

小师妹学 JVM 之: 深入理解 JIT 和编译优化 - 你看不懂系列

简介
小师妹已经学完JVM的简单部分了,接下来要进入的是JVM中比较晦涩难懂的概念,这些概念是那么的枯燥乏味,甚至还有点惹人讨厌,但是要想深入理解JVM,这些概念是必须的,我将会尽量尝试用简单的例子来解释它们,但一定会有人看不懂,没关系,这个系列本不是给所有人看的。
更多精彩内容且看:
JIT编译器
小师妹:F师兄,我的基础已经打牢了吗?可以进入这么复杂的内容环节了吗?
小师妹不试试怎么知道不行呢?了解点深入内容可以帮助你更好的理解之前的知识。现在我们开始吧。
上次我们在讲java程序的处理流程的时候,还记得那通用的几步吧。
小师妹:当然记得了,编写源代码,javac编译成字节码,加载到JVM中执行。
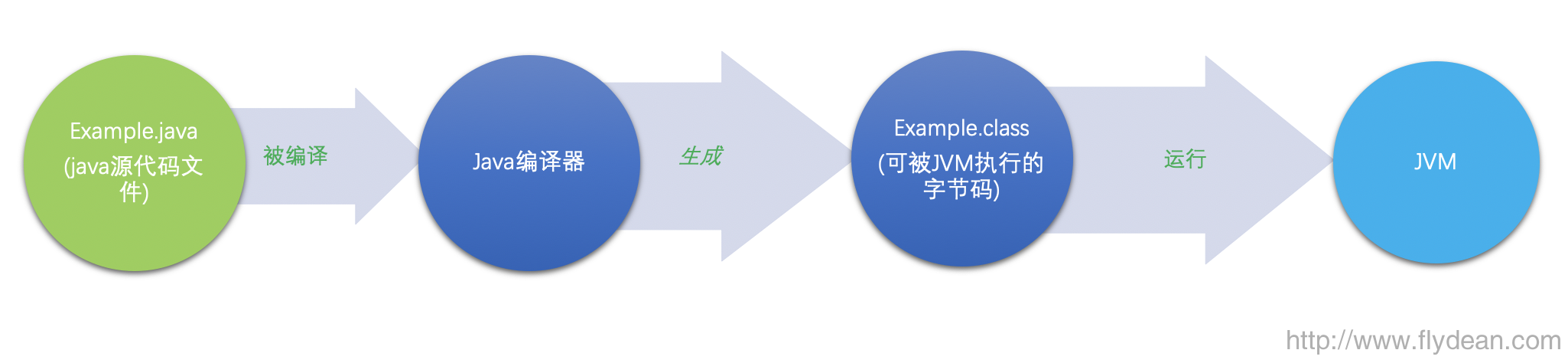
对,其实在JVM的执行引擎中,有三个部分:解释器,JIT编译器和垃圾回收器。
