
CeresDB 技术架构简介

1.本文主旨
蚂蚁的时间序列数据库 CeresDB 已开源,项目主要使用 Rust 和 golang 进行开发,github 主仓库为:https://github.com/CeresDB/ceresdb
本文希望能对 CeresDB 做一个整体的介绍,帮助那些想更多了解 CeresDB 技术细节但又无从下手的开发者找到一个起点。当然我们也希望能有更多的开发者参与 CeresDB 这一开源项目的研发。
对 CeresDB 中的一些重要模块以及这些模块之间的关系做一个简短的介绍。具体每个模块的实现细节不在本文中进行展开。
2.架构目标
CeresDB 本质上是作为一个时序数据库进行研发的。我们经过调研发现,业界比较流行的几个传统时序数据库在处理分析型工作负载(analytic workloads)的时候,性能表现都有一定程度的瑕疵。由此,CeresDB 的架构目标被定义为:能同时处理好时序型和分析型的工作负载。
在传统时序数据库中,对 Tag 列(不同时序数据库对这个概念有不同的叫法,InfluxDB 中称之为 Tag ,在 Prometheus 中被称为 Label)通常生成了倒排索引,以加速查询。但是,在不同的场景下,Tag 组合的笛卡尔积乘开量级差异是巨大的。在某些场景下,Tag 组合的数量非常巨大,存储和查询使用倒排索引的开销非常巨大。结合一些分析型数据库的常用技术实践,我们发现在这种场景下,单纯的扫表和剪枝能获取非常不错的性能表现。
结合以上的分析,CeresDB 核心的设计思想是通过引入混合存储格式以及相应的查询配套,来获得在传统时序负载和分析型负载这两个不同场景下的综合性能提升。
3.架构图
下图展示了 CeresDB 单机模式下的架构,以及它内部的一些重要模块的信息。这些重点模块的细节会在本文后面重点进行介绍;
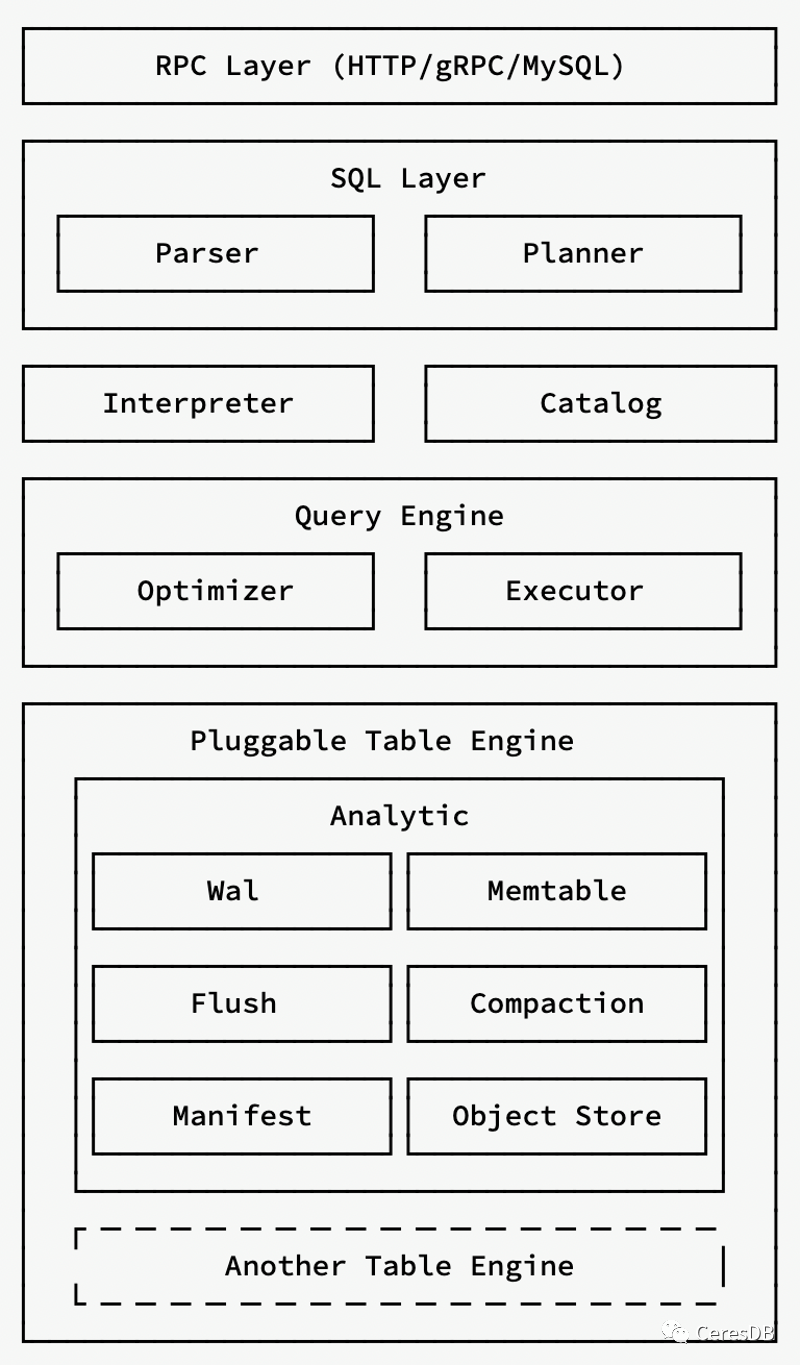
4.RPC 通信层
当前的 RPC 层支持了多种不同的协议,包括 HTTP,gRPC,MySQL。按照当前项目的状态,HTTP 协议和 MySQL 协议主要是用来进行手动查询,debug CeresDB,DDL 操作(比如建表,删表)等非高频行为。而 gRPC 协议可以认为是我们经过了高度调优的一个特化协议,对生产环境大量的写入和查询相对比较友好。
5.SQL 层
