架构师训练营 week6 作业
作业1 简述CAP
概述
在任意的分布式系统中,一致性(Consistency),可用性(Availability)和分区容错性(Partition-tolerance)这三种属性最多只能同时存在两个属性。
一致性(Consistency)
一致性,这里体现了这个存储系统对统一数据提供的读写操作是线性化的。如果客户端写入数据,并且写操作返回成功给客户端,那么在下一次读取的时候(下一次写入以前),如果系统返回了“非失败”的响应,就一定是读出了完整、正确(最新)的那份数据,而不会读取到过期数据,也不会读取到中间数据。
可用性(Availability)
可用性,体现的是存储系统持续提供服务的能力,
这里表现在两个方面:
返回“非失败”的响应,就是说,不是光有响应就可以了,系统得是在实实在在地提供服务,而不是在报错;
在限定时间内返回,就是说,这个响应是预期时间内返回的,而不出现请求超时。
请注意,这里说的是“非失败”响应,而并没有说“正确”的响应。也就是说,返回了数据,但可以是过期的,可以是中间数据,因为数据是否“正确”并非由可用性来保证,而是由一致性来保证的。系统的单个节点可能会在任意时间内故障、出错,但是系统总能够靠处于非失败(non-failing)状态的其它节点来继续提供服务,保证可用性。
分区容忍性(Partition Tolerance)
分区容忍性,体现了系统是否能够接纳基于数据的网络分区。只要出现了网络故障,无论什么原因导致某个节点和系统的其它节点失去了联系,节点间的数据同步操作无法被“及时”完成,那么,即便它依然可以对外(客户端)提供服务,网络分区也已经出现了。
当然,如果数据只有一份,不存在其它节点保存的副本,或不需要跨节点的数据共享,那么,这就不存在“分区”,这样的分布式存储系统也就不是 CAP 关心的对象。
如何使用 CAP 理论
只要有网络交互就一定会有延迟和数据丢失,而这种状况我们必须接受,还必须保证系统不能挂掉。所以就像我上面提到的,节点间的分区故障是必然发生的。也就是说,分区容错性(P)是前提,是必须要保证的。
现在就只剩下一致性(C)和可用性(A)可以选择了:要么选择一致性,保证数据正确;要么选择可用性,保证服务可用。那么 CP 和 AP 的含义是什么呢?
当选择了一致性(C)的时候,一定会读到最新的数据,不会读到旧数据,但如果因为消息丢失、延迟过高发生了网络分区,那么这个时候,当集群节点接收到来自客户端的读请求时,为了不破坏一致性,可能会因为无法响应最新数据,而返回出错信息。
