大数据 2 学习总结
1、Spark
Spark生态体系
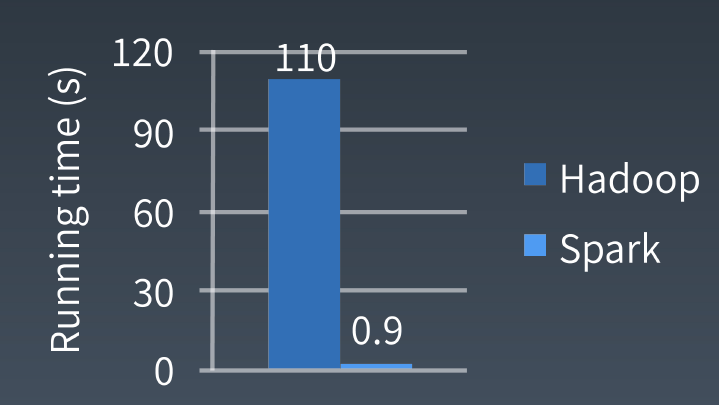
Hadoop和Spark性能对比
Spark特点
DAG切分的多阶段计算过程更快速(细化任务并行)
使用内存存储中间计算结果更高效(减少中间IO交换)
RDD的编程模型更简单(编码模型简化面向数据)
val textFile=SC.textF i le(”hdfs//...”)
val counts=textFi le.flatMap(line=>line.split(””))
.map(word=>(word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("hdfs//…")
第1行代码:根据HDFS路径生成一个输入数据RDD
第2行代码:在输入数据RDD上执行3个操作,得到一个新的RDD
将输入数据的每一行文本用空格拆分成单词。
将每个单词进行转换,word=>(word, 1),生成的结构。
相同的Key进行统计,统计方式是对Value求和,(_+_)。
第3行代码:将这个RDD保存到HDFS
RDD的编程模型
RDD是Spark的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。既是Spark面向开发者的编程模型,又是Spark自身架构的核心元素。
作为Spark编程模型的RDD。我们知道,大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce针对输入数据,将计算过程分为两个阶段,一个Map阶段,一个Reduce阶段,可以理解成是面向过程的大数据计算。我们在用MapReduce编程的时候,思考的是,如何将计算逻辑用Map和Reduce两个阶段实现,map和reduce函数的输入和输出是什么,MapReduce是面向过程的。
而Spark则直接针对数据进行编程,将大规模数据集合抽象成一个RDD对象,然后在这个RDD上进行各种计算处理,得到一个新的RDD,继续计算处理,直到得到最后的结果数据。所以Spark可以理解成是面向对象的大数据计算。我们在进行Spark编程的时候,思考的是一个RDD对象需要经过什么样的操作,转换成另一个RDD对象,思考的重心和落脚点都在RDD上。
WordCount的代码示例里,第2行代码实际上进行了3次RDD转换,每次转换都得到一个新的RDD, 因为新的RDD可以继续调用RDD的转换函数,所以连续写成一行代码可以分成3行。
val rdd1=textFi le.flatMap(line=>line.split(””))
val rdd2=rdd1.map(word=>(word,1))
val rdd3=rdd2.reduceByKey(_+_)
RDD上定义的函数分两种,一种是转换(transformation)函数, 这种函数的返回值还是RDD,另一种是执行(action)函数, 这种函数不再返回RDD。
RDD定义7很多转换操作函数,比如有计算map(func)、过滤filter(func)、合并数据集union(otherDataset)、根据Key聚合reduceByKey(func, [numPartitions])、连接数据集join(otherDataset, [numPartitions])、分组groupByKey([numPartitions])等十几个函数。
