
统一观测丨使用 Prometheus 监控 Nginx Ingress 网关最佳实践
作者:凌竹
01 Nginx Ingress 网关简介
在 Kubernetes 集群中,我们通常使用 “Nginx Ingress” 实现集群南北向流量的代理转发,Nginx Ingress 基于集群内 Ingress 资源配置生成具体的路由规则。Ingress 资源负责对外公开服务的管理,一般这类服务通过 HTTP 协议进行访问。通过 Nginx Ingress + Ingress 资源可以实现以下场景:
一、通过 Nginx Ingress 将来自客户端的全部流量转发给单一 Service。
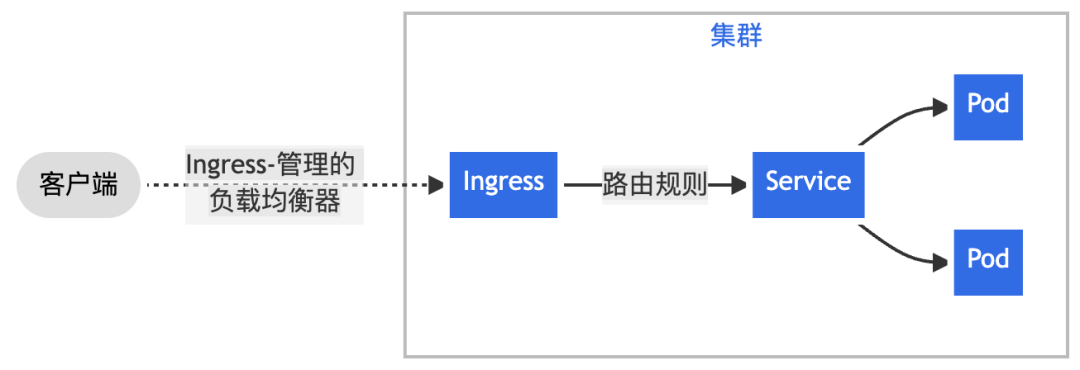
图:Nginx Ingress 工作模式介绍
二、通过 Nginx Ingress 实现更复杂的路由转发规则,将来自单一绑定 IP 地址的所有流量根据 URL 请求路径前缀转发给不同的 Service。
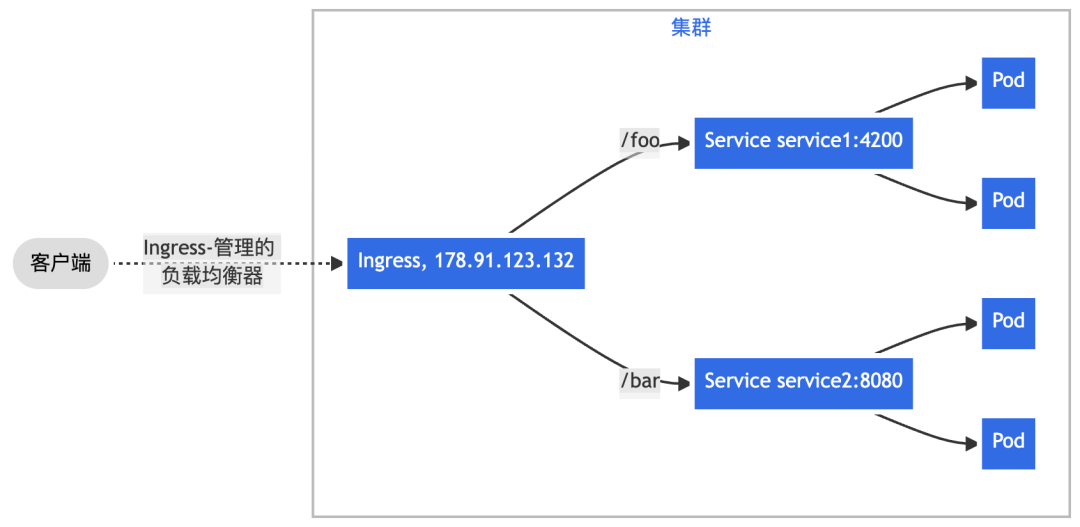
图:基于 URL 请求路径的转发
三、根据 HTTP 请求头部携带的 Host 字段——通常由访问的域名决定,将来自单一绑定 IP 地址的流量分发给不同后端 Service,实现基于名称的虚拟主机(Name-based Virtual Hosting)能力。
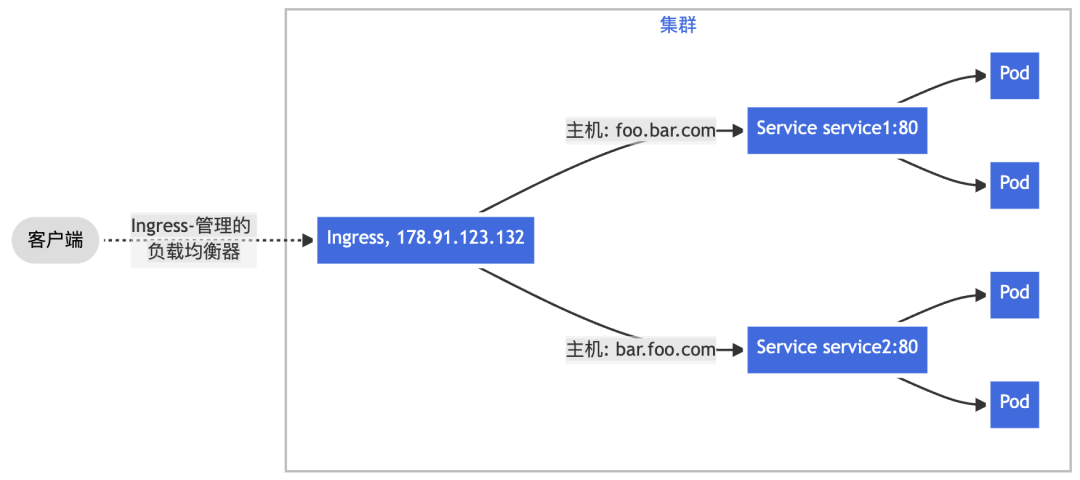
图:基于 Host 请求头的转发
通常,围绕 Nginx Ingress 网关监控场景,我们通常会关注两类核心指标数据:
工作负载资源
即 Nginx Ingress Controller Pod 的负载情况,当 CPU 、内存等资源水位处于饱和或过载,会导致集群对外服务不稳定。针对“工作负载监控”,一般建议关注 “USE” 指标,即:使用率(Utilization)、饱和度(Saturation)、错误率(Errors)。对此,阿里云 Prometheus 监控提供了预置性能监控大盘,可参考 **《工作负载性能监控组件接入》 [ 1] **完成数据采集与大盘创建。
入口请求流量
包括集群范围全局的流量、某个 Ingress 规则转发的流量、某个 Service 的流量,以及对应的成功率/错误率、延迟,乃至请求来源的地址、设备等信息的分析与统计。针对“入口请求流量监控”,一般建议关注 “RED” 指标,即:请求速率(Rate)、请求失败数(Errors)、请求延迟(Duration)。可通过本文最佳实践实现接入。
02 Nginx Ingress 网关监控实现方式
基于 Exporter 指标
Kubernetes 基于开源 Nginx 实现的 Nginx Ingress 发行版一大特色是其每个进程都扮演着 Exporter 角色,实现遵循 Prometheus 协议格式的自监控指标,如:
使用开源或阿里云 Prometheus Agent 配合服务发现策略即可完成指标抓取与上报,通过 PromQL 实现分析、告警配置,或通过 Grafana 实现指标数据可视化展现。但这种监控实现方式在生产实践中存在不少问题。
问题 1:暴露太多不实用的 Histogram 指标
对生产或测试集群中的 Nginx Ingress 进行一次抓取,会发现它所展现的指标清单中,Histogram 类型指标占据非常多数量,Histogram 指标一般以 _bucket 命名,配合 _count 和 _count 一起使用。并且,其中包含常见分析不会使用的指标, 如:
nginx_ingress_controller_request_size_bucket:对每个请求体大小的分桶采样;