SQL 层主要负责进行 SQL 解析和执行计划生成。基于 sqlparser 这一开源库, 我们通过引入时序数据领域中的一些重要概念,比如 Tag 和 Timestamp,并构建了支持时序数据处理的 SQL 方言变体。另外,由于 CeresDB 使用了 DataFusion 这一开源库,使得我们在执行计划层不仅可以生成普通的执行计划,也能支持 PromQL 等时序领域特定查询语言的执行计划。
6.Interpreter
Interpreter 模块封装了 SQL 中的 CRUD 操作。实际上,在执行流程中,一条发送到 CeresDB 的 SQL 语句会被解析,然后转化成执行计划,最后被特定的 interpreter 来执行。例如 SelectInterpreter 和 InsertInterpreter 等。
7.Catalog
Catalog 是实际进行元数据管理的模块。CeresDB 中的元数据管理层次结构和 PostgreSQL 基本类似:Catalog > Schema > Table,不过在 CeresDB 中当前这些元数据仅仅用作了命名空间。
CeresDB 的单机模式和分布式模式中,Catalog 和 Schema 有两种不同的实现。原因是这两种模式下,一些生成 id 的策略和元数据持久化策略存在不同。
8.查询引擎
查询引擎的主要工作是对 SQL 层提交过来的基础执行计划进行优化与执行。当前这些优化工作主要是代理给了 DataFusion。
除了 SQL 查询的基本功能,CeresDB 同样定义和实现了一些自定义的协议。这些协议和执行计划的优化规则是基于 DataFusion 的扩展机制完成的。举个例子,PromQL 的实现与执行优化就是通过这种方式。如果读者对这块感兴趣,可以具体翻阅下相关的代码。
9.可插拔的表引擎
TableEngine 是一个管理 CeresDB 中表的存储引擎。TableEngine 的可插拔能力是 CeresDB 的一个核心设计思想,这关系到我们是否能达同时高性能处理时序和分析型工作负载的设计目标。由于实现了多种不同的 TableEngine,CeresDB 可做到针对不同工作负载模式,选择最合适的 TableEngine 作为底层存储引擎。
对 TableEngine 的需求我们可以抽象为如下的几个方面:
管理该 TableEngine 所控制的所有共享资源,包括:
内存
存储空间
CPU
管理表的元数据,比如表的结构和表的参数
提供 Table 实例的抽象服务能力,它包含 read 和 write 方法
负责表的创建,打开,关闭删除的操作
...