作为数据分片的RDD
MapReduce一样,Spark也是对大数据进行分片计算,Spark分布式计算的数据分、任务调度都是以RDD为单位展开的,每个RDD分片都会分配到一个执行进程去处跟片理。
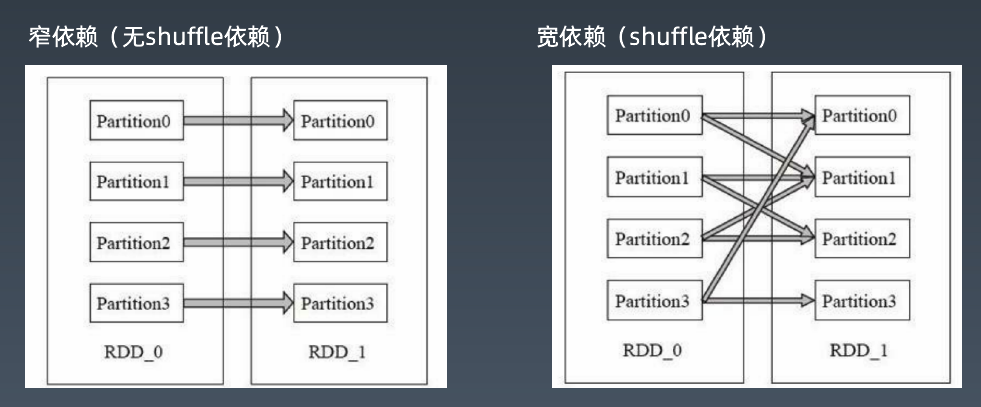
RDD上的转换操作又分成两种,一种转换操作产生的RDD不会出现新的分片,比如map、filter等,也就是说一个RDD数据分片,经过map或者filter转换操作后,结果还在当前分片。就像你用map函数对每个数据加1,得到的还是这样一组数据,只是值不同。实际上,Spark并不是按照代码写的操作顺序去生成RDD,比如
rdd2=rddl .map(func)
这样的代码并不会在物理上生成一个新的RDD。物理上,Spark只有在产生新的RDD分片时候,才会真的生成一个RDD, Spark的这种特性也被称作惰性计算。
另一种转换操作产生的RDD则会产生新的分片,比如reduceByKey,来自不同分片的相同Key必须聚合在一起进行操作,这样就会产生新的RDD分片。然而,实际执行过程中,是否会产生新的RDD分片,并不是根据转换函数名就能判断出来的。
Spark的计算阶段
和MapReduce一个应用一次只运行一个map和一个reduce不同,Spark可以根据应用的复杂程度,分割成更多的计算阶段(stage ),这些计算阶段组成一个有向无环图DAG, Spark任务调度器可以根据DAG的依赖关系执行计算阶段。
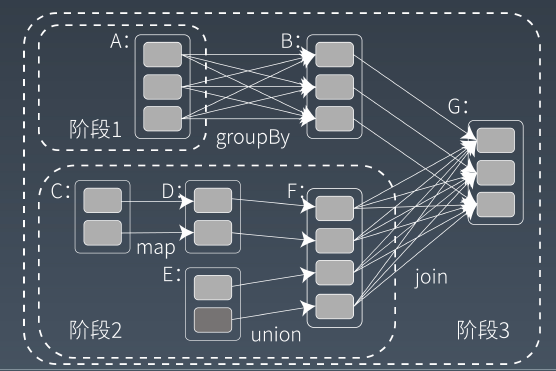
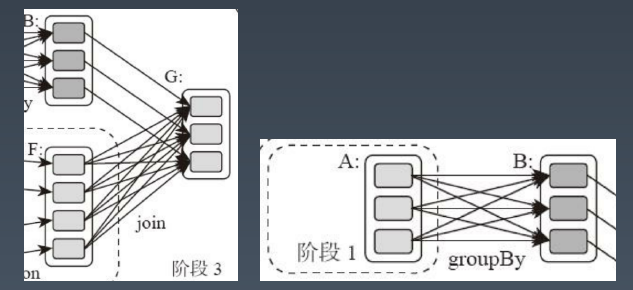
这个DAG对应的Spark程序伪代码如下
rdd B=rddA .groupBy(key)
rdd D=rddC .map(func)
rdd F=rddD .union(rddE)
rddG=rddB .join(rdd F)
整个应用被切分成3个阶段,阶段3需要依赖阶段1和阶段2,阶段1和阶段2互不依赖。Spark在执行调度的时候,先执行阶段1和阶段2,完成以后,再执行阶段3。如果有更多的阶段,Spark的策略也是一样的。只要根据程序初始化好DAG,就建立了依赖关系,然后根据依赖关系顺序执行各个计算阶段,Spark大数据应用的计算就完成了。
Spark作业调度执行的核心是DAG,有了DAG,整个应用就被切分成哪些阶段,每个阶段的依赖关系也就清楚了。之后再根据每个阶段要处理的数据量生成相应的任务集合(TaskSet),每个任务都分配一个任务进程去处理,Spark就实现了大数据的分布式计算。
负责Spark应用DAG生成和管理的组件是DAGScheduler, DAGScheduler根据程序代码生成DAG,然后将程序分发到分布式计算集群,按计算阶段的先后关系调度执行。那么Spark划分计算阶段的依据是什么呢?显然并不是RDD上的每个转换函数都会生成一个计算阶段,比如上面的例子有4个转换函数,但是只有3个阶段。
当RDD之间的转换连接线呈现多对多交叉连接的时候,就会产生新的阶段。一个RDD代表一个数据集,图中每个RDD里面都包含多个小块,每个小块代表RDD的一个分片。
Spark也需要通过shuffle将数据进行重新组合,相同Key的数据放在一起,进行聚合、关联等操作,因而每次shuffle都产生新的计算阶段。这也是为什么计算阶段会有依赖关系,它需要的数据来源于前面一个或多个计算阶段产生的数据,必须等待前面的阶段执行完毕才能进行shuffle,并得到数据。