nginx_ingress_controller_bytes_sent_bucket:对每个响应体大小的分桶采样。
默认情况下,如果不在 Prometheus 的 metric_relabel_configs 采集配置中执行 drop 操作,这些指标都会被抓取、上报,占用大量带宽与存储资源。
问题 2:Pull 模式拉取太多不活跃的时间线
当第一个问题遇到 Prometheus Agent 的 Pull 模式,情况变得更加糟糕,如果某个访问频率不那么高的微服务,历史只要发生过一次请求,那么与它有关的所有时间线会在 Nginx Ingress 暴露的指标清单中一直出现。在每个抓取周期中,被不停采集、上报,资源浪费加剧。
这个现象背后的本质问题是一个计数器类型指标在观察周期内无变化时,如何避免上报?我们发现通过 Pull 模式很难落地一个好的解决方案,后文会介绍新的思路。
问题 3:Ingress Path 不可扩展、下钻
一般体现 HTTP 流量的监控指标,URL Path 是个很难处理的对象,如果直接将每个请求的 URL Path 加入到指标标签作为分析用途,将产生可怕的“维度爆炸”问题,可如果不加入这个信息,又无法实现指标细粒度的下钻分析。
Nginx Ingress 暴露的指标中,通过 path 标签记录 Ingress 规则中对应的请求路径字段,如 “/(.+)”、“/login”、“/orders/(.+)”,避免了 URL Path 明细不可枚举问题。但当用户想实现更细粒度的下钻分析时,如希望看到 “/users/(.+)/follower”、“/users/(.+)/followee” 两个不同 URL Pattern 的统计数据,无法扩展,预置在 Nginx Ingress 实现中的这部分指标计算逻辑不可编程。
问题 4:缺少地理、设备信息的分析
通常,网站系统的运维人员更关注请求来源侧信息,如:
访问网站的用户分布在全国哪几个省市?其中, Top10 的城市是哪些?
用户通过移动端还是 PC 端访问网站?其中,移动端有多少是 iOS 机型,有多少是 Android 机型?
这些数据也是 Nginx Ingress 自身暴露的指标中所未体现的。
问题 5:Kubernetes 官方 Grafana 大盘布局不够聚焦
虽然与 Nginx Ingress 暴露的指标无关,但用户一般会搭配 Kubernetes 官方提供的 Grafana 大盘进行数据可视化展现,所以也作为一个问题记录。
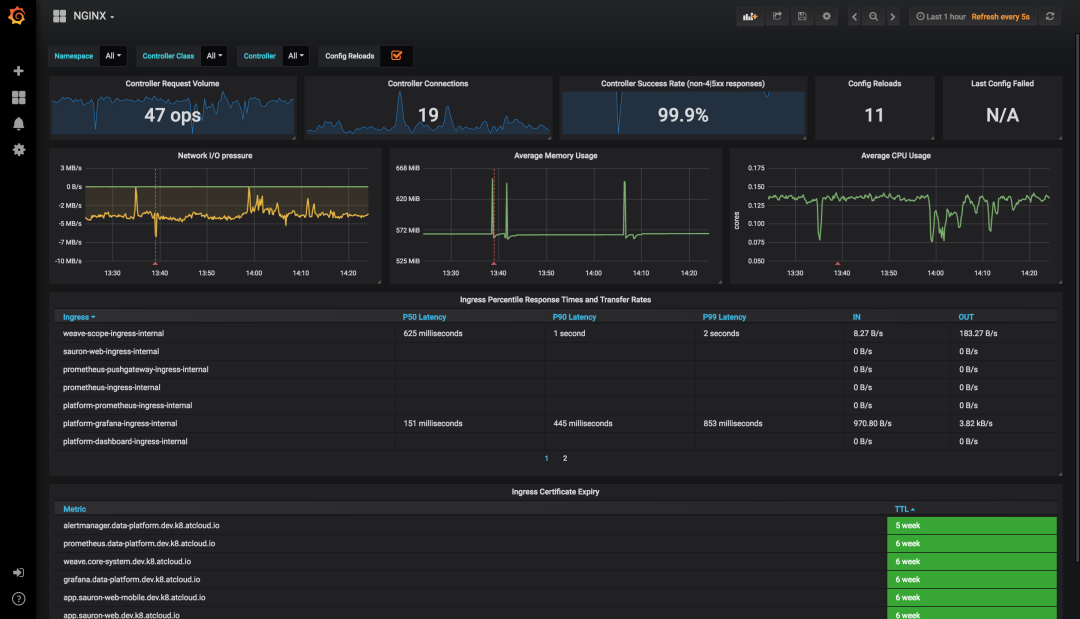
图:Kubernetes 官方提供的基于 Nginx Ingress 产出自监控指标的 Grafana 大盘
前面提到,在针对入口流量的监控场景中,我们一般关注 “RED” 指标:请求速率(Rate)、请求失败数(Errors)、请求延迟(Duration)。但面对这张大盘首屏,如果站在分析请求流量的用户视角,它的布局或者信息结构显得不是那么合理:
我不关注 Ingress Controller 的连接数,这是 HTTP 请求下层的概念
我不关注 Controller 级别的成功率,我更关注贯穿 Ingress / Host、Service、URI 路径上的成功率
我不关注 Ingress Controller 的配置被 Reload 了多少次
我不关注 Ingress Controller 上一次配置拉取失败
我不关注 Ingress 证书到期时间
……
因此,提供一张聚焦、好用的大盘,也是实现 “Nginx Ingress 网关监控” 无法回避的事情。
基于访问日志统计
