云原生在京东丨云原生时代下的监控:如何基于云原生进行指标采集?

云妹导读:
从 IDC 到云,从弹性计算到容器技术,整个软件运行的环境发生了天翻地覆的变化,监控对象以及指标也发生了微妙的变化。从原本的主机为主体,变为了容器和服务为主体。而人们对于监控的要求,也逐渐从“看到指标 ”向被监控对象的“可观测性”发生转变。这一转变在以 Kubernetes 为代表的容器管理领域尤为明显。
从 Kubernetes 成为容器管理领域的事实标准开始,基于云原生也就是基于 Kubernetes 原生。在云的体系下,基础硬件基本上都被抽象化、模糊化,硬故障需要人为干预的频次在逐渐降低,健康检查、失败自愈、负载均衡等功能的提供,也使得简单的、毁灭性的故障变少。而随着服务的拆分和模块的堆叠,不可描述的、模糊的、莫名其妙的故障却比以前更加的频繁。
“看到指标”只是对于数据简单的呈现,在目前云的环境下,并不能高效地帮助我们找到问题。而“可观测性”体现的是对数据的再加工,旨在挖掘出数据背后隐藏的信息,不仅仅停留在展现数据层面,更是经过对数据的解析和再组织,体现出数据的上下文信息。
为了达成“可观测性”的目标,就需要更加标准化、简洁化的指标数据,以及更便捷的收集方式,更强更丰富的语义表达能力,更快更高效的存储能力。本篇文章将主要探讨时序指标的采集结构和采集方式,数据也是指时序数据,存储结构以及 tracing、log、event 等监控形式不在本次讨论范围之内。

提到时序数据,让我们先看看几个目前监控系统比较常用的时序数据库:opentsdb,influxdb,prometheus 等。
经典的时序数据基本结构大家都是有统一认知的:
唯一序列名标识,即指标名称;
指标的标签集,详细描述指标的维度;
时间戳与数值对,详细描述指标在某个时间点的值。
时序数据基本结构为指标名称 + 多个 kv 对的标签集 + 时间戳 + 值,但是在细节上各家又各有不同。



opentsdb 使用大家耳熟能详的 json 格式,可能是用户第一反应中结构化的时序数据结构。只要了解基本时序数据结构的人一眼就能知道各个字段的含义。

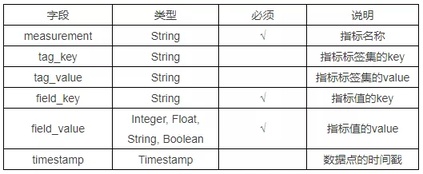

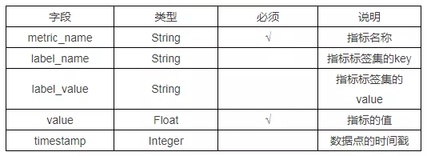
influxdb 和 prometheus 都使用了自定义文本格式的时序数据描述,通过固定的语法格式将 json 的树状层级结构打平,并且没有语义的丢失,行级的表述形式更便于阅读。