计算阶段划分的依据是shuffle,不是转换函数的类型,有的函数有时候有shuffle,有时候没有。例子中RDD B和shuffle, RDD B就不需要。RDD F进行join,得到RDD G,这里的RDD F需要进行shuffle,RDD B就不需要
Spark里面的RDD函数有两种,一种是转换函数,调用以后得到的还是一个RDD, RDD的计算
逻辑主要通过转换函数完成。
另一种是action函数,调用以后不再返回RDD。比如count()函数,返回RDD中数据的元素个
数;saveAsTextFile(path),将RDD数据存储到path路径下。Spark的DAGScheduler在遇到
shuffle的时候,会生成一个计算阶段,在遇到action函数的时候,会生成一个作业(job)。
RDD里面的每个数据分片,Spark都会创建一个计算任务去处理,所以一个计算阶段会包含很多
个计算任务(task)。
Spark的执行过程
Spark支持Standalone, Yarn, Mesos, Kubernetes等多种部署方案,几种部署方案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。
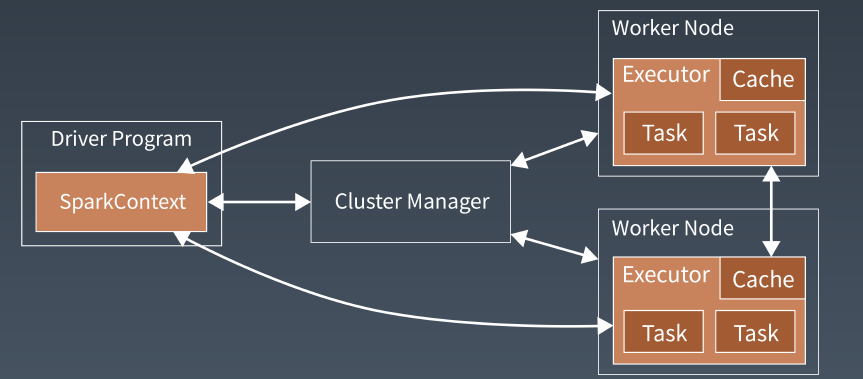
首先,Spark应用程序启动在自己的」VM进程里,即Driver进程,启动后调用SparkContext初始化执行配置和输入数据。SparkContext启动DAGScheduler构造DAG图,切分成最小的执行单位也就是计算任务。
然后Driver向Cluster Manager请求计算资源,用于DAG的分布式计算。Cluster Manager收到请求以后,将Driver的主机地址等信息通知给集群的所有计算节点Worker。
Worker收到信息以后,根据Driver的主机地址,跟Driver通信并注册,然后根据自己的空闲资源向Driver通报自己可以领用的任务数。Driver根据DAG图开始向注册的Worker分配任务。
Worker收到任务后,启动Executor进程开始执行任务。Executor先检查自己是否有Driver的执行代码,如果没有,从Driver下载执行代码,通过Java反射加载后开始执
2、流计算 Storm和Flink
实时计算系统
低延迟
高性能
分布式
可伸缩
高可用

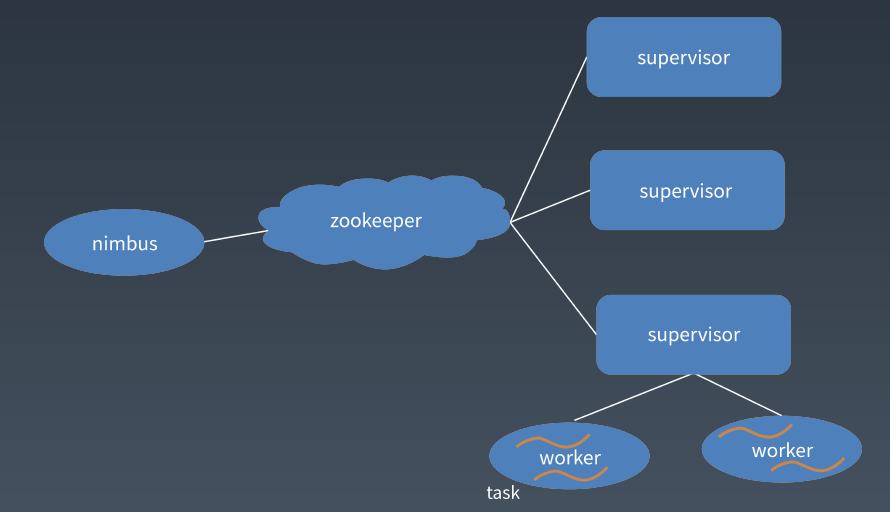
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受Nimbus分配的任务,启动和停止属于自己管理的Worker进程。
Worker:运行具体处理组件逻辑的进程。
Task: Worker中每一个Spout/Bolt的线程称为一个Task。
Topology: Storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
Spout: 在一个Topology中产生源数据流的组件。通常情况下Spout会从外部数据源中读取数据,然后转换为Topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,Storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