需要 TableEngine 处理的事项事实上是比较复杂的。当前 CeresDB 仅实现了一个 TableEngine,也即是所谓的 Analytic 引擎。该 TableEngine 擅长处理分析性的工作负载,但是当前还尚不擅长处理传统时序数据的查询负载。我们打算后续通过加入索引等方式来增强其在处理时序负载的性能。以下内容具体展开讲解了 AnalyticTableEngine 的一些实现细节。
9.1 WAL
CeresDB 处理数据的模型是 WAL + MemTable。最近的数据会首先被写入到 WAL,然后数据被保存基于内存 MemTable 中。经过一定量的数据积累之后,数据会被组织成查询友好型的格式,并被写入到持久化存储设备中。当前系统中已经提供了两个不同的 WAL 实现(以应对单机模式和分布式模式):
对于单机模式的 CeresDB,WAL 是基于 RocksDB 实现的,数据被保存到了本地磁盘上。
对于分布式模式的 CeresDB,WAL 需要作为一个分布式模块存在以保证新写入数据的高可靠性,当前我们提供了一套基于 OceanBase 的实现。当然在我们的研发计划里程碑上,还将提供更加轻量的分布式 WAL 实现方案。
除此之外, WAL 的 trait 定义也说明了,WAL 有 Region 的概念。事实上,每一张表都会分配给一个 Region,因而不同表之间的隔离性也得到了实现。这种隔离性在我们对 Table 进行各种不同的管控操作时提供了极大的便利(比如对不同的表设置不同的 TTL)。
9.2 MemTable
MemTable 用于承接新近写入的数据。当数据量积累到一定程度之后,CeresDB 会将 MemTable 中的数据重新组织成查询友好型的存储格式(我们称为 SST),并将其写入到持久化存储设备。在 MemTable 中的数据被持久化之前,它的数据是可读的。
当前的 MemTable 实现是基于 agatedb 的跳表。它支持并发读写,并且还提供了基于 Arena 的内存使用管控能力。
9.3 Flush
当 MemTable 的内存使用量到达一定阈值之后,Flush 行为就会被触发。一部分 MemTable 会被选中,将内存中的数据重新组织成查询友好的 SST,并被写入到持久化存储。在 Flush 的执行过程中,数据会被划分到特定时间段(该参数可配置,为 table 的 option 参数 Segment Duration)。任何 SST 都不会跨越 Segment Duration。而这也是大多数时间序列数据库处理数据的常规模式,利用时间维度来组织数据以加速后续与时间相关的操作,比如对一个时间范围的查询,根据 TTL 删数据等。
当前 Flush 的控制流程还是比较复杂的,所以具体细节会单开一篇文章进行详细解释。
9.4 Compation
MemTable 中的数据变成 SST 之后,SST 文件的大小并不是规则的,此时 SST 文件可能都非常小。过多的或者过小的文件会导致查询时的性能较低。因此我们引入了 Compaction 这一行为,它会重新组织存量的 SST,将多个较小的 SST 文件合并成一个较大的 SST 文件。
