
记一次 HBASE 的故障分析和排查过程

HBASE 在大数据技术栈中,是一个常用的组件,可以在单表存储量以百亿级的数据,并且提供毫秒级的读写能力,通过线性扩展可达超高 TPS 能力,在大规模清单存储和查询场景中大显身手,然而在实际生产中,也时常会有意想不到的烦恼。
今年笔者支撑的某项目一个部署 HBASE 的大规模集群中发生了连续的宕机事件,对业务造成严重影响。每次宕机后,启动消耗时间都很长,导致业务出现中断。其最关键的问题是,连续宕机且原因不明,所以大概率存在再次宕机的风险,在根因没有定位出来的情况下,这个故障就是达摩克利斯之剑依然悬在半空,谁也不知道什么时候会落下来。下面的篇幅就依此故障排查分析过程为主线展开。
一、故障线索,机会出现
该 HBASE 集群发生的严重宕机事件,具体表现为管理节点 HMaster 异常退出,并且超过一半的 RegionServer 也出现宕机退出,导致业务生产中断。运维人员根据常规步骤进行启动集群操作,之后进行故障分析定位,由于日志级别设置为 DEBUG 级别,日志刷新速度较快,重启后没有及时进行备份转存,故障的时间点的日志没有办法获取,这给查找故障原因造成了很大的麻烦。就在大家面对缺少关键日志,不知道该如何进行故障分析复盘的时候,在不到 24 小时的时间里面,集群出现了又一次宕机!现象是和第一次是一样的,也是 HMaster 异常退出,期间也有大量的 RegionServer 出现宕机。
虽然说连续的故障带来客户的严重不满,但是也给了我们揭开故障根因面纱的大好机会。
二、问题排查,迷雾重重
有了前期的教训,这一次次故障产生后,立即在第一时间将 HBASE 的相关日志都转储保存好,然后就马上着手进行分析和定位。这次故障表象实在有些特殊,HBASE 的日志反应的是 Zookeeper 连接异常:
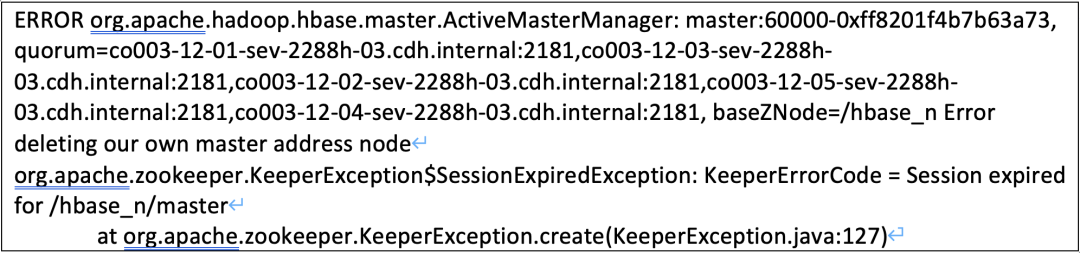
这个时候所有的思路焦点都聚集到 Zookeeper 的这个异常点上面,为什么会出现 Session expired 呢?Zookeeper 是不是出现了什么异常的情况?
之前集群也出现过 HBASE 的故障,因为 Zookeeper 连接超时导致,当时进行过以下举措解决:
所以比较肯定,故障应该还是出在 Zookeeper 上,所以第一时间分析 ZK 的日志。但是 ZK 在整个故障过程中,始终没有出现异常及宕机行为,这个就给问题定位带来很大的不确定性了,因为 Zookeeper 正常,即使是 HBASE 的日志显示连接 ZK 异常,但这个时候依然没有办法定位到具体的原因是由哪个参数哪个配置导致的,也就是说真正有说服力的原因是没有定位到,这样肯定是没有办法结案,而且系统随时可能再次宕机,危机仍在。
只能再次分析 Zookeeper 的日志,查找可能出现异常的原因。通过 ZK 的日志,发现到一个情况,某几台主机连接数特别多,一天下来都有上百万次连接了,这个根据经验来看是不正常的,是不是因为访问量过大导致异常呢?迅速地,进行了对 ZK 的各项指标进行全面的监控,查找可能的连接异常。
排查异常连接数据的主机是哪些程序发出的
在所内模拟对 ZK 进行高负载的连接,测试稳定性
然而结果并不顺利,主机没有部署特别的程序,仅是 HADOOP 集群的计算节点,内测也进行过百万次级别的高负载连接压测,ZK 没有出现异常。
三、拔云见日,真相大白
在经过一天的艰苦研究后,终于看到了曙光!
通过分析日志,发现连接 Zookeeper 的 sessionid 是有异常的。HMaster 和 Zookeeper 是通过 session 维持连接的,这里日志显示了 sessionId 是:0xff8201f4b7b63a73

