本文首发于个人博客,文章链接为:https://blog.d77.xyz/archives/f10ab485.html
前言
上一篇文章讲了如何使用 scrapy 和 selenium 搭配来爬取数据,这篇文章来写一下如何用 selenium 来爬取使用 Ajax 加载数据的网站并且过掉反爬。
环境配置
本篇文章中所用到的环境都已经在上篇文章中配置好了,不知道如何使用的小伙伴可以移步上一篇文章。
开始爬取
antispider1
antispider1 说明如下:
对接 WebDriver 反爬,检测到使用 WebDriver 就不显示页面,适合用作 WebDriver 反爬练习。
WebDriver 反爬,说明使用 selenium 会被检测到。
先使用上篇文章中提到的方法来尝试下。
import scrapy
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
class AntiSpider(scrapy.Spider):
name = 'antispider1'
def start_requests(self):
urls = ['https://antispider1.scrape.center/']
for a in urls:
yield SeleniumRequest(url=a, callback=self.parse, wait_time=8, wait_until=EC.presence_of_element_located(
(By.CLASS_NAME, 'm-b-sm')))
def parse(self, response, **kwargs):
print(response.text)
input()
运行代码,selenium 会抛出一个超时异常,因为在指定的时间内未搜索到指定的标签,所以报了超时错误。
selenium.common.exceptions.TimeoutException: Message:
同时查看页面,很明显被检测到了,页面内容都被 JS 删掉了,接下来查找检测点,过掉反爬。
先删除 selenium 等待元素的代码,防止抛异常导致浏览器退出,让程序无限等待在 input 函数上,爬虫不会退出,浏览器也不会被关掉,方便调试。
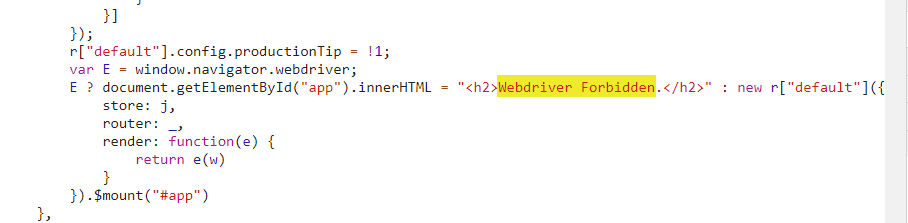
因为这种反爬检测没有比较好的入手点,所以直接打开浏览器控制台,全局搜索字符串 Webdriver Forbidden,只找到了一处。
看样子是一个三元运算符,通过判断 window.navigator.webdriver 的值来确定是显示反爬界面还是正常加载数据。
执行 window.navigator.webdriver 可以看到它的值为 true,有两个方法可以修改它的返回值:
通过 window.navigator.webdriver = undefined
Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});
在最新版的 Chrome 上测试过这两种方法都已经失效了,直接赋值的方法虽然执行成功但是并不能修改返回值,通过修改属性的方式虽然可以修改返回值,但是在新建页面或者访问一个新的 URL 时 window.navigator.webdriver 会自动变回 true,需要在每个页面加载前执行才可以,所以问题就变成了如何在页面加载之前执行自定义的命令。
在 selenium 中可以使用 CDP(即 Chrome Devtools-Protocol)Chrome 开发工具协议可以解决这个问题,CDP 命令可以在每个页面加载前加载自定义的代码,在 CDP 中这个命令叫做 Page.addScriptToEvaluateOnNewDocument。
通过 execute_cdp_cmd 函数执行 CDP 命令,代码为:
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})"""
})
这样只需要执行一次,Chrome 就会在每次加载页面前自动执行提前定义好的指令了。
方法有了,如何集成到现有的框架中呢?因为现在使用了第三方包集成 selenium,不能直接修改第三方包的代码,而 driver 对象又掌管在第三方包中,我们可能拿不到这个对象,怎么才能执行 CDP 命令呢?
