Scrapy 中 process_request 返回 request 和 None 的区别
本文首发于个人博客,文章链接为:https://blog.d77.xyz/archives/67ddca4b.html
前言
上篇文章中遇到了一个问题,就是在 process_request 函数中返回 request 对象导致爬虫退出的问题,这篇文章来解释下。
环境搭建
为了弄清楚这个问题,首先搭建一个可以运行 scrapy 的环境,新建一个 scrapy 项目,scrapy startproject testscrapy,之后添加一个名为 testscrapy 的爬虫,代码为:
并且在设置中开启下载中间件,运行下爬虫没有问题环境就搭建好了。
问题原因
首先以正常模式运行爬虫,没有问题,可以正常打印状态码和 title。
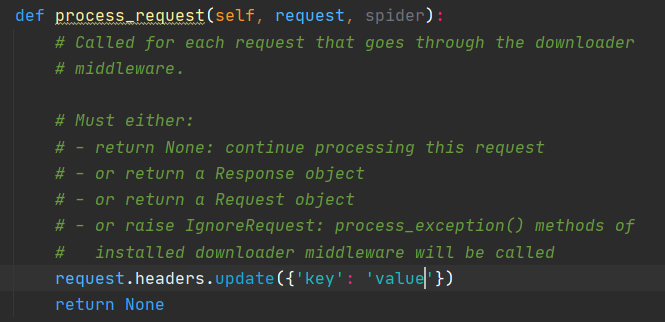
接着修改下载中间件,在请求头中随意添加一个键值对。
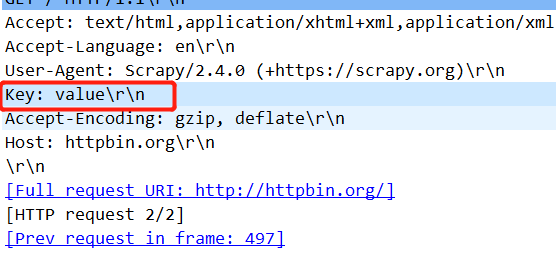
运行爬虫,抓包可以看到请求头被正常添加进去了。
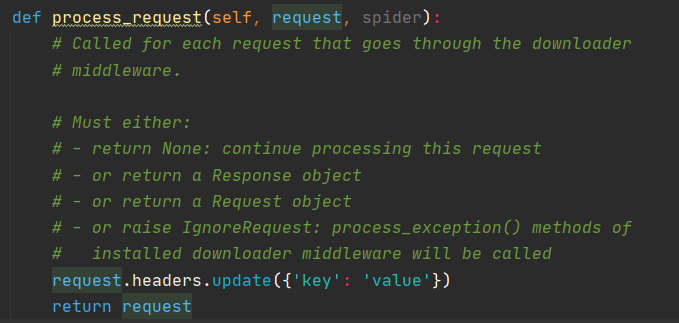
此时如果将返回值修改为 request 对象的话,爬虫会直接退出。
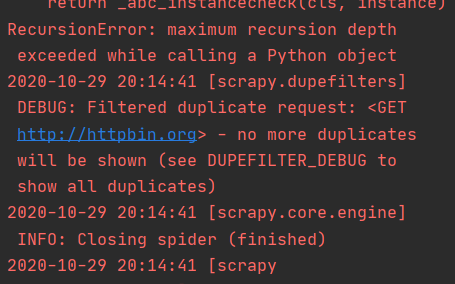
并不会打印状态码和 title,这里有两条日志供我们分析。
首先是递归错误,超过了最大递归深度(RecursionError: maximum recursion depth exceeded while calling a Python object)。
其次是不再显示重复项(no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates))
看到第一条日志我猜测可能是出现了死循环,process_request 函数在不停的调用自己。
看到第二条日志我猜测可能是 request 被重复调度了,scrapy 发现返回的 request 对象已经被请求过了,所以不再调度它。由于 scrapy 默认开启了 URL 去重,所以 request 对象会被丢掉。
再来看日志顺序,重复调度日志在递归错误之后,这里可以猜测在递归错误报错后(因为死循环时是无法调度的)调度器才调度到了 request 对象,然后发现请求过了,之后打印日志,丢掉 request 请求对象。
为了证明 process_request 进入了死循环,加一个延迟,运行爬虫。
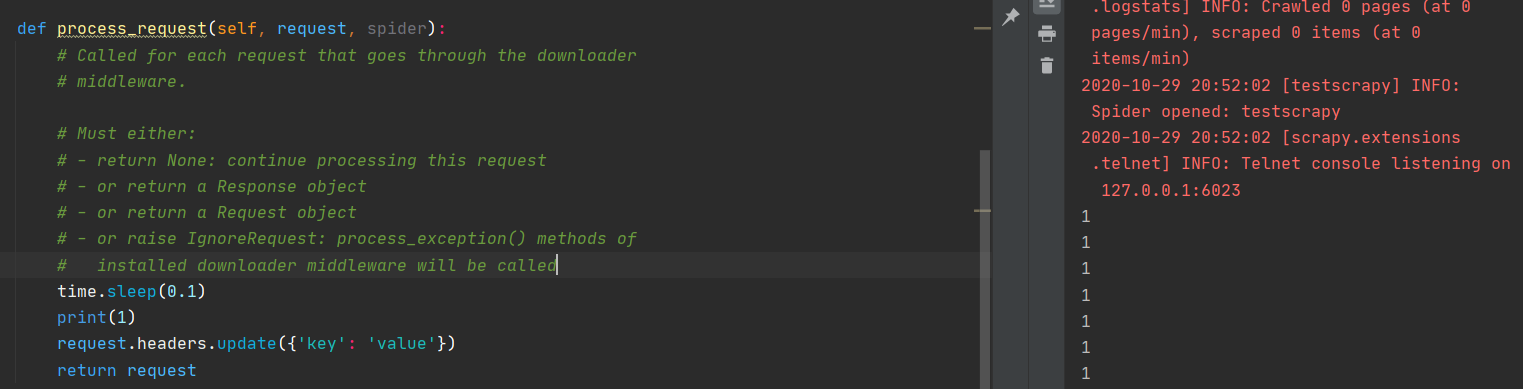
可以看到,一直在打印数字 1,没有打印重复调度的日志,直到递归错误,爬虫才会往下继续运行提示重复调度。
到这里原因就很明显了,如果 processrequest 方法返回一个 request 请求的话,scrapy 会马上将这个 request 对象添加到下载队列(不会进入到下载器),然后继续处理它,由于 processrequest 方法又会返回 request 对象,又会重复将 request 对象添加到下载队列,进入到了死循环。
当发生递归错误之后,死循环被打破,scrapy 提示重复调度,丢掉请求,爬虫退出。
解决方法
所以解决方案就是:不要默认返回 request 对象!
如果只是添加请求头,修改代理 IP 等需求,直接返回 None 就可以了,scrapy 会将修改后的 request 对象调度到下载器去下载。
如果需要将一个请求转到另一个请求的话,需要做好判断后返回 request 对象。

