Apache Doris 在京东广告的应用实践

1、序言
本文主要介绍Apache Doris在京东广告报表查询场景下的应用。文章将从我们原有系统开始讲述,包括我们遇到的问题,面临的挑战,以及我们为何选择使用Apache Doris。最后将介绍Doris在我们在生产环境下的使用情况,包括Apache Doris在京东“618”,“双11”大促中的表现。希望通过我们的使用实践为大家提供一些经验参考,也欢迎大家对我们的不足之处提出建议。
2、背景介绍
京准通是京东集团旗下的广告营销推广平台。我们团队主要负责京准通平台的报表查询服务,主要为广告主/运营/采销等提供实时/离线的报表的查询,支持了十余个业务线,300多张报表,覆盖了京准通内绝大多数效果报表,每日千万级查询总量,百亿级数据增量,毫秒级的查询耗时。
3、原有系统存在的问题
我们原来有一套京东广告自己内部开发广告效果数据查询系统,可以支持数据预聚合,支持原子导入,支持按列建立Rollup表。由于这些特性的原因,原有系统在广告效果数据报表的特定场景下,可以满足日常线上查询的需求。
但随着业务的迭代,上层查询系统对我们的要求越来越高,主要表现以下几个方面:
1. 原有系统已经逐渐无法满足我们日常业务的性能需求。
2. 日常业务所需的Schema Change,Rollup等操作,在原有系统上有极高的人力成本。
3. 原有系统的数据无法迁移,扩容需要重刷全部历史数据,运维成本极高。
4. 在“618”和“双11”的时候,原有系统会成为我们对外服务的一个隐患。
因此我们需要一个合适的数据查询引擎来替代我们原有系统,考虑到我们团队的人力和研发能力,我们选择使用开源的OLAP引擎来替换原有系统。
4、技术选型
这里简单介绍我们日常操作的关注的痛点,也是我们在之后技术选型方面主要考虑的方面。
• 查询
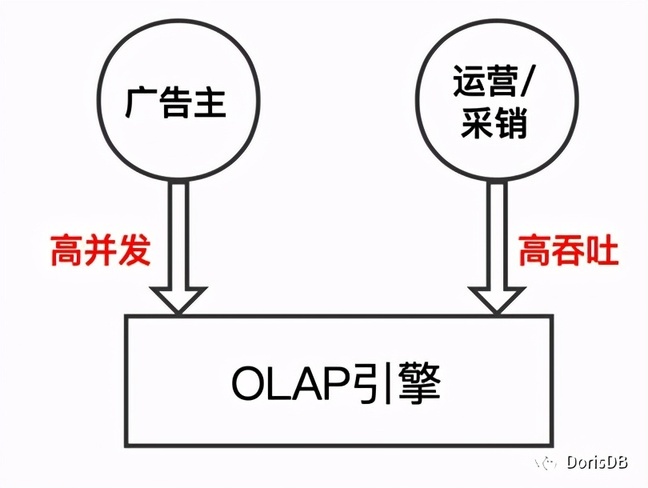
我们为广告主提供在线报表数据查询服务,因此该OLAP查询引擎必须满足:可以支持高并发查询,可以毫秒级返回数据,且可以随着业务的发展水平扩展。此外我们也承接了越来越多运营和采销同事的多维数据分析的需求,因此希望该OLAP引擎也可以支持高吞吐的Ad-hoc查询。
• 数据导入
我们需要同时支持离线(T+1)大规模数据和实时(分钟级间隔)数据的导入,数据导入后即可查询,保证数据导入的实时性和原子性。离线数据(几十G)的导入任务需要在1小时内完成,实时数据(百M到几G)的导入任务需要在10分钟内完成。
• 扩容
在“618”这类大促前我们通常会进行扩容,因此需要新系统扩容方便,无需重刷历史数据来重新分布数据,且扩容后原有机器的数据最好可以很方便地迁移到新机器上,避免造成数据倾斜。
