YARN 的架构设计和工作原理(通俗易懂)

本文旨在用最通俗易懂的语言帮你理解Apache Yarn的架构设计和工作原理。相信学习大数据的同学都有相同的感受,知识点又多又密又杂,所以我将会按照我自己的理解帮你归纳梳理Apache Yarn的知识点,这些知识点都是Yarn最核心的内容,我认为如果你能将这些知识点都纳入到自己的知识体系中,再去学习更细节的内容会事半功倍。
以下内容为原创,如果你有疑问的地方,欢迎来评论区相互讨论,谢谢!
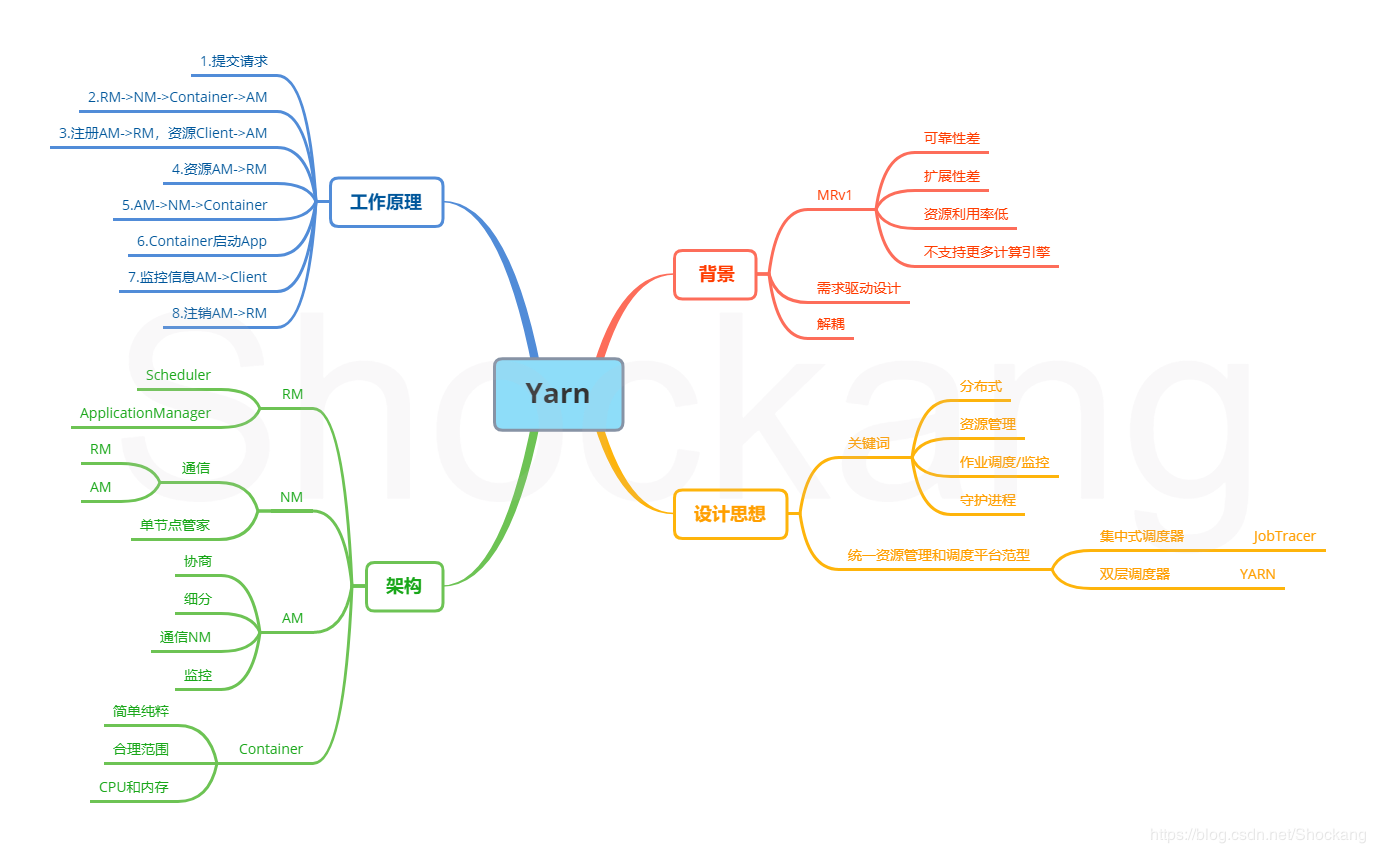
思维导图
先放本文的思维导图,帮助理解:
背景
祖师爷Doug Cutting 在谷歌三驾马车的启发下,创造了Hadoop。第一代的Hadoop分为分布式文件系统HDFS以及分布式计算引擎MapReduce,其中MapReduce v1 的架构大致长下面这个样子的。
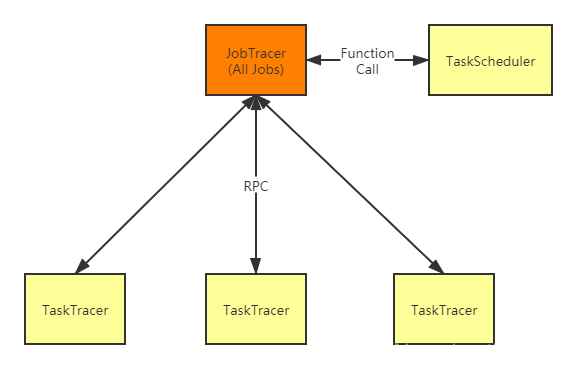
上图中有个叫JobTracer的东东,有两个非常重要的职责,一个是资源管理,另一个是作业控制。
你可以这样理解,为什么要这么去分类——简单来说,对于某个具体的应用程序,其中一个和它直接相关的(作业控制),另一个是和它非直接相关的(资源管理)。
我在知乎上看到一个论点,有点意思,这里借用一下(原文链接——关于YARN你必须要知道的)。诸葛亮为啥死的早,其中一个很大的原因是啥事都管,这里不讨论和本文不相干的,只是想说明一点,你啥事都管,指定死的早(嘿嘿,没啥冒犯的,我对孔明先生还是很尊敬的。)
其实在软件行业有个类似的思想——解耦,这个基本上每个程序猿都知道。回到MR v1来,人们却是后知后觉的,为啥呢——需求驱动设计。人们在使用MR v1的过程中,发现了很多痛点:
1.可靠性差:MR v1采用了主从架构,其中主节点存在单点故障的问题,一挂全挂。
