训练营第六周作业 2
作业二:根据当周学习情况,完成一篇学习总结
NoSQL
NoSQL,泛指非关系型的数据,用于超大规模数据的存储,是关系型数据库的补充,不保证关系数据的ACID特性。
CAP原理
CAP理论,作为分布式系统的基础理论,它描述的是一个分布式系统在以下三个特性中:
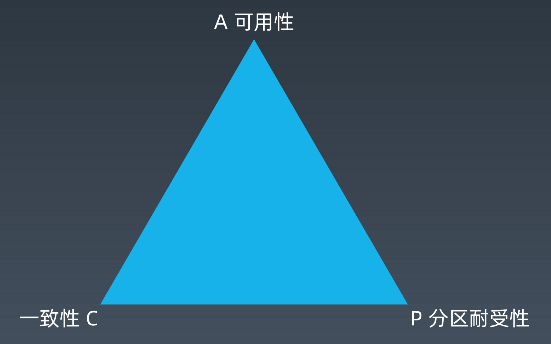
一致性(Consistency):在分布式系统完成某写操作后,任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
可用性(Availability): 每次请求可以正常访问并得到系统的正常响应。用户角度来看就是不会出现系统操作失败或者访问超时等问题。
分区容错性(Partition tolerance):指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供服务。
CAP原理,首先,当网络分区故障发生的时候,我们要么取消操作,这样数据就是一致的,但是系统却不可用;要么继续写入数据,但就保证不了数据一致性。
再说,对于一个分布式系统而言,网络故障一定会发生,也就是说,分区耐受性是必须要保证的,那就要在可用性和一致性上要二选一。
总的来说,当网络分区故障,若选择了一致性,系统就可能返回错误或超时,即系统不可用。若选择了可用性,系统总可以返回一个数据,但并不能保证这个数据是新的。更准确来说,在分布式系统必须满足分区耐受性的前提下,可用性和一致性无法同时满足。
CAP三者不可兼得,该如何取舍:
(1) CA: 优先保证一致性和可用性,放弃分区容错。 这也意味着放弃系统的扩展性,系统不再是分布式的,有违设计初衷。
(2) CP: 优先保证一致性和分区容错性,放弃可用性。在数据一致性要求比较高的场合(如:zookeeper, Hbase) 是比较常见的做法,一旦发生网络故障或者消息丢失,就会牺牲用户体验,等恢复之后用户才逐渐能访问。
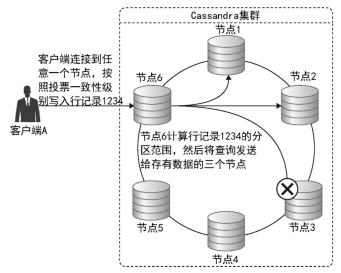
(3) AP: 优先保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra 就是这种架构。跟CP一样,放弃一致性不是说一致性就不保证了,而是逐渐的变得一致。
ACID与BASE
ACID,关系数据库, 最大的特点就是事务处理, 即满足ACID;ACID可以理解为ACID最重要的含义,就是Atomicity和Isolation ,即强制一致性,要么全做要么不做,所有用户看到的数据一致。强调数据的可靠性, 一致性和可用性。
ACID 为 Atomicity, Consistency, Isolation, and Durability,其中ACID分别表示为:
原子性(Atomicity):事务中的操作要么都做,要么都不做。
一致性(Consistency):系统必须始终处在强一致状态下。
隔离性(Isolation):一个事务的执行不能被其他事务所干扰。