根据日常业务的需要,我们经常会进行Schema Change操作。由于原有系统对这方面的支持很差,我们希望新系统可以进行Online Schema Change,且对线上查询无影响。
• 数据修复
由于业务的日常变更会对一些表进行数据修复,因此新系统需要支持错误数据的删除,从而无需重刷全部历史数据,避免人力和计算资源的浪费。
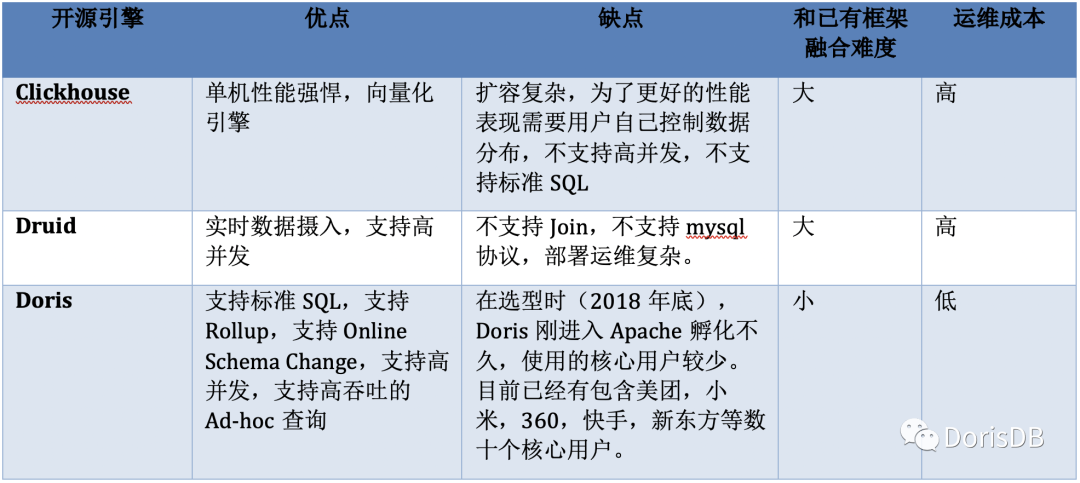
目前开源的OLAP引擎很多,但由于面临大促的压力,我们需要尽快完成选型并进行数据迁移,因此我们只考察了比较出名的几个OLAP系统:ClickHouse,Druid和Doris。最终我们选择了Doris来替换我们的原有系统,主要基于以下几方面的考虑:
1. Doris的查询速度是亚秒级的,并且相对ClickHouse来说,Doris对高并发的支持要优秀得多。
2. Doris扩容方便,数据可以自动进行负载均衡,解决了我们原有系统的痛点。ClickHouse在扩容时需要进行数据重分布,工作量比较大。
3. Doris支持Rollup和Online Schema Change,这对我们日常业务需求十分友好。而且由于支持MySQL协议,Doris可以很好地和之前已有的系统进行融合。而Druid对标准SQL的支持有限,并且不支持MySQL协议,对于我们来说改造成本很高。
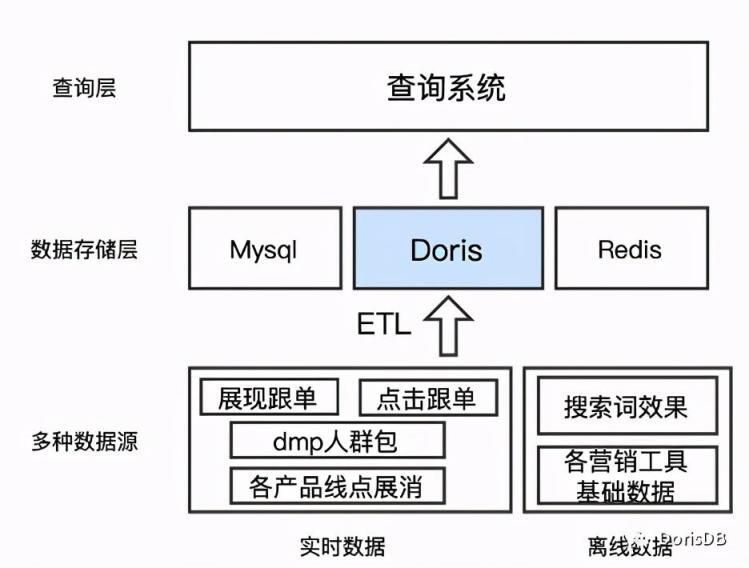
5、广告场景应用
经过对我们系统的改造,目前我们使用Doris作为我们系统中的一个数据存储层,汇总了离线和实时数据,也为上层查询系统提供统一的效果数据查询接口。如下图所示:
• 数据导入
我们日常实时数据主要包含展现/点击跟单数据,DMP人群包的效果数据以及十几条产品线的点击,展现和消耗数据,导入时间间隔从1分钟到1小时不等,数据量在百M左右的可以秒级导入,数据量在1G左右的可以在1分钟内完成。离线数据主要包含搜索词的效果数据和各种营销工具的基础数据,大多数都是T+1数据,每日新增数据量在20G-30G,导入耗时在10-20分钟。
• 预计算
对于我们的大多数效果数据报表,广告主的查询维度相对固定且可控,但要求能在毫秒级返回数据,所以必须保证这些查询场景下的性能。Doris支持的聚合模型可以进行数据的预聚合,将点击,展现,消耗等数据汇总到建表时指定的维度。
此外,Doris支持建立Rollup表(即物化视图)也可以在不同维度上进行预聚合,这种自定义的方式相比Kylin的自动构建cube,有效避免了数据的膨胀,在满足查询时延的要求下,降低了磁盘占用。Doris还可以通过Rollup表对维度列的顺序进行调整,避免了Kylin中因过滤维度列在HBase RowKey后部而造成的查询性能低下。
• 现场计算