这时候就需要去翻阅第三方包的代码,看看作者将 driver 对象保存到了哪里,如何才能获取到它。
先看第一个文件(scrapy_selenium/http.py)
class SeleniumRequest(Request):
"""Scrapy ``Request`` subclass providing additional arguments"""
def __init__(self, wait_time=None, wait_until=None, screenshot=False, script=None, *args, **kwargs):
self.wait_time = wait_time
self.wait_until = wait_until
self.screenshot = screenshot
self.script = script
super().__init__(*args, **kwargs)
只是继承了 scrapy 的 Request 类,是为了方便传递四个参数给到 driver 对象,再来看另一个文件(scrapy_selenium/middlewares.py)
class SeleniumMiddleware:
"""Scrapy middleware handling the requests using selenium"""
def __init__(self, driver_name, driver_executable_path, driver_arguments,
browser_executable_path):
webdriver_base_path = f'selenium.webdriver.{driver_name}'
driver_klass_module = import_module(f'{webdriver_base_path}.webdriver')
driver_klass = getattr(driver_klass_module, 'WebDriver')
driver_options_module = import_module(f'{webdriver_base_path}.options')
driver_options_klass = getattr(driver_options_module, 'Options')
driver_options = driver_options_klass()
if browser_executable_path:
driver_options.binary_location = browser_executable_path
for argument in driver_arguments:
driver_options.add_argument(argument)
driver_kwargs = {
'executable_path': driver_executable_path,
f'{driver_name}_options': driver_options
}
self.driver = driver_klass(**driver_kwargs)
@classmethod
def from_crawler(cls, crawler):
"""Initialize the middleware with the crawler settings"""
driver_name = crawler.settings.get('SELENIUM_DRIVER_NAME')
driver_executable_path = crawler.settings.get('SELENIUM_DRIVER_EXECUTABLE_PATH')
browser_executable_path = crawler.settings.get('SELENIUM_BROWSER_EXECUTABLE_PATH')
driver_arguments = crawler.settings.get('SELENIUM_DRIVER_ARGUMENTS')
if not driver_name or not driver_executable_path:
raise NotConfigured(
'SELENIUM_DRIVER_NAME and SELENIUM_DRIVER_EXECUTABLE_PATH must be set'
)
middleware = cls(
driver_name=driver_name,
driver_executable_path=driver_executable_path,
driver_arguments=driver_arguments,
browser_executable_path=browser_executable_path
)
crawler.signals.connect(middleware.spider_closed, signals.spider_closed)
return middleware
def process_request(self, request, spider):
"""Process a request using the selenium driver if applicable"""
if not isinstance(request, SeleniumRequest):
return None
self.driver.get(request.url)
for cookie_name, cookie_value in request.cookies.items():
self.driver.add_cookie(
{
'name': cookie_name,
'value': cookie_value
}
)
if request.wait_until:
WebDriverWait(self.driver, request.wait_time).until(
request.wait_until
)
if request.screenshot:
request.meta['screenshot'] = self.driver.get_screenshot_as_png()