综上所述,基于 Nginx Ingress 原生的自监控指标在生产实践中存在诸多问题,阿里云 Prometheus 监控提供的 “Nginx Ingress 网关监控” 则采用另一种——基于访问日志统计的方式。
与开源版的 Nginx 类似,Nginx Ingress 会往它的 Ingress Controller Pod 标准输出中打印每一条请求的日志,我们称为访问日志(Access Log):
目前 ACK 默认的 Nginx Ingress 所打印的访问日志包含以下信息:
请求时间
请求来源 IP
请求方法,如:GET
请求路径,如:/api/cart
响应状态码
请求体长度
响应体长度
请求耗时
请求上游服务名,如:default-my-otel-demo-frontend-8080
请求 User-Agent,如:Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/3.0)
请求头携带的 Host / 域名,如:my.otel-demo.com,这有助于确定流量是从哪个 Ingress 路由规则进来的
基于这些信息,只需在 K8s 环境里部署一个采集器,通过预聚合计算方式即可实现入口流量 RED 指标统计,并通过可控的技术手段规避基于 Exporter 指标实施监控的几大问题:
“暴露太多不实用的 Histogram 指标”——制作一组精益指标,裁剪不需要的指标项,满足大部分统计分析场景需要;
“Pull 模式拉取太多不活跃的时间线”——抛弃计数器模型,使用滚动窗口计算 Gauge 指标,窗口间数据独立,使用 RemoteWrite 方式推送,避免历史堆积时间线的重复上报;
“Ingress Path”不可扩展、下钻——预聚合逻辑可使用 CR 配置扩展,通过建立新的匹配规则实现下钻;
“缺少地理、设备信息的分析”——预聚合过程通过 GeoIP、UserAgent 分析等手段实现数据富化;
“Kubernetes 官方 Grafana 大盘布局不够聚焦”——建立新的入口观测大盘,优化布局与信息结构,提升大盘的价值与体验。
03 Nginx Ingress 网关监控指标模型
通用请求量指标(ingress_requests)
指标名:ingress_requests
指标类型:Gauge
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的请求量数值
指标标签:
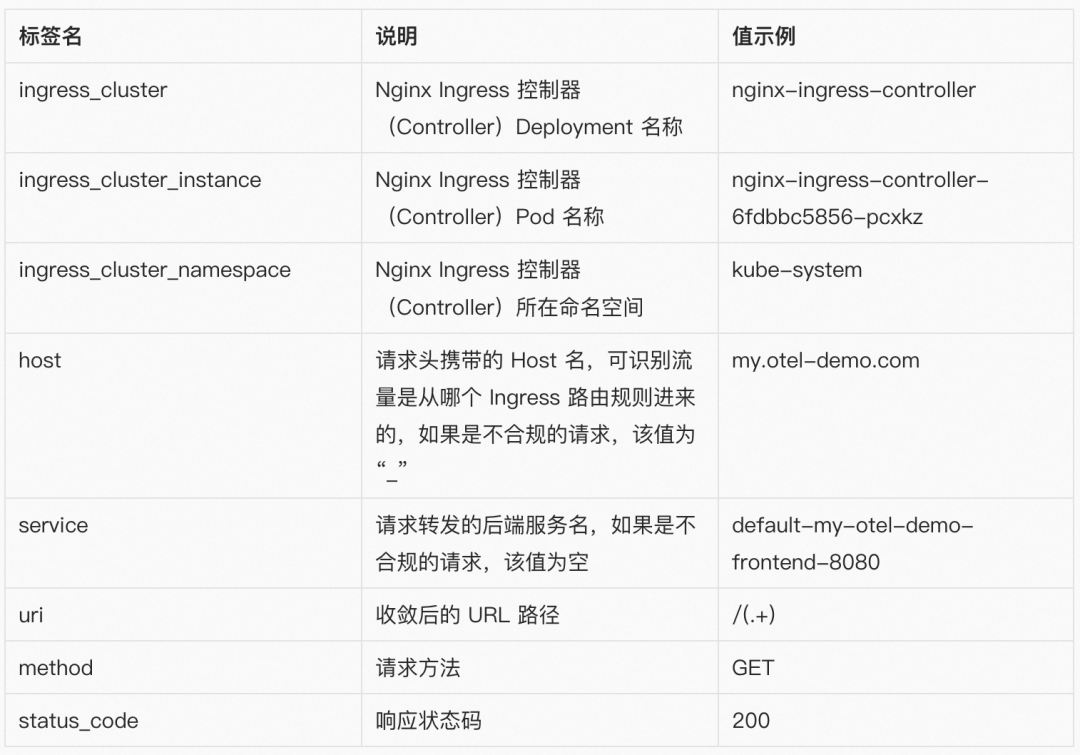
1. 基于地理的请求量指标(ingress_geoip_requests)
指标名:ingress_geoip_requests
指标类型:Gauge
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的请求量数值,标签中富化了地理信息
指标标签:
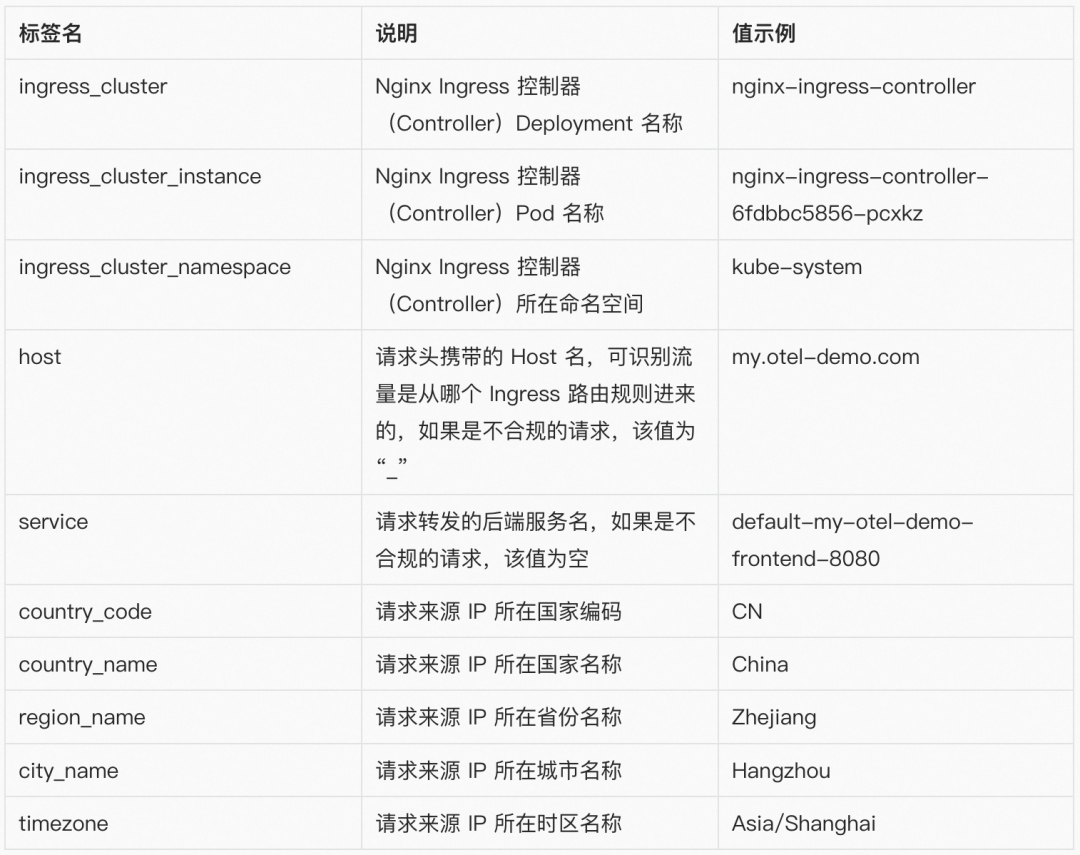
注:我们刻意裁剪了标签中 URI、Method、Status Code 等几个维度信息,该指标常见的使用场景中,请求路径的粒度至服务(Service)级即可满足,更细的粒度需要更昂贵的存储,且使用价值较低。
2. 基于设备的请求量指标(ingress_user_agent_requests)
指标名:ingress_user_agent_requests
指标类型:Gauge
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的请求量数值,标签中富化了设备信息
指标标签:
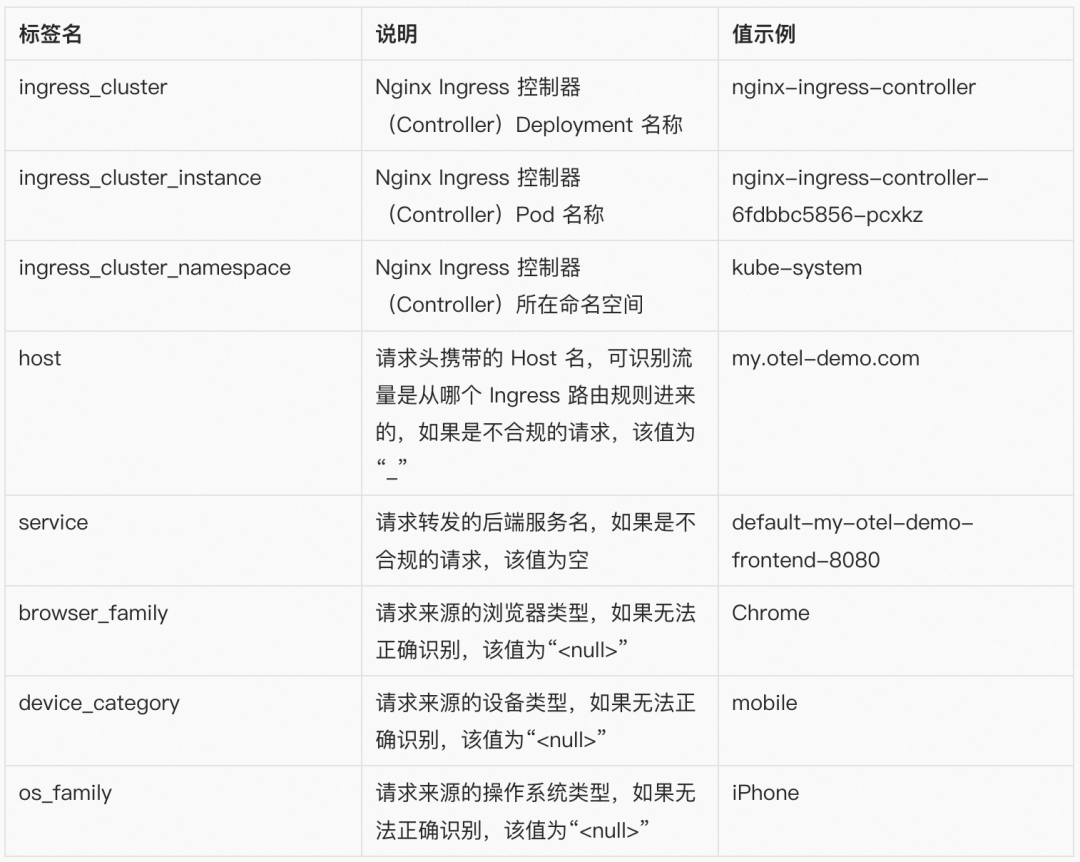
