设计与思考,关于资源和生命周期(三)

系列文章:
一摘要
前面介绍了我们对资源的理解,和数据库连接池和线程池的实现原理,本篇将结合工作中一个真实的资源管理案例给出思考与实践。
二 业务场景
在我们的一个应用内,会由运营维护一批用于在应用内加人的运营号,在用户在投放页报名后,需要使用这些运营号去执行与用户建立好友关系和发送消息等后续的运营动作。并且,为了避免对用户造成骚扰,每个运营号执行动作的频率是有限制的,并且随着风控策略的不断丰富,导致有多种控制规则。
2.1 需求分析
首先,可以确定在这个场景中,可以提炼的基本信息如下:
资源:是上述的运营号;
提供的能力:加人能力、发送消息能力、....
使用及风控策略:
1)使用频次限制,每天最多使用 5 次,到达上限后需要等到第三个自然日才可以再次使用;
2)每使用一次后,需要等一小时后才可以再次使用;
事实上,真实场景中还有更多更复杂的规则,不过这里我们只先根据上述两个条件进行设计。
2.2 资源定义
运营号属性字段:
id
名称
编号
供应商
所属分组
入库事件
更新时间
以上是主要属性字段。可见这个场景的资源与连接池和线程池之间的联系和区别。新资源创建和销毁不算频繁,没有到达一定空闲时间后自动回收的控制,但也会有新资源入库和移除的动作,这与线程池的创建和销毁是类似的。
2.3 生命周期设计
运营号进入我们的资源池,需要做一些列的操作,入库只是其中的第一步。在提供应用使用之前,需要先做好初始化和分组动作,并把资源加入生命周期中。应用层都是从通过分组 id 字段,从生命周期中取分组 id 相同,且可用状态的运营号执行业务动作。
三 方案设计
3.1 流程分析
一个简单的生命周期流程示意如下:
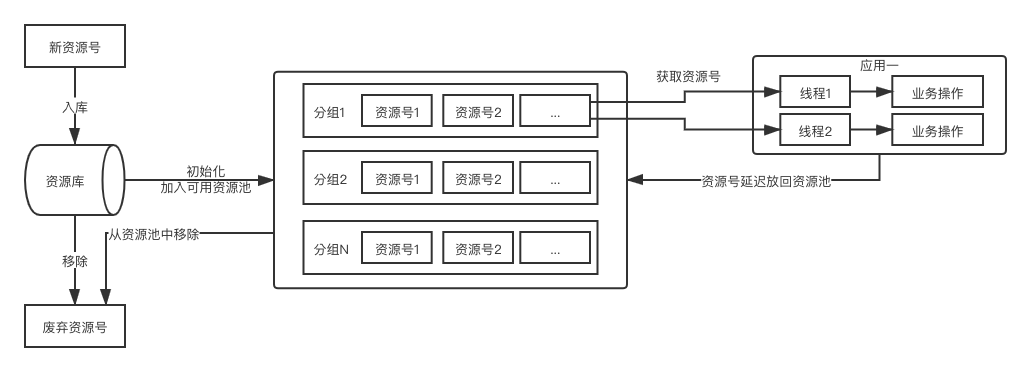
3.2 核心问题
从上图中可以看出,我们的设计需要解决以下几个问题:
1、资源的持久化存储
2、可用资源池维护,其中包含分组概念
3、应用层使用时,是从资源池获取一个/多个可用资源,但有可能是多线程获取,而一个资源,同一时刻只可能被一个线程获取并执行操作;再下次被加入可用资源池之前,其他线程无法获取;
4、资源被使用一次后或当日到达使用次数上限后,需要根据具体策略,到达时间后才可以再次加入可用资源池、延迟加入资源池。
而这四个核心问题之中,1 持久化存储比较容易,任一关系数据库即可满足,资源的入库和移除都属于低频操作;3 属于同步问题,简单的做法可以通过加锁同步来保证取资源的串行操作,并且在被获取后立即移除,以确保不会被两个线程同时获取;
2,4 较为复杂,也更为重要。
3.3 一种设计实现思路
3.3.1 可用资源池实现
从流程图中可以看到,如果要求资源池内的资源是根据资源加入的顺序先进先出,那么就可以通过队列来实现。考虑到资源池 与 应用之间可能是跨进程调用,那么分布式存储工具是第一选择。redis 中就提供了队列(list)数据结构,通过 lpush 把资源入池,lpop 从资源池中取出,对资源池操作时加锁保证同步。
如果不要求有序取出,那么也可以使用 zset 数据结构。ZADD 和 ZREM 执行加入和取出;而且 zset 提供了更丰富的命令集合,可以一次操作多个资源。
key 设计,需要包含分组 id,用于让应用获取属于自己的资源队列内的资源。可以通过业务前缀+下划线+分组 id 的方式组织 key,避免过长的同时保证足以区分。