与 Flush 一样,Compaction 也会后续单独出文章进行说明。
9.5 Manifest
Manifest 负责管理 Analytic 引擎中表的元数据,包括:
表结构和表参数
最新的 flush 完成的 sequence
SST 的管理信息,例如 SST 文件的路径
当前的 Manifest 的实现是基于 WAL 的(这里的 WAL 与上文提到的负责最新写入数据持久化的 WAL 不是同一个实例)。为了防止元数据的无限增长(每次 Flush 都会导致 SST 管理信息的更新),快照也被引入了,用于清除历史的元数据更新信息。
9.6 对象储存
通过 Flush 行为生成的 SST 文件需要被写入持久化存储。在 CeresDB 中,我们对底层存储设备的抽象是对象存储,这包括多种实现:
本地文件系统
阿里云的 OSS
分布式模式下的 CeresDB 是一套计算存储分离的架构,这就要求底层的对象存储能做到高可靠和高可用。因此像 AWS 的 S3,阿里云的 OSS 是作为底层存储介质的一个不错选择。其他云厂商的底层存储系统我们也有后续的计划进行适配。
9.7 SST 文件
Flush 和 Compaction 都用到了 SST 文件,不过在代码仓库中,SST 本身是一个抽象的概念。它可以有若干种具体实现。当前我们的实现是基于 Parquet 这种列式数据存储文件格式的,考虑的因素主要是 Parquet 的格式设计上是比较有利于高效数据写入和查询的。
SST 文件的格式对于拉取数据是至关重要的,它也是关系到我们的设计目标能否达成的关键(同时高效处理时序与分析负载)。当前版本基于 Parquet 的实现对于分析型查询相对友好,但是对典型时序查询并不是很友好。在我们的研发计划中,CeresDB 将探索更多的存储格式,以获取在这两种不同负载下的良好性能水平。
9.8 Space
在分析引擎中,有一个概念叫做 Space, 这里具体解释下这个概念,以防止在读代码的过程中产生一些歧义。实际上在我们实现的分析引擎中,并没有 Catalog 和 Schema 的概念,并且它只提供了两个层次的概念关系:Table 和 Space。在和上层对接中,schema id (在所有 catalog 中都保持唯一)是映射到了 space id。
10.关键执行路径
在前面对 CeresDB 的所有重要模块都进行了简短介绍过了之后,我们对代码中的一些关键执行路径进行介绍。希望能在大家在读代码的过程中提供一些辅助。
查询
我们以 select 查询语句为例,说明执行过程。下图展示了查询的整个流程,其中的数字代表了在不同模块之间的调用顺序。
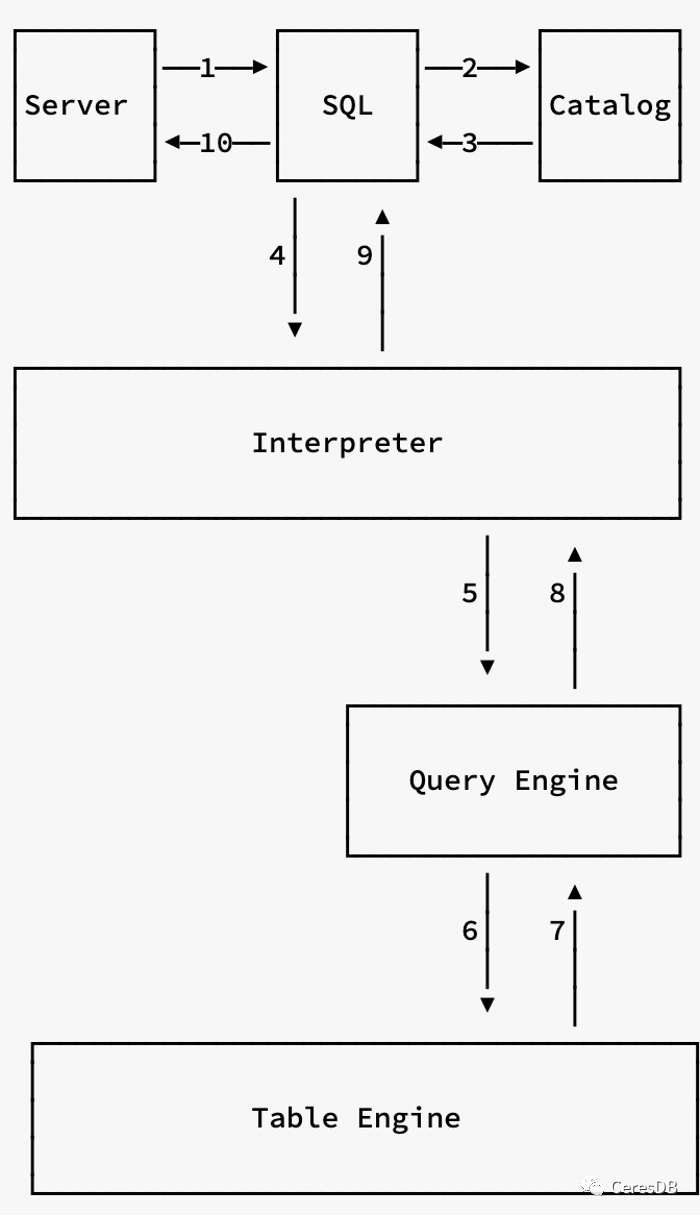
以下说下具体流程:
CeresDB server 收到一个查询请求时,会根据请求中的协议信息,择一个合适的通信协议模块(HTTP,gRPC 或 mysql)来处理请求