注:我们刻意裁剪了标签中 URI、Method、Status Code 等几个维度信息,该指标常见的使用场景中,请求路径的粒度至服务(Service)级即可满足,更细的粒度需要更昂贵的存储,且使用价值较低。
3. 请求延迟分桶指标(ingress_request_time)
指标名:ingress_request_time
指标类型:GaugeHistogram
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的请求延迟分桶值
指标标签:
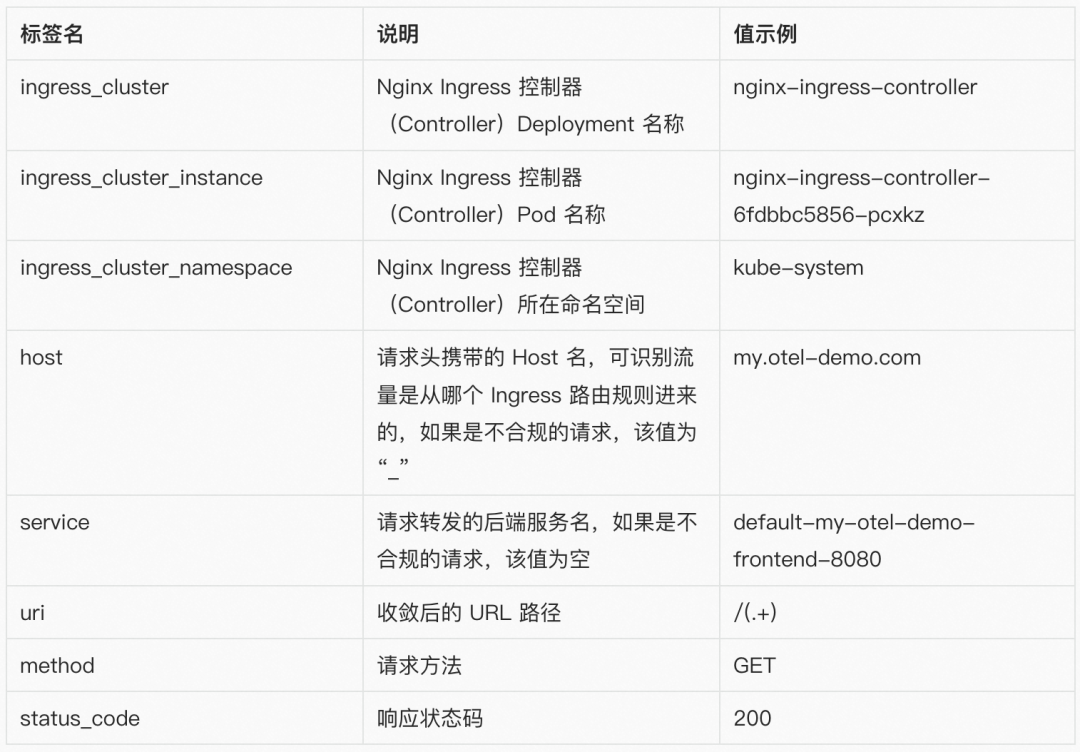
注:请留意当前指标类型并非常见的 Histogram 类型——每个桶的数值为计数器模型,而是 GaugeHistogram 类型——每个桶的数值为当前聚合周期内观察到的一种“瞬时值”,因此如果要对这种指标进行分位数计算,参考表达式:histogram_quantile(0.95,sum(sum_over_time(ingress_request_time_bucket{...}[1m])) by (le))。
4. 入流量指标(ingress_request_size)
指标名:ingress_request_size
指标类型:Gauge
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的请求报文总字节数
指标标签:
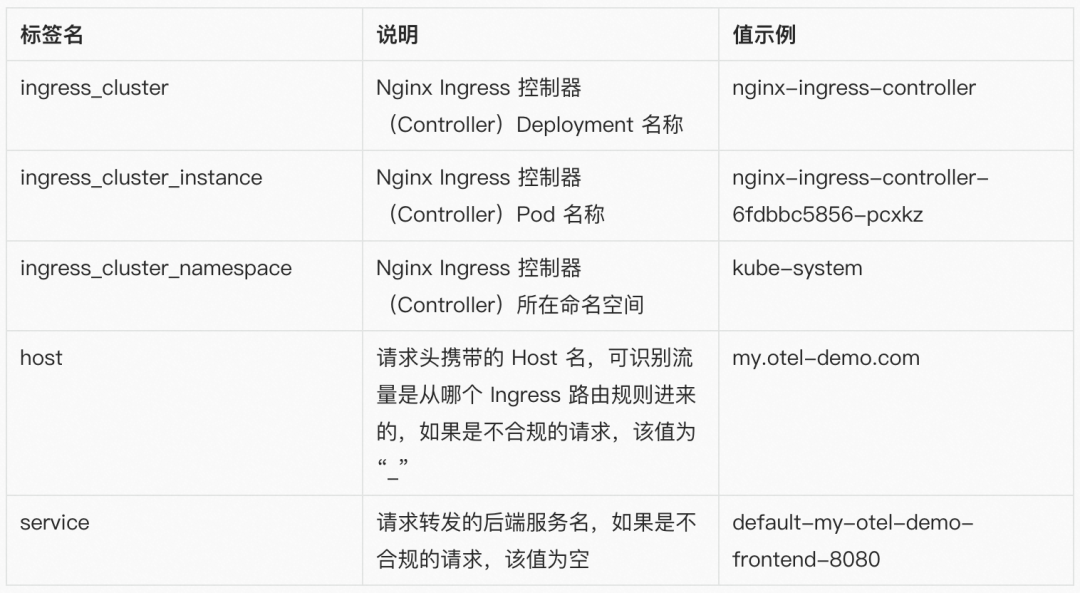
注:我们刻意裁剪了标签中 URI、Method、Status Code 等几个维度信息,该指标常见的使用场景中,请求路径的粒度至服务(Service)级即可满足,更细的粒度需要更昂贵的存储,且使用价值较低。
5. 出流量指标(ingress_response_size)
指标名:ingress_response_size
指标类型:Gauge
聚合周期:30s
指标说明:表示一个聚合周期内在标签对应维度上被统计到的响应报文总字节数——受 Nginx Ingress 实现限制,这里只能统计到响应体的字节数,不包含响应头的大小
指标标签:
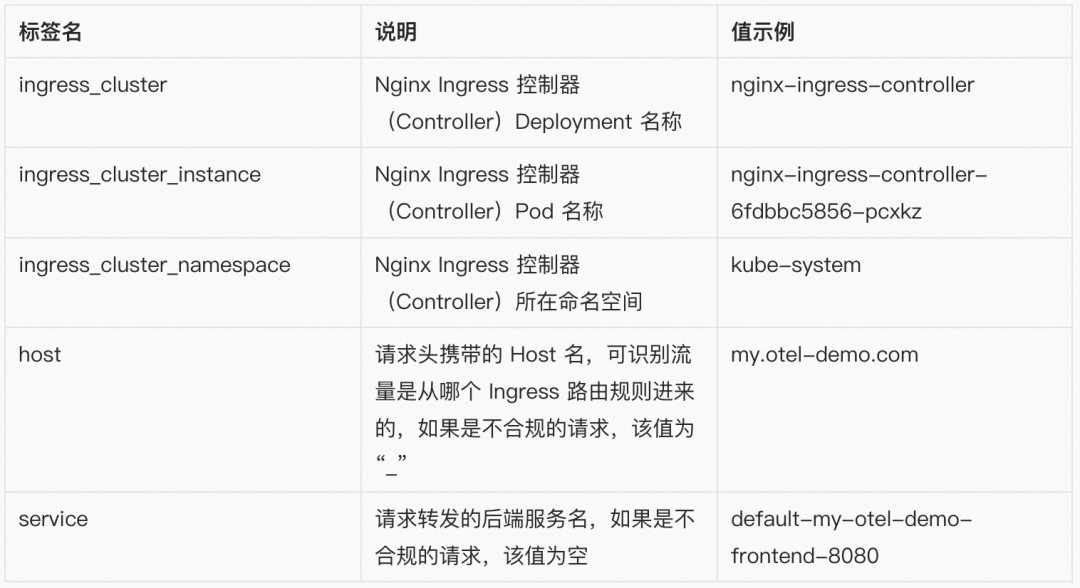
注:我们刻意裁剪了标签中 URI、Method、Status Code 等几个维度信息,该指标常见的使用场景中,请求路径的粒度至服务(Service)级即可满足,更细的粒度需要更昂贵的存储,且使用价值较低。
04 Nginx Ingress 网关监控接入
方法一:实现 ACK 集群默认安装的 Nginx Ingress 网关监控
如果您在创建 ACK 集群时勾选了安装 Nginx Ingress 组件,那么在集群的 kube-system 空间下会有一组默认的 Ingress Controller Pod 实现网关流量代理,可通过下列方式完成这个默认 Nginx Ingress 网关的监控接入:
第一步:进入阿里云 Prometheus 监控集成中心
进入阿里云 Prometheus 监控,找到您 ACK 集群对应的 Prometheus 实例,在首页集成中心找到 “Nginx Ingress 网关监控”:
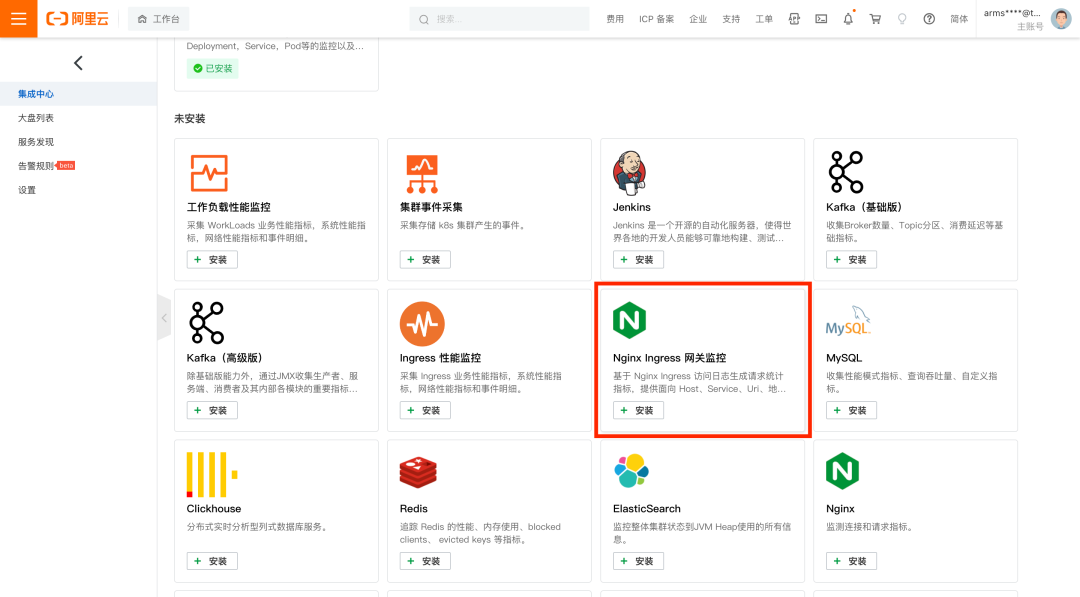
图:选择“Nginx Ingress 网关监控”
第二步:填写安装参数
图:安装参数
如果您在 ACK 集群创建后没有对 Nginx Ingress 执行任何变更操作(如:更改命名空间、IngressClass 标识名等),可在这步直接点击“确定”提交安装。