2.扩展性差:上面说到,JobTracer干了两件事儿,作业控制和资源管理,但是一旦同时提交的作业过多,JobTracer就玩球子了,这成了整个系统的性能瓶颈啊,严重制约了集群的扩展性。
3.资源利用率低:MR v1的资源表示模型是“槽”,分为Map槽(只能干Map任务)和Reduce槽(只能干Reduce任务),坑爹的是,两种槽还不能混用,回到现实中来,比如某些景点,为啥女厕所排队如长龙,男厕所人来人往,没人排队呢?这里不讨论别的(据说有些景点已经在试用男女混合如厕了),只是想说明,你不混用,肯定会造成资源浪费的嘛。
4.不支持更多的计算引擎:随着大数据的发展,除了MR之外,还诞生了很多计算引擎——Spark,Flink等。MR v1只支持MR,这可不行啊,MR都快被淘汰了,死抱着MR哪行,得分家呀!
于是,MR v1分家了,分成了两家,老大MapReduce专门负责计算引擎,老二Yarn专门负责资源管理调度。实际上老二的财产都是从JobTracer继承过来的,今天我们来聊聊老二,看看他是如何解耦的。
设计思想
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. ——Apache Hadoop YARN官方文档
正如你从官网看到的,YARN的基本思想就是将资源管理和作业调度/监控拆分成单独的守护进程。个人认为,以下4个关键词可以用来概括YARN:
1.分布式
2.资源管理
3.作业调度/监控
4.守护进程
其中1和4,大数据框架必备。YARN就是为分布式系统设计的,就没人奇怪为啥所有的大数据框架都是守护进程吗?
守护进程
In multitasking computer operating systems, a daemon is a computer program that runs as a background process, rather than being under the direct control of an interactive user.