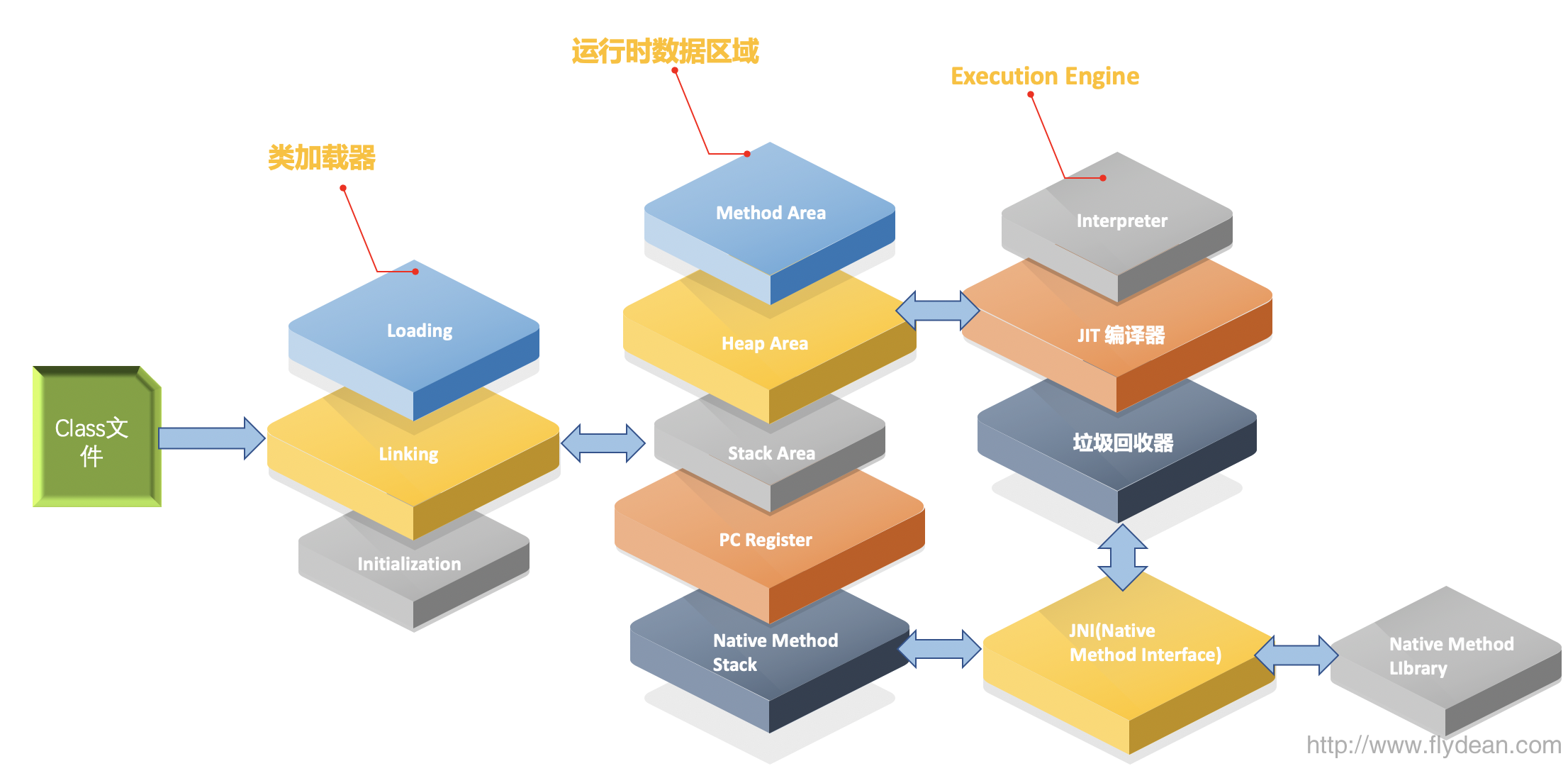
解释器会将前面编译生成的字节码翻译成机器语言,因为每次都要翻译,相当于比直接编译成机器码要多了一步,所以java执行起来会比较慢。
为了解决这个问题,JVM引入了JIT(Just-in-Time)编译器,将热点代码编译成为机器码。
Tiered Compilation分层编译
小师妹你知道吗?在JDK8之前,HotSpot VM又分为三种。分别是 client VM, server VM, 和 minimal VM,分别用在客户端,服务器,和嵌入式系统。
但是随着硬件技术的发展,这些硬件上面的限制都不是什么大事了。所以从JDK8之后,已经不再区分这些VM了,现在统一使用VM的实现来替代他们。
小师妹,你觉得Client VM和Server VM的本质区别在哪一部分呢?
小师妹,编译成字节码应该都是使用javac,都是同样的命令,字节码上面肯定是一样的。难点是在执行引擎上面的不同?