如果您正在接入的是自建、第 N 套 Nginx Ingress 网关,请参见下文“实现自建/多套 Nginx Ingress 网关监控”进行接入。
注:启用当前监控将在您的 K8s 集群中部署一个采集器工作负载(DaemonSet),资源限制为 0.5 核/512MB ,可以结合网关实际流量规模进行资源限制的调整,请通过 kubectl edit daemonset -narms-prom arms-vector 命令进行变更。
第三步:查看 Nginx Ingress 网关监控大盘
您可以打开 “Nginx Ingress 网关监控” 集成卡片侧边栏,在“大盘” TAB 页签找到名为 “Universal Ingress Observability Dashboard” 的大盘,点击跳转 Grafana 查看数据。
图:“大盘” TAB 页签
在您完成第二步安装后,且 Nginx Ingress 网关有真实流量数据的情况下,一般 2-3 分钟即可在大盘看到采集、上报的指标数据。
方法二:实现自建/多套 Nginx Ingress 网关监控
如果您是自建 Nginx Ingress 网关,或者参照 ACK 官方文档 **《部署多个 Ingress Controller》 [ 2] **在当前 K8s 集群内部署了多套 Nginx Ingress 网关,通过本节内容实现监控接入。
接入过程其他保持不变,在 “Nginx Ingress 网关监控” 的安装页根据实际情况调整参数:
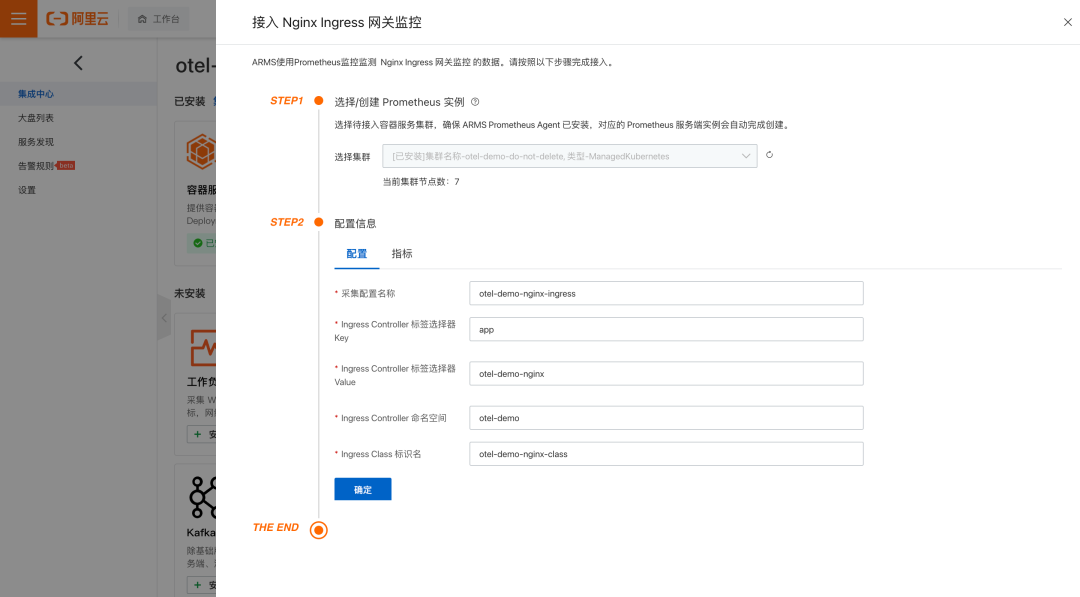
图:自定义安装参数
这里需要关注的五个参数介绍如下:
采集配置名称:作为当前采集配置的唯一 ID 进行设置,如:otel-demo-nginx-ingress
Ingress Controller 标签选择器 Key:采集器通过标签选择器查找指定的 Ingress Controller Pod,这里提供选择器的键名,如:app
Ingress Controller 标签选择器 Value:采集器通过标签选择器查找指定的 Ingress Controller Pod,这里提供选择器的值,如:otel-demo-nginx,这样与上面的键名组合成查询表达式:app=otel-demo-nginx
Ingress Controller 命名空间:Ingress Controller 所在的命名空间,如:otel-demo
Ingress Class 标识名:该 Ingress Controller 监听的目标 Ingress Class 标识,如:otel-demo-nginx-class
注:监控多套 Nginx Ingress 网关会复用相同的采集器工作负载,它默认的资源限制为 0.5 核/512MB ,请关注网关实际流量规模,进行相应的资源限制调整,请通过 kubectl edit daemonset -narms-prom arms-vector 命令进行变更。
05 Nginx Ingress 网关监控可视化大盘
整个 Nginx Ingress 网关监控可视化大盘分为六个区域:
概览:体现首屏亟需关注的指标信息
服务统计 - TopN:以 TopN 视角展示 Host / 域名、服务、URI 的访问 PV、耗时、成功率等信息
服务统计 - 趋势分布:展示 PV、出入流量、请求成功率、延迟等趋势,以及状态码、请求方法、Ingress Pod 请求数等分布
服务统计 - 请求分析:以表格形式呈现贯穿 Host / 域名、Service、Uri 请求路径上的 PV、成功率、4XX 比例、5XX 比例、延迟情况
地理统计:以占比视角和表格明细分别呈现基于地理信息的请求情况
设备统计:以占比视角和表格明细分别呈现基于设备信息的请求情况
