数仓规范篇 | 命名规范

一、通用命名规范
目前主流的命名方法大体分类:大驼峰命名法 (camelCase) 和小驼峰命名法 (snake_case),本规范要求使用小驼峰命名法 (snake_case),统一为小写字符,单词之间使用下划线隔开,贴源层字段可以不遵守,字段命名和源系统保持一致。
单词长度不超过 64 个字符,字段或者表命名小于 6 级
命名尽量做到见名知意,言简意赅,尽量使用英文以及符合业界要求的字符,特殊情况下可以使用汉语拼音缩写
尽量避免使用关键字,确实需要使用关键字情况下使用“`”转义
优先使用词根管理规范中已有的关键字,定期维护词根规范表
定期 review 新增命名使用的字段规范性
二、表命名规范
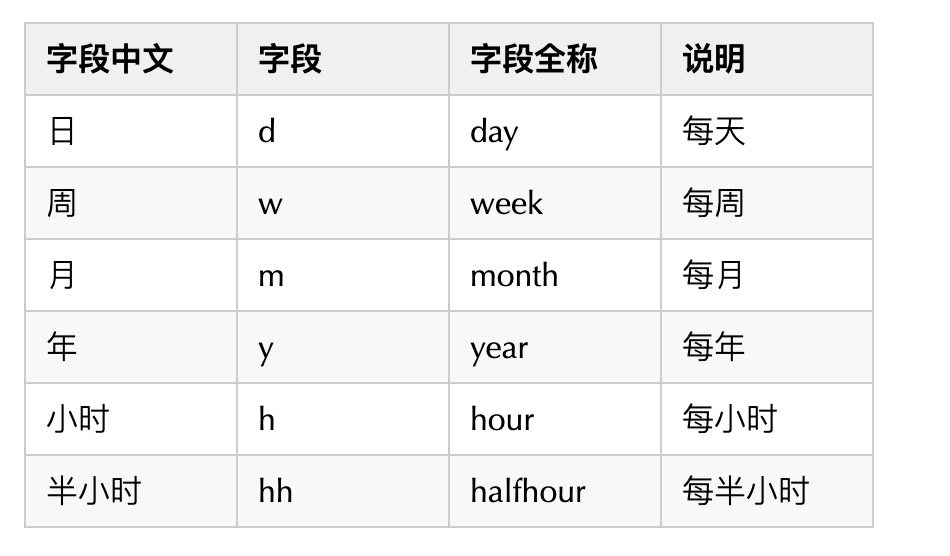
聚合粒度以及加工频率字段说明
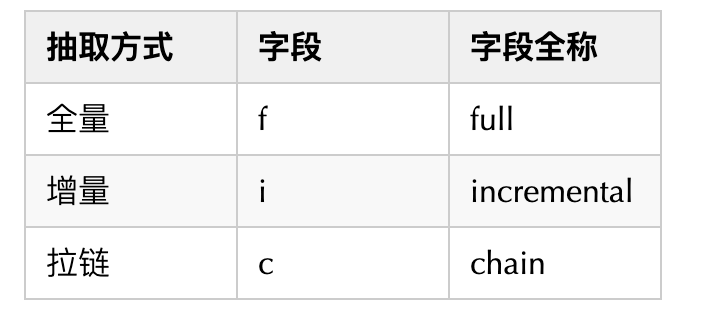
抽取方式字段说明
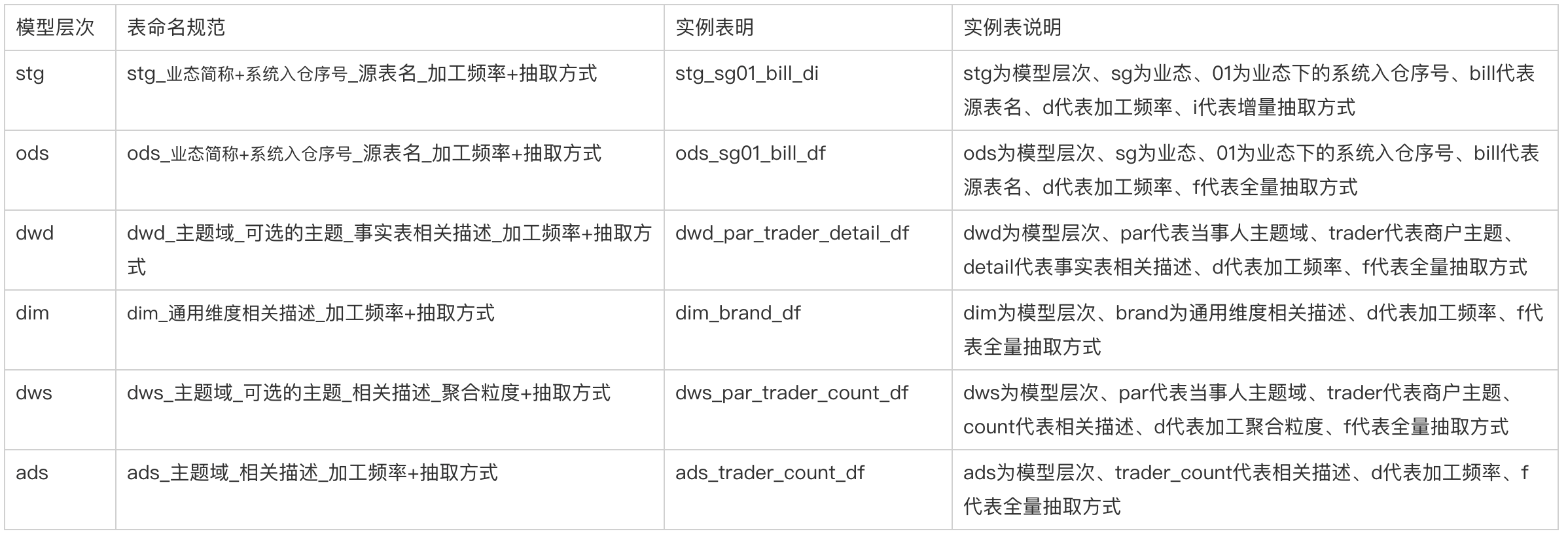
数据表命名规范详解
对于表名中统计周期和加工频率字段的补充说明