文本格式优势
○ 更符合人类阅读习惯
○ 行级的表述结构对文件读取的内存优化更友好
○ 减少了层级的嵌套
文本格式劣势
○ 解析成本更高
○ 校验相对更麻烦

使用过 Prometheus 的同学可能会注意到其实 Prometheus 的采集结构不是单行的,每类指标往往还伴随着几行注释内容 ,其中主要是两类 HELP 和 TYPE ,分别表示指标的简介说明和类型。格式大概是:
Prometheus 主要支持 4 类指标类型:
Counter:只增不减的计数器。
Gauge:可增可减的数值。
Histogram:直方图,分桶采样。
Summary:数据汇总,分位数采样。
其中 Counter 和 Gauge 很好理解,Histogram 和 Summary 可能一时间会让人迷惑。其实 Histogram 和 Summary 都是为了从不同维度解决和过滤长尾问题。
例如,我和首富的平均身价并不能真实反映出我自己的身价。因此分桶或者分位数才能更准确的描述数据真实的分布状态。
而 Histogram 和 Summary 主要区别就在于对分位数的计算上,Histogram 在客户端只进行分桶计算,因此可以在服务端进行整体的分位数计算。Summary 则是在客户端环境下计算了分位数,因此失去了在整体视图上进行分位数计算的可能性。官方也给出了 Histogram 和 Summary 的区别:
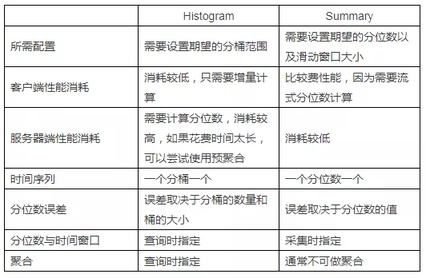
需要说明的是,截止到目前为止的 Prometheus 版本 2.20.1,这些 metric types 仅仅使用在客户端库(client libraries)和传输协议(wire protocol)中,服务端暂时没有记录这些信息。所以如果你对一个 Gauge 类型的指标使用 histogram_quantile(0.9,xxx) 也是可以的,只不过因为没有 xxx_bucket 的存在,计算不出来值而已。

时序监控数据的采集,从监控端来看,数据获取的形式只有两种,pull 和 push,不同的采集方式也决定了部署方式的不同。
还是通过 opentsdb,prometheus 来举例,因为 influxdb 集群版本方案为商业版,暂不做讨论。

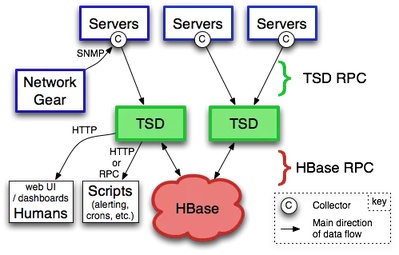
上图为 opentsdb 架构图 ,其中:
Servers:表示被采集数据的服务,C 则是表示采集指标的工具,可以理解为 opensdb 的 agent,servers 通过 C 将数据推送到下游的 TSD。
TSD:对应实际进程名 TSDMain 是 opentsdb 组件,理解为接收层,每个 TSD 都是独立的,没有 master 和 slave 的区分,也没有共享状态。
HBase:opentsdb 实际的最终数据存储在 hbase 中。
从架构图可以看出,如果推送形式的数据量大量增长的情况下,可以通过多级组件,或者扩容无状态的接收层等方式较为简单的进行吞吐量的升级。

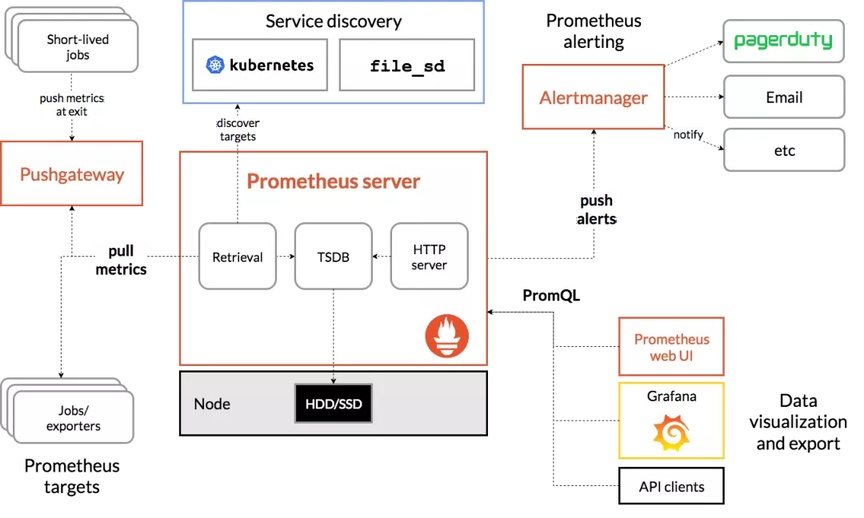
上图为 prometheus 架构图,主要看下面几个部分:
Prometheus Server:用于抓取和存储时间序列化数据。
Exporters:主动拉取数据的插件。
Pushgateway:被动拉取数据的插件。
拉取的方式,通常是监控端定时从配置的各个被监控端的 Exporter 处拉取指标。这样的设计方式可以降低监控端与被监控端的耦合程度,被监控端不需要知道监控端的存在,这样将指标发送的压力从被监控端转义到监控端。
对比一下 pull 和 push 方式各自的优劣势:
pull 的优势
pull 的劣势
简单对比了 pull 和 push 各自的特点,在云原生环境中,prometheus 是目前的时序监控标准,为什么会选择 pull 的形式,这里有官方的解释(https://prometheus.io/docs/introduction/faq/#why-do-you-pull-rather-than-push)。
上面简单介绍了一下从监控端视角看待数据采集方式的 pull 和 push 形式,而从被监控端来看,数据获取的方式就多种多样了,通常可以分为以下几种类型:
默认采集
探测采集
组件采集
埋点采集
下面一一举例说明。

