

第十三周作业
作业一:
Google 搜索引擎是如何对搜索结果进行排序的?(请用自己的语言描述 PageRank 算法。)
互联网中的所有网页会形成一个很大的网络,而且这些网络之间是互相关联(引用)的。同理也就意味着一网页即可能引用其它的网页,也有可能被其它网页所引用。看到这里你可能就想了,那能不能用这些网页之间的引用关系,再通过一个模型来计算出搜索引擎之间的排序呢?
基于这面这个思路,那就开始设计了,如果只是简单的网页之间的引用关系进行累加,这就是一个简单的线性关系,很明显有很大的漏洞,不能更加精确的体现出网页之间的关系。那怎么办呢,要不试试加权?
先给所有网页一个初始值,假如都是1。一个网页的计算结果应该就是所有引用这个网页加权的累加,这样就能给每个网页都计算出一轮值了,如果再多来几轮每个网页的计算结果变动不那么大的时候。这个值不就出来了,这样的计算结果也是相对精确的。简直了,prefect。
听说搜索引擎的竞价排名可以赚钱?这时,人性恶的一面显示出来了。故意的伪造一些恶意的链接都指向自己的网页,而自己的这个网页呢,就像一个“小黑洞”一样,只吃不拉,从而导致大家认为精确页面的计算结果都为0了(真是,黑科技的力量是无穷的)。于是,蹭蹭蹭,自己广告网页的排名上去了。
恶意了对不对,干着急有木有?于是google的小猪佩奇就提出一个随机浏览的模型,假设了这样一个场景:用户并不都是按照跳转链接的方式来上网,还有一种可能是不论当前处于哪个页面,都有概率访问到其他任意的页面,比如说用户就是要直接输入网址访问其他页面,虽然这个概率比较小。所以他定义了阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
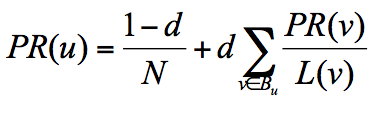
其中 N 为网页总数,这样我们又可以重新迭代网页的权重计算了,因为加入了阻尼因子 d,一定程度上解决了上面个小黑洞的问题。

还未添加个人签名 2018.04.13 加入
还未添加个人简介










评论