

分布式缓存框架

什么是缓存
存储在计算机上的一个原始数据复制集,以便于访问。
缓存无处不在
CPU 缓存,操作系统缓存,数据库缓存,JVM编写缓存,CDN缓存,代理和反向代理缓存,应用程序缓存,分布式对象缓存。
缓存数据存储
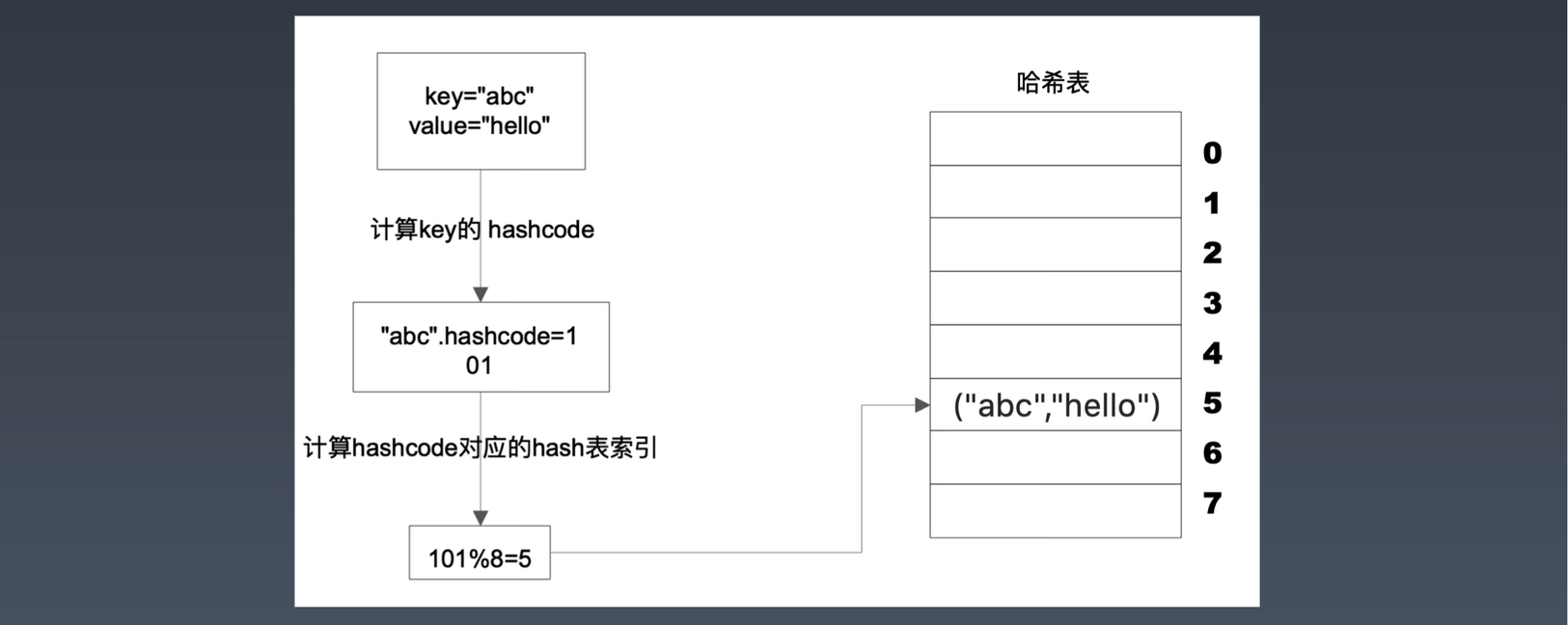
Hash表 key-value 如图:
缓存的关键指标
缓存命中率:缓存是否有效依赖于能多少次重用同一个缓存响应业务请求,这个度量的指标称为缓存命中率。
影响缓存命中率的重要指标:缓存键集合大小,缓存可以使用的内存空间,缓存对象生存时间(TTL)。
通读缓存
代理缓存,反向代理缓存,CDN缓存都是通读缓存。
通读缓存给客户端返回缓存资源,并在请求位命中缓存时获取实际数据。
客户端连接的是通读缓存而不是生成响应的原始服务器。
旁路缓存
对象缓存是一种旁路缓存,旁路缓存通常是一个独立键值对存储。
应用代理通常会访问对象缓存需要的对象缓存如果存在,它会获取并使用缓存对象。如果不存在或者已经过期,应用就会连接数据源来组装对象,并将其保存回对象缓存中以便将来使用。
本地对象缓存
对象直接缓存在应用程序的内存中。
对象存储在共享内存,同一台机器的多个进程可以访问它们。
缓存服务器作为独立的应用部署在同一个服务器上。
本地对象缓存构建分布式集群(如:Jboss cache 存在严重的性能问题而被淘汰 )
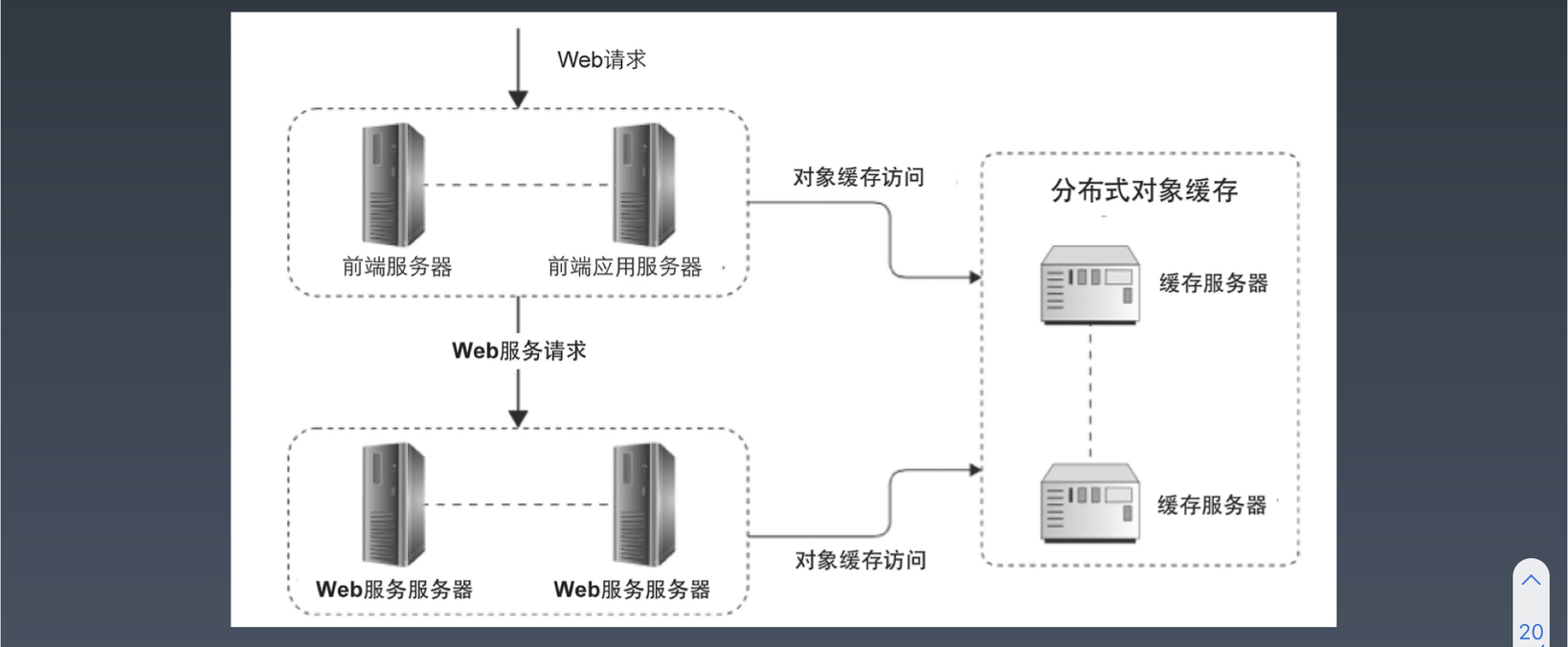
远程分布式对象缓存
