企业是如何选择技术栈来做离线数仓

前言
最近在跟一位粉丝聊天,聊起来了做离线数仓时该用那些技术栈。于是根据我的经验和参考一些资料于就有本篇文章。在这里我会分享三个按案例,仅供参考。

案例一、小型公司
首先我们要明白一点小型公司人员并不多其次服务器的配置有不是很高,这时如果要做数仓使用到的大数据组价就不可能了,那我们就使用传统数据库来进行讲解。
1.1 技术选型
首先公司在选择一个技术时需要考虑成本的,比如人员的安排,公司的员工对大数据的组件都不是很了解,如果选择大数据的组件学习成本较高,可以还会找一批大数据的员工进来开发,提高了项目的成本,由于数据量也不是很高 1 年也就几百万的数据量,目前市场上的数据库也是支持存储的,MySQL、oracle,SQL server 该选择那个一个那?
MySQL、oracle、SQL server 对比
MySQL 优缺点
优
它使用的核心线程是完全多线程,支持多处理器。
有多种列类型:1、2、3、4、和 8 字节长度自有符号/无符号整数、FLOAT、DOUBLE、CHAR、VARCHAR、TEXT、BLOB、DATE、TIME、DATETIME、 TIMESTAMP、YEAR、和 ENUM 类型。
它通过一个高度优化的类库实现 SQL 函数库并像他们能达到的一样快速,通常在查询初始化后不该有任何内存分配。没有内存漏洞。
全面支持 SQL 的 GROUP BY 和 ORDER BY 子句,支持聚合函数(COUNT()、COUNT(DISTINCT)、AVG()、STD()、SUM()、MAX()和 MIN())。你可以在同一查询中混来自不同数据库的表。
支持 ANSI SQL 的 LEFT 0UTER JOIN 和 ODBC。
所有列都有缺省值。你可以用 INSERT 插入一个表列的子集,那些没用明确给定值的列设置为他们的决省值。
MySQL 可以工作在不同的平台上。支持 C、C++、Java、Perl、PHP、Python 和 TCL API。
支持索引创建
缺
MySQL 最大的缺点是其安全系统,主要是复杂而非标准,另外只有到调用 mysqladmin 来重读用户权限时才发生改变。
MySQL 的另一个主要的缺陷之一是缺乏标准的 RI(Referential Integrity-RI)机制;Rl 限制的缺乏(在给定字段域上的一种固定的范围限制)可以通过大量的数据类型来补偿。
MySQL 没有一种存储过程(Stored Procedure)语言,这是对习惯于企业级数据库的程序员的最大限制。
MySQL 不支持热备份。
MySQL 的价格随平台和安装方式变化。Linux 的 MySQL 如果由用户自己或系统管理员而不是第三方安装则是免费的,第三方案则必须付许可费。Unix 或 Linux 自行安装 免费 、Unix 或 Linux 第三方安装 200 美元,
oraclet 优缺点
优
开放性:oracle 能所有主流平台上运行(包括 windows)完全支持所有工业标准采用完全开放策略使客户选择适合解决方案对开发商全力支持;
可伸缩性,并行性:Oracle 并行服务器通过使组结点共享同簇工作来扩展 windownt 能力提供高用性和高伸缩性簇解决方案 windowsNT 能满足需要用户把数据库移 UNIXOracle 并行服务器对各种 UNIX 平台集群机制都有着相当高集成度;
安全性:获得最高认证级别的 ISO 标准认证。
性能:Oracle 性能高 保持开放平台下 TPC-D 和 TPC-C 世界记录;
客户端支持及应用模式:Oracle 多层次网络计算支持多种工业标准用 ODBC、JDBC、OCI 等网络客户连接
使用风险:Oracle 长时间开发经验完全向下兼容得广泛应用地风险低
缺
对硬件的要求很高;
价格比较昂贵;
管理维护麻烦一些;
操作比较复杂,需要技术含量较高;
SQL Server 优缺点
优
易用性、适合分布式组织的可伸缩性、用于决策支持的数据仓库功能、与许多其他服务器软件紧密关联的集成性、良好的性价比等;