持续性(Durability):一个已提交的事务对数据库中数据的改变是永久性的。
保证ACID是传统关系型数据库中事务管理的重要任务,几种事务类型为:未提交读、可提交读、可重复读、可序列化
BASE,分布式数据库最大的特点就是分布式,即满足BASE,ASE方法通过牺牲一致性和孤立性来提高可用性和系统性能。
BASE为Basically Available, Soft-state, Eventually consistent,其中BASE分别代表:
基本可用(Basically Available):系统能够基本运行、一直提供服务。
软状态(Soft-state):系统不要求一直保持强一致状态。
最终一致性(Eventual consistency):系统需要在某一时刻后达到一致性要求。
表示为支持可用性,牺牲一部分一致性,可以显著的提升系统的伸缩性,数据为最终一致。和ACID为相反的方向。其中事务支持不会很高。
Cassandra
Apache Cassandra是一个开源,分布式和分散式/分布式存储系统(数据库),用于管理遍布世界各地的大量结构化数据。它提供高可用性的服务,没有单点故障。
Cassandra 架构
Cassandra设计目的,处理跨多个节点的大数据工作负载,而没有任何单点故障。Cassandra在其节点之间具有对等分布式系统,并且数据分布在集群中的所有节点之间。
集群中的所有节点都扮演相同的角色。 每个节点是独立的,并且同时互连到其他节点。
集群中的每个节点都可以接受读取和写入请求,无论数据实际位于集群中的何处。
当节点关闭时,可以从网络中的其他节点提供读/写请求。
Cassandra数据复制,在Cassandra中,集群中的一个或多个节点充当给定数据片段的副本。如果检测到一些节点以过期值响应,Cassandra将向客户端返回最近的值。返回最新的值后,Cassandra在后台执行读修复以更新失效值。
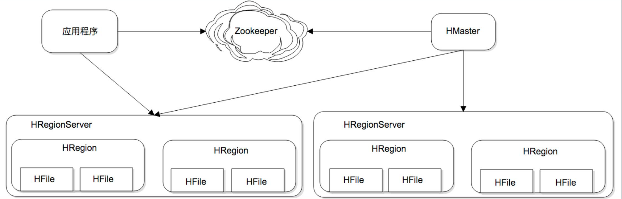
HBase
HBase是一个高可靠、高性能、面向列、可伸缩的分布式开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,主要用来存储非结构化和半结构化的松散数据,实现的编程语言为Java。Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。HBase的目标是处理非常庞大的表,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表,因此,它可以容错地存储海量稀疏的数据。
HBase架构
LSM树(Log-Structured Merge Tree)存储引擎
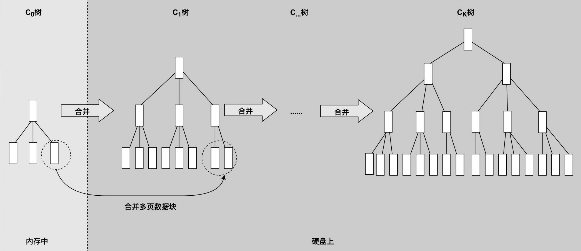
核心思想的核心就是放弃部分读能力,换取写入的最大化能力。LSM Tree ,这个概念就是结构化合并树的意思,它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到最后多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾。