>
——维基百科
实际上守护进程和普通进程没啥区别,按照维基百科的说法,守护进程就是一种不和用户直接交互的后台进程。它通常用来响应对服务的请求,或者拿来监视系统,或者运行计划的任务。所以大数据框架之所以都这么设计,其中一个很重要的原因是为了和用户进程分离开——我只是想老老实实的提供底层系统服务就好了。(当然翻遍百度和谷歌这个问题都找不到答案,这里只是我自己的理解,欢迎评论区讨论!)
------
我们主要关注2和3,前面讲到,你啥事都干,肯定干不好,所以得拆分。这里先引申一个概念——统一资源管理和调度平台范型。
我们将根据目前资源管理和调度平台的总体运行宏观机制对其进行分类,一共可以归纳出三种:集中式调度器、双层调度器与状态共享调度器,其中第三种现在还不成熟,咱们就不讲了。
集中式调度器
集中式调度器最大特点就是全局只有一个大脑——中央调度器,所有的请求都给这个大脑,所有的调度逻辑也都是它来实现的。有人觉得怎么好像在哪见过,没错,上面提到的JobTracer其实就是一种集中式调度器。
双层调度器
双层调度将整个调度工作划分成两层:中央调度器和框架调度器。中央调度器管理着集群中所有资源的状态,它拥有集群所有的资源信息,按照一定的策略将资源粗粒度地分配给框架调度器,每个框架调度器再跟进作业特性细粒度地分配给容器执行具体的计算任务。
这种设计大大减轻了中央调度器的负载。
YARN的架构设计其实就是遵循着双层调度的思想来实现的。
YARN架构
YARN的总体架构图如下所示:
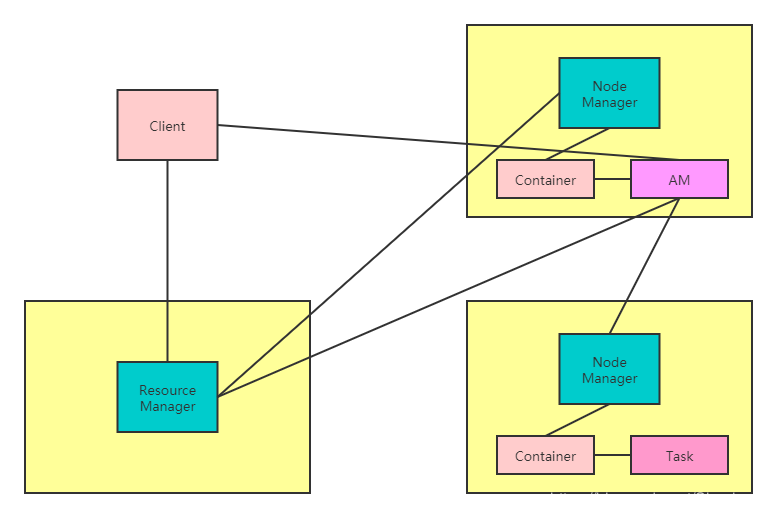
YARN总体上采用主从架构,其中ResourceManager(RM)为主,NodeManager(NM)为从,RM负责对各个NM上的资源进行统一管理和调度。
正如我上面讲到的,如果只是单纯的主从架构实际上还达不到解耦的目的,我们需要将其中与具体应用程序密切相关的部分提取出来,单独来处理,这就是上图中AM的设计来源。
------
我们先来谈谈AM这样设计有啥好处?
将所有复杂性(在可能的范围内)转移到AM上,同时提供足够的功能以允许应用程序框架作者具有足够的灵活性和功能。
由于它本质上是用户代码,因此请不要信任AM,即任何AM都不是特权服务。
YARN系统(RM和NM)必须保护自己免受错误或恶意的AM以及不惜一切代价授予它们的资源。
------
再和上面提到的双层调度知识点串联起来,实际上RM代表的是中央调度器,AM代表的是框架调度器(或者叫二层调度器)。
试想一下,如果让你来设计,你怎么去处理AM的具体交互呢?