当选择了可用性(A)的时候,系统将始终处理客户端的查询,返回特定信息,如果发生了网络分区,一些节点将无法返回最新的特定信息,它们将返回自己当前的相对新的信息。
误解
大部分人对 CAP 理论有个误解,认为无论在什么情况下,分布式系统都只能在 C 和 A 中选择 1 个。其实,在不存在网络分区的情况下,也就是分布式系统正常运行时(这也是系统在绝大部分时候所处的状态),就是说在不需要 P 时,C 和 A 能够同时保证。只有当发生分区故障的时候,也就是说需要 P 时,才会在 C 和 A 之间做出选择。而且如果读操作会读到旧数据,影响到了系统运行或业务运行(也就是说会有负面的影响),推荐选择 C,否则选 A。
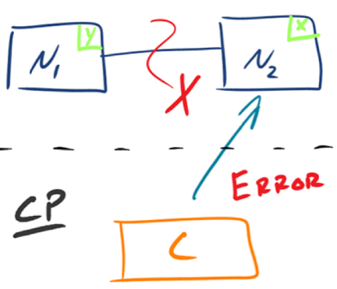
CP - Consistency/Partition Tolerance
如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
AP - Availability/Partition Tolerance
为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
存储技术的选择:NoSQL 三角形
CP 系统:Google BigTable, Hbase, MongoDB, Redis, MemCacheDB,这些存储架构都是放弃了高可用性(High Availablity)而选择 CP 属性的。
AP 系统:Amazon Dynamo 系统以及它的衍生存储系统 Apache Cassandra 和 Voldemort 都是属于 AP 系统
CA 系统:Apache Kafka 是一个比较典型的 CA 系统。
从图中可以发现,关系数据几乎都落在了 CA 一侧,但是请注意,技术也在不断更新,许多关系数据库如今也可以通过配置而形成其它节点的数据冗余;有时,我们则是在其上方自己实现数据冗余,比如配置数据库的数据同步到备份数据库。无论哪一种方法,一旦其它节点用于数据冗余的数据副本出现,这个存储系统就落到上述三角形的另外两边去了。
云上的 NoSQL 存储服务,多数落在了 AP 一侧,这也和 NoSQL 运动可用性优先保证而降级一致性的主题符合。比如 Amazon 的 DynamoDB,但是这个也是可以通过不同的设置选项来改变的,比如 DynamoDB 默认采用最终一致性,但也允许配置为强一致性,那时它就落到了 CP 上面。
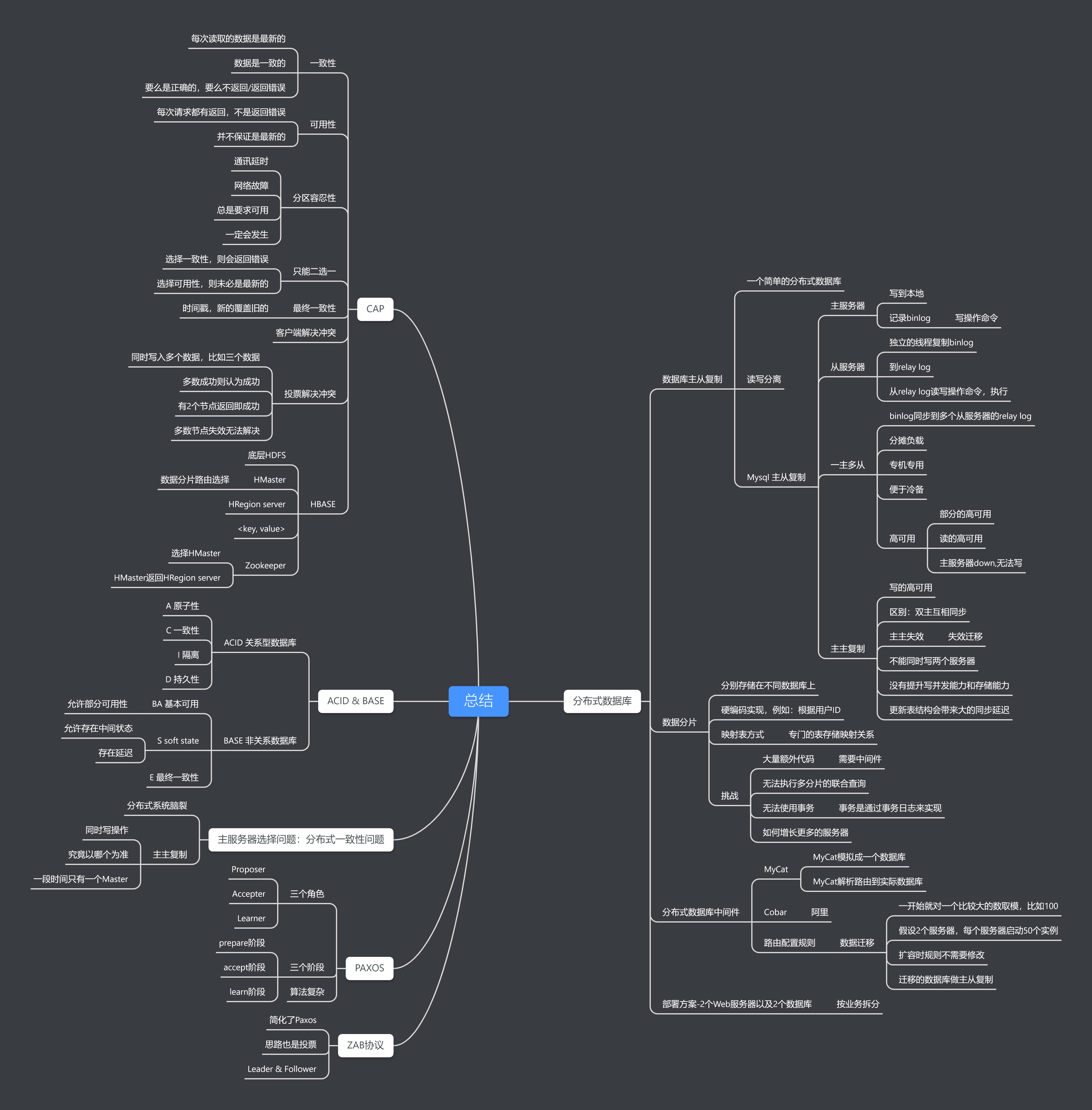
总结

还未添加个人签名 2019.04.11 加入
还未添加个人简介









评论