LSM树存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
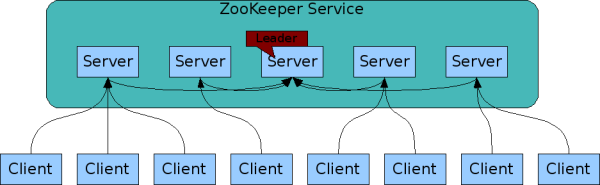
ZooKeeper
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
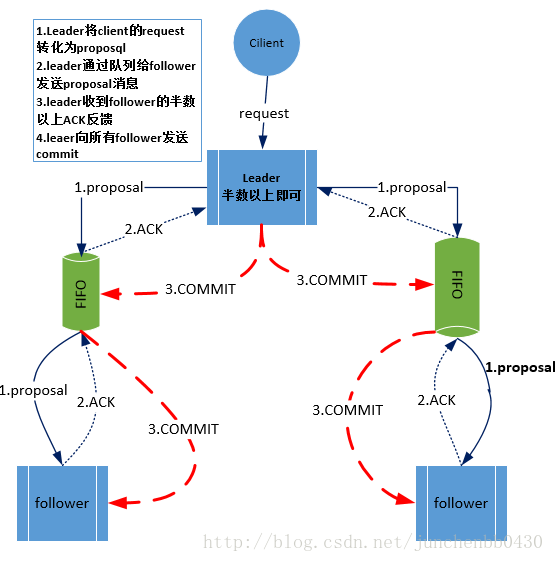
分布式系统脑裂:在分布式系统中,不同服务器获得了互相冲突的数据信息或者执行指令,导致整个 集群陷入混乱,数据损坏,这称为分布式系统脑裂。
解决脑裂问题,有三种常用思路:
设置仲裁机制,是引入第三方检测器的方式,定时检测保障主存活。
lease机制,是以认证凭据方式,保障切换后,老主失效。
设置隔离机制,保证系统识别得到唯一主,剔除掉失效主节点。
主主备
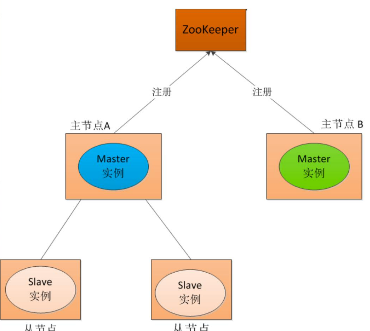
分布式一致性算法Paxos
第一阶段:Prepare阶段,Proposer向超过半数(n/2+1)Acceptor发起prepare消息,如果prepare符合协议规则Acceptor回复promise消息,否则拒绝。
第二阶段:Accept阶段,多数Acceptor回复promise后,Proposer向Acceptor发送accept消息
,Acceptor检查accept消息是否符合规则,消息符合则批准accept请求。
第三阶段:Learn阶段,Proposer在收到多数Acceptors的Accept后,标志本次Accept成功,决议形成,将形成的决议发给所有Learners。
其他:分布式一致性算法Raft、ZAB、Gossip。
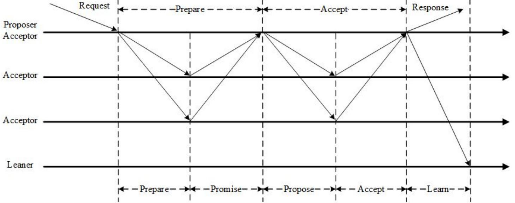
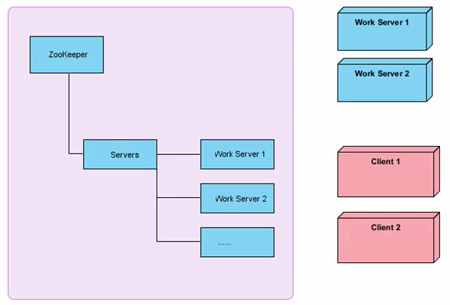
ZooKeeper架构
Zab协议
ZAB 协议是为分布式协调服务ZooKeeper专门设计的一种支持崩溃恢复的一致性协议。
树状记录结构
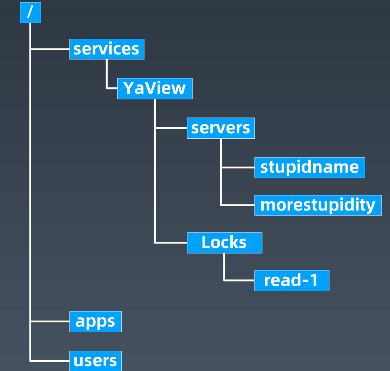
API
create /path data创建一个名为/path的znode节点,并包含数据data。
delete /path删除名为/path的znode。
exists /path检查是否存在名为/path的节点。
setData /path data设置名为/path的znode的数据为data。
getData /path返回名为/path节点的数据信息。
getChildren /path返回所有/path节点的所有子节点列表。
void sync(path) 对指定的路径,强制本连接所在的服务器和leader同步信息,异步调用
List multi(ops) 原子地执行多步zk操作
...
