构建 Apache Flink 开发环境 (四)

写在前面:
大家好,我是强哥,一个热爱分享的技术狂。目前已有 12 年大数据与 AI 相关项目经验, 10 年推荐系统研究及实践经验。平时喜欢读书、暴走和写作。
业余时间专注于输出大数据、AI 等相关文章,目前已经输出了 40 万字的推荐系统系列精品文章,强哥的畅销书「构建企业级推荐系统:算法、工程实现与案例分析」已经出版,需要提升可以私信我呀。如果这些文章能够帮助你快速入门,实现职场升职加薪,我将不胜欢喜。
想要获得更多免费学习资料或内推信息,一定要看到文章最后喔。
内推信息
如果你正在看相关的招聘信息,请加我微信:liuq4360,我这里有很多内推资源等着你,欢迎投递简历。
免费学习资料
如果你想获得更多免费的学习资料,请关注同名公众号【数据与智能】,输入“资料”即可!
学习交流群
如果你想找到组织,和大家一起学习成长,交流经验,也可以加入我们的学习成长群。群里有老司机带你飞,另有小哥哥、小姐姐等你来勾搭!加小姐姐微信:epsila,她会带你入群。
现在我们已经了解了前三章涉及到的很多理论知识,是时候开始动手操作一下了,我们准备开始开发第一个 Flink 应用程序了! 在本章中,你将学习如何设置开发、运行和调试 Flink 应用程序的环境。 我们将首先讨论需要准备好必需的软件,以及从哪里可以获得这本书所用到的示例代码。 通过使用这些示例,我们将了解如何在 IDE 中执行和调试 Flink 应用程序。 最后,我们展示了如何创建一个 Flink Maven 项目,这是构建一个新的 Flink 项目的第一步。
必需软件
首先,让我们讨论开发 Flink 应用程序所需的软件。 你可以在 Linux、MacOS 和 Windows 上开发和执行 Flink 应用程序。 但是,基于 UNIX 的环境是最合适的,主要是由于 UNIX 环境拥有最丰富的工具支持,因此这个环境是大多数 Flink 开发人员首选的。 我们将在本章的其余部分中基于一个假设出来的 UNIX 的环境来运行 Flink 项目。 作为 Windows 用户,你可以使用 Linux(WSL)、Cygwin 或 Linux 虚拟机的 Windows 子系统在 UNIX 环境中运行 Flink。
Flink 的 DataStream API 可用于 Java 和 Scala 开发。 因此,需要一个 Java JDK 环境来实现 Flink 数据流应用程序,一般选 JDK 8(或更高版本)。 单纯的 JRE 环境是不够的。
假设我们安装了以下软件,尽管有一些不是开发 Flink 应用程序所严格要求的,但是一般都需要具备:
l Apache Maven 3.x 版本,本书的代码示例使用 Maven 构建管理,而且 Flink 还提供了 Maven 项目原型去构建一个新的 Flink Maven 项目。
l 用于开发 Java 或者 Scala 的 IDE 工具,通常选择具有丰富插件支持的 IntelliJ IDEA、Eclipse 或 Netbeans 等 IDE 工具(例如 Maven、Git 和 Scala 支持),这里我们建议使用 IntelliJ IDEA。你可以按照 IntelliJ IDEA(https://www.jetbrains.com/idea/download/)网站上的说明去下载和安装它。
在 IDE 中运行和调试 Flink 程序
即使 Flink 是一个分布式数据处理系统,你通常会在本地机器上开发和运行初始化测试。 这使开发变得更容易,并简化了集群部署,因为你可以在集群环境中运行完全相同的代码,而无需进行任何更改。 在下面,我们将描述如何获取我们在这里使用的代码示例,如何将它们导入 IntelliJ,如何运行示例应用程序,以及如何调试它。
在 IDE 中导入书中示例
本书的代码示例托管在 GitHub 上。 在https://github.com/streaming-with-flink上,你将找到一个包含 Scala 示例的项目仓库和一个包含 Java 示例的项目仓库。 我们将使用 Scala 仓库进行设置,但如果你更喜欢 Java,你也可以按照说明进行设置。
打开终端并运行下面的 Git 命令,以将 scala 示例仓库克隆到本地计算机。
git clone https://github.com/streaming-with-flink/examples-scala
你也可以从 Github 上下载样例源代码的 zip 文件。
> wget https://github.com/streaming-with-flink/examples-
scala/archive/master.zip
> unzip master.zip
本书的示例是一个 Maven 项目。 你可以在 src / 目录下找到按章节分组的源代码:

现在打开 IDE 并导入 Maven 项目,大多数 IDE 的导入步骤都类似。 在下文中,我们将详细解释 IntelliJ 如何操作这一步骤。
打开文件导航栏,新建文件,从已有的项目导入,找到本书示例所在的文件夹,选择 Maven 项目模型,点击下一步,选择要导入的项目(应该只有一个),设置 SDK,并为项目命名,单机完成即可(File -> New-> Import project from external model -> Maven -> Next ->Root directory -> Select Maven projects to import -> Next -> set SDK -> Project name -> Finish):
图 4-1 、图 4-2 和图 4-3 体现了项目导入的部分操作步骤。


完成这一步就算是大功告成,接下来你就可以开始随意浏览和查阅本书的示例代码。
在 IDE 中运行 Flink 程序
接下来,让我们在 IDE 中运行本书的一个示例应用程序,双击 Shit 键,搜索 AverageSensorReadings 类并打开它。正如第 1 章所述,该程序为多个热传感器生成模拟数据,作为事件输入源,并将事件中的温度从华氏温度转换为摄氏温度,并计算每个传感器每秒的平均温度。程序的结果被发送到标准输出。就像许多 DataStream 应用程序一样,程序的发生器、接收器和算子操作都是在 AverageSensorReadings 类的 main()方法中组合起来的。
通过运行该类的 main()方法启动应用程序,程序的输出被写入到 IDE 的标准输出窗口(或控制台)。一开始输出的日志信息会提示程序并行算子任务不同阶段的状态信息,例如 SCHEDULING, DEPLOYING 和 RUNNING 等状态。一旦所有任务都启动并运行,程序就会开始生成传感器模拟数据,看起来类似于以下几行的结果:
2> SensorReading(sensor_31,1515014051000,23.924656183848732)
4> SensorReading(sensor_32,1515014051000,4.118569049862492)
1> SensorReading(sensor_38,1515014051000,14.781835420242471)
3> SensorReading(sensor_34,1515014051000,23.871433252250583)
程序会不断模拟生成新事件,进一步处理它们,并且会每秒钟得到新的结果(即平均温度),直到你停止程序为止。
现在让我们快速讨论一下这个过程背后究竟发生了什么。如第 3 章所述,Flink 应用程序首先被提交给 JobManager (master,也就是程序的管理者),它将执行任务分配给一个或多个 TaskManager (workers,实际执行计算任务的进程)。由于 Flink 是一个分布式系统,JobManager 和 TaskManagers 往往作为独立的 JVM 进程在不同的机器上运行。通常来说,程序的 main()方法负责组装数据流,并在调用 StreamExecutionEnvironment.execute()方法时将其提交给远程 JobManager。
但是,还有另一种模式,在这种模式中,当我们调用 execute()方法时,会在同一 JVM 进程中将 JobManager 和 TaskManager(默认情况下,具有与可用 CPU 线程一样多的插槽)作为独立的线程启动。因此,整个 Flink 应用程序是多线程的,并在同一个 JVM 进程中执行。这种模式适用于在 IDE 中执行 Flink 程序。
在 IDE 中调试 Flink 程序
由于是单个 JVM 执行模式,所以你也可以在 IDE 中调试 Flink 应用程序,跟 IDE 中的其他程序一样。你可以像在正常情况下那样在代码中定义断点并调试应用程序。