框架图如下:
Memcached 分布式对象缓存 About
分布式内存对象缓存系统。采用键值对(key-value)方式存储较小的任意对象(String,Object)。
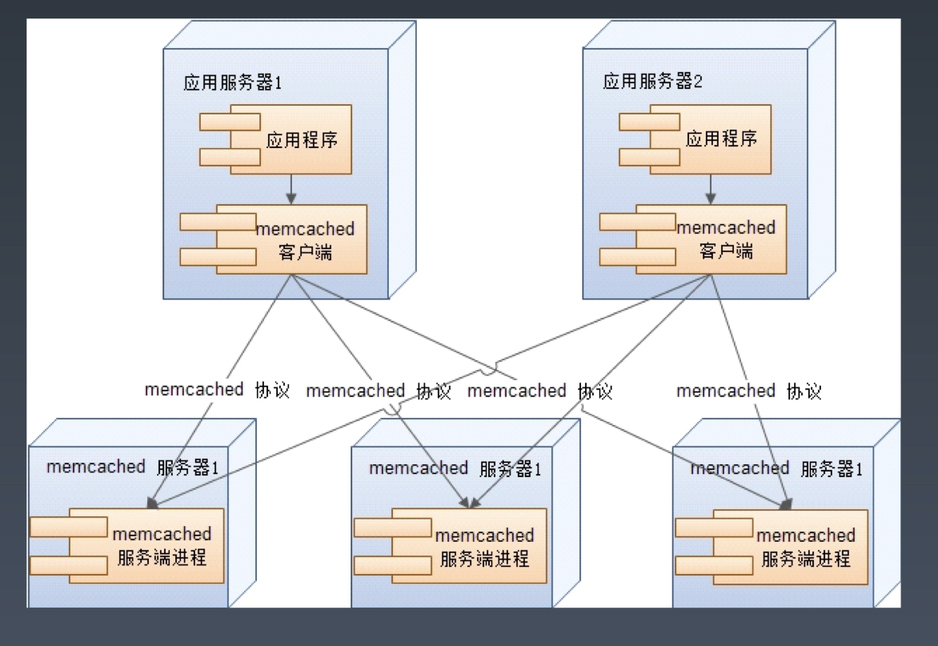
Memcache 的实现通过客户端(Client) 和 服务端(Server)组成,Client 将需要读取的Key通过一致性Hash算法选择可用的Server进行读写操作。Memecache 的 Server 集群之间相互并不感知彼此的存在。Server 直接没有任何通信,可以通过添加Servers的方式轻松扩展虚拟内存。Server 通过最近最少使用算法 LRU (Least Recently Used)进行内存置换。
分布式对象缓存的一致性hash算法(图1)JAVA源码
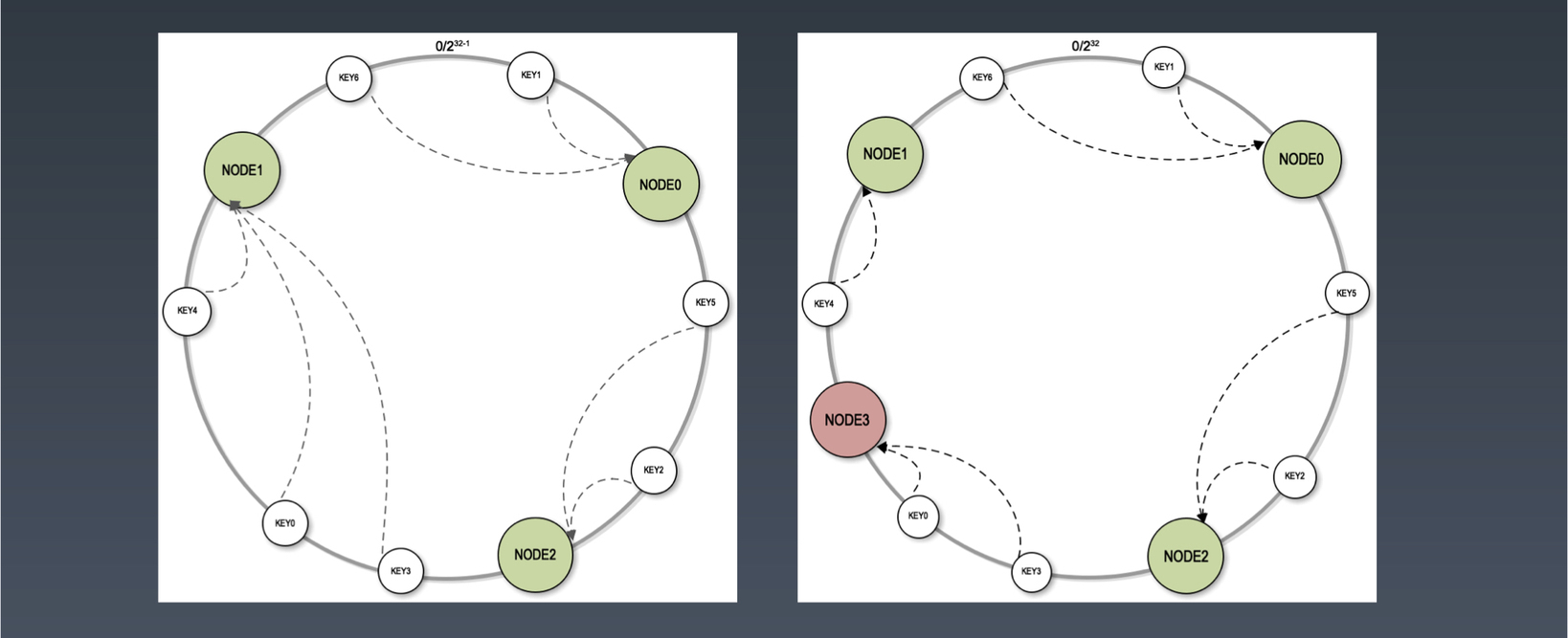
上图是两个包含2^32个结点的hash环,其中左图包含Node0,Node1,Node2三个物理结点。白色圆圈为key的结点位置,key结点按照顺时针方向查找距离自己最近的一个Node结作为真正的数据存储结点。如右图所示如果向hash环中添加一个Node3结点,原来介于Node2和Node1之间的key3将有一部分数据转移到Node3上实现水平伸缩。带来的问题也是很明显的,如果大部分的keys是介于Node0和Node2之间,并没有因为Node3结点的加入而减少本身结点的负载。所以此类算法并未达到负载均衡的效果。从而衍生了为解决负载均衡问题的基于虚拟结点的一致性hash算法。如下图所示:将单个Node0虚拟成多个虚拟结点均