对于一些为广告主提供的营销工具,维度和指标通常会有30~60列之多,而且大部分查询要求按照所有维度列进行聚合,由于维度列较多,这种查询只能依赖于现场计算能力。目前我们对于这种类型的查询请求,会将其数据尽量均匀分布到多台BE上,利用Doris MPP架构的特性,并行计算,并通过控制查询时间范围(一个月),可以使TP99达到3s左右。
• 业务举例
正是由于Doris具有自定义的预计算能力和不俗的现场计算能力,简化了我们的日常工作。以我们为广告主提供的营销工具“行业大盘”为例,如图所示,这种业务场景下,不仅要计算广告主自身的指标数据,还需计算广告主所在类目的指标数据,从而进行对比。
原有系统数据分片只能按照指定列进行散列,没有分布式查询计划,就不能汇总类目维度数据。原先为了解决这种业务场景,虽然底层是同一数据源,但我们需要建两个表,一个是广告主维度表,一个是类目维度表,维护了两个数据流,增大了工作负担。
使用了Doris之后,广告主维度表可以Rollup出类目维度表。查询广告主维度数据时可以根据分区分桶(按照时间分区,按照广告主ID分桶)确定一个Tablet,缩小数据查询范围,查询效率很高。查询类目维度时,数据已经按照广告主ID进行分片 ,可以充分利用Doris现场计算的能力,多个BE并行计算,实时计算类目维度数据,在我们的线上环境也能实现秒级查询。这种方案下数据查询更加灵活,无需为了查询性能而维护多个预计算数据,也可以避免多张表之间出现数据不一致的问题。

6、实际使用效果
• 日常需求
– Doris支持聚合模型,可以提前聚合好数据,对计算广告效果数据点击,展现和消耗十分适合。对一些数据量较大的高基数表,我们可以对查询进行分析,建立不同维度或者顺序的的Rollup表来满足查询性能的需求。
– Doris支持Online Schema Change,相比原有系统Schema Change需要多个模块联动,耗费多个人力数天才能进行的操作,Doris只需一条SQL且在较短时间内就可以完成。对于日常需求来说,最常见的Schema Change 操作就是加列,Doris对于加列操作使用的是Linked Schema Change方式,该方式可以无需转换数据,直接完成,新导入的数据按照新的Schema进行导入,旧数据可以按照新加列的默认值进行查询,无需重刷历史数据。
– Doris通过HLL列和BITMAP列支持了近似/精确去重的功能,解决了之前无法计算UV的问题。
– 日常数据修复,相较于以前有了更多的方式可以选择。对于一些不是很敏感的数据,我们可以删除错误数据并进行重新导入;对于一些比较重要的线上数据,我们可以使用Spark on Doris计算正确数据和错误数据之间的差值,并导入增量进行修复。这样的好处是,不会暴露一个中间状态给广告主。我们还有一些业务会对一个或多个月的数据进行重刷。我们目前在测试使用Doris 0.12版本提供的Temp Partition功能,该功能可以先将正确数据导入到Temp Partition中,完成后可以将要删除的Partition和Temp Partition进行交换,交换操作是原子性的,对于上层用户无感知。
