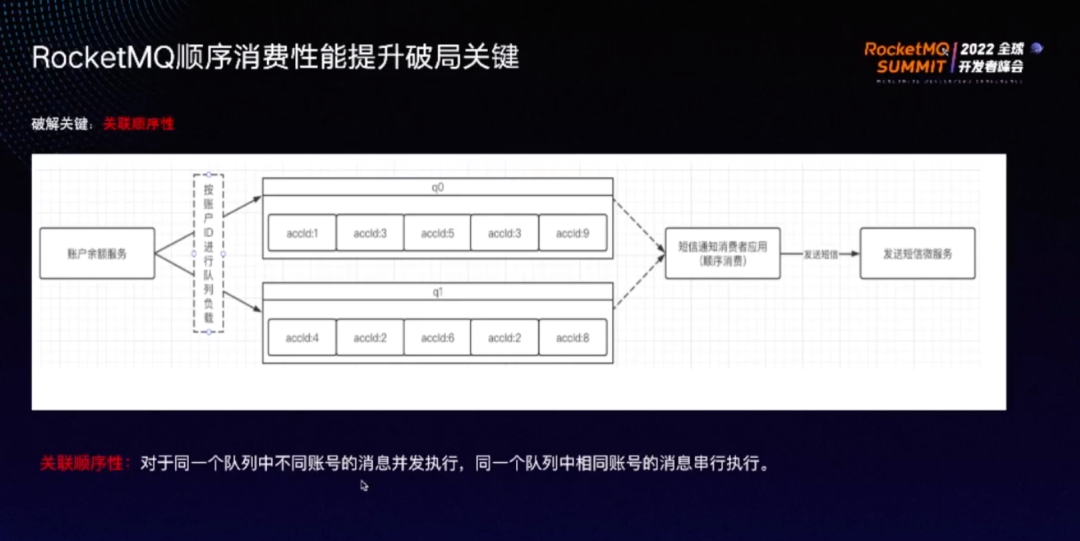
破解并发度困境的关键词为:关联顺序性。
关联顺序性指同一个队列中不同账号的消息并发执行,同一队列中相同账号的消息串行执行。
如上图,以账户余额短信通知服务为例,q0 队列中有 1、3、5、3、9,只需要保证其中的 1、3、5、9 并行执行,而前后两个 3 按顺序执行即可。
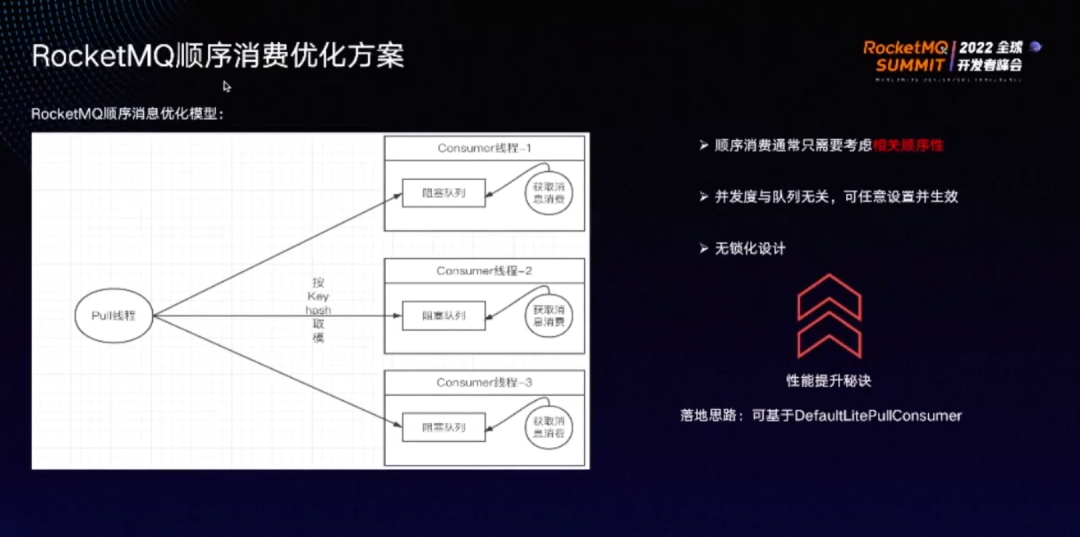
上图为顺序消费模型的优化方案。
定义一个线程池,消费时按哈希取模,使同 key 的消息进入同一线程,不同 key 的消息分散在所有线程池中。比如原先有 10 个线程,不够用则可增加至 20 个线程,即破解了并发度带来的困境。该模型下,并发度与队列无关,可任意根据需求设置并生效。且实现了无锁化设计,按 key 选择线程。
RocketMQ4.6.0 版本提供了 DefaultLitePullConsumer API,其功能与 Kafka 高度类似,实现了 RocketMQ 与 Kafka 的通用性。
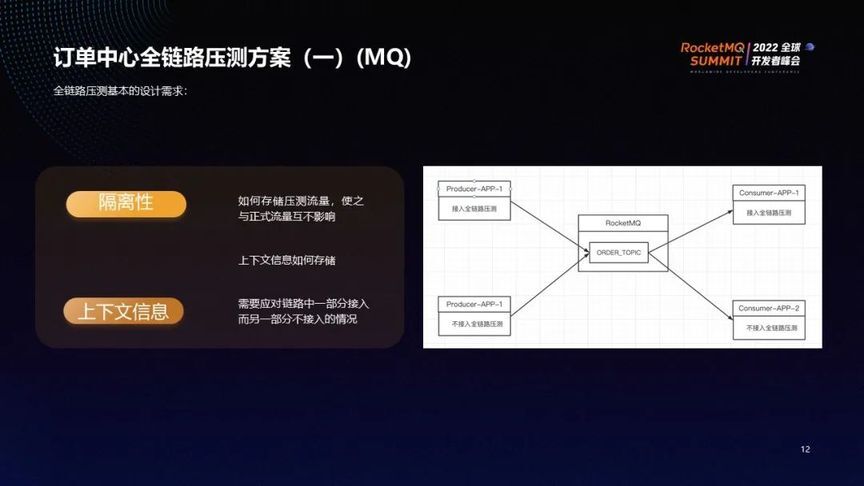
全链路压测的基本设计需求有两个点:
①隔离性:如何存储压测流量,使其与正式流量互不影响。
②上下文信息:链路中一部分接入而另一部分不接入的情况下,上下文信息如何存储?
我们主要通过影子 topic 和影子消费组实现了全链路压测方案。
如上图所示,消息发送到中通自研数据同步平台后,会判断其是否为压测数据。如果是,则发送至 shadow_T_ORDER_TOPIC,否则发送至 T_ORDER_TOPIC。
order_consumer 中包含 shadow_C_ORDER_CONSUMER 和 ORDER_CONSUMER,分别消费压测消息和非压测消息。没有接入全链路压测的消费者指消费非压测数据。通过以上方式,从消息发送和消息消费链路上实现了将流量分开。