检测所有的 ZK 服务器的日志,又发现了一段信息:

这个 sessionid,不是 HMaster 的主机,是 10.26.9.35 发出的,也就是说 sessionid 出现了冲突的情况。而由于 sessionid 出现了冲突,并且修改了原 session 的元数据信息,导致 Master 连接 ZK 的长连接出现了过期异常,无法正常续约,HMaster 退出。
那接下来的事情就明了:查明白为什么 ZK 的 sessionid 会出现冲突
首先检测 ZK 产生 sessionid 的源代码:
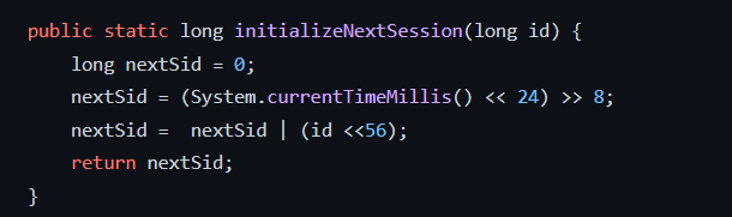
这里肯定看到是通过时间和 ZK 的实例 ID 作为基准进行生成的,现在的问题就是同样的 ID 会参数相同的开始 ID 段。
通过对这段代码进行测试,就发现了问题,无论送的是什么 id 过来,结果都是一样的,这样不同的 ZK 实例,必定会产生相同的 sessionid,也就是说是一个 BUG 来了!
仔细分析了这段代码,发现的是带符号右移,导致溢出了,然后马上检查了后续的版本,发现并进行了修复:
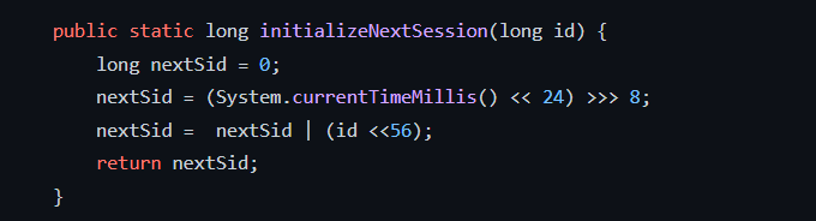
代码确实很少,就是 >>8 变成了 >>>8
符号移位日常使用比较少,确实容易出错:
Java 提供了两种右移运算符:“>>” 和">>>"。其中,“>>”被称为有符号右移运算符,“>>>”被称为无符号右移运算符,它们的功能是将参与运算的对象对应的二进制数右移指定的位数。二者的不同点在于“>>”在执行右移操作时,若参与运算的数字为正数,则在高位补 0;若为负数,则在高位补 1。而“>>>”则不同,无论参与运算的数字为正数或为负数,在执运算时,都会在高位补 0。
上述的问题在于,左移 24 位,再右移 8 位后,当前时间出现了溢出,导致变成负数,真相大白。
ZK 的更新补丁说明:
ZOOKEEPER-1622 session ids will be negative in the year 2022
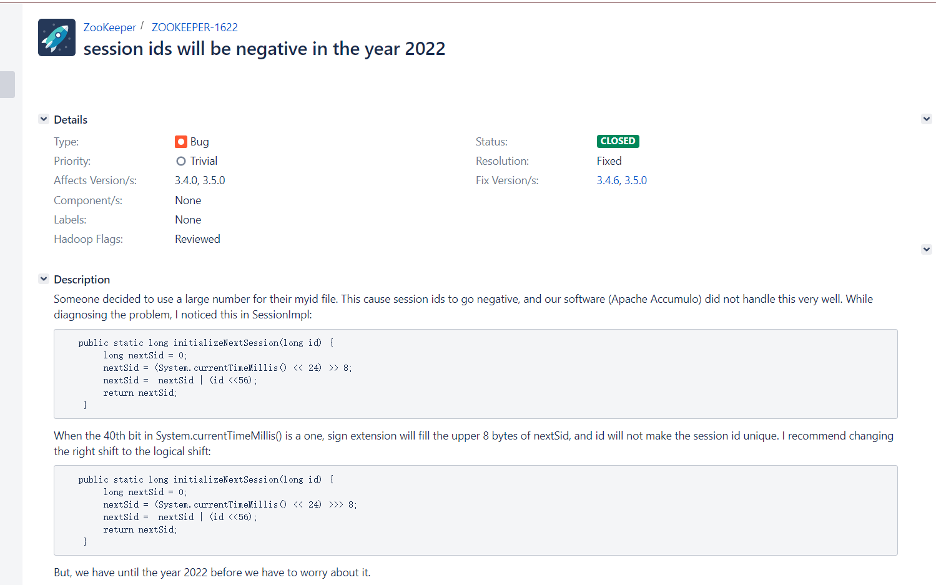