为数据管理与分析带来了灵活性,允许单位在快速变化的环境中从容响应,从而获得竞争优势
缺
SQL Server 只能 windows 上运行没有丝毫开放性操作系统系统稳定对数据库十分重要 Windows9X 系列产品偏重于桌面应用 NT server 只适合小型企业而且 windows 平台靠性安全性和伸缩性非常有限象 unix 样久经考验尤其处理大数据库;
SQL server 并行实施和共存模型并成熟难处理日益增多用户数和数据卷伸缩性有限;
没有获得任何安全证书。
SQL Server 多用户时性能佳 ;
客户端支持及应用模式: 客户端支持及应用模式。只支持 C/S 模式,SQL Server C/S 结构只支持 windows 客户用 ADO、DAO、OLEDB、ODBC 连接
5. SQL server 完全重写代码经历了长期测试断延迟许多功能需要时间来证明并十分兼容;
小结
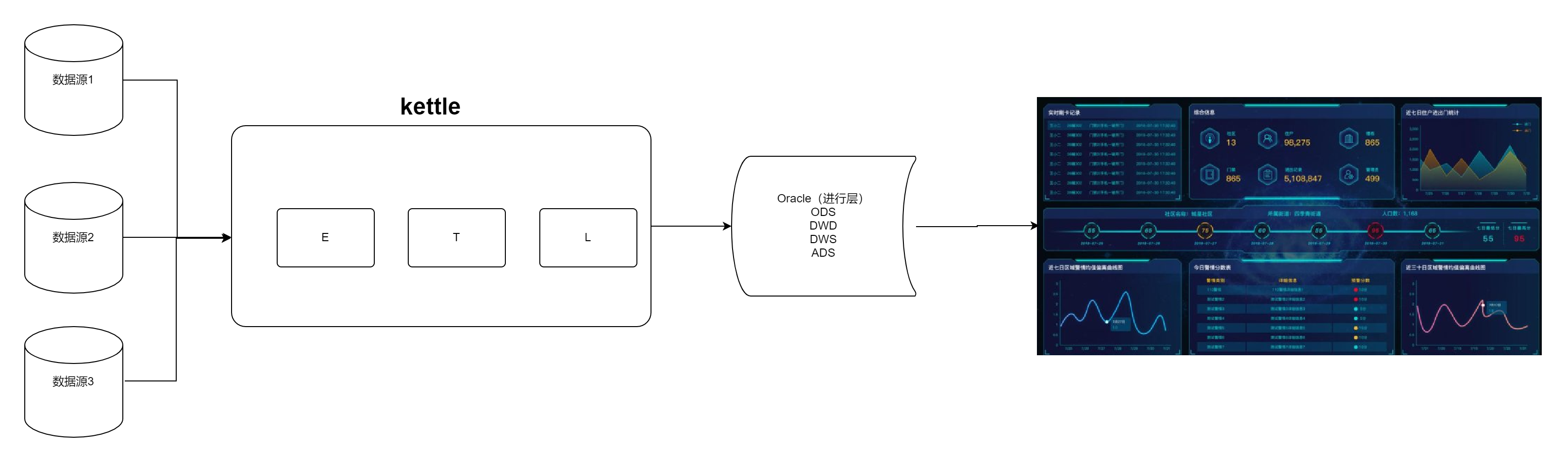
根据开会和各位领导的决定使用 oracle 来做数仓,分别在 oracle 中构构建四层分别为 ods、dwd、dws、ads这里我就不介绍数仓分层概念了最后的整体架构如下:
数据库:Oracle
数据同步 : kettle
数据展示: 大屏展示,Superset
1.2 技术架构
案例二、中型公司
首先中型公司做离线数仓并不单纯的做数仓,你将你数据存放在数仓中通报表的形式展示在大屏中,体现不出数仓的价值,可以通过这个些数据做一个用户画像。我在这里举一个不恰到的例子:比如数仓的中的数据没有被利用起来,我购买了一个商品在后台报表中加上我刚刚下单的这一条数据(死数据),只是报表发生了改变但是对于公司而是价值不大,这时我们是不是可用基于数仓做一个用户画像,分析出这个用户喜欢够那类商品,价格的区间是多少,这样就可以做一个精准推荐。废话就不多少了直接开始。
2.1 技术选型
技术选型需要根据公司的需求以及公司得数据量等综合的因素进行选择,可以使用Hive、HBase等技术来做。那我们这里就使用Hive详细架构请看下:
数据采集: Kettle、sqoop、flume
数据存储:HDFS、Hbase、Redis、Kafka
任务调度:Yarn
计算引擎:Spark
离线处理:Hive
数据应用层: kylin 、大屏展示、Superset
我拍在这里就有好多小伙伴不知道为什么这么选型,我就在这一一给讲解下:
数据采集:
kettle 一般处理一些数据量比较小的数据,因为学习成本低,适合那些刚刚接触 ETL 的员工,并且还有丰富的组件,例如 exec、Json、文本等信息录入到数据库中。
sqoop 主要将关系型数据同步到 hive 中,因为它的底层是通过 MapReduce 的方式当多量数据通过分布式方式效率也不会很慢。
Flume 主要将前端产生的日志存到 kafka 中用来做一些点击流操作。例如:分析用户在这个页面停留了多长时间。求出页面的 TopN 等信息。
数据存储
HDFS 主要存储一些要求时效不高的数据,但是这些数据又不能被丢失场景,一般会结合 Hive 一起使用。
Hbase 一般会将 hive 中的 ADS 层的一部分数据出存储到 Hbase 中提供数据支撑。这一部分数据一般要求时效性比较高。
Redis 一般用于前端与数据库之间的桥梁,前端来的请求先去 Redis 查,这样就避免了数据库高并出现宕机的现象。
kafka 主要存储非结构化数据,一般设置保存 7 天,场景不同。这里用于做点击流。
任务调度
yarn 想必大家对它都不陌生主要用户做资源调度了。
计算引擎
Spark 在本次项目中主要做数据分析,通过 SparkSql 更快的提高分析效率,大大的节约了时间。
离线处理
Hive这里起到了数据仓库的作用 ,Hive 在这里进行了分层分别为ods、dwd、dws、ads 每个层都有他自己的作用域。
2.2 技术架构