1. 概览
概览区域通过体现流量与服务质量/体验的仪表盘设计充分展示了 RED 指标定义的要素:请求速率(Rate)、请求失败数(Errors)、请求延迟(Duration)。
① 体现流量的仪表盘
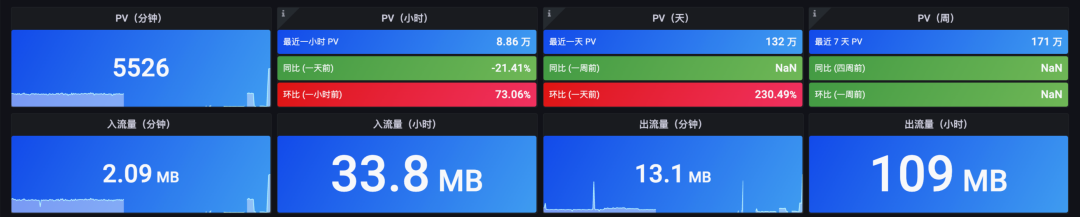
图:PV 与流量
在 Nginx Ingress 网关监控可视化大盘的首屏顶部,即呈现最重要的与流量相关的数据:
分钟级访问 PV
小时级访问 PV
与一天前的同比
与一小时前的环比
一天级访问 PV
与一周前的同比
与一天前的环比
一周级访问 PV
与四周前(月)的同比
与一周前的环比
同时,通过 Grafana 强大的可视化能力,我们用不同的颜色区分指标是否需要关注的事实,下文可以看到不止一处应用了这一实践:
当同比、环比上涨时使用红色显示指标值
当同比、环比下跌是使用绿色显示指标值
② 体现服务质量/体验的仪表盘

图:成功率、错误数、延迟
概览区域同样体现了非常重要的请求成功率、错误请求数、延迟等指标信息。这里对成功的请求定义是响应码为 1XX、2XX、3XX,如果是 4XX、5XX 则被计算为失败/错误的请求。
我们选取了一组需要特别关注的错误响应码,它们是:
404:当该数值异常升高时需要排查是否应用配置错误导致被搜索引擎抓取的页面无法正确加载
429:当该数值异常升高时需要关注是否有客户端以超过正常的频率访问后端服务导致限流
499:当该数值异常升高时需要关注是否因为后端服务响应耗时过久导致客户端提前关闭连接
500:当该数值异常升高时需要关注是否有后端服务因业务逻辑未正确实现导致内部错误
503:当该数值异常升高时需要关注是否有后端服务因为升级等原因导致不可用
504:当该数值异常升高时需要关注是否有后端服务响应超过了 Nginx Ingress 承受范围导致超时
同时,这里也充分应用了“可观测即颜色”的实践,策略是:
请求成功率
当大于 90% 时表现为绿色
当大于 50% 但小于 90% 时表现为黄色
当小于 50% 时表现为红色
5XX 比例
当大于 50% 时表现为红色
当小于 50% 但大于 10% 时表现为黄色
当小于 10% 时表现为绿色
各类错误请求数:在当前周期内大于 0 即表现为黄色
各类延迟指标:
当小于 200ms 时表现为绿色
当小于 500ms 但大于 200ms 时表现为黄色
当大于 500ms 时表现为红色
此外,需要注意到,正确的请求和错误请求,它们的延迟指标差异较大,因此建议通过顶部下拉筛选,指定正常响应码或错误响应码来区别分析。
2. 服务统计 - TopN
服务统计 - TopN 区域通过排序的方式,陈列访问 PV 前 10、请求耗时前 10、5XX 比例前 10 的 Host / 域名、Service、URI。
① 访问 PV
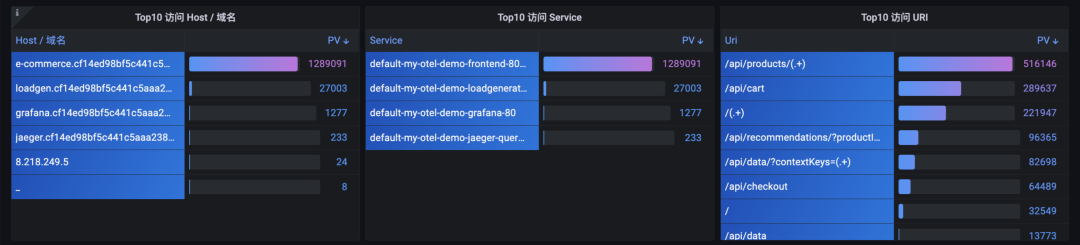
图:访问 PV 排名
这里可以通过顶部下拉筛选,指定响应状态码来区别正常请求访问和错误请求访问的排名。
② 请求耗时
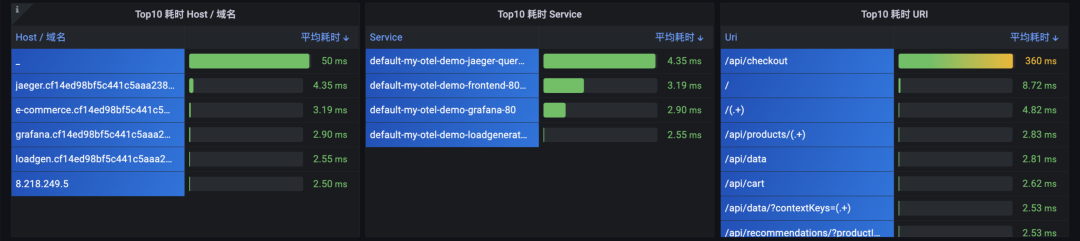
图:请求耗时排名
这里的颜色变化策略是:
当小于 200ms 时表现为绿色
当小于 500ms 但大于 200ms 时表现为黄色
当大于 500ms 时表现为红色
此外,正确的请求和错误请求,它们的延迟指标差异较大,因此建议通过顶部下拉筛选,指定正常响应码或错误响应码来区别分析。
③ 5XX 比例
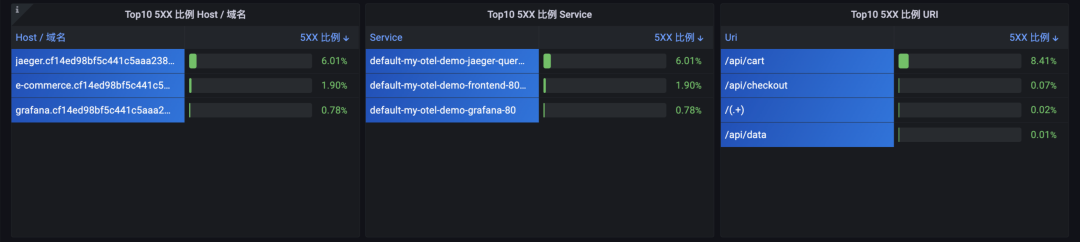
图:5XX 比例排名
这里的颜色变化策略是:
当大于 50% 时表现为红色