配置
tickTime:这个时间是作为Zookeeper服务器之间或者客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一下心跳。
initLimit:这个配置项是用来配置zookeeper接受客户端的(这里所说的客户端不是用户连接Zookeeper服务器的客户端而是Zookeeper服务器集群中连接到Leader的Follower服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper服务器还没有接到客户端的返回信息,那么表明这个客户端连接失败。总时间长度就是102000=20秒。
syncLimit:这个配置项标示Leader与Follower之间发送消息、请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是52000=10秒。
dataDir:Zookeeper保存数据的目录,默认情况下,Zookeeper将数据的日志文件也保存在这里。dataLogDir
clientPort:这个端口就是客户端连接Zookeeper服务器的端口。Zookeeper会监听这个端口,接受客户端的访问请求。
server.A=B:C:D 其中A是一个数字,标示这是第几号服务器;B是这个服务器的ip地址;C标示的是这个服务器与集群中的Leader服务器交换信息的端口;D标示的是万一集群中Leader服务器挂了,需要一个端口来进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于B都是一样,所以不同的Zookeeper实例通信端口号不能一样,所以要给他们分配不同的端口号。
myid:集群模式下配置一个文件myid,这个文件在daraDir目录下,这个文件里面就有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
集群(负载均
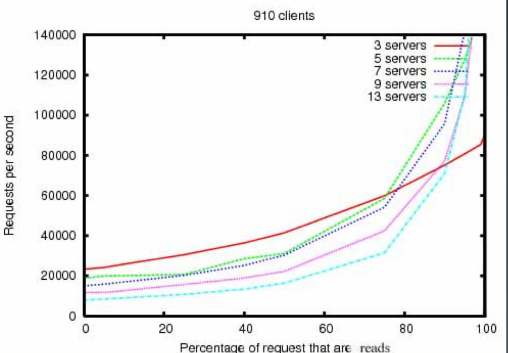
性能