if request.script:
self.driver.execute_script(request.script)
body = str.encode(self.driver.page_source)
request.meta.update({'driver': self.driver})
return HtmlResponse(
self.driver.current_url,
body=body,
encoding='utf-8',
request=request
)
def spider_closed(self):
"""Shutdown the driver when spider is closed"""
self.driver.quit()
是一个下载中间件的类,代码比较长,一块一块的看。
先来看 from_crawler 方法,通过配置文件获取到定义好的配置,然后创建当前类的对象,将爬虫关闭的信号连接到 spider_closed 方法上, 在爬虫关闭时及时执行 quit 方法关闭浏览器。
再来看初始化方法,接受四个参数,通过接收到的参数使用 import_module 方法来导入类,最后添加一些参数创建 driver 对象赋值给 self.driver,到这里就找到了 driver,可以想办法执行 CDP 方法了。
最后就是 process_request 方法,使用 get 方法来获取网页源代码,将 request 对象的 cookie 都添加到 driver 对象中,根据参数值的不同执行不同的动作,等待、截图、执行代码等等,通过 meta 属性公开了 driver 对象,方便在请求完页面数据后使用其他中间件来进行点击、滑动、翻页等等动作,最后返回一个 THML 响应对象。
虽然最后通过 meta 属性公开了 driver 对象,但这是在获取到网页源代码之后了,我们需要在网页加载前执行对应 CDP 命令才可以。
为了在页面加载之前执行命令,所以我们需要自定义一个自己的下载中间件,继承 SeleniumMiddleware 类,修改父类初始化方法。
在 middlewares.py 文件中添加以下代码,别忘了导入 SeleniumMiddleware。
class MyDownloadMiddleware(SeleniumMiddleware):
def __init__(self, driver_name, driver_executable_path, driver_arguments,
browser_executable_path):
super(MyDownloadMiddleware, self).__init__(driver_name, driver_executable_path, driver_arguments,
browser_executable_path)
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})"""
})
先执行 super 方法初始化父类,再使用父类创建好的 driver 对象执行 CDP 命令。别忘了去 settings.py 中修改下载中间件的值为:
DOWNLOADER_MIDDLEWARES = {
'learnscrapy.middlewares.MyDownloadMiddleware': 800
}
重新运行爬虫,应该可以看到页面正常加载了,并且网页源代码也可以正常获取到了,之后再补充上具体的解析代码即可。
class AntiSpider(scrapy.Spider):
name = 'antispider1'
def start_requests(self):
urls = ['https://antispider1.scrape.center/']
for a in urls:
yield SeleniumRequest(url=a, callback=self.parse, wait_time=3, wait_until=EC.presence_of_element_located(
(By.CLASS_NAME, 'm-b-sm')))
def parse(self, response, **kwargs):
result = response.xpath('//div[@class="el-card item m-t is-hover-shadow"]')
for a in result:
item = SSR1ScrapyItem()
item['title'] = a.xpath('.//h2[@class="m-b-sm"]/text()').get()
item['fraction'] = a.xpath('.//p[@class="score m-t-md m-b-n-sm"]/text()').get().strip()
item['country'] = a.xpath('.//div[@class="m-v-sm info"]/span[1]/text()').get()
item['time'] = a.xpath('.//div[@class="m-v-sm info"]/span[3]/text()').get()
item['date'] = a.xpath('.//div[@class="m-v-sm info"][2]/span/text()').get()
url = a.xpath('.//a[@class="name"]/@href').get()
print(response.urljoin(url))
yield SeleniumRequest(url=response.urljoin(url), callback=self.parse_person, meta={'item': item},
wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
def parse_person(self, response):
item = response.meta['item']