我们经常会发现聚合表的后缀会出现 _di 或者 _df,这里的 i 和 f 表示增量和全量,而 d 表示天,但是却又总是说不清楚它究竟是表示天级别的聚合粒度还是每天运行一次的加工频率。大多数情况下表的聚合粒度和它的调度周期是一致的,然而也确实存在例外的情况,在 dws 层你可能每天运行一个聚合到小时级粒度的数据,以观察每小时的走势。站在使用者的角度来看,他并不关心表的调度周期,只在乎这个表的聚合粒度。
所以我们尽量不将表使用无关的 ETL 信息暴露给使用者。在 dws 层的时间后缀只表示该表的聚合粒度,与 ETL 的调度周期无关。
三、字段命名规范
同名同义性是我们对字段命名的首要要求。如果两个字段名字一样,那么它们的含义应该是一样的;反之,如果两个字段名字不一样,那么它们的含义就一定是要有区别的。当这个要求放在单个主题域内的时候,还是容易实现的。当它推广到全域范围内,这个事情就会变得有些困难。
其次,字段名称清晰是另外一个要求。良好的字段命名应当是自解释的,如果看完字段的注释还无法理解甚至曲解字段的含义,那个可以说这个字段的命名和注释是不合格的。
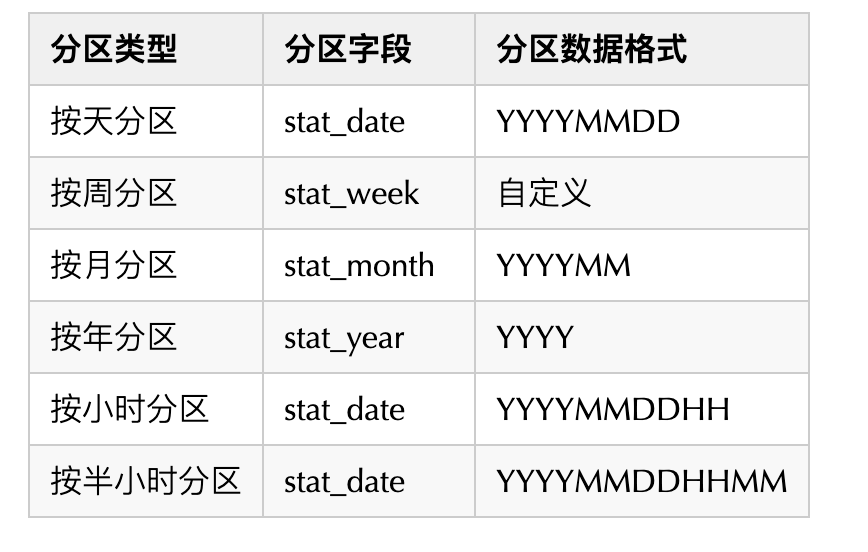