当小于 50% 但大于 10% 时表现为黄色
当小于 10% 时表现为绿色
3. 服务统计 - 趋势分布
服务统计 - 趋势分布区域分别展示了 Host / 域名维度和 Service 维度各 RED 指标变化的趋势,以及请求在响应状态码、请求方法、Ingress Controller Pod 上的分布。
① Host / 域名维度的 RED 指标
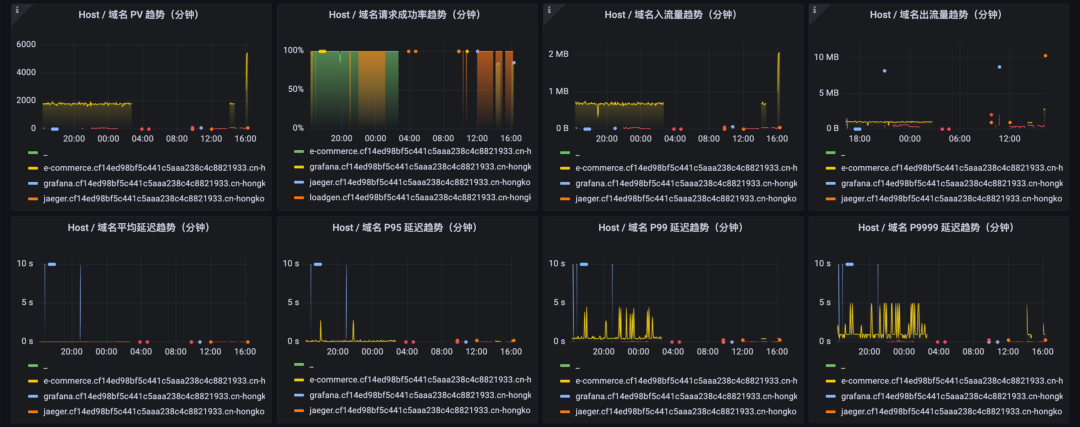
图:Host 维度 RED 指标
这部分仪表盘展示了各 Host / 域名的 RED 指标要素:
各 Host / 域名分钟级的 PV 变化
各 Host / 域名分钟级的请求成功率变化
各 Host / 域名分钟级的出入流量变化
各 Host / 域名分钟级的延迟变化
其中,PV 趋势和延迟趋势,受顶部下拉筛选的响应状态码变化控制,可以区分正常请求和错误请求的 PV 和延迟。
② Service 维度的 RED 指标
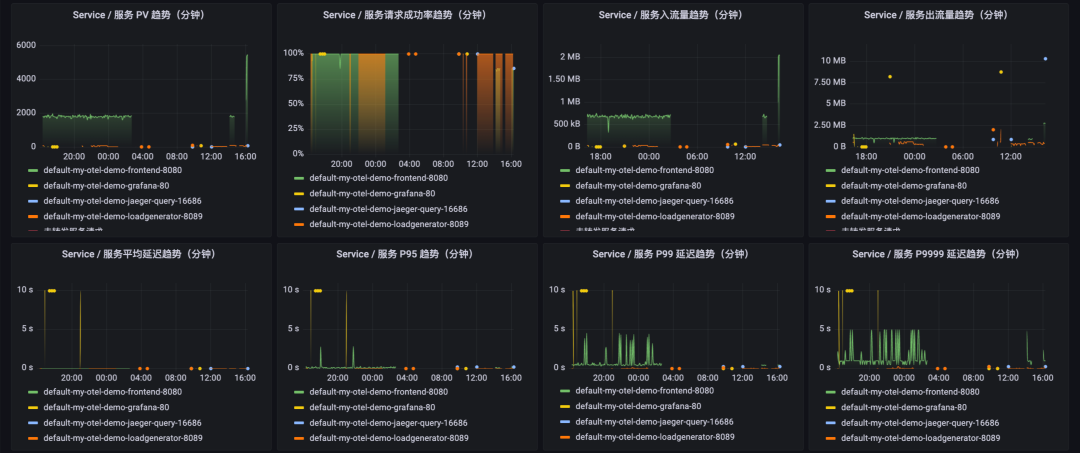
图:Service 维度 RED 指标
这部分仪表盘展示了各 Service 的 RED 指标要素:
各 Service 分钟级的 PV 变化
各 Service 分钟级的请求成功率变化
各 Service 分钟级的出入流量变化
各 Service 分钟级的延迟变化
其中,PV 趋势和延迟趋势,受顶部下拉筛选的响应状态码变化控制,可以区分正常请求和错误请求的 PV 和延迟。
③ 请求分布
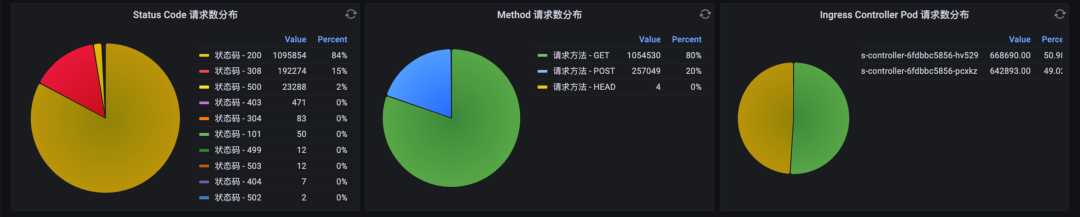
图:响应状态码、请求方法、Ingress Controller Pod 分布
这部分仪表盘用饼图展示了请求流量在各维度上的分布:
请求流量分布在各响应状态码的占比与具体数值
请求流量分布在各请求方法的占比与具体数值
请求流量分布在各 Ingress Controller Pod 的占比与具体数值
它们的统计范围是当前顶部选择的时间段。
4. 服务统计 - 请求分析
图:请求分析表格
服务统计最后一部分则是将贯穿 Host / 域名、Service、Uri 请求路径上的 PV、成功率、4XX 比例、5XX 比例、延迟情况以表格形式详细呈现。它们的统计范围是当前顶部选择的时间段。如果希望下钻看到更细粒度的 URI 请求分析统计,需要扩展 URI 收敛规则, 请参考进阶指南部分的“编辑 CR 扩展 URI 收敛规则”。
5. 地理统计
图:基于地理信息的统计
地理统计区域提供了各维度的占比情况和对应的表格:
访问省份
各访问省份 / 地区的占比情况,统计范围是当前顶部选择的时间段
访问省份 / 地区的表格详情,统计范围是当前顶部选择的时间段
访问城市
各访问城市的占比情况,统计范围是当前顶部选择的时间段
访问城市的表格详情,统计范围是当前顶部选择的时间段
访问时区
各访问时区的占比情况,统计范围是当前顶部选择的时间段
访问时区的表格详情,统计范围是当前顶部选择的时间段
6. 设备统计
图:基于设备信息的统计
设备统计区域提供了各维度的占比情况和对应的表格:
设备类型维度
各设备类型的占比、具体数值,统计范围是当前顶部选择的时间段
设备类型的表格详情,统计范围是当前顶部选择的时间段
操作系统维度
各操作系统的占比、具体数值,统计范围是当前顶部选择的时间段
操作系统的表格详情,统计范围是当前顶部选择的时间段
浏览器维度
各浏览器的占比、具体数值,统计范围是当前顶部选择的时间段
浏览器的表格详情,统计范围是当前顶部选择的时间段
一镜到底效果图
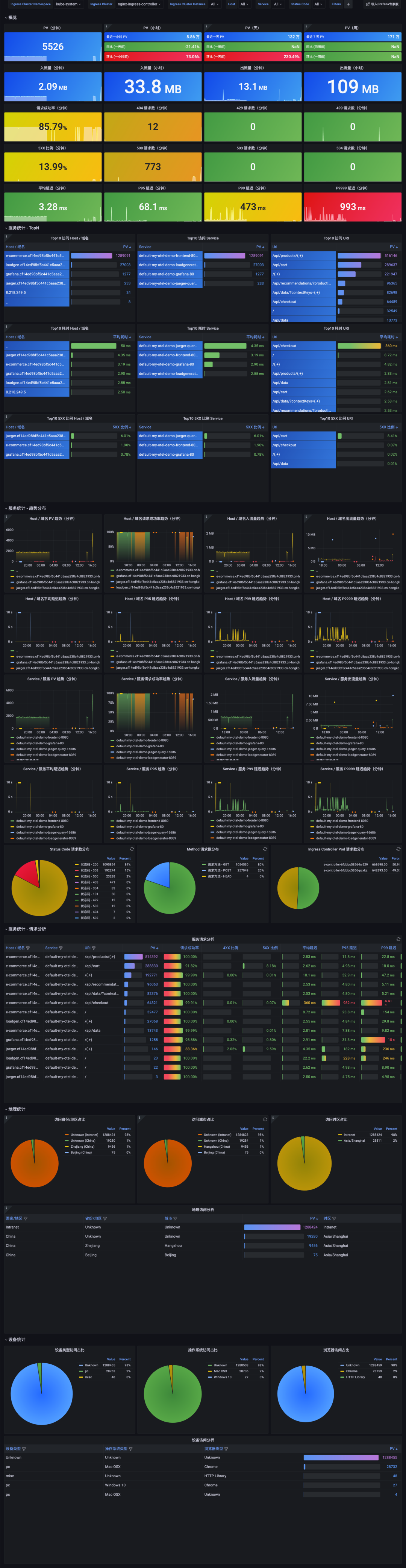
06 Nginx Ingress 网关监控进阶指南