搜素引擎
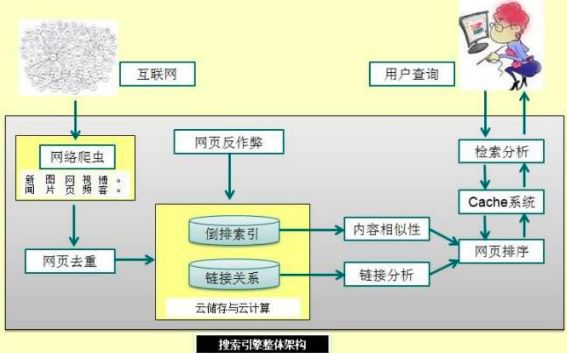
互联网搜索引擎架构
Lucene架构
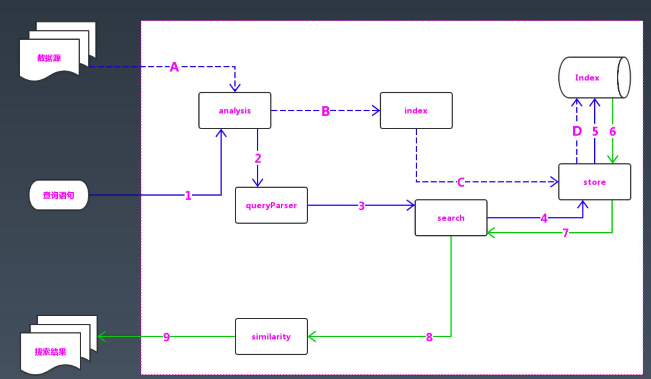
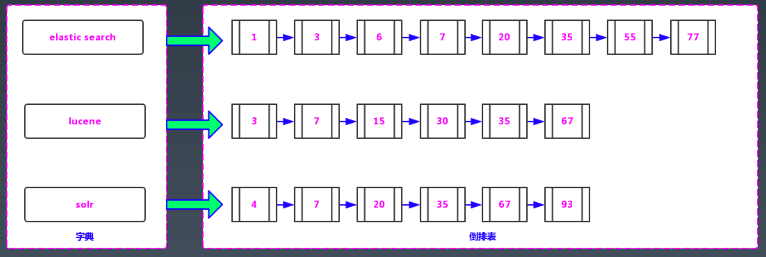
倒排索引
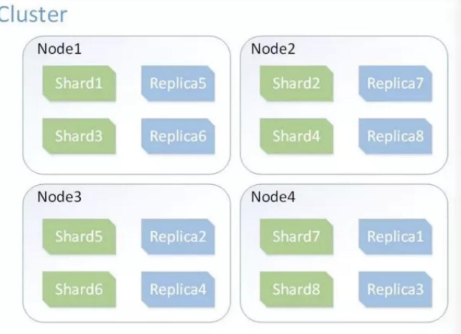
ES 架构
索引分片,实现分布式;索引备份,实现高可用;API更简单、更高级。
PageRank算法

Doris KV引擎
需求现状
1、网站关键业务有许多海量KV数据存储和访问需求;
2、多套KV方案,接口不统一,运维成本高;
3、扩容困难、写性能低、实时性低、使用复杂
产品需求
产品定位:海量分布式透明化KV存储引擎
解决问题:解决扩容迁移复杂、维护困难问题;海量数据数据存储数TB级,增长也快。
产品目标
功能目标:KV存储引擎,逻辑管理,二级索引
非功能目标:海量存储、伸缩性、高可用、高性能、高扩展、低运维成本-易管理监控
约束:最终一致性
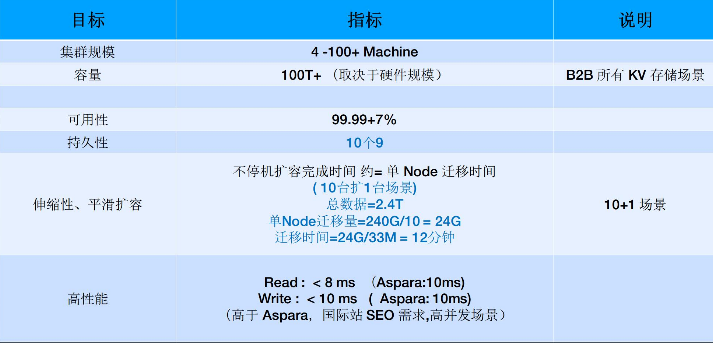
技术指标
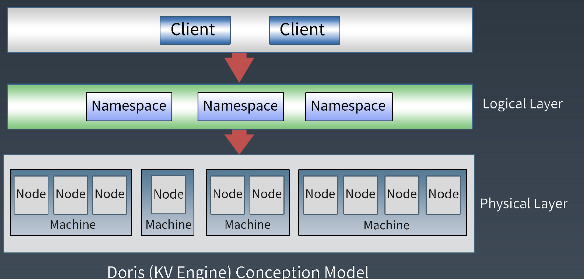
逻辑架构
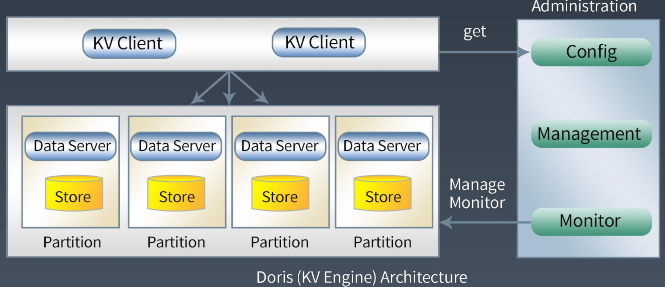
存储模型
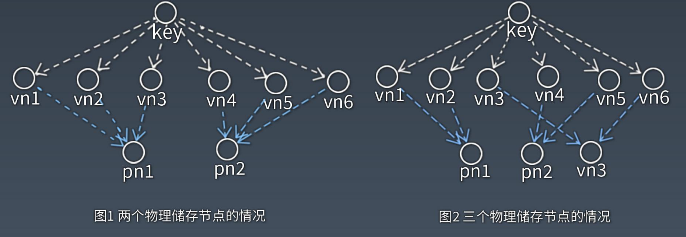
关键技术点-数据分区
基于虚拟节点的分区算法:X/(M+X)
关键技术点-临时失效
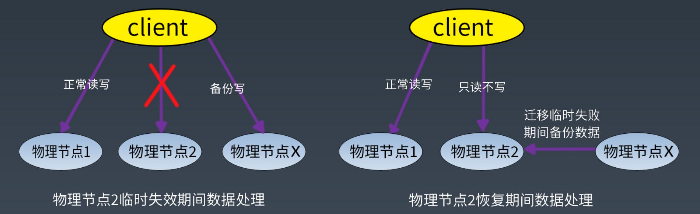
关键技术点-永久失效
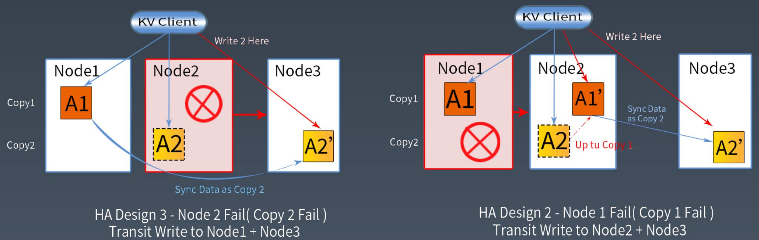
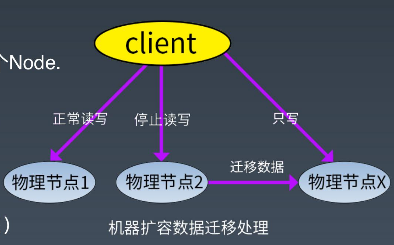
关键技术点-扩容数据迁移
专利申请,保护知识产权,项目团队荣誉。

还未添加个人签名 2018.05.16 加入
还未添加个人简介









评论