用 Serverlss 部署一个基于深度学习的古诗词生成 API

前言
古诗词是中国文化殿堂的瑰宝,记得曾经在韩国做Exchange Student的时候,看到他们学习我们的古诗词,有中文的还有翻译版的,自己发自内心的骄傲,甚至也会在某些时候背起一些耳熟能详的诗词。
本文将会通过深度学习为我们生成一些古诗词,并将模型部署到Serverless架构上,实现基于Serverless的古诗词生成API。
项目构建
古诗词生成实际上是文本生成,或者说是生成式文本。关于基于深度学习的文本生成,最入门级的读物包括Andrej Karpathy的博客。他使用例子生动讲解了Char-RNN(Character based Recurrent Neural Network)如何用于从文本数据集里学习,然后自动生成像模像样的文本。
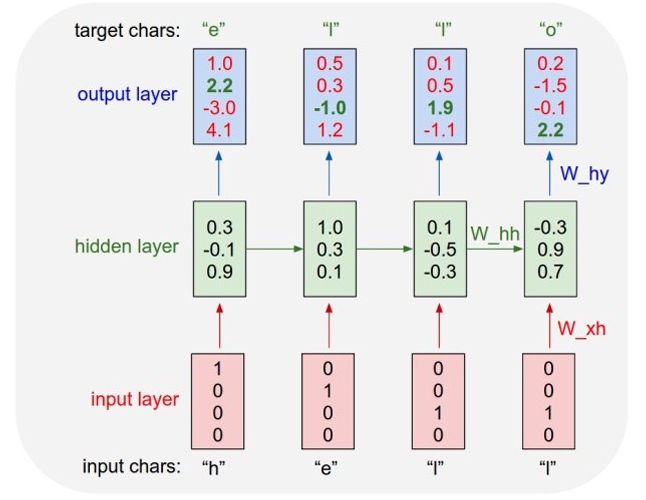
上图直观展示了Char-RNN的原理。以要让模型学习写出“hello”为例,Char-RNN的输入输出层都是以字符为单位。输入“h”,应该输出“e”;输入“e”,则应该输出后续的“l”。输入层我们可以用只有一个元素为1的向量来编码不同的字符,例如,h被编码为“1000”、“e”被编码为“0100”,而“l”被编码为“0010”。使用RNN的学习目标是,可以让生成的下一个字符尽量与训练样本里的目标输出一致。在图一的例子中,根据前两个字符产生的状态和第三个输入“l”预测出的下一个字符的向量为<0.1, 0.5, 1.9, -1.1>,最大的一维是第三维,对应的字符则为“0010”,正好是“l”。这就是一个正确的预测。但从第一个“h”得到的输出向量是第四维最大,对应的并不是“e”,这样就产生代价。学习的过程就是不断降低这个代价。学习到的模型,对任何输入字符可以很好地不断预测下一个字符,如此一来就能生成句子或段落。
本文项目构建参考了Github已有项目:https://github.com/norybaby/poet
通过Clone代码,并且安装相关依赖:
pip3 install tensorflow==1.14 word2vec numpy
通过训练:
python3 train.py
可以看到训练结果:
此时会生成多个模型在output_poem文件夹下,我们只需要保留最好的即可,例如我的训练之后生成的json文件:
此时,我只需要保存output_poem/best_model/model-20390模型即可。
部署上线
在项目目录下,安装必要依赖:
pip3 install word2vec numpy -t ./
由于tensorflow等是腾讯云云函数内置的package,所以这里无需安装,另外numpy这个package需要在CentOS+Python3.6环境下打包。也可以通过之前制作的小工具打包:https://www.serverlesschina.com/35.html
完成之后,编写函数入口文件:
同时需要准备好Yaml文件:
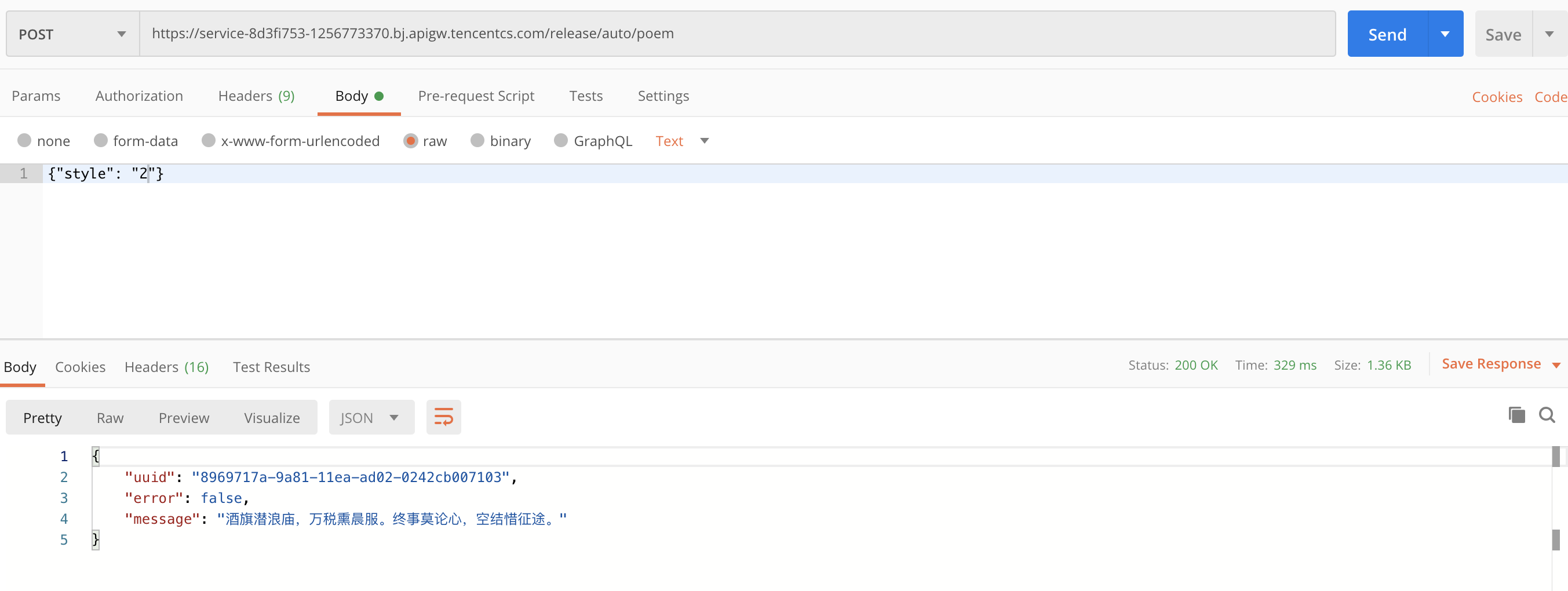
此时,我们就可以通过Serverless Framework CLI部署项目。部署完成之后,我们可以通过PostMan测试我们的接口:
总结
本文通过已有的深度学习项目,在本地进行训练,保存模型,然后将项目部署在腾讯云云函数上,通过与API网关的联动,实现了一个基于深度学习的古诗词撰写的API。
版权声明: 本文为 InfoQ 作者【刘宇】的原创文章。
原文链接:【http://xie.infoq.cn/article/c7bf20fe944243f3750c12750】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

腾讯后台研发工程师,Serverless倡导者 2020.01.04 加入
腾讯云后台研发工程师,曾在腾讯、滴滴出行等多家公司担任产品经理,目前全身心投入到Serverless架构上,是Serverless Framework国内开发人之一(主要开发Tencent Cloud相关组件),著书《Serverless架构》。









评论 (1 条评论)