编辑 CR 扩展 URI 收敛规则
由于访问日志中的请求路径这类明细数据是不可枚举的,直接放入 Ingress 请求指标的标签中将导致维度发散,存储成本急剧上升,甚至影响指标查询。
因此,实现 Nginx Ingress 网关监控的采集器会根据一组 URI 收敛规则对请求路径做精简,每个收敛规则由两部分组成:
匹配表达式:一个正则表达式,如果当前 URI 匹配命中,则进行收敛,如:
收敛后文本:将 URI 收敛为另一个具备可读性的字符串,如:ProductItem
采集器会在第一次启用时扫描当前 K8s 集群的 Ingress 资源,并根据已有的路由规则提供的 Path 信息组装收敛规则。如果这部分配置无法满足您的分析、统计需要,请参照下列步骤进行扩展。
首先,执行 kubectl edit ingresslog -narms-prom ingresslog-<您的采集配置名>,进入这个自定义资源的编辑窗口,如:kubectl edit ingresslog -narms-prom ingresslog-default-ingress-nginx。
请找到 spec.logParser.reduceUri.allowList 字段,对其进行扩展。比如,它默认可能只有两条收敛规则:
allowList 字段为一个数组对象,它的每一个元素即表示一个收敛规则,每个收敛规则下的 pattern 字段表示“匹配表达式”,reduced 字段表示“收敛后文本”。
根据您实际的业务场景,可按如下参考示例进行改写:
这里请按照顺序,将最短匹配路径的规则放到列表末,如:^/$。保存该配置后等待 2-3 分钟,即可在大盘看到根据 URI 收敛规则扩展后的进一步细化的指标数据。
扩展 URI 收敛规则会细化您的时间线,导致生成的指标数量上升,影响计费,请及时关注指标量的变化。
注 1:请您及时在本地备份 URI 收敛规则,因为在卸载当前 Nginx Ingress 网关监控能力后,对应的 IngressLog 自定义资源默认会被删除。
注 2:请不要改动 IngressLog 自定义资源中的其他配置,否则将导致 Nginx Ingress 网关监控无法正常工作!
相关链接:
[1] 《工作负载性能监控组件接入》
https://help.aliyun.com/document_detail/445938.html
[2] 《部署多个 Ingress Controller》
https://help.aliyun.com/document_detail/151524.htm
参考资料:
Kubernetes 官方文档
Ingress 介绍:https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/
Ingress Controller 介绍:https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress-controllers/
阿里云 ACK 官方文档
Ingress 概述:https://help.aliyun.com/document_detail/198892.html
Nginx Ingress 最佳实践:https://help.aliyun.com/document_detail/398740.html
版权声明: 本文为 InfoQ 作者【阿里巴巴云原生】的原创文章。
原文链接:【http://xie.infoq.cn/article/a531ce47d2326ffec07d68da9】。文章转载请联系作者。

阿里云云原生 2019-05-21 加入
还未添加个人简介









评论