item['director'] = response.xpath(
'//div[@class="directors el-row"]//p[@class="name text-center m-b-none m-t-xs"]/text()').get()
yield item
完整代码详见https://github.com/libra146/learnscrapy/tree/antispider1
其实在页面加载之前执行自定义的 JS 代码还有另外一种方法,那就是 Chrome 拓展,可以使用类似于油猴插件的拓展来实现,限于篇幅问题这里就不演示了。
antispider2
antispider2 说明如下:
对接 User-Agent 反爬,检测到常见爬虫 User-Agent 就会拒绝响应,适合用作 User-Agent 反爬练习。
既然是 User-Agent 反爬,那么就使用正常的 User-Agent 就可以了,暂时不需要用到 selenium。
本来是想用 fake-useragent 的,后来看了下项目两年多没更新了,而且不是随机生成,只是从网上下载一些 UA,然后随机选取而已,这样的话没必要引入一个依赖了,自己将 UA 爬下来然后随机取就好了。
在下载中间件中添加以下代码:
class Antispider2DownloaderMiddleware(LearnscrapyDownloaderMiddleware):
def __init__(self):
super(Antispider2DownloaderMiddleware, self).__init__()
with open('ua.json', 'r') as f:
self.ua = json.load(f)
def process_request(self, request, spider):
request.headers.update({'User-Agent': random.choice(self.ua)})
读取本地文件,然后在 process_request 函数中每次随机去一个 UA 更新默认的 UA 即可。
完整代码详见https://github.com/libra146/learnscrapy/tree/antispider2
antispider3
antispider3 说明如下:
对接文字偏移反爬,所见顺序并不一定和源码顺序一致,适合用作文字偏移反爬练习。
网站使用到了文字偏移反爬,猜测应该使用了 CSS 控制网页文字的位置来达到反爬的目的。
看了下渲染后的网页源代码,的确是通过改变 style 的值来使文字发生偏移的,处理方法就是将文字和 style属性一起获取,然后按照 style 升序排列就可以得到正确的结果:思维改变生活。往下看了看有的文字有偏移有的文字没有偏移,需要在代码里进行判断。
开始写代码,解析 HTML,获取数据,顺便获取对应的 style,处理后得到顺序正确的数据。
class AntiSpider(scrapy.Spider):
name = 'antispider3'
def start_requests(self):
urls = ['https://antispider3.scrape.center/']
for a in urls:
yield SeleniumRequest(url=a, callback=self.parse, wait_time=3, wait_until=EC.presence_of_element_located(
(By.CLASS_NAME, 'm-b-sm')))
def parse(self, response, **kwargs):
result = response.xpath('//div[@class="el-card__body"]')
for a in result:
item = Antispider3ScrapyItem()
chars = {}
if r := a.xpath('.//h3[@class="m-b-sm name"]//span'):
for b in r:
chars[b.xpath('.//@style').re(r'\d\d?')[0]] = b.xpath('.//text()').get().strip()
item['title'] = ''.join(list(zip(*sorted(chars.items(), key=lambda i: i[0])))[1])
else:
item['title'] = a.xpath('.//h3[@class="name whole"]/text()').get()
item['author'] = a.xpath('.//p[@class="authors"]/text()').get().strip()
url = a.xpath('.//a/@href').get()
print(response.urljoin(url))
yield SeleniumRequest(url=response.urljoin(url), callback=self.parse_person, meta={'item': item},
wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
def parse_person(self, response):
item = response.meta['item']
item['price'] = response.xpath('//p[@class="price"]/span/text()').get()
item['time'] = response.xpath('//p[@class="published-at"]/text()').get()
item['press'] = response.xpath('//p[@class="publisher"]/text()').get()
item['page'] = response.xpath('//p[@class="page-number"]/text()').get()