例如:如果想要将 httpbin.org 的请求转发到 baidu,可以按照以上的代码来请求,可以看到,返回了正确的状态码和百度的 title。
顺便再来说下返回值为 response 对象的适用范围。
如果 process_request 方法返回一个 response 对象的话,说明不需要 scrapy 的下载器来下载响应,直接就可以将 response 对象当作下载好的响应返回。
例如:
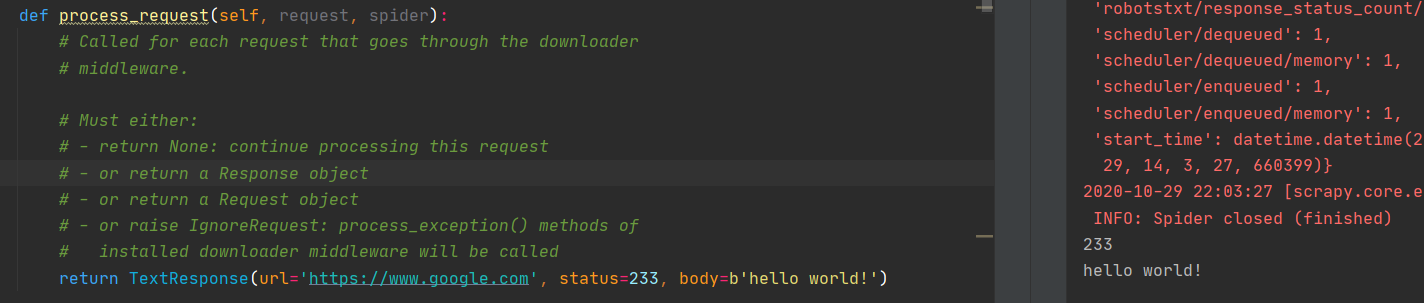
可以看到状态码和 body 都是返回的 response 响应里面的内容,而不是 httpbin 网站的 title。
最常见的用途就是 selenium,它使用 selenium 来渲染网页,然后将获取到的源代码封装成 response 对象返回,巧妙地跳过了 scrapy 自带的下载器,因为它不能执行 JS 代码。
总结
通过以上的实验,可以得知 scrapy 下载中间件死循环的原因和解决方法,scrapy 的官方文档只有简单的几句话介绍,并没有更详细的解释,所以在遇到这种解释很简单的方法时,最好自己动手实验一下,可以加深自己对 scrapy 的理解。
版权声明: 本文为 InfoQ 作者【LLLibra146】的原创文章。
原文链接:【http://xie.infoq.cn/article/d118131e1472975ce0a4eeb16】。未经作者许可,禁止转载。

还未添加个人签名 2018.09.17 加入
还未添加个人简介









评论