说的对,因为Client VM和Server VM的出现,所以在JIT中出现了两种不同的编译器,C1 for Client VM, C2 for Server VM。
因为javac的编译只能做少量的优化,其实大量的动态优化是在JIT中做的。C2相对于C1,其优化的程度更深,更加激进。
为了更好的提升编译效率,JVM在JDK7中引入了分层编译Tiered compilation的概念。
对于JIT本身来说,动态编译是需要占用用户内存空间的,有可能会造成较高的延迟。
对于Server服务器来说,因为代码要服务很多个client,所以磨刀不误砍柴工,短暂的延迟带来永久的收益,听起来是可以接受的。
Server端的JIT编译也不是立马进行的,它可能需要收集到足够多的信息之后,才进行编译。
而对于Client来说,延迟带来的性能影响就需要进行考虑了。和Server相比,它只进行了简单的机器码的编译。
为了满足不同层次的编译需求,于是引入了分层编译的概念。
大概来说分层编译可以分为三层:
第一层就是禁用C1和C2编译器,这个时候没有JIT进行。
第二层就是只开启C1编译器,因为C1编译器只会进行一些简单的JIT优化,所以这个可以应对常规情况。
第三层就是同时开启C1和C2编译器。
在JDK7中,你可以使用下面的命令来开启分层编译:
而在JDK8之后,恭喜你,分层编译已经是默认的选项了,不用再手动开启。
OSR(On-Stack Replacement)
小师妹:F师兄,你刚刚讲到Server的JIT不是立马就进行编译的,它会等待一定的时间来搜集所需的信息,那么代码不是要从字节码转换成机器码?
对的,这个过程就叫做OSR(On-Stack Replacement)。为什么叫OSR呢?我们知道JVM的底层实现是一个栈的虚拟机,所以这个替换实际上是一系列的Stack操作。
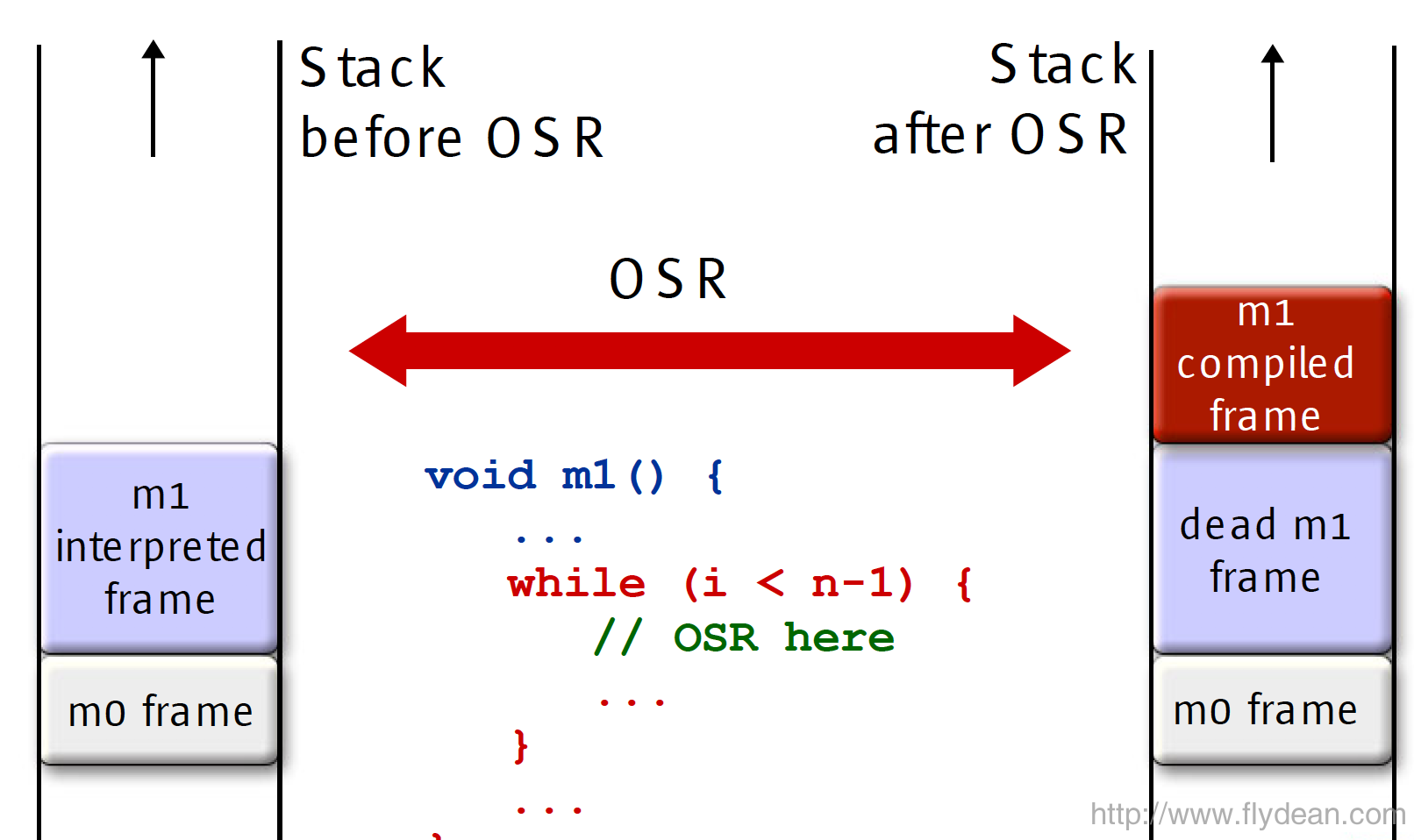
上图所示,m1方法从最初的解释frame变成了后面的compiled frame。
Deoptimization
这个世界是平衡的,有阴就有阳,有优化就有反优化。
小师妹:F师兄,为什么优化了之后还要反优化呢?这样对性能不是下降了吗?
