

Week8 学习总结
一、数据结构和算法
1、时间复杂度&空间复杂度
2、NP问题
1)P问题:能够在多项式时间复杂度内解决的问题
2)NP问题:能够在多项式时间复杂度内验证答案是否正确的问题
3)NP是否等于P问题:能够在多项式时间复杂度内验证的问题,是否可以在多项式时间复杂度内解决
3、常见数据结构
1)数组&链表
a. 数组更适合查找多的应用,链表更适合增删多的应用
2)hash表
a. 既能快速访问数据,又能快速增删数据
b. 数组与链表的结合
3)栈
4)队列
a. 队列搜索好友关系中最近的有钱人
b. 队列搜索最短路径
-->均类似用队列进行树的层次遍历
5)树
a. 二叉排序树
b. 平衡二叉树:增加节点时,需要O(1)的复杂度重新达到平衡;删除节点的时候,需要O(n)的复杂的度重新达到平衡
c. 红黑树:平衡性不如平衡二叉树,但是解决了删除节点复杂度高的问题
6)跳表:30分钟实现一个
4、常见算法
1)穷举算法
2)递归算法
a. 快速排序算法
3)贪心算法
a. 背包问题求解
b. 改进的弹性算法--迪杰斯特拉算法
4)动态规划
二、网络通信模型
1、一次网络请求的过程
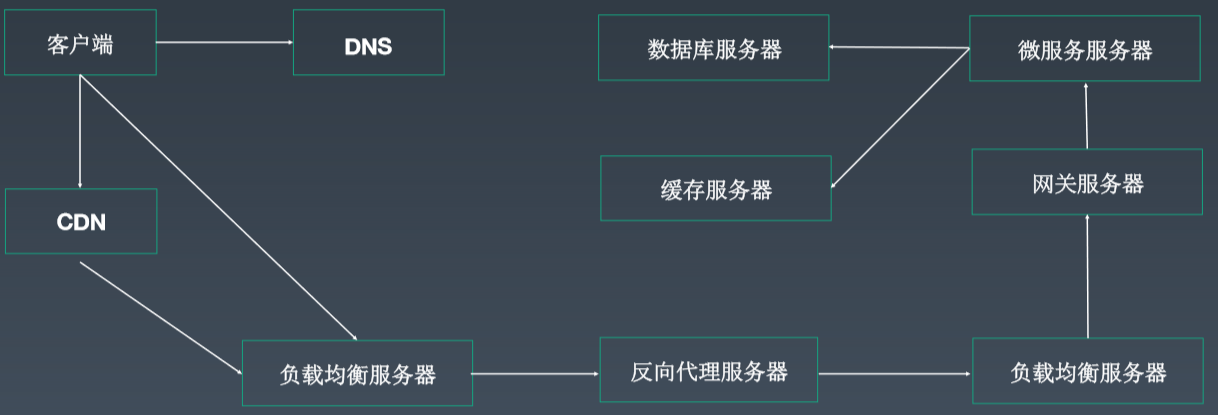
2、网络分层模型--OSI七层模型
1)物理层
2)数据链路层
a. 链路层的作用:基于MAC地址进行数据传输
b. 基于数据链路层的负载均衡:负载均衡服务器对目标服务器的MAC地址进行修改
-> 负载均衡服务器与应用服务器集群在内网中有相同的IP地址(虚拟IP、VIP),即有相同的虚拟IP地址,但是各自的MAC地址不同
-> 负载均衡服务器转发客户端请求时,直接修改目标MAC地址,请求的目的IP不会被改变
-> 负载均衡服务器的压力减小,其网络带宽不会成为性能瓶颈
3)网络层:IP地址
a. 网络层的作用:根据IP地址进行目标服务器的访问
b. 基于IP层的负载均衡:负载均衡服务器对请求的目标服务器的IP地址进行修改
-> 负载均衡服务器和应用服务器在内网中的地址各不相同
-> 负载均衡服务器转发客户端请求时,建立新的链接,源地址为自己,目标地址为应用服务器集群中的一台机器
-> 应用服务器处理后,负载均衡服务器收到响应,将响应中的目标地址改为自己,源地址改为客户端,然后返给客户端
-> 一起网络请求,涉及到一次请求转发;负载均衡服务器会成为性能瓶颈
4)传输层:TCP/UDP 协议
a. TCP协议:解决网络层的不可靠传输问题
b. 3次握手
c. 4次挥手
5)会话层
6)表示层
7)应用层
a. Http协议:请求类型、响应状态、协议版本
3、基于分层模型的网络调用
1)调用流程:发起时自上而下,一层层的加协议头;解析时自下而上,一层层的去协议头
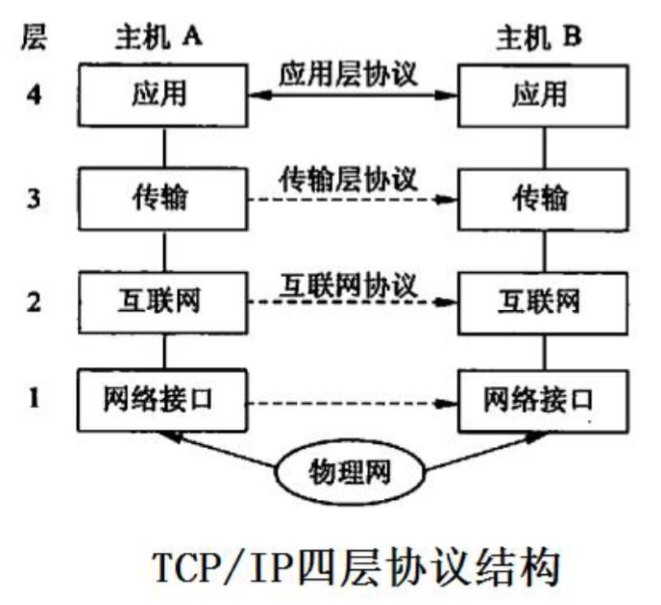
2)数据包格式