在 Parser 中解析请求中的 SQL 语句
解析之后的 SQL 配合 catalog/schema 模块,DataFusion 可以生成逻辑执行计划
根据逻辑执行计划, 对应的 Interpreter 会被创建,然后逻辑计划会被它执行。对于常规的 select 语句,逻辑计划会通过 SelectInterpreter 执行
在 SelectInterpreter 执行过程中, 具体的查询逻辑会通过 QueryEngine 执行,包括以下步骤:
优化逻辑计划
生成物理执行计划
优化物理执行计划
执行物理计划
具体执行物理计划时会用到 Analytic 引擎:
数据通过 Table 实例的 read 方法获取,Table 实例由引擎提供。
table 的真实数据源头是 SST 文件和内存中的 MemTable。在获取数据过程中,数据可以被下推的谓词进行过滤
在获取到表数据之后,查询引擎会继续执行对应的计算逻辑,并生成最终的查询结果
SelectInterpreter 会获取到这一结果,并将它们返回到协议层
协议层处理并转换收到的数据,最后将封装好的数据返回给客户端
写入
我们以 insert 语句为例,说明执行过程。下图展示了写入的整个流程,其中的数字代表了在不同模块之间的调用顺序。

具体展开讲下流程(前半部分处理流程类似查询):
CeresDB server 收到一个数据写入请求时,会根据请求中的协议信息,择一个合适的通信协议模块(HTTP,gRPC 或 mysql)来处理请求
在 Parser 中解析请求中的 SQL 语句
解析之后的 SQL 配合 catalog/schema 模块,DataFusion 可以生成逻辑执行计划
根据逻辑执行计划, 对应的 Interpreter 会被创建,然后逻辑计划会被它执行。对于常规的 insert 语句,逻辑计划会通过 InsertInterpreter 执行
在 InsertInterpreter 中,会绕过查询引擎,直接调用 Analytic 引擎提供的 table 实例的 write 方法,进行以下操作:
将数据首先写入到 WAL
然后将数据写入到内存中的 MemTable
写入内存中的 MemTable 之前,内存用量首先会被检查。如果内存的使用量过高,那么刷盘的流程也会被触发:
将旧的 MemTable 中的数据保存为 SST
删除对应的 WAL
更新元数据,包括新的 SST 文件信息和 WAL 的 sequence
以上流程执行完之后,server 会反馈给 客户端写入成功与否的信息
11.各代码模块入口
欢迎各位有兴趣的同学一起参与开源项目的研发。以上介绍的各个模块的代码实现可以直接参考这些具体仓库链接:

版权声明: 本文为 InfoQ 作者【TRaaS】的原创文章。
原文链接:【http://xie.infoq.cn/article/bee3bb9bec1470e605566e0be】。未经作者许可,禁止转载。

还未添加个人签名 2022.06.22 加入
还未添加个人简介









评论