匀的分布在整个hash环上(Node1,Node2,Node3同理)。由于Hash值取值(按照HashCode于2^32取模)带有一定的随机性所以理论上Node0到Node3的虚拟结点是存在重合的但是带来的负面影响不大可以忽略。按照上面提到过的key的选择方式key将先会找到某个Node结点的虚拟结点,再通过虚拟结点找到真正的Node结点,实现key数据的读取或保存。如果添加Node4结点受到影响的数据将会有多少?假设每一个Node结点一共有10个虚拟结点。原来虚拟结点的总数量有30个,原来key的数量是300而且均匀的分布在每一个结点之上。每一个结点承载10个key。新增10个结点后的影响,每个节点承载 300/40=7.5 个key。受到影响的key的数量为 10-7.5 = 2.5 个key。占总体key的比例为 2.5/300 = 0.0083333 约等于 百分之0.8左右,而且虚拟结点的数量也会影响最后的占比,选择一个合适的虚拟结点数量也很重要。
缓存为什么能够显著提升性能
缓存数据通常来自于内存,比磁盘上的数据有更快的访问速度。
缓存数据存储数据的最终结果形态,不需要中间计算,减少cpu资源消耗。
缓存降低数据库,磁盘,网络的负载压力,使这些io设备获得更好的响应特性。
合理使用缓存需要考虑的问题
频繁修改的数据不适用缓存,一般来说读写比在2:1以上,缓存才有意义。