然而,在 IDE 中调试 Flink 应用程序时,有需要注意以下几个方面:
除非你在程序中指定了并行度,不然的话程序默认由与本机 CPU 线程数量相同的线程执行,所以,你应该意识到你可能调试的是一个多线程程序。
与通过将 Flink 程序发送到远程作业管理器来执行 Flink 程序相比,该应用程序是在单个 JVM 中执行的,因此,某些像类加载这样的问题不能正确调试。
尽管程序是在单个 JVM 中执行的,但是记录被序列化以用于跨线程通信,并且可能持久化内部状态。
创建 Flink Maven 项目
将本书的示例仓库导入 IDE 以体验 Flink 项目是很好的开始。但是除此之外,你还应该知道如何从头创建一个全新的 Flink 项目。
Flink 提供了 Maven 原型,用于为 Java 或 Scala Flink 应用程序生成 Maven 项目。首先打开终端,运行以下命令创建一个 Flink Maven Quickstart Scala 项目,作为 Flink 应用程序的起点:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-scala \
-DarchetypeVersion=1.7.1 \
-DgroupId=org.apache.flink.quickstart \
-DartifactId=flink-scala-project \
-Dversion=0.1 \
-Dpackage=org.apache.flink.quickstart \
-DinteractiveMode=false
这将在一个名为 flink-scala-project 的文件夹中为 Flink 1.7.1 版本你的 Flink 生成一个 Maven 项目。你可以通过更改上述 mvn 命令的各个参数来更改 Flink 版本、group 和 artifact ID、版本和生成的包。最终生成的文件夹包含一个 src/文件夹和一个 pom.xml 文件。src/ 文件夹的结构如下:
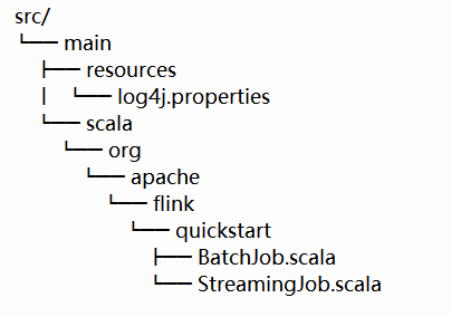
该项目包含两个样例类文件,BatchJob.scala 和 StreamingJob.scala,对应批处理作业和流处理作业,作为项目的启动文件,如果你觉得不需要,可以选择删除它们。
可以按照上一节中描述的步骤在 IDE 中导入项目,也可以执行以下命令来构建 JAR 文件:
mvn clean package -Pbuild-jar
如果命令成功完成,你将在项目文件夹中找到一个新的目标文件夹(target)。 该文件夹包含一个文件 flink-scala-project-0.1.jar,它是 Flink 应用程序的 JAR 文件。 生成的 pom.xml 文件还包含关于如何向项目添加新依赖项的说明。
小结
在本章中,我们学习了如何设置开发和调试 Flink 数据流应用程序的环境,以及如何使用 Flink 的 Maven 原型生成 Maven 项目。 显而易见的下一步将是学习如何实际实现数据流程序。第 5 章将向你介绍 Data Stream API 的基本使用,第 6、7 和 8 章将为你介绍需要了解的关于基于时间的算子、有状态函数以及源连接器(source connector)和接收端连接器(sink connector)的所有内容。
注意:我们同样提供了基于 Java 实现的样例仓库。
版权声明: 本文为 InfoQ 作者【数据与智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/b63dcfe16bc7724af8e9438bf】。文章转载请联系作者。

还未添加个人签名 2018.05.14 加入
公众号【数据与智能】主理人,个人微信:liuq4360 12 年大数据与 AI相关项目经验, 10 年推荐系统研究及实践经验,目前已经输出了40万字的推荐系统系列精品文章,并有新书即将出版。









评论