• 大促备战
– Doris添加新的BE节点后可以自动迁移Tablet到新节点上,达到数据负载均衡。通过添加FE节点,则可以支撑更高的查询峰值,满足大促高并发的要求。
– 大促期间数据导入量会暴增,而且在备战期间,也会有憋单演练,在短时间内会产生大量数据导入任务。通过导入模块限制Load的并发,可以避免大量数据的同时导入,保证了Doris的导入性能。
– Doris在我们团队已经经历了数次大促,在所有大促期间无事故发生,查询峰值4500+qps,日查询总量8千万+,TP99毫秒级,数据日增量近300亿行,且实时导入数据秒级延迟。
• 使用实践
– Doris支持低延时的高并发查询和高吞吐的Ad-hoc查询,但是这两类查询会相互影响,迁移到Doris的初期日常线上的主要问题就是高吞吐的查询占用资源过多,导致大量低延时的查询超时。后来我们使用两个集群来对两类查询进行物理隔离,解决了该问题。
– Doris在0.11版本时FE的MySQL服务IO线程模型较为简单,使用一个Acceptor+ThreadPool来完成MySQL协议的通信过程,单个FE节点在并发较高(2000+qps左右)的时候会出现连接不上的问题,但此时CPU占用并不高。在0.12版本的时候,Doris支持了NIO,解决了这个问题,可以支撑更高的并发。也可以使用长连接解决这个问题,但需要注意Doris默认对连接数有限制,连接占满了就无法建立新的连接了。
7、总结
通过一年多时间的生产环境使用,Doris满足了我们日常使用的需求,并通过了多次大促的考验,证明了其在广告效果数据场景下适用性,和高并发场景下的可靠性。在日常使用中,其良好的设计也大大降低我们的维护成本,缩短了我们日常业务的开发时间。Doris已经成为了京东广告的核心系统之一。
当前Doris已经逐渐成熟,其周边的生态也越来越完善,未来可以在更多业务场景下进行尝试。Doris研发团队的核心成员组建了鼎石科技,不仅对Apache Doris有更强的支持,而且他们研发的企业版产品,相对于开源版本功能更加完善,性能也更加卓越。在使用Doris的过程中,鼎石科技的小伙伴们也给予了我们很大的帮助。
未来,我们会进一步探索Doris在广告其他方面的应用,包括广告物料数据方面等。期待Doris的功能和性能进一步提升,最终成为解决数据分析问题的统一平台。
作者:京东广告研发工程师 杨文波

最好的国产MPP分析型数据库 2020.08.08 加入
还未添加个人简介









评论