同时,其他相关信息比如 ID 等会存储于 RocketMQ 的消息属性中。
未接入全链路压测的应用无法识别消息属性,因此也无法区分消息是否带有压测属性,会导致流量全部打到不接全链路压测的 ORDER_CONSUMER,因此不适合用消息属性进行隔离。如果希望使用消息属性进行隔离,则数据必须全部是业务方会消费的消息。
03 中通基于 RocketMQ 平台化建设实践
中通基于 RocketMQ 的平台已经开源,开源地址如下:
https://github.com/ZTO-Express/zms
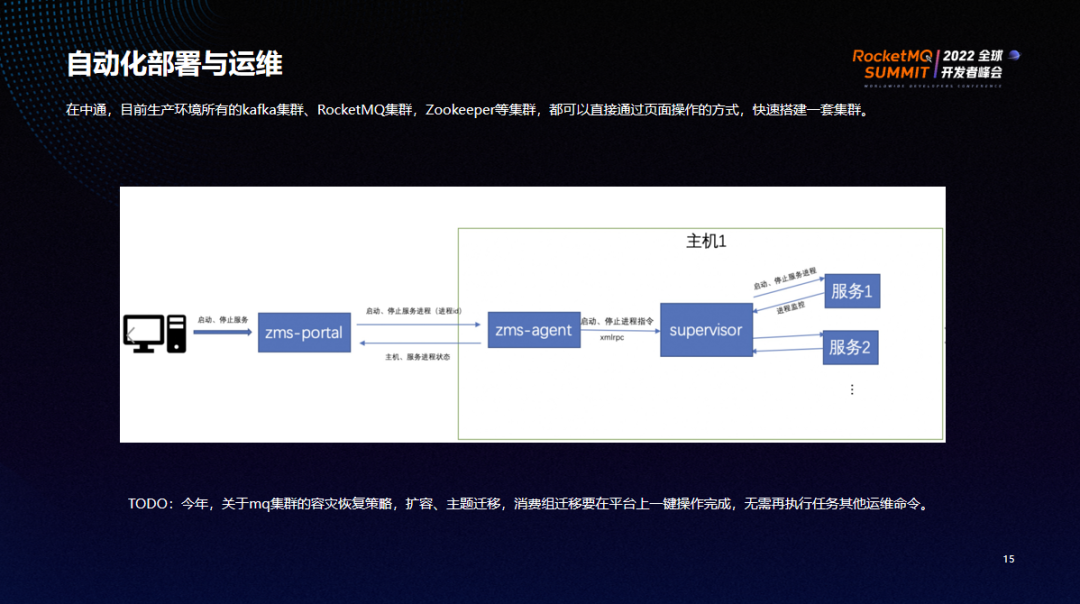
在中通,目前生产环境中所有的 kafka 集群、RocketMQ 集群、Zookeeper 等就能可以直接通过页面操作的方式快速搭建一套集群。实现原理如下:
在页面上访问 zms-portal 来启动和停止服务进程,由 zms-agent 启动 supervisor 进程管理体系来启动和停止服务。安装过程中,将参数提供给 zms-agent,再发送给 supervisor 启动脚本,以启动服务。
今年,中通计划实现关于 MQ 集群的容灾恢复策略,扩容、主题迁移,在平台上一键操作完成消费组迁移而无需执行其他运维命令等能力。
NameServer 地址动态感知机制指:项目组使用 ams-sdk 进行消息发送,消息消费时无需感知 nameserver 地址,只需面对 topic、消费组编程;若集群出现问题,可以无感知地实现 topic 和消费组从一个集群迁移至另外一个集群。