Bolt: 在一个Topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元。本来应该是一个key-va lu e的map,但是由于各个组件间传递的tuple
的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
Stream: 源源不断传递的tuple就组成了stream
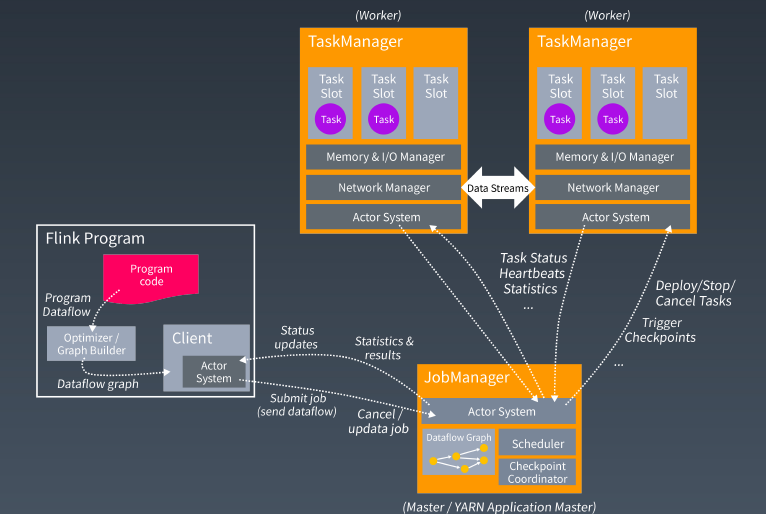
Filnk
3、HiBench
https://github.com/Intel-bigdata/HiBench
Micro Benchmarks:
Sort (sort)
WordCount (wordcount)
TeraSort (terasort)
Repartition (micro/repartition)
Sleep (sleep)
enhanced DFSIO (dfsioe)
Machine Learning:
Bayesian Classification (Bayes)
K-means clustering (Kmeans)
Gaussian Mixture Model (GMM)
Logistic Regression (LR)
Alternating Least Squares (ALS)
Gradient Boosted Trees (GBT)
XGBoost (XGBoost)
Linear Regression (Linear)
Latent Dirichlet Allocation (LDA)
Principal Components Analysis (PCA)
Random Forest (RF)
Support Vector Machine (SVM)
Singular Value Decomposition (SVD)
SQL:
Scan (scan) 2. Join (join), 3. Aggregate (aggregation)
Websearch Benchmarks:
PageRank (pagerank)
Nutch indexing (nutchindexing)
Graph Benchmark:
NWeight (nweight)
Streaming Benchmarks:
Identity (identity)
Repartition (streaming/repartition)
Stateful Wordcount (wordcount)
Fixwindow (fixwindow)
Supported Hadoop/Spark/Flink/Storm/Gearpump releases:
Hadoop: Apache Hadoop 3.0.x, Apache Hadoop 3.1.x, Apache Hadoop 3.2.x, Apache Hadoop 2.x, CDH5, HDP
Spark: Spark 2.4.x, Spark 3.0.x
Flink: 1.0.3
Storm: 1.0.1
Gearpump: 0.8.1
Kafka: 0.8.2.2

还未添加个人签名 2020.04.14 加入
还未添加个人简介









评论