默认采集通常是通俗意义上的所有人都会需要观察的基础指标,往往与业务没有强关联,例如 cpu、memory、disk、net 等等硬件或者系统指标。通常监控系统都会有特定的 agent 来固定采集这些指标,而在云原生中非常方便的使用 node_exporter、CAdvisor、process-exporter,分别进行节点机器、容器以及进程的基础监控。

探测采集主要是指从外部采集数据的方式。例如域名监控、站点监控、端口监控等都属于这一类。采集的方式对系统没有侵入,因为对网络的依赖比较强,所以通常会部署多个探测点,减少因为网络问题造成的误报,但是需要特别小心的是,一定要评估探测采集的频次,否则很容易对被探测方造成请求压力。

通常是指已经有现成的采集方案,只需要简单的操作或者配置就可以进行详细的指标采集,例如 mysql 的监控,redis 的监控等。在云原生环境中,这种采集方式比较常见,得益于 prometheus 的发展壮大,常见的组件采集 exporter 层出不穷,prometheus 官方认证的各种 exporter。对于以下比较特殊或者定制化的需求,也完全可以按照 /metrics 接口标准自己完成自定义 exporter 的编写。

对于一个系统的关键性指标,本身的研发同学是最有发言权的,通过埋点的方式可以精准的获取相关指标。在 prometheus 体系中可以非常方便的使用 github.com/prometheus/client_* 的工具包来实现埋点采集。

本文对监控系统的第一个阶段“采集”,从“采集结构”和“采集方式”两方面做了简单的介绍和梳理。相比于以往,在云原生的环境中,服务颗粒度拆分的更细致,迭代效率更高,从开发到上线形成了更快节奏的反馈循环,这也要求监控系统能够更快速的反映出系统的异常,“采集结构”和“采集方式”虽然不是监控系统最核心的部分,但是简洁的采集结构和便捷的采集方式也为后续实现“可观测性”提供了基础。目前在云原生环境中,使用 prometheus 可以非常方便快捷的实现监控,虽然仍有许多工作需要做,例如集群化、持久化存储等,但是随着 Thanos 等方案的出现,prometheus 也在渐渐丰满中。
欢迎点击【京东智联云】了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东智联云开发者】公众号
版权声明: 本文为 InfoQ 作者【京东科技开发者】的原创文章。
原文链接:【http://xie.infoq.cn/article/9785197658085598fb4558156】。文章转载请联系作者。

拥抱技术,与开发者携手创造未来! 2018.11.20 加入
我们将持续为人工智能、大数据、云计算、物联网等相关领域的开发者,提供技术干货、行业技术内容、技术落地实践等文章内容。京东科技开发者社区官方网站【https://developer.jdcloud.com/】,欢迎大家来玩









评论