NameServer 地址动态感知机制的实现原理如下:引用 ZK 存储元信息,zms-portal 在新增、修改、删除时,会去操作 Message 集群,同时会将操作写入到 ZK,在 ZK 中存储 topic 属于哪个集群、nameserver 地址等。zms-client 发送消息之前,会查询 topic 的元信息并根据元信息构建底层的发送者进行消息发送。
如果要从一个集群迁移到另一集群,可以先修改元信息并更新 ZK,ZK 更新后,zms-client 会订阅 topic 内容的变化,如果发生变化则通知 SDK 重新构建发送者,实现切换。
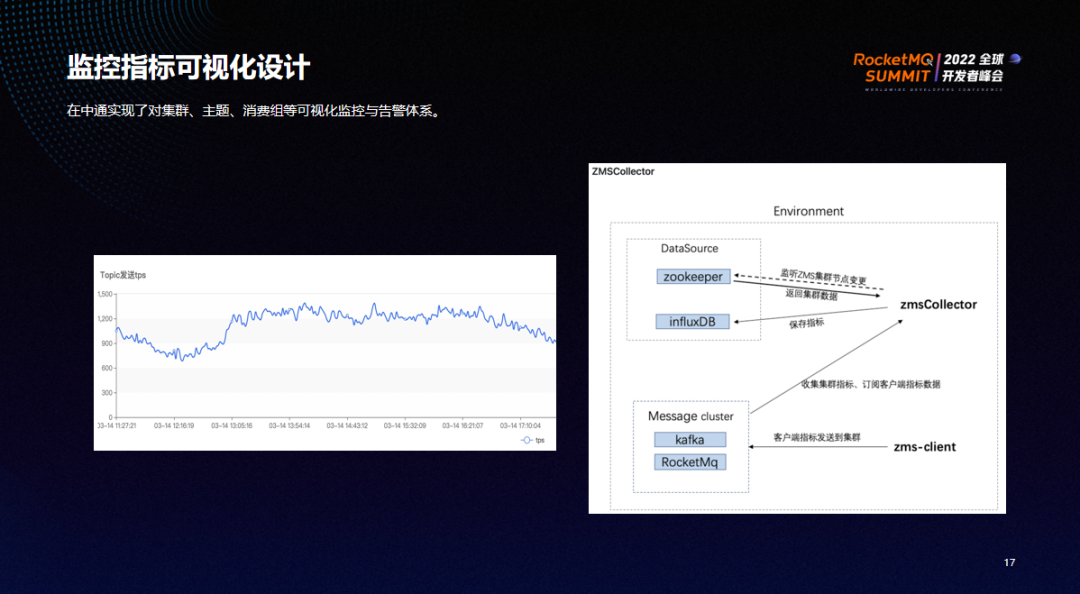
中通实现了对集群、主题、消费组等的可视化监控与告警体系。此能力的实现主要通过 zmsCollector 服务监听 ZMS 节点的变更并返回集群数据,由 Message Cluster 收集集群指标、订阅客户端指标数据给 zmsCollector,再存储至 influxDB 最终进行展示。
此外,RocketMQ 的客户端耗时等指标,我们也在 zms-sdk 那进行埋点,发送至 Message Cluster 后,由 zmsCollector 进行消费,然后发送给 influxDB 最终进行展示。
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。
版权声明: 本文为 InfoQ 作者【Apache RocketMQ】的原创文章。
原文链接:【http://xie.infoq.cn/article/d530629ffb5b253e02192c3dd】。文章转载请联系作者。

Apache RocketMQ 官方 2022-11-09 加入
帮助更多企业、更多开发者来学习、了解、体验Apache RocketMQ~








评论