item['isbm'] = response.xpath('//p[@class="isbn"]/text()').get()
yield item
通过判断对应元素是否存在的方式来判断 title 是否被反爬,在判断分支中进行不同的处理。
由于时间关系代码中只爬取了一页数据,证明方法可行就可以。
有个插曲,其实这个网站的数据也是通过 Ajax 请求的, 也就是说直接从接口请求就可以获取到数据,不用处理反爬措施,这里是为了学习文字偏移反爬才从 HTML 中获取数据。
完整代码详见https://github.com/libra146/learnscrapy/tree/antispider3
antispider4
antispider4 说明如下:
对接字体文件反爬,显示的内容并不在 HTML 内,而是隐藏在字体文件,设置了文字映射表,适合用作字体反爬练习。
字体反爬,这种情况下需要先找到字体映射表,并且解析字体映射表中的文字和代码的对应关系才可以正常爬取。
但是我在看到这里之后我发现这好像不是字体反爬😂(虽然这个网站的确有一个单独的字体文件),数字内容被放在了 CSS 样式表文件中,虽然我是第一次见到这种反爬措施,但是我认为叫它 CSS 反爬好像更合理一些。
不知道是不是作者搞错了的原因,这里暂且当作 CSS 反爬来处理吧。
这种反爬措施需要将 HTML 源码中对应数字的 class 的值都抓出来,然后将 CSS 文件中对应的 value 替换就可以了,所以首先需要处理的是 CSS 文件,而不是 HTML。
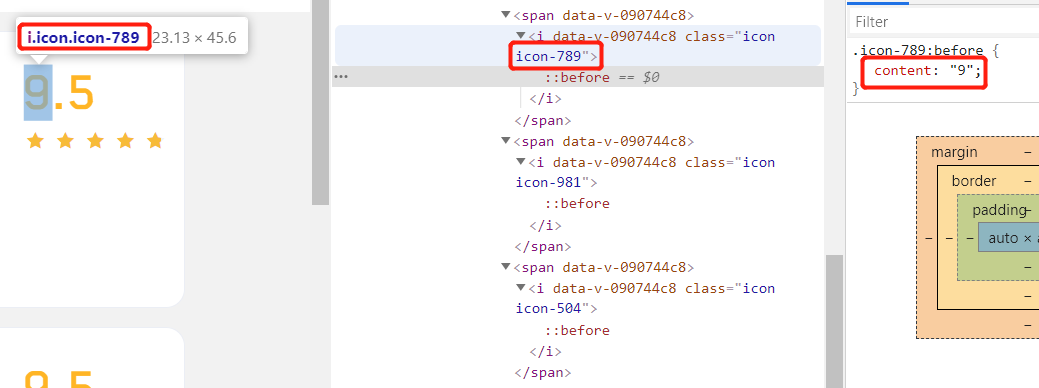
查了下,这种使用方式叫隐式 Style–CSS.
CSS中,::before 创建一个伪元素,其将成为匹配选中的元素的第一个子元素。常通过 content 属性来为一个元素添加修饰性的内容。
class AntiSpider(scrapy.Spider):
name = 'antispider4'
css = {}
def start_requests(self):
urls = ['https://antispider4.scrape.center/css/app.654ba59e.css']
for a in urls:
yield Request(url=a, callback=self.parse_css)
def parse_css(self, response):
result = re.findall(r'\.(icon-\d*?):before{content:"(.*?)"}', response.text)
for key, value in result:
self.css[key] = value
print(self.css)
yield SeleniumRequest(url='https://antispider4.scrape.center/', callback=self.parse_data,
wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
def parse_data(self, response):
result = response.xpath('//div[@class="el-card item m-t is-hover-shadow"]')
for a in result:
item = Antispider4ScrapyItem()
item['title'] = a.xpath('.//h2[@class="m-b-sm"]/text()').get()
if r := a.xpath('.//p[@class="score m-t-md m-b-n-sm"]//i'):
item['fraction'] = ''.join([self.css.get(b.xpath('.//@class').get()[5:], '') for b in r])
item['country'] = a.xpath('.//div[@class="m-v-sm info"]/span[1]/text()').get()
item['time'] = a.xpath('.//div[@class="m-v-sm info"]/span[3]/text()').get()
item['date'] = a.xpath('.//div[@class="m-v-sm info"][2]/span/text()').get()
url = a.xpath('.//a[@class="name"]/@href').get()
print(response.urljoin(url))
yield SeleniumRequest(url=response.urljoin(url), callback=self.parse, meta={'item': item},
wait_time=3, wait_until=EC.presence_of_element_located((By.CLASS_NAME, 'm-b-sm')))
def parse(self, response, **kwargs):
item = response.meta['item']
item['director'] = response.xpath(
'//div[@class="directors el-row"]//p[@class="name text-center m-b-none m-t-xs"]/text()').get()
yield item
处理方式就是先将 CSS 文件中所需要用到的内容使用正则匹配出来,在需要替换的地方直接替换就可以得到正确的分数数据了。
完整代码详见https://github.com/libra146/learnscrapy/tree/antispider4
总结
本篇文章只写针对 selenium 出现的各种反爬措施,针对 IP 地址或者账号进行的反爬的内容下篇文章来写。
网页获取数据的方式无外乎就那几种,HTML,JS,CSS,Ajax等,所以在遇到反爬时先找数据是怎么被渲染出来的,剩下的问题就是处理数据,根据数据的来源进行针对性的处理。












评论