4、其他
1)TCP/IP四层模型
a. 网络访问层
b. 网络互联层
c. 传输层
d. 应用层
2)2层负载均衡、3层负载均衡......
三、网络IO模型
1、一次网络IO的请求过程
1)服务端启动,等待客户端发起并建立连接:socket.accept()、阻塞式等待
2)连接建立后,服务端等待客户端的请求数据:数据读取、socket.read()、阻塞式等待
3)服务端进行请求响应: 数据写入、socket.write()、阻塞式等待
2、多线程的IO模型
1)一个客户端请求对应一个处理线程,每个处理线程都是new出来的
2)一个客户端请求对应一个处理线程,处理线程是从线程池拿出来的
3、非阻塞IO模型
1)socket通信时的IO阻塞过程
a. accept阻塞:没有新的客户端连接时会阻塞
b. read阻塞:从socket缓冲区读不到指定长度的数据时会阻塞
c. write阻塞:socket缓冲区剩余长度不够时,写入数据到缓冲区会阻塞
2)阻塞IO & 非阻塞IO
a. 阻塞IO:进行IO操作时,用户线程会一直阻塞,知道读操作或写操作完成
b. 非阻塞IO:进行IO操作立即返回,用户线程不会阻塞等待
3)Java NIO:New IO、更高效、仍然是阻塞的
a. channel类似于socket
b. selector检查所有的channel,并且检查所有的事件:accpet事件、read可读事件、write可写事件
c. selector是NIO的核心,它使得一个线程可以处理多个连接
d. selectorl轮询事件的过程是阻塞的,但是这个阻塞影响不大,因为轮询事件的过程可以被任意的网络事件唤醒,如果selector被阻塞的话,表示没有任何的网络请求
e. 读取数据的时候,是从channel对应的buffer中读取,每次读取会立即返回,不会阻塞等待,所以执行读操作后,可能并没有读到数据
4、IO复用
1)pool & epoll
a. poll:如果连接量大的话,每次轮询所有的socket,判断socket(channel)是否有网络事件发生的过程,会有较大的性能损耗
b. epoll:有网络事件发生时,除了发送事件通知,还会将触发事件的socket放在文件列中,然后每次轮询的时候,只遍历对应的事件列表,避免轮询所有的socket对象
四、数据库基本概念
1、数据库架构
1)整体架构
a. 连接器
b. 语法分析器
c. 语义分析与优化器
d. 执行引擎

2)为什么PreparementStatement更好
a. 会提前生成好执行计划,当给定参数后,就可以直接执行,不用再执行语法分析、语义分析等操作
b. 防止SQL注入攻击:因为已经生成好了执行计划,不会再进行语法分析、语义分析等操作,所以传入的参数不会再进行语法分析
2、数据库索引
1)B-树与B+树
2)聚簇索引:主键索引、记录和索引一起存储在叶子节点、B+树
3)非聚簇索引:回表
4)合理使用索引
a. 不盲目添加索引
b. 删除无用的索引:索引的维护也是需要代价的,会导致增删的额外开销
c. 使用更小的数据类型:保证B+树的一个数据块能够存储更多的索引,避免树太高
3、数据库事务
1)事务的特性:ACID
2)事务的实现原理:事务日志
五、其他
1、学习知识的技巧
1)不单纯的学知识,学会推导知识,发掘知识背后的演绎过程
a. 知识都不是凭空出现的,一定是可以被推导,可以发掘其背后的演绎过程的
b. 学会推导知识,而不是什么都去学
2)轻松学习知识的方法
a. 先自己猜测,如果我做的话,我会怎么做?
b. 寻找资料进行验证,以及纠正自己的错误
c. 进行总结和思考:我的猜测和别人的实现有什么差别?别人为什么这么做?值得学习的地方是什么?
->学习知识,重要的是自己的思考&知识的推导过程,而不是单纯的知识学习!
->拔高自己的高度进行学习,站在更高的高度思考(系统的架构是怎样的?为什么会这样?)

还未添加个人签名 2018.05.02 加入
还未添加个人简介










评论