通常来说是这样的,但是有些特殊的情况下面,确实是需要进行反优化的。
下面是比较常见的情况:
需要调试的情况
如果代码正在进行单个步骤的调试,那么之前被编译成为机器码的代码需要反优化回来,从而能够调试。
代码废弃的情况
当一个被编译过的方法,因为种种原因不可用了,这个时候就需要将其反优化。
优化之前编译的代码
有可能出现之前优化过的代码可能不够完美,需要重新优化的情况,这种情况下同样也需要进行反优化。
常见的编译优化举例
除了JIT编译成机器码之外,JIT还有一下常见的代码优化方式,我们来一一介绍。
Inlining内联
举个例子:
上面的add方法可以简单的被替换成为内联表达式。
Branch Prediction分支预测
通常来说对于条件分支,因为需要有一个if的判断条件,JVM需要在执行完毕判断条件,得到返回结果之后,才能够继续准备后面的执行代码,如果有了分支预测,那么JVM可以提前准备相应的执行代码,如果分支检查成功就直接执行,省去了代码准备的步骤。
比如下面的代码:
Loop unswitching
如果我们在循环语句里面添加了if语句,为了提升并发的执行效率,可以将if语句从循环中提取出来:
可以改为下面的方式:
Loop unrolling展开
在循环语句中,因为要不断的进行跳转,所以限制了执行的速度,我们可以对循环语句中的逻辑进行适当的展开:
转变为:
虽然循环体变长了,但是跳转次数变少了,其实是可以提升执行速度的。
Escape analysis逃逸分析
什么叫逃逸分析呢?简单点讲就是分析这个线程中的对象,有没有可能会被其他对象或者线程所访问,如果有的话,那么这个对象应该在Heap中分配,这样才能让对其他的对象可见。
如果没有其他的对象访问,那么完全可以在stack中分配这个对象,栈上分配肯定比堆上分配要快,因为不用考虑同步的问题。
我们举个例子:
上面的例子中,setFoo引用了foo对象,如果bar对象是在heap中分配的话,那么引用的foo对象就逃逸了,也需要被分配在heap空间中。
但是因为bar和foo对象都只是在example方法中调用的,所以,JVM可以分析出来没有其他的对象需要引用他们,那么直接在example的方法栈中分配这两个对象即可。
逃逸分析还有一个作用就是lock coarsening。
为了在多线程环境中保证资源的有序访问,JVM引入了锁的概念,虽然锁可以保证多线程的有序执行,但是如果实在单线程环境中呢?是不是还需要一直使用锁呢?
比如下面的例子:
Vector是一个同步对象,如果是在单线程环境中,这个同步锁是没有意义的,因此在JDK6之后,锁只在被需要的时候才会使用。
这样就能提升程序的执行效率。
总结
本文介绍了JIT的原理和一些基本的优化方式。后面我们会继续探索JIT和JVM的秘密,敬请期待。
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-jit-in-detail/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
版权声明: 本文为 InfoQ 作者【程序那些事】的原创文章。
原文链接:【http://xie.infoq.cn/article/a8fbe4fb701bd8657888619f3】。文章转载请联系作者。
关注公众号:程序那些事,更多精彩等着你! 2020.06.07 加入
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧,尽在公众号:程序那些事!










评论 (1 条评论)