确实到了 2022 年后,由于 sessionid 出现负数,导致所有的 ZK 实例都会产生相同的 sessionid 初始值,所以才出现冲突。
四、故障解决
由于是 ZOOKEEPER 的 BUG 导致,所以后续还是必然还是会有可能再次出现异常,所以根本原因必须要对 ZK 打补丁,才能彻底解决。在没有进行充分验证的情况下,只能通过避免程序到 ZK 的频繁连接,要求对应用程序进行整改,才能降低 BUG 被触发的风险,并且再更新之前每天进行系统及业务巡检。
经过一个业务周期运行观察,系统稳定运行。
五、经验总结
这次的故障定位是一波三折,付出了很大的努力才最终完成问题的定位。由于是组件的 BUG 引起,并且在 2022 年才会触发,这个在之前多年的运维 HADOOP 集群还是第一回出现。
故障分析处理过程中分析日志包括 :HBASE 的 MASTER,REGIONSERVER 实例日志,ZOOKEEPER 的 5 台主机实例日志,YARN 调度程序运行记录日志。
通过这次故障分析可以看出,往往造成原因多方面的,也体现了大数据生态体系复杂性,不同组件的兼容和协同能力是至关重要的,需要研发和运维团队有较强的生态和源代码把控能力,而不是简单的把开源组件堆起即可使用。
几点寄语:
01 故障发生后,现场需要第一时间保留所有的日志
02 需要从故障发生点的异常日志里面,查找有价值的信息
03 需要通过整合所有的日志文件,进行综合分析,大数据集群相对复杂,所有的需要综合分析所有的组件信息,才能在复杂的环境中定位出真正的问题
版权声明: 本文为 InfoQ 作者【鲸品堂】的原创文章。
原文链接:【http://xie.infoq.cn/article/bd96df71e517572fd2f80b2f4】。文章转载请联系作者。

全球领先的数字化转型专家 2021-03-16 加入
鲸品堂专栏,一方面将浩鲸精品产品背后的领先技术,进行总结沉淀,内外传播,用产品和技术助力通信行业的发展;另一方面发表浩鲸专家观点,品读行业、品读市场、品读趋势,脑力激荡,用远见和创新推动通信行业变革。








评论