具体的细节咱们放到工作原理再来细讲,我们先来介绍一下上图中每个模块的作用,为了方便记忆,我提取了相应的关键词。
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理与分配。RM按照职能也被拆分成了主要的两个组件:
Scheduler
纯调度器
Scheduler会根据每一个应用的具体需求分配资源,而资源分配的单位用一个抽象的概念“容器”(Container)表示。
可插拔
用户可以根据需求设计新的调度器,YARN基于常见的调度策略也提供了直接可用的调度器。
ApplicationManager
应用程序全局管理
ApplicationManager负责管理整个系统所有的应用程序,包括:应用程序注册,与Scheduler协商资源来启动ApplicationMaster,监控ApplicationMaster的运行状态,如果ApplicationMaster挂了重新再拉起来等。
------
RM是如此重要,我们需要通过主从热备来保障整个集群的高可用性。关于HA的内容不是本文重点,这里不再赘述。
NodeManager(NM)
NM是每个节点上面的资源管理器。
通信RM
接收及处理来自 ResourceManager 的命令请求,分配 Container 给应用的某个任务;
定时地向RM汇报以确保整个集群平稳运行,RM 通过收集每个 NodeManager 的报告信息来追踪整个集群健康状态的,而 NodeManager 负责监控自身的健康状态;
通信AM
NM接收并处理来自AM的任务启动/停止等各种请求。
单节点管家
管理着所在节点每个 Container 的生命周期;
管理每个节点上的日志;
ApplicationMaster(AM)
有人会将AM和上面的ApplicationManager混淆,实际上你只需要这样理解就行,ApplicationManager是AM的老大,而AM对应的是单个的应用程序。
AM主要的功能包括:
协商
与RM协商以获取资源
细分
得到的资源进一步分配给内部的任务。
通信NM
与NM通信以启动/停止任务
监控
监控所有任务的运行状态,并在任务运行失败的时候重新为任务申请资源以重启任务。
------
这一部分注定是与整个系统资源管理/调度解耦的,不同的计算框架和服务有不同的实现。
Container
Container是一个动态资源分配单位,它将内存、CPU等资源封装在一起,从而限定每个应用的资源使用量。
简单纯粹
相比于MR v1的槽,Container对于不同计算框架都是无差别对待,Container完全没有计算框架的逻辑,非常的简单纯粹。
合理范围
这里面需要注意,管理员只需要设置Container资源的最大值,表示该节点有多少个资源可供使用。Container位于一个节点上,也就是说,最大资源也就是一个NodeManager的资源大小。AM向RM申请的资源只需要在这个合理范围内都行。
管理员可以配置单个Container资源的最大最小值、增量大小来更细粒度的控制。
CPU和内存
当前版本,Container只支持CPU和内存两种资源。
------
我们目前只关注核心的四大组件RM/NM/AM/Container,其余的比如JobHistoryServer ,TimelineServer 等我们暂不讨论。
工作原理
组件咱们已经初步掌握了,那么这些组件之间是如何协同发挥作用的呢?
其实从前面讲到的架构,我们很容易就看出来,AM其实起到了一个至关重要的作用,应用程序和集群之间的桥梁其实就是AM。
我们再来看这个问题:如果让你来设计,你怎么去处理AM的具体交互呢?