表分区字段说明
其他字段相关说明
数据表 etl 时间字段统一使用 etl_time
标志类型的字段,是否类型的,统一使用 int 类型,取值统一使用 0/1,0 代表否,1 代表是,不允许出现空值域(如果有空值则新增取值 2,代表未知)
字段命名规范中未说明的部分参照通用命名规范
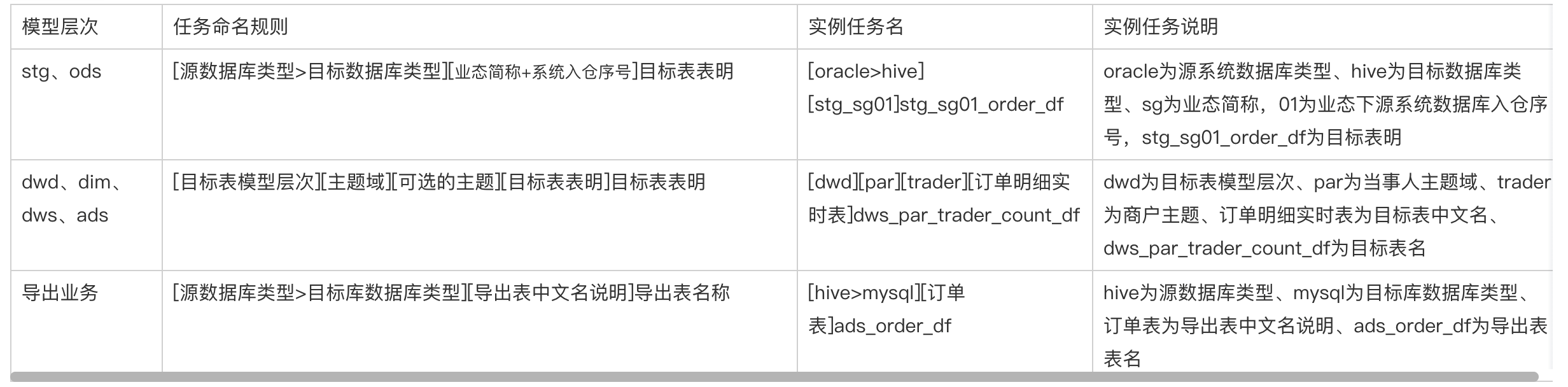
四、任务命名规范
任务是组成工作流的最小单位,也是完成一次 ETL 的最小开发单位,同时也是调度任务进行失败重试的最小单元。我们要求一个任务只写一张目标表,同时任务的命名中必须包含该目标表的表名。
本文使用 Markdown StudyTime 排版
版权声明: 本文为 InfoQ 作者【白程序员的自习室】的原创文章。
原文链接:【http://xie.infoq.cn/article/b2d1ff8561f159eb0886313a4】。文章转载请联系作者。

这里有程序员的故事,分享日常学习的技术。 2018.04.25 加入
公众号: 白程序员的自习室 博客地址:https://www.studytime.xin/









评论