没有热点的访问(二八定律)。
数据不一致于脏读。
缓存雪崩。
缓存预热。
缓存穿透。
Redis 集群
Redis 集群预先分好16384个桶,当需要在Redis集群中放置一个key-value时,根据CRC16(key) mod 16384的值,将决定一个key放在那个桶中。
Redis-Cluster 把所有的物理结点映射到【0-16384】slot上(不一定是均匀的)cluster 负责维护 slot于服务器的映射关系。
客户端于redis结点直连,客户端不需要连接集群的所有结点,连接集群中任何一个可用结点即可。
所有的redis结点彼此互联。
消息队列与异步架构
消息队列构建异步调用框架,点对点模式和发布订阅模式。
消息队列的好处
实现异步处理,提升处理性能。
具有更好的伸缩性。
削峰填谷。
失败隔离和自我修复。
解耦合
主流产品:RabbitMq,ActiveMq,RocketMq,Kafka。
总结
一致性hash算法是分布式缓存框架的开端。缓存的使用应当保持其简单的特点,因为简单所以性能才高。缓存只做缓存,那些缓存框架附带的炫酷技巧也有可能将你带离最初使用缓存的目的,切记谨慎使用!
版权声明: 本文为 InfoQ 作者【王鹏飞】的原创文章。
原文链接:【http://xie.infoq.cn/article/cbb5e5f8fa8a7ea2c676c00d7】。文章转载请联系作者。

还未添加个人签名 2019.06.11 加入
还未添加个人简介










评论