我们作为程序猿,免不了要和项目经理打交道,实际上,项目经理就类似于上面提到的AM。你想想看,假设你是一个刚刚准备立项的项目经理,你要做哪些事情,你首先得有个规划吧,大致需要哪些资源你得列出来吧,你写好PPT,是不是得跟上级汇报一下,上级评估一下资源以后,再看看哪个地方有空余的项目室然后批给你,这样你等各种人力、财务资源等都到齐以后,就可以正式干活了,当然你作为项目经理,监控整个项目的进度是必不可少的工作,项目都完成以后,人力资源等都还回去了,一个项目就结束了。
当然了,我没有做过项目经理,我知道项目经理的职责要比我说的多得多,你就别跟我较劲那些细节了,我本意只是方便你去理解它。
------
如果你理解了上面的流程,我相信你去理解下面的流程也不会很难:
用户将应用程序提交到 RM上;
RM为应用程序申请资源,并与某个 NM通信启动第一个 Container,以启动AM;
AM与 RM注册进行通信,为内部要执行的任务申请资源,一旦得到资源后,将于 NM通信,以启动对应的 Task;
所有任务运行完成后,AM向 RM注销,整个应用程序运行结束。
------
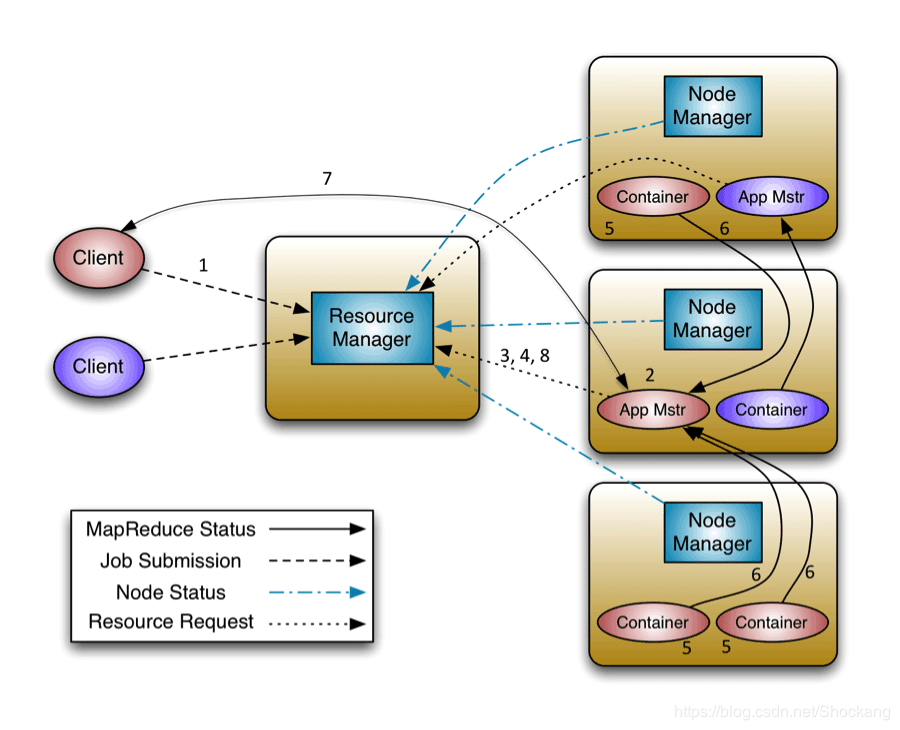
如果你理解了上面的简单流程,那么你再去理解下面完整版的我相信也不会太难。
客户端程序向 RM提交应用并请求一个 AM实例;
RM找到一个可以运行一个 Container 的 NM,并在这个 Container 中启动 AM实例;
AM向RM进行注册,注册之后客户端就可以查询 RM获得自己 AM的详细信息,以后就可以和自己的 AM直接交互了(这个时候,客户端主动和 AM 交流,应用先向 AM发送一个满足自己需求的资源请求);
在平常的操作过程中,AM根据 resource-request协议 向 RM发送 resource-request请求;
当 Container 被成功分配后,AM通过向 NM发送 container-launch-specification信息 来启动Container,container-launch-specification信息包含了能够让Container 和 AM交流所需要的资料;
应用程序的代码以 task 形式在启动的 Container 中运行,并把运行的进度、状态等信息通过 application-specific协议 发送给AM;
在应用程序运行期间,提交应用的客户端主动和 AM交流获得应用的运行状态、进度更新等信息,交流协议也是 application-specific协议;
一旦应用程序执行完成并且所有相关工作也已经完成,AM向RM取消注册然后关闭,用到所有的 Container 也归还给系统。
------
或许你会说,这下面的完整版和我上面举的项目经理的例子差太多了吧,实际上我们学习如果能将新知识和旧知识串联起来,新知识会吸收的更快。为了方便你理解,下面还有一张图:
我自己提炼了一下:
参考:
《Hadoop海量数据处理-技术详解与项目实战第2版》-范东来著
《大数据技术体系详解-原理、架构与实践》-董西成著
个人网站:
个人博客:
https://blog.csdn.net/Shockang
版权声明: 本文为 InfoQ 作者【Shockang】的原创文章。
原文链接:【http://xie.infoq.cn/article/9ef8aac9e524d8060d705547a】。文章转载请联系作者。

大数据开发工程师 2018.10.10 加入
分享大数据开发学习中的心得体会









评论