3.3.2 资源的延迟加回资源池
比较容易想到的也有两种方式:数据库+定时任务, 和 延时队列。
1)基于数据库+定时任务
对于从资源池中取出的资源,我们可以存储在数据库表中,这可以理解为一条待处理任务。同时,起一个定时任务队列,定时取扫描这个任务表,当发现到了可以加回资源池的时间时,就执行加回动作。
2)延时队列
也可以考虑引入消息队列。当资源被使用后,我们根据使用情况,计算得出需要推迟多久后加回资源池(这点与 1 相同),然后通过发送延迟消息到消息队列。这样当到达既定时间时,消费者就可以消费到这条延时消息,然后执行加回资源池动作。
优缺点分析:
方法 1)是采用任务扫描加定时任务的方式。好处是不太容易出现资源遗漏的情况。再确认资源加回资源池成功之前,任务状态一直是待处理;
缺点:定时任务需要指定一个扫描的时间周期,而且通畅不宜过于频繁,因为每次调度都需要做一次表数据扫描;而且不太容易实现到秒级或者更灵活的时间周期控制。当然,可以考虑采用类似 kafka 时间轮的方案,但实现难度会增加不少。
方法 2)依赖消息队列,那么我们就必须考虑消息丢失、消息积压的问题。如果对资源加回可用资源池的延迟时间并不是很敏感,那么影响还不大。但消息丢失的问题必须解决。这可以转化为消息队列防止消息丢失的问题,通过手动提交、事务控制等手段来确保不会出现消息丢失。
3.4 到此为止了吗?
当看到这个标题的时候,大家就肯定已经明白,问题并不会到此为止。上面的“方案”,只是做到了“实现”,具体来说,就是在一定的条件(理想条件,理想的远离现实)且不出现任何意外的情况下,这个“方案”才能达到我们预想的效果。但事实上,我们再次回顾那张示意图,仔细思考一下,就是明白还欠缺了哪些问题。
1、资源池支持分组,分组数会有多少?最多会增加到多大的数量级?一个资源池内最多会有多少个资源?会占用多少空间?当一个 redis 单点服务内分组 key 过多的时候,使用要考虑使用 proxy+多实例,或 redis-cluster 的方案来支持?
2、使用条件中,除了每使用一次,就需要推迟一小时才能再加回生命周期外,还有一个每天 5 次使用次数上限的限制,那么怎样记录使用次数?
3、真实的应用场景中,除了常规的使用要求(时间间隔)外,还可能在使用时,资源接口返回的一些信息调整推迟加回资源池的时间,而这个时间可能与常规的时间间隔相冲突,策略的优先级怎么实现?怎么确保资源不会被提前加回资源池,导致放回的是一个实际上不可用的资源?
4、.....
四 总结
当我们真的想清楚了上述问题,并提供出一个覆盖了各环节的解决方案,并且能组成一个能够顺畅运行的系统时(至少是在脑中验证),才算是完成了方案设计。而这样的方案,才能真正的得以很好的落实,而不会上线后遇到问题采取做各种碎片化的修复逻辑,不停的不定堆叠,最终导致不可用、无法维护的系统。
版权声明: 本文为 InfoQ 作者【程序员架构进阶】的原创文章。
原文链接:【http://xie.infoq.cn/article/a9c16b59622528f5790d810aa】。文章转载请联系作者。

磨炼中成长,痛苦中前行 2017.10.22 加入
微信公众号【程序员架构进阶】。多年项目实践,架构设计经验。曲折中向前,分享经验和教训









评论