案例三、携程机票数据仓库技术栈
以下内容来源于: https://www.sohu.com/a/403837625_411876
携程机票部门的数据仓库建设主要基于公司公共部门的大数据基础环境及数据调度平台,辅以部分自运维的开源存储引擎和基于开源组件二次开发的数据同步工具和运维工具。
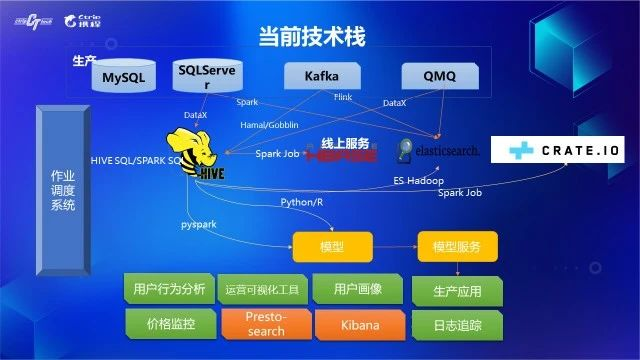
3.1 当前技术栈
生产环境的数据可以大致分成三类:
业务数据,主要存储在 MySQL 和 SQLServer,在这些关系型数据库里面有数以万计的表承接着各种生产服务的业务数据写入;
基础数据,也是存储在 MySQL 和 SQLServer 中,生产应用时一般会建立一层中心化缓存(如 Redis)或者本地缓存;
日志数据,这类数据的特点是”append only”,对已经生成的数据不会有更新的操作,考虑到这类数据的高吞吐量,生产环境一般会用消息队列 Kafka 暂存;
>数据仓库在实施数据同步时,会根据需求在实时、近实时以及 T+1 天等不同的频率执行数据同步,并且在大数据环境会用不同的载体承接不同频率同步过来的数据。在携程机票,实时同步的目标载体是 ElasticSearch、CrateDB 或者 HBase,近实时(一般 T+1 小时)或者 T+1 天的目标载体是 Hive。
从生产的数据载体来讲,主要包括 DB 和消息队列,他们的数据同步方案主要是:
生产 DB 到 Hive 的同步使用 taobao 开源的 DataX,DataX 由网站运营中心 DP 团队做了很多扩展开发,目前支持了多种数据源之间的数据同步。实时同步的场景主要在 MySQL,使用 DBA 部门使用 Canal 解析并写入至消息队列的 bin log。
从 Kafka 到 Hive 同步使用 Camus,但是由于 Camus 的性能问题及消费记录和消费过期较难监控的问题,我们基于 spark-sql-kafka 开发了 hamal,用于新建的 Kafka 到 Hive 的同步;Kafka 实时同步的载体主要是 ElasticSearch 或者 CrateDB,主要通过 Flink 实施。
生产数据被同步数据仓库后,会在数仓内完成数据清洗、信息整合、聚合计算等数据扭转流程,最终数据出仓导入到其它载体,这一系列的流程调度由公司 DP 团队运维的调度平台 Zeus 完成。
3.2 技术架构
小结
一套完整的数据仓库实施方案应该包括但不局限于上面介绍的数据同步方案、数据存储方案、数据规范、元数据建设、数据质量体系、运维工具等,每个实施团队应该根据面临的实际情况选择针对每个点的具体技术方案。我在这里为大家提供大数据的资料需要的朋友可以去下面 GitHub 去下载,信自己,努力和汗水总会能得到回报的。我是大数据老哥,我们下期见~~~
>资源获取 获取 Flink 面试题,Spark 面试题,程序员必备软件,hive 面试题,Hadoop 面试题,Docker 面试题,简历模板等资源请去
>GitHub 自行下载 https://github.com/lhh2002/Framework-Of-BigData
>Gitee 自行下载 https://gitee.com/liheyhey/dashboard/projects

微信搜公众号【大数据老哥】 2021.01.03 加入
微信搜索公众号【大数据老哥】 自己GitHub【https://github.com/lhh2002】 欢迎来star









评论